Recognition: 2 theorem links
· Lean TheoremOmakase: proactive assistance with actionable suggestions for evolving scientific research projects
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
An AI research assistant that monitors project documents generates timely queries and converts long reports into significantly more actionable suggestions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that monitoring project documents allows the system to infer a user's latent information needs, issue appropriate queries to a deep research system, and then distill the resulting long reports into suggestions that are contextualized to the current state of the evolving project.
What carries the argument
Document monitoring to infer queries combined with report distillation into contextualized actionable suggestions.
Load-bearing premise
That a user's project documents contain enough information to reliably infer their current latent needs without missing key context or generating off-target queries.
What would settle it
If a follow-up study with researchers shows no significant difference in rated actionability between the distilled suggestions and the original full reports, or if many generated queries are judged irrelevant to the actual project needs.
Figures





read the original abstract
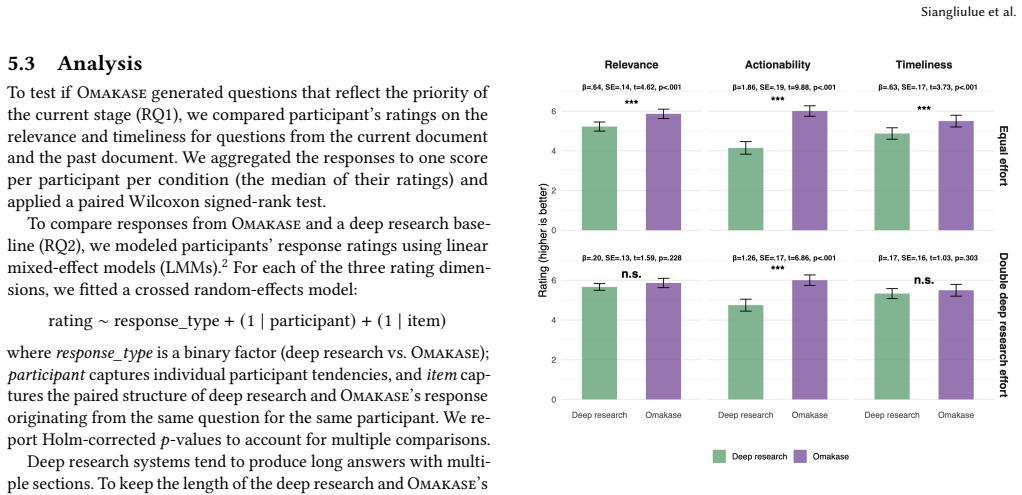
As AI agents become increasingly capable of complex knowledge tasks, the lack of context limits their capability to proactively reason about a user's latent needs throughout a long evolving project. In scientific research, many researchers still manually query a deep research system and compress their rich project contexts into short, targeted queries. Further, a deep research system produces exhaustive reports, making it difficult to identify concrete actions. To explore the opportunities of research assistants that are proactive throughout a research project, we conducted several studies (N=42) with a technology probe and an iterative prototype. The latest iteration of our system, Omakase, is a research assistant that monitors a user's project documents to infer timely queries to a deep research system. Omakase then distills long reports into suggestions contextualized to their evolving projects. Our evaluations showed that participants found the generated queries to be useful and timely, and rated Omakase's suggestions as significantly more actionable than the original reports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Omakase, a proactive research assistant that monitors a user's evolving project documents to infer timely queries to a deep research system and then distills the resulting exhaustive reports into contextualized, actionable suggestions. The authors describe an iterative design process using a technology probe and prototype, followed by evaluations with N=42 participants that found the generated queries useful and timely and the distilled suggestions significantly more actionable than the original reports.
Significance. If the empirical claims are substantiated with full study details, this work could meaningfully advance proactive AI assistance in scientific research by tackling context loss and actionability gaps in long-running projects. The technology-probe approach and focus on document-driven inference offer a concrete design pattern that could inform future systems, provided the inference reliability is better validated.
major comments (2)
- [Evaluation] Evaluation section (and abstract): The central claim that participants rated Omakase suggestions as 'significantly more actionable' than original reports is load-bearing for the contribution, yet no study design details, condition descriptions, statistical tests, p-values, effect sizes, or participant breakdown are reported. This prevents assessment of whether the result is robust or could be explained by phrasing, expectation effects, or lack of controls.
- [System Description and Evaluation] System and Evaluation sections: The assumption that document monitoring reliably infers latent needs (without missing evolving context or generating irrelevant queries) is not directly tested via ground-truth comparisons, precision/recall against researcher-stated needs, or longitudinal checks across project iterations. Positive subjective ratings alone do not establish this inference reliability, which underpins the proactive assistance claim.
minor comments (2)
- [Abstract] Abstract: The phrasing 'several studies (N=42)' leaves unclear how participants and tasks were distributed across the technology probe and iterative prototype phases.
