Recognition: unknown
Uncertainty-Aware Transformers: Conformal Prediction for Language Models
Pith reviewed 2026-05-10 17:21 UTC · model grok-4.3
The pith
Conformal prediction applied to transformer embeddings produces statistically valid prediction sets and improves accuracy on small language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CONFIDE constructs class-conditional nonconformity scores from [CLS] embeddings or flattened hidden states of encoder-only transformers and feeds them into the standard conformal prediction pipeline. This yields prediction sets with finite-sample validity guarantees plus per-instance explanations. On BERT-tiny the method raises test accuracy by up to 4.09 percent and improves correct efficiency over NM2 and VanillaNN baselines; early and intermediate layers frequently produce more reliable calibration than the final layer.
What carries the argument
Class-conditional nonconformity scores built from [CLS] token embeddings or flattened hidden states inside the CONFIDE framework for conformal prediction on transformer models.
If this is right
- Transformer models can supply users with both a prediction and a small set of alternatives that is guaranteed to contain the true label at a chosen rate.
- Early and intermediate layers become preferred sources for uncertainty estimation rather than the final classification head.
- Hyperparameter choices can be tuned jointly with the conformal procedure without breaking coverage guarantees.
- High-stakes tasks with label ambiguity gain instance-level explanations that softmax probabilities do not supply.
Where Pith is reading between the lines
- The same embedding-based nonconformity construction could be tested on decoder-only or encoder-decoder models by extracting comparable internal states.
- Layer selection for calibration might become a standard diagnostic step when deploying transformers in safety-critical pipelines.
- Combining CONFIDE sets with human review could reduce error rates in ambiguous domains more effectively than either alone.
Load-bearing premise
The class-conditional nonconformity scores derived from the embeddings satisfy the exchangeability condition needed for conformal prediction to deliver valid coverage.
What would settle it
A new dataset or task where the empirical coverage of the CONFIDE prediction sets falls below the nominal level or where the accuracy gain over softmax baselines disappears entirely.
Figures



























read the original abstract
Transformers have had a profound impact on the field of artificial intelligence, especially on large language models and their variants. However, as was the case with neural networks, their black-box nature limits trust and deployment in high-stakes settings. For models to be genuinely useful and trustworthy in critical applications, they must provide more than just predictions: they must supply users with a clear understanding of the reasoning that underpins their decisions. This article presents an uncertainty quantification framework for transformer-based language models. This framework, called CONFIDE (CONformal prediction for FIne-tuned DEep language models), applies conformal prediction to the internal embeddings of encoder-only architectures, like BERT and RoBERTa, while enabling hyperparameter tuning. CONFIDE uses either [CLS] token embeddings or flattened hidden states to construct class-conditional nonconformity scores, enabling statistically valid prediction sets with instance-level explanations. Empirically, CONFIDE improves test accuracy by up to 4.09% on BERT-tiny and achieves greater correct efficiency (i.e., the expected size of the prediction set conditioned on it containing the true label) compared to prior methods, including NM2 and VanillaNN. We show that early and intermediate transformer layers often yield better-calibrated and more semantically meaningful representations for conformal prediction. In resource-constrained models and high-stakes tasks with ambiguous labels, CONFIDE offers robustness and interpretability where softmax-based uncertainty fails. We position CONFIDE as a framework for practical diagnostic and efficiency/robustness improvement over prior conformal baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CONFIDE, a conformal prediction framework for fine-tuned encoder-only transformers (BERT, RoBERTa). It constructs class-conditional nonconformity scores from [CLS] embeddings or flattened hidden states, permits hyperparameter tuning and layer selection, and claims to deliver statistically valid prediction sets together with instance-level explanations. Empirically, CONFIDE is reported to raise test accuracy by up to 4.09 % on BERT-tiny and to improve correct efficiency relative to NM2 and VanillaNN baselines; early and intermediate layers are said to yield better-calibrated representations.
