Recognition: 2 theorem links
· Lean TheoremGRASP: Grounded CoT Reasoning with Dual-Stage Optimization for Multimodal Sarcasm Target Identification
Pith reviewed 2026-05-10 18:12 UTC · model grok-4.3
The pith
GRASP uses grounded chain-of-thought reasoning and dual-stage optimization to locate fine-grained sarcasm targets in text and images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
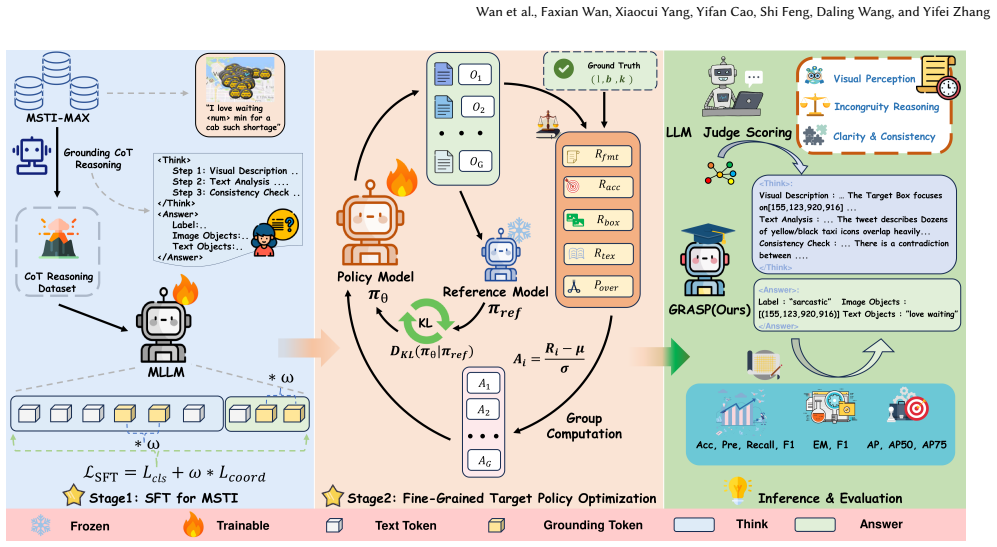
GRASP integrates visual grounding with explicit Chain-of-Thought reasoning that forces the model to anchor sarcasm-related visual regions inside the reasoning trajectory, articulate rationales, and only then predict classification labels and sarcasm targets. A coordinate-aware weighted loss during supervised fine-tuning followed by Fine-Grained Target Policy Optimization produces the final model. This explicit, grounded trajectory replaces the implicit cross-modal alignments used in prior work.
What carries the argument
Grounded CoT reasoning, which explicitly anchors sarcasm-related visual regions within the reasoning trajectory and requires the model to articulate rationales before predicting final labels and targets.
If this is right
- Explicit anchoring of reasoning steps to visual regions improves localization of sarcasm targets beyond what implicit alignment achieves.
- The dual-stage process of supervised fine-tuning with coordinate loss then policy optimization jointly raises both label accuracy and target precision.
- Curating a class-balanced dataset with enriched multimodal cues supports more reliable training for fine-grained identification tasks.
- LLM-as-a-Judge evaluation provides a quantitative check on reasoning-chain quality that can be applied to similar multimodal reasoning setups.
Where Pith is reading between the lines
- The same grounding technique could be tested on related tasks such as detecting irony or humor that span text and images.
- If the reasoning chains remain stable under distribution shift to new social-media sources, the method may scale beyond the curated dataset.
- Pairing the coordinate-aware loss with other visual grounding models might further reduce cases where rationales and targets diverge.
Load-bearing premise
The grounded chain-of-thought steps reliably point to the correct sarcasm-related visual regions rather than producing incorrect or hallucinated rationales that happen to yield right final answers.
What would settle it
Human review of the generated reasoning chains showing frequent anchoring to wrong image regions or inconsistent rationales that still produce correct target labels would falsify the claim that the grounding step drives the performance gain.