- [Discussion] The manuscript would benefit from explicit discussion of potential failure modes, such as when project documents are sparse or contain conflicting information.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important areas for strengthening the substantiation of our claims. We respond to each major comment below and commit to revisions that address the identified gaps without overstating the current evidence.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): The central claim that participants rated Omakase suggestions as 'significantly more actionable' than original reports is load-bearing for the contribution, yet no study design details, condition descriptions, statistical tests, p-values, effect sizes, or participant breakdown are reported. This prevents assessment of whether the result is robust or could be explained by phrasing, expectation effects, or lack of controls.
Authors: We agree that the submitted manuscript insufficiently detailed the evaluation methodology supporting the actionability claim. In the revised version, we will substantially expand the Evaluation section (and adjust the abstract accordingly) to include: full study design descriptions, explicit condition details (e.g., presentation of raw reports vs. distilled suggestions, task instructions given to participants), the statistical tests employed (including whether paired or independent, parametric or non-parametric), exact p-values, effect sizes, and a participant breakdown (N=42 demographics, research domains, and experience levels). We will also discuss steps taken to mitigate confounds such as phrasing biases and expectation effects (e.g., counterbalancing, neutral framing). These additions will allow readers to evaluate the robustness of the findings. revision: yes
-
Referee: [System Description and Evaluation] System and Evaluation sections: The assumption that document monitoring reliably infers latent needs (without missing evolving context or generating irrelevant queries) is not directly tested via ground-truth comparisons, precision/recall against researcher-stated needs, or longitudinal checks across project iterations. Positive subjective ratings alone do not establish this inference reliability, which underpins the proactive assistance claim.
Authors: We acknowledge that the evaluation of query inference relied on subjective ratings of usefulness and timeliness from the technology probe and prototype studies rather than objective ground-truth measures such as precision/recall or explicit longitudinal tracking of context evolution. The N=42 participants were active researchers who reviewed inferred queries against their own project documents over iterative sessions, providing real-world feedback that informed system refinements. However, we did not perform formal precision/recall analyses or multi-iteration ground-truth comparisons. In the revision, we will add an explicit Limitations subsection discussing this gap and its implications for the proactive assistance claim. We will also elaborate on the probe study protocol to clarify how participant feedback served as a form of validation. While the subjective data from domain experts offers initial support, we agree that stronger objective validation would be valuable and note this as an avenue for future work. revision: partial
Circularity Check
No circularity: claims rest on independent user ratings from external participants
full rationale
The paper presents a technology probe and iterative prototype evaluated via user studies (N=42) where participants rate generated queries for usefulness/timeliness and compare actionability of suggestions vs. raw reports. No mathematical derivations, equations, fitted parameters, or predictions appear in the abstract or described methodology. Central claims rely on external human judgments rather than any self-referential fitting, self-citation load-bearing premises, or renaming of known results. The evaluation design uses participant feedback as an independent benchmark, satisfying the criteria for a self-contained, non-circular HCI study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Users maintain project documents that reflect their evolving research needs
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Omakase monitors a user’s project documents to infer timely queries to a deep research system. Omakase then distills long reports into suggestions contextualized to their evolving projects.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our evaluations showed that participants found the generated queries to be useful and timely, and rated Omakase's suggestions as significantly more actionable than the original reports.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
not novel enough
Osama Mohammed Afzal, Preslav Nakov, Tom Hope, and Iryna Gurevych. 2026. Beyond" not novel enough": Enriching scholarly critique with llm-assisted feed- back. InProceedings of the 19th Conference of the European Chapter of the Associ- ation for Computational Linguistics (Volume 1: Long Papers). 2648–2671
2026
-
[2]
2026.NotebookLM
Alphabet. 2026.NotebookLM. https://notebooklm.google.com/
2026
-
[3]
2026.Stitch
Alphabet. 2026.Stitch. https://stitch.withgoogle.com/
2026
-
[4]
2026.Claude Code
Anthropic. 2026.Claude Code. https://www.anthropic.com/
2026
-
[5]
T. Babaian, B. Grosz, and Stuart M. Shieber. 2002. A writer’s collaborative assistant.International Conference on Intelligent User Interfaces(2002), 7–14. doi:10.1145/502716.502722
-
[6]
Nishant Balepur, Malachi Hamada, Varsha Kishore, Sergey Feldman, Amanpreet Singh, Pao Siangliulue, Joseph Chee Chang, Eunsol Choi, Jordan Lee Boyd- Graber, and Aakanksha Naik. 2026. Language Models Don’t Know What You Want: Evaluating Personalization in Deep Research Needs Real Users. https: //api.semanticscholar.org/CorpusID:286579566
2026
-
[7]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psy- chology.Qualitative Research in Psychology3, 2 (2006), 77–101. doi:10.1191/ 1478088706qp063oa
2006
- [8]
-
[9]
Valerie Chen, Alan Zhu, Sebastian Zhao, Hussein Mozannar, David Sontag, and Ameet Talwalkar. 2024. Need Help? Designing Proac- tive AI Assistants for Programming. https://www.semanticscholar. org/paper/Need-Help-Designing-Proactive-AI-Assistants-for-Chen- Zhu/dfc1d15965300c9e632822b3ff8cb90653f1e35b
2024
- [10]
-
[11]
Thomas H Costello, Gordon Pennycook, and David Rand. 2025. Just the facts: How dialogues with AI reduce conspiracy beliefs.Preprint at https://osf. io/preprints/psyarxiv/h7n8u(2025)
2025
-
[12]
Yang Deng, Wenqiang Lei, Hongru Wang, and Tat-seng Chua. 2023. Prompting and Evaluating Large Language Models for Proactive Dialogues: Clarification, Target-guided, and Non-collaboration.Conference on Empirical Methods in Natu- ral Language Processing(2023). doi:10.48550/arXiv.2305.13626
- [13]
-
[14]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Alan Car- roll, Kavita Kulkarni, Nenad Tomašev, Yuan Guan, Vi...