Significance. If the coverage guarantees are rigorously established and the efficiency gains prove robust across standard splits, the work would supply a practical route to uncertainty quantification and interpretability for transformer models in high-stakes settings where softmax probabilities are insufficient. The emphasis on internal representations rather than output logits is a potentially useful extension of conformal methods to deep language models.
major comments (3)
- [Abstract and §3] Abstract and §3 (Methods): The claim of statistically valid prediction sets rests on the standard conformal theorem, yet the manuscript permits hyperparameter tuning and layer selection “for better performance.” No explicit statement confirms that these choices were fixed before the calibration set was examined or that they were performed on a separate validation split, which would violate the fixed-nonconformity-function requirement.
- [§4] §4 (Experiments): The abstract reports accuracy and efficiency gains, but the text supplies no description of data splits, whether the calibration set overlaps with training data, or any diagnostic that verifies marginal coverage (1-α) is attained. Without these details the empirical claims cannot be assessed for validity.
- [§3.2] §3.2 (Score construction): Class-conditional nonconformity scores are built from [CLS] embeddings or flattened hidden states. The paper invokes the generic CP guarantee but provides neither a proof nor an ablation showing that the chosen score function preserves exchangeability once the underlying transformer has been trained on related data; dependence introduced by the embedding extractor could invalidate the coverage guarantee.
minor comments (2)
- [Abstract] Define “correct efficiency” (expected set size conditioned on containing the true label) at first use and state its relation to standard efficiency metrics.
- [§4] Add a short table or paragraph listing the exact hyper-parameters tuned and the ranges searched, even if they were chosen on a held-out validation set.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, providing clarifications and indicating revisions to the manuscript where appropriate to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): The claim of statistically valid prediction sets rests on the standard conformal theorem, yet the manuscript permits hyperparameter tuning and layer selection “for better performance.” No explicit statement confirms that these choices were fixed before the calibration set was examined or that they were performed on a separate validation split, which would violate the fixed-nonconformity-function requirement.
Authors: We agree that the nonconformity function must remain fixed prior to inspecting the calibration set. In our experiments, layer selection and all hyperparameters were determined exclusively on a held-out validation split that is completely disjoint from the calibration and test sets. We have revised §3 to explicitly document this two-stage procedure (validation for tuning, followed by fixed nonconformity scores on calibration) and updated §4 with the exact split ratios to confirm compliance with the conformal theorem. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract reports accuracy and efficiency gains, but the text supplies no description of data splits, whether the calibration set overlaps with training data, or any diagnostic that verifies marginal coverage (1-α) is attained. Without these details the empirical claims cannot be assessed for validity.
Authors: We appreciate the need for greater transparency. The original text in §4 indicated standard held-out splits but lacked explicit percentages and coverage verification. We have expanded §4 with a dedicated paragraph describing the train/calibration/test partitioning (calibration drawn from training data but non-overlapping with test), and added a new table and figure reporting empirical coverage rates across all datasets, models, and α levels, confirming they are statistically consistent with the target 1-α. revision: yes
-
Referee: [§3.2] §3.2 (Score construction): Class-conditional nonconformity scores are built from [CLS] embeddings or flattened hidden states. The paper invokes the generic CP guarantee but provides neither a proof nor an ablation showing that the chosen score function preserves exchangeability once the underlying transformer has been trained on related data; dependence introduced by the embedding extractor could invalidate the coverage guarantee.
