Recognition: 2 theorem links
· Lean TheoremHarnessing Weak Pair Uncertainty for Text-based Person Search
Pith reviewed 2026-05-10 18:13 UTC · model grok-4.3
The pith
Estimating uncertainty in image-text pairs lets the model keep weak positives instead of pushing them away during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
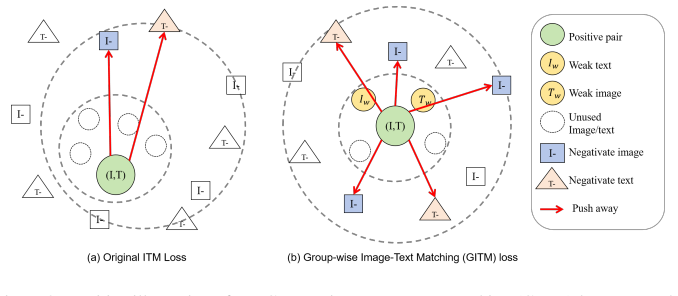
The central claim is that explicitly estimating image-text pair uncertainty and folding it into the optimization prevents the model from pushing away potentially weak positive candidates. This is realized by an uncertainty estimation module that outputs relative confidence for each positive pair, an uncertainty regularization term that adaptively re-weights the loss, and a group-wise image-text matching loss that further structures the space among weak pairs. On the CUHK-PEDES, RSTPReid and ICFG-PEDES datasets the method records mAP gains of 3.06 percent, 3.55 percent and 6.94 percent over prior competitive baselines.
What carries the argument
Uncertainty estimation module that produces relative confidence scores for positive image-text pairs, combined with uncertainty regularization that scales loss contributions and a group-wise image-text matching loss.
If this is right
- Weak positive pairs from different camera views contribute to learning instead of being treated as negatives.
- The learned representation space maintains useful similarity structure among descriptions that vary in viewpoint.
- The same regularization can be dropped into existing contrastive pipelines for text-based person retrieval without architecture changes.
- Mean average precision improves consistently across three standard evaluation sets.
Where Pith is reading between the lines
- The uncertainty signal could serve as a lightweight proxy for label quality when scaling to noisier web-collected image-text data.
- The same soft-weighting idea may transfer to other cross-modal tasks such as video-text retrieval where viewpoint or temporal variation creates analogous weak positives.
- If uncertainty estimates prove reliable, they could be used at inference time to down-weight unreliable matches in a deployed search system.
Load-bearing premise
The uncertainty scores learned by the model truly indicate which pairs are weak positives rather than simply fitting noise or dataset-specific patterns.
What would settle it
A controlled test in which human annotators rate the visual-textual similarity strength of held-out pairs and the model's uncertainty values show no correlation with those ratings, or in which replacing the learned uncertainties with random values eliminates the reported mAP gains.
Figures






read the original abstract
In this paper, we study the text-based person search, which is to retrieve the person of interest via natural language description. Prevailing methods usually focus on the strict one-to-one correspondence pair matching between the visual and textual modality, such as contrastive learning. However, such a paradigm unintentionally disregards the weak positive image-text pairs, which are of the same person but the text descriptions are annotated from different views (cameras). To take full use of weak positives, we introduce an uncertainty-aware method to explicitly estimate image-text pair uncertainty, and incorporate the uncertainty into the optimization procedure in a smooth manner. Specifically, our method contains two modules: uncertainty estimation and uncertainty regularization. (1) Uncertainty estimation is to obtain the relative confidence on the given positive pairs; (2) Based on the predicted uncertainty, we propose the uncertainty regularization to adaptively adjust loss weight. Additionally, we introduce a group-wise image-text matching loss to further facilitate the representation space among the weak pairs. Compared with existing methods, the proposed method explicitly prevents the model from pushing away potentially weak positive candidates. Extensive experiments on three widely-used datasets, .e.g, CUHK-PEDES, RSTPReid and ICFG-PEDES, verify the mAP improvement of our method against existing competitive methods +3.06%, +3.55% and +6.94%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an uncertainty-aware framework for text-based person search that addresses the issue of weak positive image-text pairs (same identity but differing camera views/annotations). It introduces an uncertainty estimation module to predict relative confidence on positive pairs and an uncertainty regularization module to adaptively modulate loss weights, supplemented by a group-wise image-text matching loss. The method claims to prevent the model from incorrectly pushing away weak positives during contrastive optimization, with reported mAP gains of +3.06%, +3.55%, and +6.94% on CUHK-PEDES, RSTPReid, and ICFG-PEDES respectively over prior competitive methods.
