Recognition: 2 theorem links
· Lean TheoremPost-Hoc Guidance for Consistency Models by Joint Flow Distribution Learning
Pith reviewed 2026-05-10 18:19 UTC · model grok-4.3
The pith
A lightweight alignment method gives pre-trained consistency models adjustable classifier-free guidance without any diffusion teacher.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
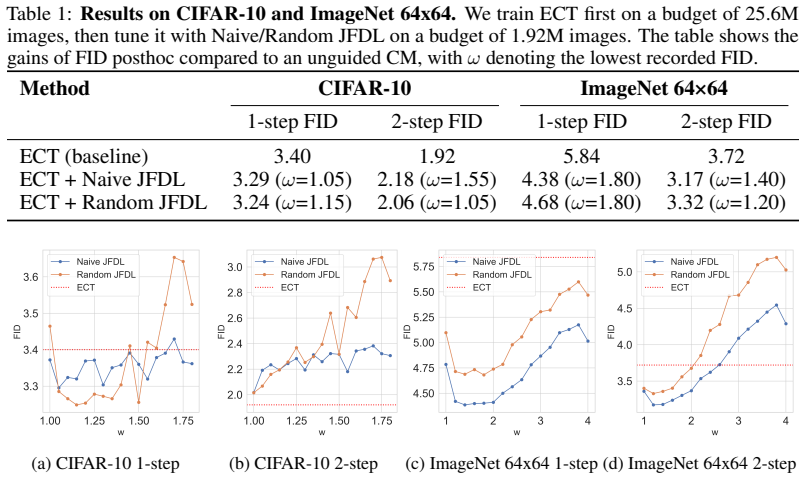
Joint Flow Distribution Learning (JFDL) equips any pre-trained consistency model with post-hoc classifier-free guidance by aligning the flow distributions induced by unconditional and conditional velocity fields; because normality tests confirm the variance-exploding noise is Gaussian, the standard guidance scaling can be used directly, yielding improved FID on CIFAR-10 and ImageNet 64x64 even for models trained only with consistency training.
What carries the argument
Joint Flow Distribution Learning (JFDL), an alignment procedure that treats the pre-trained consistency model as an ODE solver to match unconditional and conditional flow distributions.
If this is right
- Any pre-trained consistency model can now use an adjustable guidance knob to trade fidelity against diversity.
- Originally consistency-trained models gain the ability to produce guided samples without retraining or a teacher.
- FID scores drop on CIFAR-10 and ImageNet 64x64 when the learned guidance is applied.
- Guidance is obtained while keeping the original one- or few-step sampling cost.
- No separate diffusion model is required for the guidance stage.
Where Pith is reading between the lines
- The same alignment idea might extend to other few-step generators whose velocity or score fields are approximately Gaussian.
- If the Gaussianity holds more generally, JFDL could serve as a template for adding controllable generation to many fast samplers without architectural changes.
- The approach highlights that post-hoc distribution alignment on flow fields can substitute for explicit distillation in some cases.
Load-bearing premise
That confirming the Gaussian character of the variance-exploding noise via normality tests on velocity fields is enough to make the guidance scale produce useful and stable results.
What would settle it
Running the guidance scale on a pre-trained consistency model and finding that sample quality does not improve or that the outputs lose the characteristic trade-off between fidelity and diversity seen in CFG diffusion models would show the method fails.