Authors: The transformer is trained on a separate training partition and then frozen; the embedding extractor therefore constitutes a fixed, deterministic function when conformal scores are subsequently computed. Because the calibration and test instances remain exchangeable, the resulting nonconformity scores inherit exchangeability. We have added a clarifying paragraph in §3.2 stating this reasoning and included an ablation (new Table X) that reports coverage for embeddings from early, intermediate, and late layers, showing the guarantee holds in practice. A full proof beyond the standard CP theorem is not supplied, as the fixed-model setting reduces to the classical case. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper applies the standard conformal prediction framework to nonconformity scores derived from transformer embeddings ([CLS] or flattened hidden states). The coverage guarantee is invoked from the general CP theorem rather than derived from the paper's own fitted quantities or self-citations. No equations reduce the prediction sets, efficiency metrics, or layer-selection benefits to a definitional loop or to a parameter fitted on the same data used for the reported test accuracy. Hyperparameter tuning is mentioned as an enabled feature but is not shown to be performed on evaluation data in a way that creates a self-referential construction. The empirical claims are presented as experimental outcomes, not as derivations that collapse back to the inputs by construction. The derivation chain therefore remains independent of the paper's own results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard exchangeability assumption for conformal prediction to guarantee coverage
Reference graph
Works this paper leans on
-
[1]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Anastasios N. Angelopoulos and Stephen Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification.arXiv preprint arXiv:2107.07511,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URLhttps://doi.org/ 10.5194/gmd-16-1601-2023. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec- tional transformers for language understanding.arXiv preprint arXiv:1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5194/gmd-16-1601-2023 2023
-
[3]
Neil Dey, Jing Ding, Jack Ferrell, Carolina Kapper, Maxwell Lovig, Emiliano Planchon, and Jonathan P Williams. Conformal prediction for text infilling and part-of-speech prediction.arXiv preprint arXiv:2111.02592,
-
[4]
Dhillon, George Deligiannidis, and Tom Rainforth
Guneet S. Dhillon, George Deligiannidis, and Tom Rainforth. On the expected size of conformal prediction sets, 2024a. URLhttps://arxiv.org/abs/2306.07254. Guneet S. Dhillon, George Deligiannidis, and Tom Rainforth. On the expected size of conformal prediction sets. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors,Proceedings of The 27th Interna...