Figures




read the original abstract
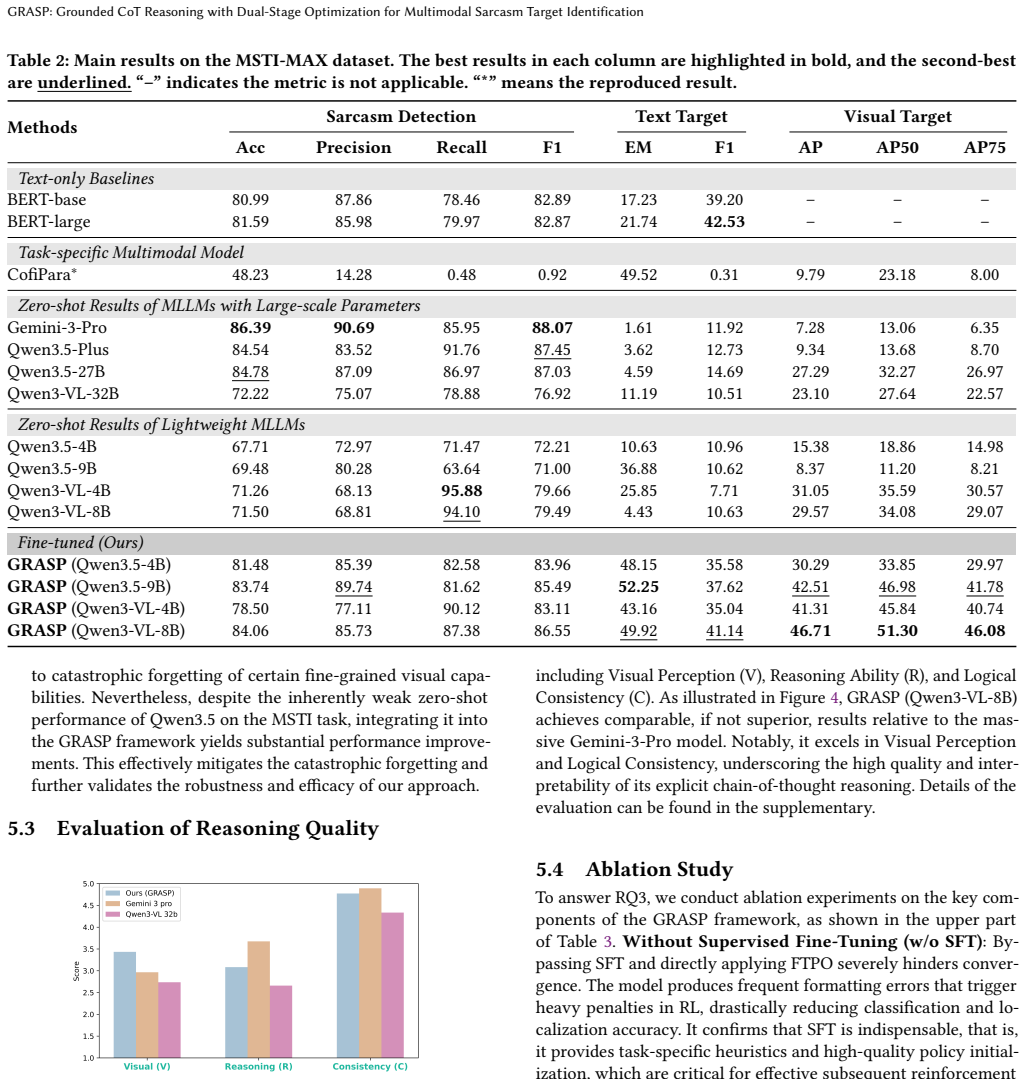
Moving beyond the traditional binary classification paradigm of Multimodal Sarcasm Detection, Multimodal Sarcasm Target Identification (MSTI) presents a more formidable challenge, requiring precise localization of fine-grained targets such as textual phrases and visual regions. Existing approaches predominantly rely on implicit cross-modal alignment, offering limited interpretability and suboptimal fine-grained localization. To address these limitations, we propose GRASP, Grounded Chain-of-Thought ReAsoning with Dual-Stage Optimization for Multimodal Sarcasm Prediction and Target Identification, a framework that integrates visual grounding with explicit Chain-of-Thought (CoT) reasoning to move beyond black-box MSTI. Specifically, we curate MSTI-MAX, a refined dataset that mitigates class imbalance and enriches multimodal sarcasm cues. We introduce Grounded CoT reasoning, which explicitly anchors sarcasm-related visual regions within the reasoning trajectory and prompts the model to articulate rationales before predicting the final classification labels and sarcasm targets. Furthermore, we employ a dual-stage outcome-supervised joint optimization strategy: Supervised Fine-Tuning with a coordinate-aware weighted loss, followed by Fine-Grained Target Policy Optimization. Extensive experiments demonstrate that GRASP outperforms existing baselines in fine-grained sarcasm target identification across modalities, and an LLM-as-a-Judge evaluation quantitatively measures the quality of internal reasoning chains. Our dataset and source code will be released on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