Significance. If the uncertainty scores are shown to specifically capture view-induced weak-positive semantics rather than generic re-weighting or dataset artifacts, the approach could meaningfully advance cross-modal retrieval by better utilizing intra-identity variation without discarding useful pairs. The explicit integration of uncertainty into loss modulation and the group-wise term represent a targeted extension of contrastive learning for this task, but the practical significance hinges on validation that the gains are not reproducible by simpler re-weighting schemes.
major comments (2)
- [Abstract and Section 3] Abstract and Section 3 (Methods): the central claim that the uncertainty estimation module 'explicitly prevents the model from pushing away potentially weak positive candidates' lacks a supporting derivation or constraint; the module outputs relative confidence that modulates loss weights, but no term in the objective (e.g., the uncertainty regularization or group-wise loss) enforces that high-uncertainty scores correspond to view-variant same-identity pairs rather than label noise or spurious correlations.
- [Experiments] Experiments section (results tables): the mAP improvements are presented without an ablation isolating the contribution of the uncertainty estimator versus the group-wise matching loss alone, nor any analysis (e.g., correlation of predicted uncertainty with camera-ID differences or human weak-positive labels); this is load-bearing because the skeptic concern that gains may arise from generic re-weighting cannot be ruled out from the reported numbers.
minor comments (2)
- [Abstract] Abstract: '.e.g,' should be 'e.g.,' and the sentence structure listing the three datasets is slightly awkward.
- [Section 3] Notation: the distinction between 'relative confidence' and 'uncertainty' is used interchangeably in the abstract and methods description; a single consistent definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our paper. We have carefully considered each comment and provide point-by-point responses below. We believe our responses address the concerns raised and will strengthen the manuscript in revision.
read point-by-point responses
-
Referee: [Abstract and Section 3] Abstract and Section 3 (Methods): the central claim that the uncertainty estimation module 'explicitly prevents the model from pushing away potentially weak positive candidates' lacks a supporting derivation or constraint; the module outputs relative confidence that modulates loss weights, but no term in the objective (e.g., the uncertainty regularization or group-wise loss) enforces that high-uncertainty scores correspond to view-variant same-identity pairs rather than label noise or spurious correlations.
Authors: We appreciate this observation. The uncertainty estimation module predicts a relative confidence score for each positive pair based on their feature representations. This score is then used by the uncertainty regularization module to adaptively adjust the contribution of that pair to the overall loss. The intent is that pairs exhibiting larger discrepancies (typical of view changes) receive lower weights, thus avoiding aggressive pushing away in the contrastive setup. Although there is no additional constraint term in the objective that explicitly supervises the uncertainty to match view variations, the module is trained jointly with the matching objective on datasets rich in such variations. We will revise Section 3 to include a more formal explanation of how the uncertainty estimation leads to the desired behavior, including any relevant equations or motivations. revision: partial
-
Referee: [Experiments] Experiments section (results tables): the mAP improvements are presented without an ablation isolating the contribution of the uncertainty estimator versus the group-wise matching loss alone, nor any analysis (e.g., correlation of predicted uncertainty with camera-ID differences or human weak-positive labels); this is load-bearing because the skeptic concern that gains may arise from generic re-weighting cannot be ruled out from the reported numbers.