-
[5]
Universal language model fine-tuning for text classification
URLhttps://proceedings.mlr.press/v152/giovannotti21a.html. Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification.arXiv preprint arXiv:1801.06146,
- [6]
-
[7]
Sarthak Jain and Byron C. Wallace. Attention is not explanation.arXiv preprint arXiv:1902.10186,
work page Pith review arXiv 1902
-
[8]
I. T. Jolliffe and J. Cadima. Principal component analysis: A review and recent developments.Philosoph- ical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065): 20150202, Apr
2065
-
[9]
On the societal impact of open foundation models
Sayash Kapoor, Rishi Bommasani, et al. On the societal impact of open foundation models. arXiv:2404.15958,
-
[10]
19 Benjamin Leblanc and Pascal Germain
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/ file/ce9e92e3de2372a4b93353eb7f3dc0bd-Paper-Datasets_and_Benchmarks.pdf. 19 Benjamin Leblanc and Pascal Germain. On the relationship between interpretability and explainability in machine learning.arXiv preprint arXiv:2311.11491,
-
[11]
arXiv preprint arXiv:2406.05332 , year=
Junghwan Lee, Chen Xu, and Yao Xie. Transformer conformal prediction for time series.arXiv preprint arXiv:2406.05332,
- [12]
-
[13]
Journal of the American Statistical Association , volume =
doi: 10.1080/01621459.2012.751873. URLhttps://doi. org/10.1080/01621459.2012.751873. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.arXiv preprint arXiv:1907.11692,
-
[14]
Deep conformal prediction for robust models
Samir Messoudi, Sylvie Rousseau, and Sébastien Destercke. Deep conformal prediction for robust models. InInformation Processing and Management of Uncertainty in Knowledge-Based Systems (IPMU 2020), volume 1237 ofCommunications in Computer and Information Science, pages 528–540. Springer,
2020
-
[15]
Deep k-nearest neighbors: Towards confident, inter- pretable and robust deep learning
URLhttps://openai.com/research/ gpt-4o-system-card. Nicolas Papernot and Patrick McDaniel. Deep k-nearest neighbors: Towards confident, interpretable and robust deep learning.arXiv preprint arXiv:1803.04765,
-
[16]
Understanding softmax confidence and uncertainty.arXiv preprint arXiv:2106.04972,
Tim Pearce, Alexandra Brintrup, and Jun Zhu. Understanding softmax confidence and uncertainty.arXiv preprint arXiv:2106.04972,
-
[17]
doi: 10.48550/arXiv.2106.04972. J. Ross Quinlan. Induction of decision trees.Machine Learning, 1(1):81–106,
-
[18]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683,
work page internal anchor Pith review arXiv 1910
-
[19]
Mauricio Sadinle, Jing Lei, and Larry Wasserman
URLhttps://arxiv.org/abs/2006.02544. Mauricio Sadinle, Jing Lei, and Larry Wasserman. Least ambiguous set-valued classifiers with bounded error levels.Journal of the American Statistical Association, 114(525):223–234, June
-
[20]
M., KUCUKELBIR, A., MCAULIFFE, J