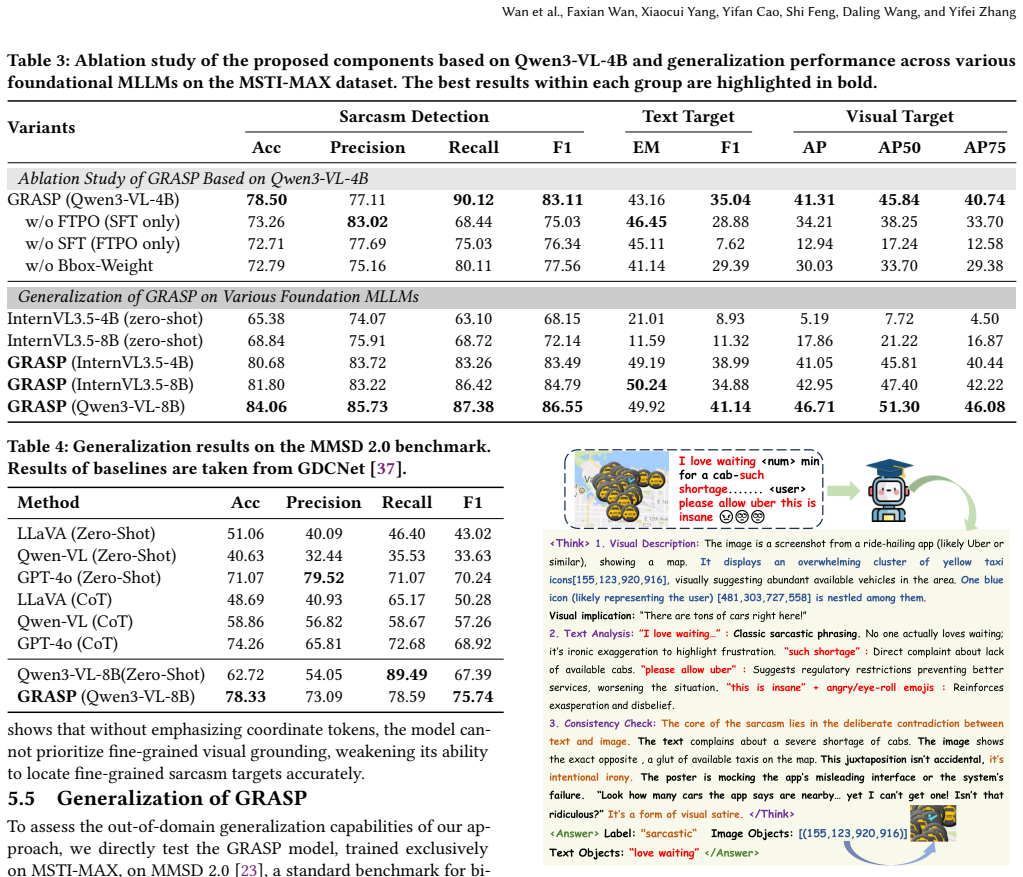
Summary. The paper proposes GRASP, a framework for Multimodal Sarcasm Target Identification (MSTI) that integrates explicit Grounded Chain-of-Thought (CoT) reasoning to anchor sarcasm-related visual regions, combined with a dual-stage optimization (supervised fine-tuning using a coordinate-aware weighted loss followed by Fine-Grained Target Policy Optimization). It introduces the MSTI-MAX dataset to address class imbalance and enrich cues, and claims that GRASP outperforms baselines in fine-grained target identification across modalities while an LLM-as-a-Judge metric quantifies reasoning chain quality.
Significance. If the performance and faithfulness claims hold under rigorous evaluation, the work would advance explainable multimodal reasoning by moving beyond implicit alignment to explicit, grounded CoT trajectories, with potential impact on sarcasm detection and broader multimodal tasks requiring localization and interpretability. The planned release of the dataset and code strengthens reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (dual-stage optimization): the training signal supervises only final labels and coarse coordinates via the coordinate-aware loss and policy optimization; no explicit penalty or verification is described for internally inconsistent or hallucinated intermediate CoT steps, which directly undermines the central claim that Grounded CoT reliably anchors sarcasm-related visual regions without unfaithful rationales.