Figures
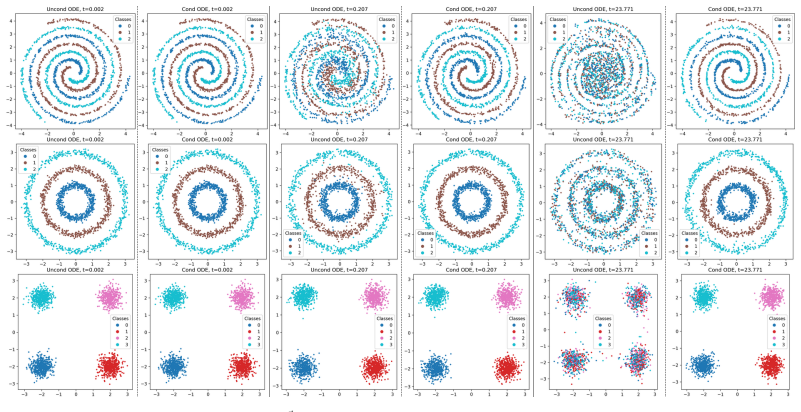
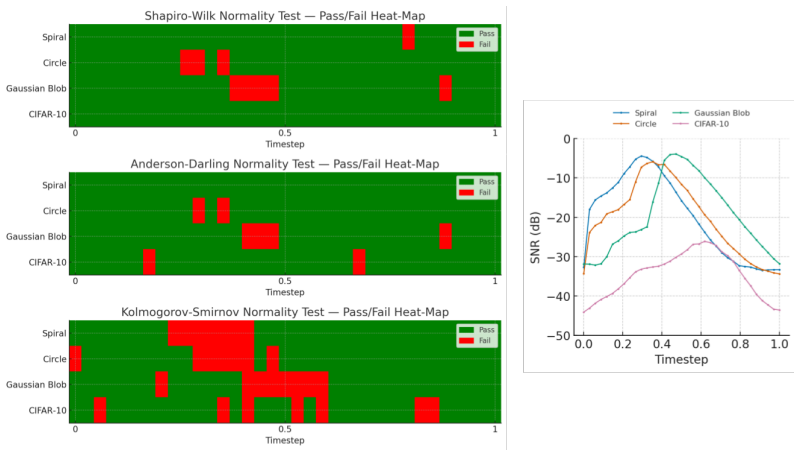














read the original abstract
Classifier-free Guidance (CFG) lets practitioners trade-off fidelity against diversity in Diffusion Models (DMs). The practicality of CFG is however hindered by DMs sampling cost. On the other hand, Consistency Models (CMs) generate images in one or a few steps, but existing guidance methods require knowledge distillation from a separate DM teacher, limiting CFG to Consistency Distillation (CD) methods. We propose Joint Flow Distribution Learning (JFDL), a lightweight alignment method enabling guidance in a pre-trained CM. With a pre-trained CM as an ordinary differential equation (ODE) solver, we verify with normality tests that the variance-exploding noise implied by the velocity fields from unconditional and conditional distributions is Gaussian. In practice, JFDL equips CMs with the familiar adjustable guidance knob, yielding guided images with similar characteristics to CFG. Applied to an original Consistency Trained (CT) CM that could only do conditional sampling, JFDL unlocks guided generation and reduces FID on both CIFAR-10 and ImageNet 64x64 datasets. This is the first time that CMs are able to receive effective guidance post-hoc without a DM teacher, thus, bridging a key gap in current methods for CMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Joint Flow Distribution Learning (JFDL), a lightweight post-hoc alignment technique that equips pre-trained Consistency Models (CMs) with classifier-free guidance by jointly learning unconditional and conditional flow distributions. Using a pre-trained CM as an ODE solver, the authors apply normality tests to velocity fields and conclude that the implied variance-exploding noise is Gaussian, enabling CFG-style guidance without a separate diffusion-model teacher. They demonstrate the approach on an original Consistency-Trained (CT) CM, reporting FID reductions on CIFAR-10 and ImageNet 64×64 while producing images with guidance characteristics similar to those of diffusion models.
Significance. If the Gaussianity verification and the resulting alignment mechanism hold, the result would meaningfully extend the applicability of fast CM sampling by removing the need for distillation-based guidance, a practical gap in current one- or few-step generative methods. The empirical FID gains on standard benchmarks provide concrete evidence of utility, and the avoidance of a DM teacher is a clear methodological advance over prior consistency-distillation approaches.
major comments (2)
- [Gaussianity verification (abstract and §3)] The verification that variance-exploding noise is Gaussian (described in the abstract and the method section) relies on normality tests applied to velocity fields from unconditional and conditional distributions. Standard normality tests on finite high-dimensional samples have limited power to detect tail deviations, cross-dimensional correlations, or conditional structure that would break the equivalence between the learned joint flow and true CFG-guided dynamics; this assumption is load-bearing for the claim that JFDL enables effective post-hoc guidance rather than incidental distribution matching.
- [Experimental results] Table reporting FID scores (presumably Table 1 or 2): the manuscript shows FID reductions for the JFDL-augmented CT model but does not include an ablation that isolates the contribution of the joint-flow alignment from simple conditional fine-tuning or from the choice of guidance scale; without this, it remains unclear whether the reported gains are produced by the intended CFG-mimicking mechanism.
minor comments (2)
- [Abstract] The abstract states that guided images have 'similar characteristics to CFG' but does not specify which quantitative metrics (beyond FID) or qualitative attributes were used to establish this similarity.