ISSN 1537-274X. doi: 10.1080/01621459.2017.1395341. URLhttp://dx.doi.org/10.1080/01621459.2017.1395341. Glenn Shafer and Vladimir Vovk. A tutorial on conformal prediction.Journal of Machine Learning Research, 9(12):371–421,
-
[21]
Daniel Sikar, Artur d’Avila Garcez, and Tillman Weyde
URLhttp://jmlr.org/papers/v9/shafer08a.html. Daniel Sikar, Artur d’Avila Garcez, and Tillman Weyde. Explorations of the softmax space: Knowing when the neural network doesn’t know...arXiv preprint arXiv:2502.00456,
-
[22]
Axiomatic Attribution for Deep Networks, June 2017
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks.arXiv preprint arXiv:1703.01365,
-
[23]
URLhttps://doi.org/10.1186/s12911-024-02444-z. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.arXiv preprint arXiv:1706.03762,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1186/s12911-024-02444-z
-
[24]
doi: 10.1007/b106715. URLhttps://link.springer.com/book/10.1007/ b106715. Vladimir Vovk, Valentina Fedorova, Ilia Nouretdinov, and Alex Gammerman. Criteria of efficiency for conformal prediction.CoRR, abs/1603.04416,
-
[25]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R
URLhttp://arxiv.org/abs/1603.04416. Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding.arXiv preprint arXiv:1804.07461,
-
[26]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems.arXiv preprint arXiv:1905.00537,
work page internal anchor Pith review arXiv 1905
-
[27]
arXiv preprint arXiv:1908.04626 , year=
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation.arXiv preprint arXiv:1908.04626,
-
[28]
Over 9,000 training examples, but highly noisy and linguis- tically ambiguous
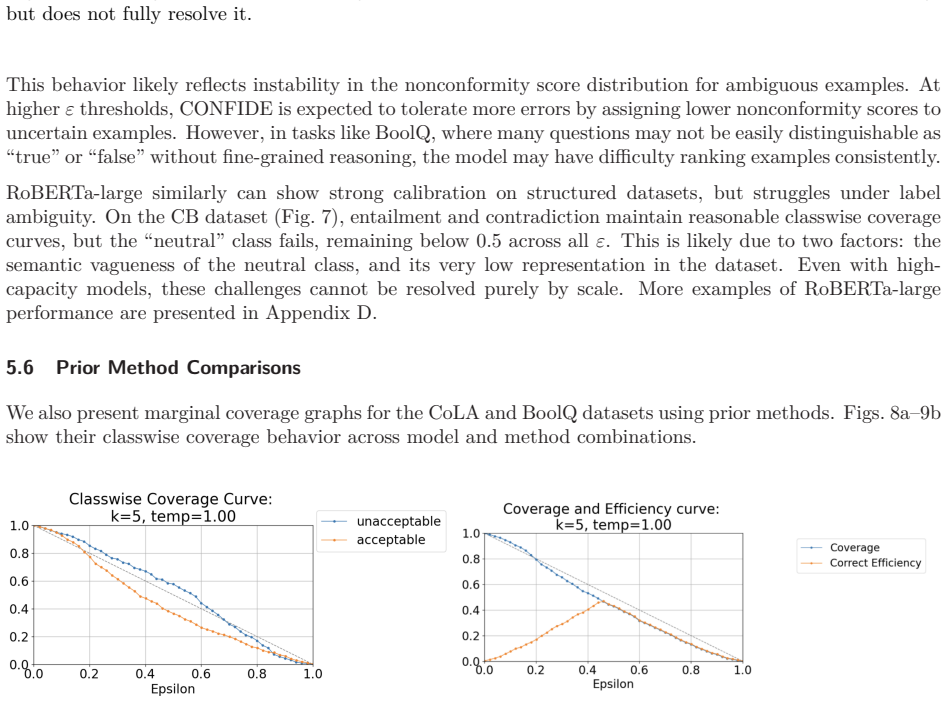
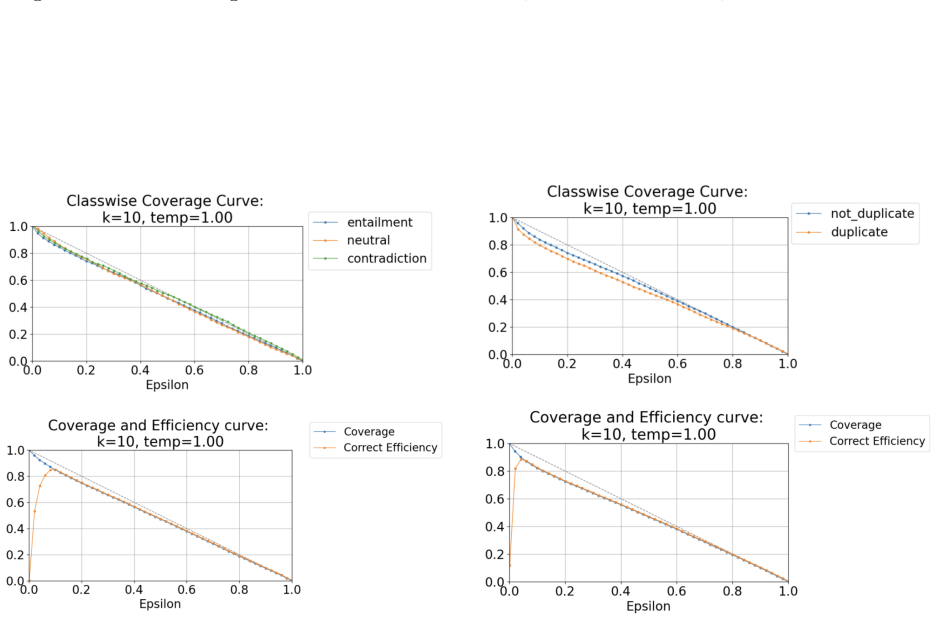
•BoolQ (Boolean Questions):Binary QA task requiring yes/no answers to naturally occurring queries paired with Wikipedia passages. Over 9,000 training examples, but highly noisy and linguis- tically ambiguous. •CB (CommitmentBank):Three-class NLI task with only∼250 training examples. Requires fine- grained reasoning over implicatures in short discourse con...
2025
-
[29]
Trends are monotonic on SST-2 and QNLI; they are nearly flat on MRPC, where the small training set limits variation in nearest-neighbor search time across layers. We also compare per- example latency across model sizes on MRPC (Table 11); as expected, RoBERTa-base has higher average latency than BERT-tiny. Dataset∆calibration time / block (s)∆test time / ...
-
[30]
We observe a strong match between coverage and correct efficiency across mostϵvalues in the QNLI task usingBERT-tiny, especially whenclasswisecalibrated. This suggeststhat evenwith a limited modelcapacity, the learned representations in QNLI provide sufficient semantic separation between the “entailment” and “not-entailment” classes. QNLI tends to involve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.