- [Experiments] Experiments section: the abstract asserts outperformance and introduces quantitative LLM-as-a-Judge evaluation, yet no specific metrics (e.g., accuracy, IoU for targets, ablation results, error bars, or statistical tests) are provided to support the claims, making it impossible to verify the central empirical contribution.
minor comments (1)
- [Method] Notation for the coordinate-aware loss weights and the exact formulation of Fine-Grained Target Policy Optimization should be clarified with equations to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (dual-stage optimization): the training signal supervises only final labels and coarse coordinates via the coordinate-aware loss and policy optimization; no explicit penalty or verification is described for internally inconsistent or hallucinated intermediate CoT steps, which directly undermines the central claim that Grounded CoT reliably anchors sarcasm-related visual regions without unfaithful rationales.
Authors: We acknowledge that the dual-stage optimization is primarily outcome-supervised, with the coordinate-aware weighted loss and Fine-Grained Target Policy Optimization focusing on final labels and target coordinates rather than applying direct penalties to intermediate CoT steps. The Grounded CoT component is intended to promote anchoring through explicit prompting that requires the model to articulate visual region references before prediction. However, we agree that the absence of an explicit consistency check or penalty for hallucinated intermediates represents a limitation in fully substantiating the faithfulness claim. In the revised manuscript, we will expand §3 to describe an additional verification step (e.g., cross-checking CoT outputs against predicted coordinates) and extend the LLM-as-a-Judge protocol to include a dedicated faithfulness score for intermediate reasoning steps. This will be a partial revision. revision: partial
-
Referee: [Experiments] Experiments section: the abstract asserts outperformance and introduces quantitative LLM-as-a-Judge evaluation, yet no specific metrics (e.g., accuracy, IoU for targets, ablation results, error bars, or statistical tests) are provided to support the claims, making it impossible to verify the central empirical contribution.
Authors: We thank the referee for noting this gap in presentation. The full experiments section reports accuracy for sarcasm classification, IoU scores for fine-grained target localization across text and visual modalities, ablation studies on the dual-stage components, and comparisons against baselines, along with the LLM-as-a-Judge quantitative scores. To address the concern directly, we will revise the experiments section to prominently feature these metrics in tables, include error bars on all reported results, add statistical significance tests (e.g., paired t-tests), and ensure all quantitative claims are supported with explicit numbers and ablation details. This will be incorporated as a full revision. revision: yes
Circularity Check
No circularity: empirical engineering contribution with independent experimental validation
full rationale
The paper describes a practical framework (Grounded CoT + dual-stage optimization on a curated dataset) whose performance claims rest on external benchmark comparisons and LLM-as-a-Judge metrics rather than any derivation that reduces outputs to inputs by construction. No equations, uniqueness theorems, or self-citations are invoked to force the central results; the method is presented as an engineering proposal whose value is measured against held-out data and baselines. This is the standard non-circular case for applied ML papers.
Axiom & Free-Parameter Ledger
free parameters (1)
- coordinate-aware loss weights
axioms (1)
- domain assumption Multimodal sarcasm cues can be explicitly localized to textual phrases and visual regions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearGrounded CoT reasoning... dual-stage outcome-supervised joint optimization... SFT with coordinate-aware weighted loss... FTPO with multidimensional rewards (format, accuracy, IoU, exact match)... LLM-as-a-Judge on Visual Perception, Incongruity Reasoning, Logical Consistency
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCoordinate-aware weighted loss... λcoord on bounding-box tokens... Rtotal = β1 Rfmt + β2 Racc + β3 Rbox + β4 Rtxt − β5 Pover
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Saroj Basnet, Shafkat Farabi, Tharindu Ranasinghe, Diptesh Kanojia, and Marcos Zampieri. 2025. Evaluating Open-Source Vision-Language Models for Multi- modal Sarcasm Detection. In2025 IEEE International Conference on Data Mining Workshops (ICDMW). 1442–1447. doi:10.1109/ICDMW69685.2025.00172
-
[5]
Yitao Cai, Huiyu Cai, and Xiaojun Wan. 2019. Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 2506–2515. doi:10.18653/v1/P19-1239
-
[6]
Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmer- mann, Rada Mihalcea, and Soujanya Poria. 2019. Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper). InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computa...