- [Method] Notation for the joint distribution alignment objective could be clarified with an explicit equation showing how the unconditional and conditional velocity fields are combined during training.
Simulated Author's Rebuttal
We thank the referee for the detailed review and valuable suggestions. We address the major comments point-by-point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Gaussianity verification (abstract and §3)] The verification that variance-exploding noise is Gaussian (described in the abstract and the method section) relies on normality tests applied to velocity fields from unconditional and conditional distributions. Standard normality tests on finite high-dimensional samples have limited power to detect tail deviations, cross-dimensional correlations, or conditional structure that would break the equivalence between the learned joint flow and true CFG-guided dynamics; this assumption is load-bearing for the claim that JFDL enables effective post-hoc guidance rather than incidental distribution matching.
Authors: We agree that standard normality tests have limited power in high-dimensional settings and may not fully capture all potential deviations such as tail behavior or correlations. However, the tests were applied to the velocity fields derived from the pre-trained consistency model to support the Gaussian assumption for the implied noise. The success of JFDL in producing guidance effects similar to CFG and the observed FID improvements provide empirical validation of the approach. To address the concern, we will revise §3 to include a more detailed discussion of the limitations of the normality tests and their implications for the method. We will also consider adding additional statistical analyses if feasible. revision: partial
-
Referee: [Experimental results] Table reporting FID scores (presumably Table 1 or 2): the manuscript shows FID reductions for the JFDL-augmented CT model but does not include an ablation that isolates the contribution of the joint-flow alignment from simple conditional fine-tuning or from the choice of guidance scale; without this, it remains unclear whether the reported gains are produced by the intended CFG-mimicking mechanism.
Authors: We acknowledge that the current experiments do not include ablations separating the effects of joint flow alignment from conditional fine-tuning or varying guidance scales. This is a valid point that would help clarify the source of the improvements. In the revised manuscript, we will add ablation studies to isolate these contributions, including comparisons with simple conditional fine-tuning and experiments varying the guidance scale to demonstrate the mechanism. revision: yes
Circularity Check
No significant circularity; derivation relies on independent empirical verification
full rationale
The paper's chain proceeds by using a pre-trained CM as an ODE solver, performing normality tests on velocity fields to confirm Gaussian variance-exploding noise, and then introducing JFDL as an alignment procedure to enable post-hoc guidance. This verification step is presented as external empirical support rather than a definitional or fitted tautology. No equations or claims reduce by construction to prior inputs, no load-bearing self-citations appear, and the method does not rename fitted quantities as predictions. The central result (post-hoc guidance without a DM teacher) therefore retains independent content from the reported experiments on CIFAR-10 and ImageNet.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The variance-exploding noise implied by the velocity fields from unconditional and conditional distributions is Gaussian.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe verify with normality tests that the variance-exploding noise implied by the velocity fields from unconditional and conditional distributions is Gaussian... Joint Flow Distribution Learning (JFDL)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearthe CVF has the analytical form ut(xt|x0)=σ′t/σt(xt−μt(x0))+μ′t(x0)
Reference graph
Works this paper leans on
-
[1]
goodness of fit
Theodore W. Anderson and Donald A. Darling. Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes.Annals of Mathematical Statistics, 23(2):193–212, 1952
1952
-
[2]
Classifier-free guidance is a predictor-corrector
Arwen Bradley and Preetum Nakkiran. Classifier-free guidance is a predictor-corrector.arXiv preprint arXiv:2408.09000, 2024
-
[3]
Pixart-δ: Fast and controllable image generation with latent consistency models, 2024
Junsong Chen, Yue Wu, Simian Luo, Enze Xie, Sayak Paul, Ping Luo, Hang Zhao, and Zhenguo Li. Pixart-δ: Fast and controllable image generation with latent consistency models, 2024
2024
-
[4]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks, 2018
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks, 2018
2018
-
[5]
Cfg++: Manifold-constrained classifier free guidance for diffusion models, 2024
Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. Cfg++: Manifold-constrained classifier free guidance for diffusion models, 2024
2024
-
[6]
Mo- tionlcm: Real-time controllable motion generation via latent consistency model, 2024
Wenxun Dai, Ling-Hao Chen, Jingbo Wang, Jinpeng Liu, Bo Dai, and Yansong Tang. Mo- tionlcm: Real-time controllable motion generation via latent consistency model, 2024
2024
-
[7]
Improved training technique for latent consistency models, 2025
Quan Dao, Khanh Doan, Di Liu, Trung Le, and Dimitris Metaxas. Improved training technique for latent consistency models, 2025
2025
-
[8]
A brief review of tests for normality.American Journal of Theoretical and Applied Statistics, 5(1):5–12, 2016
Keya Rani Das and AHMR Imon. A brief review of tests for normality.American Journal of Theoretical and Applied Statistics, 5(1):5–12, 2016
2016
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[10]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, 2017
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, 2017
2017
-
[11]
Music consistency models, 2024
Zhengcong Fei, Mingyuan Fan, and Junshi Huang. Music consistency models, 2024
2024
-
[12]
One step diffusion via shortcut models, 2024
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models, 2024
2024
-
[13]
Murphy, and Tim Salimans
Ruiqi Gao, Emiel Hoogeboom, Jonathan Heek, Valentin De Bortoli, Kevin P. Murphy, and Tim Salimans. Diffusion meets flow matching: Two sides of the same coin. 2024
2024
-
[14]
Zico Kolter
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, and J. Zico Kolter. Consistency models made easy, 2024
2024
-
[15]
Consistency diffusion bridge models, 2024
Guande He, Kaiwen Zheng, Jianfei Chen, Fan Bao, and Jun Zhu. Consistency diffusion bridge models, 2024
2024
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018
2018
-
[17]
Denoising diffusion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020
2020
-
[18]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
2022
-
[20]
Chia-Hong Hsu, Shiu-hong Kao, and Randall Balestriero. Beyond and free from diffusion: Invertible guided consistency training.arXiv preprint arXiv:2502.05391, 2025
-
[21]
Martin Hutzenthaler and Arnulf Jentzen
Rongjie Huang, Max WY Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, and Zhou Zhao. Fast- diff: A fast conditional diffusion model for high-quality speech synthesis.arXiv preprint arXiv:2204.09934, 2022. 10
-
[22]
Prodiff: Progressive fast diffusion model for high-quality text-to-speech
Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. Prodiff: Progressive fast diffusion model for high-quality text-to-speech. InProceedings of the 30th ACM International Conference on Multimedia, pages 2595–2605, 2022
2022
-
[23]
Elucidating the design space of diffusion-based generative models, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022
2022
-
[24]
Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself.Advances in Neural Information Processing Systems, 37:52996–53021, 2024
2024
-
[25]
Analyzing and improving the training dynamics of diffusion models, 2024
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models, 2024
2024
-
[26]
Simple reflow: Improved techniques for fast flow models, 2024
Beomsu Kim, Yu-Guan Hsieh, Michal Klein, Marco Cuturi, Jong Chul Ye, Bahjat Kawar, and James Thornton. Simple reflow: Improved techniques for fast flow models, 2024
2024
-
[27]
Beomsu Kim, Jaemin Kim, Jeongsol Kim, and Jong Chul Ye. Generalized consistency trajectory models for image manipulation.arXiv preprint arXiv:2403.12510, 2024
-
[28]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279, 2023
-
[29]
Prince, and Marcus A
Ivan Kobyzev, Simon J.D. Prince, and Marcus A. Brubaker. Normalizing flows: An introduction and review of current methods.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):3964–3979, November 2021
2021
-
[30]
Cifar-10 (canadian institute for advanced research)
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar-10 (canadian institute for advanced research)
-
[31]
Truncated consistency models, 2025
Sangyun Lee, Yilun Xu, Tomas Geffner, Giulia Fanti, Karsten Kreis, Arash Vahdat, and Weili Nie. Truncated consistency models, 2025
2025
-
[32]
Bidirectional consistency models, 2025
Liangchen Li and Jiajun He. Bidirectional consistency models, 2025
2025
-
[33]
Connecting consistency distillation to score distillation for text-to-3d generation
Zongrui Li, Minghui Hu, Qian Zheng, and Xudong Jiang. Connecting consistency distillation to score distillation for text-to-3d generation. InEuropean Conference on Computer Vision, pages 274–291. Springer, 2024
2024
-
[34]
Magic3d: High-resolution text-to-3d content creation, 2023
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation, 2023
2023
-
[35]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023
2023
-
[36]
Rectified flow: A marginal preserving approach to optimal transport, 2022
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport, 2022
2022
-
[37]
Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
2022
-
[38]