Authors: We agree that additional ablations would help rule out the possibility of generic re-weighting. In the current manuscript, the reported results are for the full model combining uncertainty estimation, regularization, and the group-wise loss. To address this, we will include new ablation studies in the revised experiments section, showing performance with uncertainty regularization alone, group-wise loss alone, and their combination. Furthermore, we will add an analysis section correlating the predicted uncertainty scores with camera ID differences across the datasets, as well as qualitative examples of pairs with high uncertainty scores to illustrate that they correspond to view-induced variations rather than noise. These additions will demonstrate the specific benefit of the uncertainty-aware components. revision: yes
Circularity Check
No significant circularity; uncertainty module is an independent added component
full rationale
The paper's derivation introduces an uncertainty estimation module to compute relative confidence on positive pairs and then applies uncertainty regularization to adjust loss weights plus a group-wise matching term. No equation reduces the reported mAP gains or retrieval performance to a quantity defined solely by the fitted uncertainty values themselves. The improvements (+3.06%, +3.55%, +6.94%) are presented as empirical outcomes on CUHK-PEDES, RSTPReid and ICFG-PEDES rather than algebraic identities or self-definitions. The modeling choice that uncertainty scores reflect weak-positive status is a hypothesis open to external validation and does not collapse the central claim into its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty regularization weight
axioms (2)
- domain assumption Positive pairs share identity even when descriptions differ by camera view
- standard math Uncertainty prediction network can be trained jointly with the main embedding model
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
Luitc = Litc (I,T w) / (γ×u w) + γ×u w, where u w = exp(−s w) and s w = ½(cos(f I,f Iw)+cos(f T,f Tw))
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
uncertainty estimation ... to obtain the relative confidence on the given positive pairs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
X. Shu, W. Wen, H. Wu, K. Chen, Y . Song, R. Qiao, B. Ren, X. Wang, See finer, see more: Implicit modality alignment for text-based person retrieval, in: Com- puter Vision – ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part V , Springer-Verlag, Berlin, Heidelberg, 2023, p. 624–641. doi:10.1007/978-3-031-25072-9_42
-
[3]
S. Yang, Y . Zhou, Y . Wang, Y . Wu, L. Zhu, Z. Zheng, Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark, in: Proceedings of the 2023 ACM on Multimedia Conference, 2023
2023
-
[4]
J. Sun, H. Fei, G. Ding, Z. Zheng, From data deluge to data curation: A filtering- wora paradigm for efficient text-based person search, in: ACM WWW, 2025
2025
-
[5]
X. Ke, H. Liu, P. Xu, X. Lin, W. Guo, Text-based person search via cross-modal alignment learning, Pattern Recognition 152 (2024) 110481.doi:10.1016/j. patcog.2024.110481. 34
work page doi:10.1016/j 2024
-
[6]
Jiang, M
D. Jiang, M. Ye, Cross-modal implicit relation reasoning and aligning for text-to- image person retrieval, in: CVPR, 2023
2023
-
[7]
J. Li, R. R. Selvaraju, A. D. Gotmare, S. Joty, C. Xiong, S. C. Hoi, Align before fuse: vision and language representation learning with momentum distillation, in: NeurIPS, 2021
2021
-
[8]
Z. Shao, X. Zhang, M. Fang, Z. Lin, J. Wang, C. Ding, Learning granularity- unified representations for text-to-image person re-identification, in: ACM MM, Association for Computing Machinery, New York, NY , USA, 2022, p. 5566–5574.doi:10.1145/3503161.3548028
-
[9]