-
[7]
Junjie Chen, Xuyang Liu, Subin Huang, Linfeng Zhang, and Hang Yu. 2025. Seeing Sarcasm Through Different Eyes: Analyzing Multimodal Sarcasm Perception in Large Vision-Language Models.IEEE Transactions on Computational Social Systems(2025), 1–18. doi:10.1109/TCSS.2025.3608484
-
[8]
Zixin Chen, Hongzhan Lin, Ziyang Luo, Mingfei Cheng, Jing Ma, and Guang Chen. 2024. CofiPara: A Coarse-to-fine Paradigm for Multimodal Sarcasm Target Identification with Large Multimodal Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (...
-
[9]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. Intern VL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 24185–2...
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
2019
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incen- tivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[12]
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. 2026. Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models. arXiv:2503.06749 [cs.CV] https://arxiv.org/abs/2503.06749
work page internal anchor Pith review arXiv 2026
- [13]
- [14]
-
[15]
Aditya Joshi, Pranav Goel, Pushpak Bhattacharyya, and Mark Carman. 2018. Sarcasm Target Identification: Dataset and An Introductory Approach. InPro- ceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Nicoletta Calzolari, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Koiti Hasida, Hitoshi ...
2018
-
[16]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. 2024. RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. arXiv:2309.00267 [cs.CL] https://arxiv.org/ abs/2309.00267
- [17]
-
[18]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. InComputer Vision – ECCV 2014, David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars (Eds.). Springer International Publishing, Cham, 740–755
2014
-
[19]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 2511–2522. doi:...
-
[20]
Fengmao Lv, Mengting Xiong, Junlin Fang, Lingli Zhang, Tianze Luo, Weichao Liang, and Tianrui Li. 2025. MSTI-Plus: Introducing Non-Sarcasm Reference Materials to Enhance Multimodal Sarcasm Target Identification. InProceed- ings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 614–62...
-
[21]
Diego Molla and Aditya Joshi. 2019. Overview of the 2019 ALTA Shared Task: Sarcasm Target Identification. InProceedings of the 17th Annual Workshop of the Australasian Language Technology Association, Meladel Mistica, Massimo Piccardi, and Andrew MacKinlay (Eds.). Australasian Language Technology Association, Sydney, Australia, 192–196. https://aclantholo...
2019
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[23]
Libo Qin, Shijue Huang, Qiguang Chen, Chenran Cai, Yudi Zhang, Bin Liang, Wanxiang Che, and Ruifeng Xu. 2023. MMSD2.0: Towards a Reliable Multi- modal Sarcasm Detection System. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toront...
-
[24]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Ste- fano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Wan et al., Faxian Wan, Xiaocui Yang, Yifan Cao, Shi Feng, Daling Wang, and Yifei Zhang Your Language Model is Secretly a Reward Model. InAdvances in Neu- ral Information Processing Systems, A. Oh, T. Naumann, A. G...
2023
-
[25]
Rossano Schifanella, Paloma de Juan, Joel Tetreault, and LiangLiang Cao. 2016. Detecting Sarcasm in Multimodal Social Platforms. InProceedings of the 24th ACM International Conference on Multimedia(Amsterdam, The Netherlands) (MM ’16). Association for Computing Machinery, New York, NY, USA, 1136–1145. doi:10.1145/2964284.2964321
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, and Yi R. Fung. 2025. Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers. arXiv:2506.23918 [cs.CV] https: //arxiv.org/abs/2506.23918
work page internal anchor Pith review arXiv 2025
-
[28]
Binghao Tang, Boda Lin, Haolong Yan, and Si Li. 2024. Leveraging Generative Large Language Models with Visual Instruction and Demonstration Retrieval for Multimodal Sarcasm Detection. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kev...
-
[29]
Qwen Team. 2026. Qwen3.5: Accelerating Productivity with Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5
2026
-
[30]
Qwen Teams. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jiquan Wang, Lin Sun, Yi Liu, Meizhi Shao, and Zengwei Zheng. 2022. Multimodal Sarcasm Target Identification in Tweets. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (Eds.). Association for Computa- tional Linguistics, Dublin, Irel...