Simplifying, stabilizing and scaling continuous-time consistency models, 2025
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models, 2025
2025
-
[39]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
2022
-
[40]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm- solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022
-
[41]
Understanding diffusion models: A unified perspective, 2022
Calvin Luo. Understanding diffusion models: A unified perspective, 2022. 11
2022
-
[42]
Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
2023
-
[43]
Frank J. Massey. The kolmogorov-smirnov test for goodness of fit.Journal of the American Statistical Association, 46(253):68–78, 1951
1951
-
[44]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14297–14306, 2023
2023
-
[45]
Improved denoising diffusion probabilistic models, 2021
Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models, 2021
2021
-
[46]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[47]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
2023
-
[48]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[49]
Seyedmorteza Sadat, Manuel Kansy, Otmar Hilliges, and Romann M Weber. No train- ing, no problem: Rethinking classifier-free guidance for diffusion models.arXiv preprint arXiv:2407.02687, 2024
-
[50]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review arXiv 2022
-
[51]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer, 2024
2024
-
[52]
S. S. SHAPIRO and M. B. WILK. An analysis of variance test for normality (complete samples). Biometrika, 52(3-4):591–611, dec 1965
1965
-
[53]
Denoising diffusion implicit models, 2022
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022
2022
-
[54]
Improved Tech- niques for Training Consistency Models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023
-
[55]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[56]
Generative modeling by estimating gradients of the data distribution, 2020
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution, 2020
2020
-
[57]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021
2021
-
[58]
Stable consistency tuning: Understanding and improving consistency models, 2024
Fu-Yun Wang, Zhengyang Geng, and Hongsheng Li. Stable consistency tuning: Understanding and improving consistency models, 2024
2024
-
[59]
Cache me if you can: Accelerating diffusion models through block caching, 2024
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cremers, Peter Vajda, and Jialiang Wang. Cache me if you can: Accelerating diffusion models through block caching, 2024
2024
-
[60]
A survey on video diffusion models.ACM Computing Surveys, 57(2):1–42, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video diffusion models.ACM Computing Surveys, 57(2):1–42, 2024
2024
-
[61]
Consistency flow matching: Defining straight flows with velocity consistency, 2024
Ling Yang, Zixiang Zhang, Zhilong Zhang, Xingchao Liu, Minkai Xu, Wentao Zhang, Chenlin Meng, Stefano Ermon, and Bin Cui. Consistency flow matching: Defining straight flows with velocity consistency, 2024. 12
2024
-
[62]
Comparisons of various types of normality tests.Journal of Statistical Computation and Simulation, 81(12):2141–2155, 2011
Bee Wah Yap and Chiaw Hock Sim. Comparisons of various types of normality tests.Journal of Statistical Computation and Simulation, 81(12):2141–2155, 2011
2011
-
[63]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InProceedings of the IEEE/CVF international conference on computer vision, pages 16010–16021, 2023
2023
-
[64]
Adding conditional control to text-to-image diffusion models, 2023
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models, 2023
2023
-
[65]
Jianbin Zheng, Minghui Hu, Zhongyi Fan, Chaoyue Wang, Changxing Ding, Dacheng Tao, and Tat-Jen Cham. Trajectory consistency distillation: Improved latent consistency distillation by semi-linear consistency function with trajectory mapping.arXiv preprint arXiv:2402.19159, 2024. 13 Supplementary Materials: Table of Contents A Proofs 14 A.1 Proof of Proposit...
-
[66]
The above result is obtained by the multivariate chain rule
be the solution of the forwardc-class ODE. The above result is obtained by the multivariate chain rule. We will continue to solve for terms (A) and (B). According to (15),(A)is, d dt xc t =−σ t∇x logp(x c t |c).(16) The term (B), which can be interpreted asthe change of time at t when the backward flow started, affecting the final solution at time 0, we b...
-
[67]
+o(t 2) g(t) =f(0) + f(0)−f(t) t =f(0) + σmaxt 2 ∇x logp(c|x c
-
[68]
Their approach achieved guided disribution even under unconditional sampling
+o(t 2) (27) 17 B Random JFDL The authors in [ 49] introduced Independent Conditional Guidance (ICG) that enables guidance without special training of the ∅-class. Their approach achieved guided disribution even under unconditional sampling. Inspired by their work, we introduce Random JFDL. See Alg. 2, where the difference with Alg. 1 is highlighted in bl...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.