Y . Bai, M. Cao, D. Gao, Z. Cao, C. Chen, Z. Fan, L. Nie, M. Zhang, Rasa: Re- lation and sensitivity aware representation learning for text-based person search, in: IJCAI, IJCAI-2023, 2023.doi:10.24963/ijcai.2023/62
-
[10]
Z. Wang, A. Zhu, J. Xue, X. Wan, C. Liu, T. Wang, Y . Li, Look before you leap: Improving text-based person retrieval by learning a consistent cross-modal common manifold, in: ACM MM, 2022.doi:10.1145/3503161.3548166
- [11]
-
[12]
Q. Liu, X. He, Q. Teng, L. Qing, H. Chen, Bdnet: A bert-based dual-path network for text-to-image cross-modal person re-identification, Pattern Recognition 141 (2023) 109636.doi:10.1016/j.patcog.2023.109636
-
[13]
Y . Chen, G. Zhang, Y . Lu, Z. Wang, Y . Zheng, Tipcb: A simple but effective part-based convolutional baseline for text-based person search, Neurocomputing (2022).doi:10.1016/j.neucom.2022.04.081
-
[14]
Zheng, L
Z. Zheng, L. Zheng, M. Garrett, Y . Yang, M. Xu, Y .-D. Shen, Dual-path convolu- tional image-text embedding with instance loss, ACM Transactions on Multime- dia Computing, Communications, and Applications (2020) 1–23doi:10.1145/ 3383184. 35
2020
-
[15]
Kendall, Y
A. Kendall, Y . Gal, What uncertainties do we need in bayesian deep learning for computer vision?, Advances in neural information processing systems 30 (2017)
2017
-
[16]
Multiscale Vision Transformers , isbn =
F. Warburg, M. Jorgensen, J. Civera, S. Hauberg, Bayesian triplet loss: Un- certainty quantification in image retrieval, in: ICCV , 2021.doi:10.1109/ iccv48922.2021.01194
-
[17]
Y . Chen, Z. Zheng, W. Ji, L. Qu, T.-S. Chua, Composed image retrieval with text feedback via multi-grained uncertainty regularization (2024).arXiv:2211. 07394
2024
-
[18]
Postels, M
J. Postels, M. Segu, T. Sun, L. Gool, F. Yu, F. Tombari, On the practicality of deterministic epistemic uncertainty., arXiv (Jul 2021)
2021
-
[19]
Z. Zheng, Y . Yang, Rectifying pseudo label learning via uncertainty estimation for domain adaptive semantic segmentation, Int. J. Comput. Vision 129 (4) (2021) 1106–1120.doi:10.1007/s11263-020-01395-y
-
[20]
J. Chang, Z. Lan, C. Cheng, Y . Wei, Data uncertainty learning in face recognition, in: CVPR, 2020.doi:10.1109/cvpr42600.2020.00575
- [21]
- [22]
-
[23]
Multiscale Vision Transformers , isbn =
F. Warburg, M. Jørgensen, J. Civera, S. Hauberg, Bayesian triplet loss: Un- certainty quantification in image retrieval, in: ICCV , 2021, pp. 12138–12148. doi:10.1109/ICCV48922.2021.01194
-
[24]
D. J. Marchette, Bayesian networks and decision graphs, Technometrics 45 (2) (2003) 178–179.doi:10.1198/tech.2003.s141
-
[25]
Y . Gal, Z. Ghahramani, Dropout as a bayesian approximation: Representing model uncertainty in deep learning, in: international conference on machine learning, PMLR, 2016, pp. 1050–1059. 36
2016
-
[26]
S. Li, T. Xiao, H. Li, B. Zhou, D. Yue, X. Wang, Person search with natural language description, in: CVPR, 2017.doi:10.1109/cvpr.2017.551
-
[27]
A. Zhu, Z. Wang, Y . Li, X. Wan, J. Jin, T. Wang, F. Hu, G. Hua, Dssl: Deep surroundings-person separation learning for text-based person retrieval, in: ACM Multimedia, MM ’21, Association for Computing Machinery, New York, NY , USA, 2021, p. 209–217.doi:10.1145/3474085.3475369
-
[28]
Z. Ding, C. Ding, Z. Shao, D. Tao, Semantically self-aligned network for text-to- image part-aware person re-identification., arXiv (2021)
2021
-
[29]
W. Li, R. Zhao, T. Xiao, X. Wang, Deepreid: Deep filter pairing neural network for person re-identification, in: 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014.doi:10.1109/cvpr.2014.27
-
[30]
Zheng, L
L. Zheng, L. Shen, L. Tian, S. Wang, J. Bu, Q. Tian, Person re-identification meets image search, arXiv (2015)
2015
-
[31]
T. Xiao, S. Li, B. Wang, L. Li, X. Wang, End-to-end deep learning for person search., arXiv (Apr 2016)
2016
-
[32]
D. Gray, S. Brennan, H. Tao, Evaluating appearance models for recognition, reac- quisition, and tracking, in: PETS, 2007