-
[32]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Xiaobao Wang, Yujing Wang, Dongxiao He, Zhe Yu, Yawen Li, Longbiao Wang, Jianwu Dang, and Di Jin. 2025. Elevating Knowledge-Enhanced Entity and Rela- tionship Understanding for Sarcasm Detection.IEEE Transactions on Knowledge and Data Engineering37, 6 (2025), 3356–3371. doi:10.1109/TKDE.2025.3547055
-
[34]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171 [cs.CL] https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [35]
-
[36]
Yiwei Wei, Hengyang Zhou, Shaozu Yuan, Meng Chen, Haitao Shi, Zhiyang Jia, Longbiao Wang, and Xiaodong He. 2025. DeepMSD: Advancing Multimodal Sarcasm Detection Through Knowledge-Augmented Graph Reasoning.IEEE Transactions on Circuits and Systems for Video Technology35, 7 (2025), 6413–6423. doi:10.1109/TCSVT.2025.3530436
- [37]
-
[38]
Haochen Zhao, Yongxiu Xu, Xinkui Lin, Jiarui Lu, Hongbo Xu, and Yubin Wang. 2025. EilMoB: Emotion-aware Incongruity Learning and Modality Bridg- ing Network for Multi-modal Sarcasm Detection. InProceedings of the 2025 International Conference on Multimedia Retrieval(Chicago, IL, USA)(ICMR ’25). Association for Computing Machinery, New York, NY, USA, 1868–...
-
[39]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. 2023. Judging LLM- as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neu- ral Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. ...
2023
-
[40]
Ziyang Zhou, Ziqi Liu, Yan Wang, Yiming Lin, and Yangbin Chen. 2026. RAM-SD: Retrieval-Augmented Multi-agent framework for Sarcasm Detection. arXiv:2601.17002 [cs.CL] https://arxiv.org/abs/2601.17002 A Prompt Templates The prompts used in this study are designed to guide the model through various reasoning and generation stages. The following is a detaile...
-
[41]
**FIXED Label**: (0 or 1)
-
[42]
- Note: If the box is`[0, 0, 1000, 1000]`, it means the **WHOLE IMAGE** is relevant
**Target Box**:`[x1, y1, x2, y2]`. - Note: If the box is`[0, 0, 1000, 1000]`, it means the **WHOLE IMAGE** is relevant. - If the box is smaller, it focuses on a specific object. # INSTRUCTION * **DO NOT PREDICT** the label. Just explain WHY the provided label is correct. * **FORCE ALIGNMENT**: - If Label 1 (Sarcastic): Explain the contradiction between th...
-
[43]
- If box is specific: Describe strictly the **object inside the box**
Visual Description: - If box is [0,0,1000,1000]: Describe the **overall scene** and main atmosphere. - If box is specific: Describe strictly the **object inside the box**
-
[44]
Text Analysis: Literal meaning of the tweet
-
[45]
" Image Objects: [...] Text Objects:
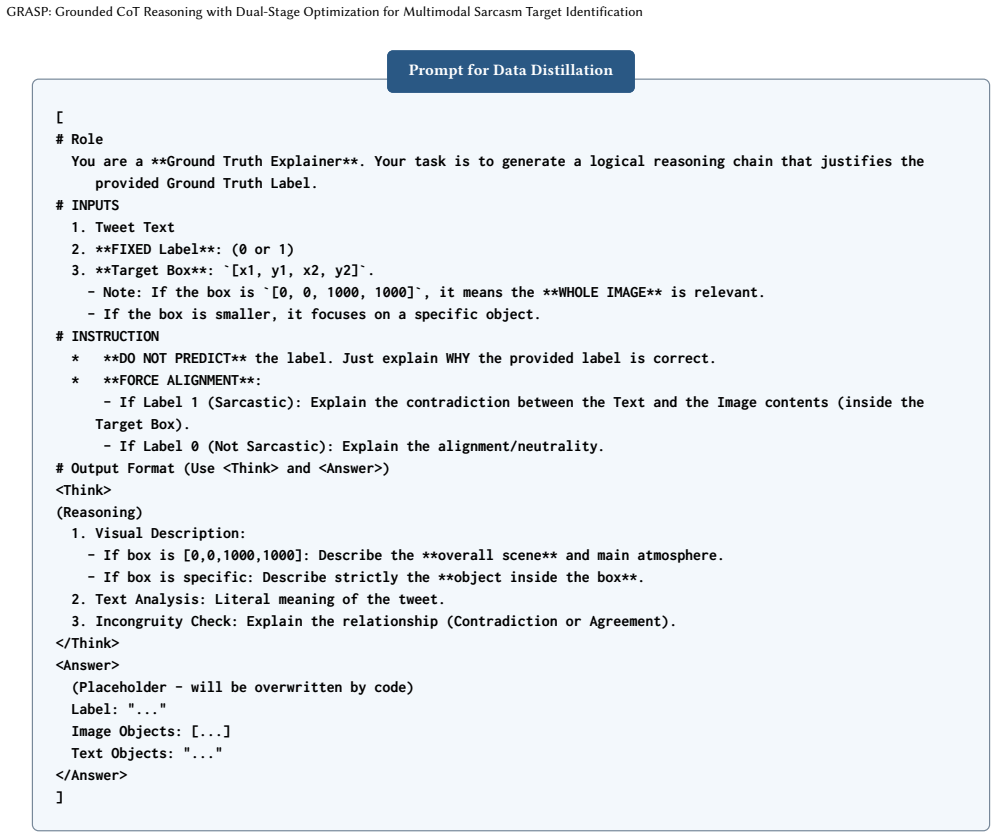