2007
-
[33]
W. Li, R. Zhao, X. Wang, Human reidentification with transferred metric learning, in: ACCV , Springer, 2013, pp. 31–44
2013
-
[34]
L. Wei, S. Zhang, W. Gao, Q. Tian, Person transfer gan to bridge domain gap for person re-identification, in: CVPR, 2018.doi:10.1109/cvpr.2018.00016
-
[35]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, in: ICCV , 2021.doi: 10.1109/iccv48922.2021.00986
-
[36]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidi- rectional transformers for language understanding (2019).arXiv:1810.04805. 37
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
Loshchilov, F
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, Learn- ing,Learning (Nov 2017)
2017
-
[38]
E. D. Cubuk, B. Zoph, J. Shlens, Q. V . Le, Randaugment: Practical automated data augmentation with a reduced search space, in: CVPR Workshop, 2020.doi: 10.1109/cvprw50498.2020.00359
-
[39]
Z. Zhong, L. Zheng, G. Kang, S. Li, Y . Yang, Random erasing data augmentation, AAAI (2020) 13001–13008doi:10.1609/aaai.v34i07.7000
-
[40]
J. Wei, K. Zou, Eda: Easy data augmentation techniques for boosting perfor- mance on text classification tasks, in: EMNLP-IJCNLP, 2019.doi:10.18653/ v1/d19-1670
2019
-
[41]
K. Niu, Y . Huang, W. Ouyang, L. Wang, Improving description-based person re- identification by multi-granularity image-text alignments, IEEE Transactions on Image Processing 29 (2020) 5542–5556
2020
-
[42]
Z. Wang, A. Zhu, J. Xue, X. Wan, C. Liu, T. Wang, Y . Li, Caibc: Capturing all- round information beyond color for text-based person retrieval, in: ACM MM, 2022.doi:10.1145/3503161.3548057
-
[43]
L. Bao, L. Wei, W. Zhou, L. Liu, L. Xie, H. Li, Q. Tian, Multi-granularity match- ing transformer for text-based person search, IEEE Transactions on Multimedia 26 (2024) 4281–4293.doi:10.1109/TMM.2023.3321504
-
[44]
S. Yan, N. Dong, L. Zhang, J. Tang, CLIP-driven fine-grained text-image person re-identification, IEEE Transactions on Image Processing 32 (2023) 6032–6046. doi:10.1109/TIP.2023.3327924
-
[45]
S. He, H. Luo, W. Jiang, X. Jiang, H. Ding, VGSG: Vision-guided semantic-group network for text-based person search, IEEE Transactions on Image Processing 33 (2024) 163–176.doi:10.1109/TIP.2023.3337653
-
[46]
M. Sun, W. Suo, P. Wang, K. Niu, L. Liu, G. Lin, Y . Zhang, Q. Wu, An adaptive correlation filtering method for text-based person search, Int. J. Comput. Vision 132 (10) (2024) 4440–4455.doi:10.1007/s11263-024-02094-8. 38
-
[47]
M. Cao, Y . Bai, Z. Zeng, M. Ye, M. Zhang, An empirical study of CLIP for text-based person search, AAAI, 2024.doi:10.1609/aaai.v38i1.27801
-
[48]
Z. Lu, R. Lin, H. Hu, Mind the inconsistent semantics in positive pairs: Semantic aligning and multimodal contrastive learning for text-based pedestrian search, IEEE Transactions on Information Forensics and Security 19 (2024) 6409–6424. doi:10.1109/TIFS.2024.3417251
-
[49]
Y . Qin, Y . Chen, D. Peng, X. Peng, J. T. Zhou, P. Hu, Noisy-correspondence learning for text-to-image person re-identification, in: CVPR, 2024, pp. 27187– 27196.doi:10.1109/CVPR52733.2024.02568
-
[50]
T.-H. Nguyen, H.-L. Tran, T. D. Ngo, ITSELF: Attention guided fine-grained alignment for vision–language retrieval (2026).arXiv:2601.01024
- [51]
-
[52]
S. Li, C. He, X. Xu, F. Shen, Y . Yang, H. T. Shen, Adaptive uncertainty-based learning for text-based person retrieval, AAAI 38 (4) (2024) 3172–3180.doi: 10.1609/aaai.v38i4.28101
-
[53]
K. Cheng, W. Zou, H. Gu, A. Ouyang, BAMG: Text-based person re- identification via bottlenecks attention and masked graph modeling, in: ACCV , 2024, pp. 1809–1826.doi:10.1007/978-981-96-0966-6_23
-
[54]
K.-H. Lee, X. Chen, G. Hua, H. Hu, X. He, Stacked cross attention for image-text matching, in: ECCV , 2018. 39
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.