Incongruity Check: Explain the relationship (Contradiction or Agreement). </Think> <Answer> (Placeholder - will be overwritten by code) Label: "..." Image Objects: [...] Text Objects: "..." </Answer> ] Figure 6: Prompt used to distill Grounded CoT reasoning annotations from the teacher model. Wan et al., Faxian Wan, Xiaocui Yang, Yifan Cao, Shi Feng, Dali...
-
[46]
* **CRITICAL**: You MUST append normalized coordinates`[xmin, ymin, xmax, ymax]`(0-1000) immediately after mentioning a relevant object
**Visual grounding**: * List key objects in the image. * **CRITICAL**: You MUST append normalized coordinates`[xmin, ymin, xmax, ymax]`(0-1000) immediately after mentioning a relevant object
-
[47]
**Semantic Analysis**: * Analyze the literal meaning and emotional tone of the tweet text
-
[48]
Does the image support the text, or contradict it?
**Incongruity Check**: * Compare the Visual Reality with the Text Description. * **Explicitly state**: "Does the image support the text, or contradict it?" ## 2. Final Structured Output (<Answer>) Inside`<Answer>`, output ONLY the following valid JSON-like format: Label: "sarcastic" OR "not sarcastic" Image Objects: [(xmin,ymin,xmax,ymax)] Text Objects: "...
-
[49]
sarcastic
**Label**: strictly "sarcastic" or "not sarcastic"
-
[50]
* If the **Whole Scene** or **General Atmosphere** contradicts the text (e.g., bad weather, traffic jam, crowd), use **Full Image Coordinates**:`[(0,0,1000,1000)]`
**Image Objects (Crucial Rules)**: * If a **specific object** contradicts the text, output its bounding box (e.g.,`[(200,300,500,600)]`). * If the **Whole Scene** or **General Atmosphere** contradicts the text (e.g., bad weather, traffic jam, crowd), use **Full Image Coordinates**:`[(0,0,1000,1000)]`. * If not sarcastic, output`[(0,0,0,0)]`or empty brackets`[]`
-
[51]
* If not sarcastic, output`""`
**Text Objects**: * Extract only the 1-3 keywords triggering the irony. * If not sarcastic, output`""`. ] Figure 7: Prompt used during inference for grounded multimodal sarcasm reasoning and structured prediction. GRASP: Grounded CoT Reasoning with Dual-Stage Optimization for Multimodal Sarcasm Target Identification Prompt for LLM-as-a-Judge Evaluation [ ...
-
[52]
Ground Truth: Label=[{gt_label}], Box(0-1000)=[{gt_boxes}], Words=[{gt_words}]
-
[53]
V": <int>,
Model Output: {model_response} [Scoring 1-5] - V_Score (Visual): 1=hallucinated/missed GT box, 3=superficial, 5=perfectly identified GT objects. - R_Score (Reasoning): 1=wrong logic, 3=shallow textual analysis, 5=deep text-image contradiction analysis matching GT. - C_Score (Consistency): 1=conclusion contradicts reasoning, 5=perfectly aligned. Output pur...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.