work page internal anchor Pith review arXiv 2025
-
[15]
Dany Haddad, Daniel Bareket, Joseph Chee Chang, Jay DeYoung, Jena D. Hwang, Uri Katz, Mark Polak, Sangho Suh, Harshit Surana, Aryeh Tiktinsky, Shriya Atmakuri, Jonathan Bragg, Mike D’Arcy, Sergey Feldman, Amal Hassan-Ali, Ruben Lozano, Bodhisattwa Prasad Majumder, C. Mcgrady, Amanpreet Singh, Brooke Vlahos, Yoav Goldberg, and Doug Downey. 2026. Understand...
2026
-
[16]
Heckerman and E
D. Heckerman and E. Horvitz. 1998. Inferring Informational Goals from Free-Text Queries: A Bayesian Approach. https://www.semanticscholar. org/paper/Inferring-Informational-Goals-from-Free-Text-A-Heckerman- Horvitz/f764ab7f2c4821056c3ee0a38ee538ac36f766b0
1998
-
[17]
Eric Horvitz. 1999. Principles of mixed-initiative user interfaces. InProceedings of the SIGCHI conference on Human Factors in Computing Systems. 159–166
1999
-
[18]
Tenghao Huang, Sihao Chen, Muhao Chen, Jonathan May, Longqi Yang, Mengting Wan, and Pei Zhou. 2025. Teaching Language Models To Gather Information Proactively. https://www.semanticscholar.org/paper/ b284e0b3c5e09079253f025a664fb476d2e65bda
2025
-
[19]
Nanna Inie, Jonas Frich, and P. Dalsgaard. 2022. How Researchers Manage Ideas. Proceedings of the 14th Conference on Creativity and Cognition(2022), 83–96. doi:10.1145/3527927.3532813
-
[20]
Peter Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bha- vana Dalvi, Bodhisattwa Prasad Majumder, Daniel S Weld, and Peter Clark. 2025. Codescientist: End-to-end semi-automated scientific discovery with code-based experimentation. InFindings of the Association for Computational Linguistics: ACL 2025. 13370–13467
2025
-
[21]
Peiling Jiang, Jude Rayan, Steven P. Dow, and Haijun Xia. 2023. Graphologue: Exploring Large Language Model Responses with Interactive Diagrams. InPro- ceedings of the 36th Annual ACM Symposium on User Interface Software and Technology(San Francisco, CA, USA)(UIST ’23). Association for Computing Ma- chinery, New York, NY, USA, Article 3, 20 pages. doi:10....
-
[22]
Hyeonsu B Kang, Rafal Kocielnik, Andrew Head, Jiangjiang Yang, Matt Latzke, Aniket Kittur, Daniel S Weld, Doug Downey, and Jonathan Bragg. 2022. From Who You Know to What You Read: Augmenting Scientific Recommendations with Implicit Social Networks. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. doi:10.1145/3491102.3517470
-
[23]
Hyeonsu B Kang, Sherry Wu, Joseph Chee Chang, and A. Kittur. 2023. Synergi: A Mixed-Initiative System for Scholarly Synthesis and Sensemaking.Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (2023). doi:10.1145/3586183.3606759
-
[24]
Rodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chan- drasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David W. Graham, F.Q. Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, ...
-
[25]
Koskela, Petri Luukkonen, Tuukka Ruotsalo, Mats Sjöberg, and P
M. Koskela, Petri Luukkonen, Tuukka Ruotsalo, Mats Sjöberg, and P. Floréen
-
[26]
Proactive Information Retrieval by Capturing Search Intent from Primary Task Context.ACM Transactions on Interactive Intelligent Systems (TiiS)8, 3 (2018), 1–25. doi:10.1145/3150975 12 Omakase: proactive assistance with actionable suggestions for evolving scientific research projects
-
[27]
Ivica Kostric, Krisztian Balog, and Ujwal Gadiraju. [n. d.]. Should We Tailor the Talk? Understanding the Impact of Conversational Styles on Preference Elicitation in Conversational Recommender Systems. ([n. d.])
- [28]
-
[29]
Yoonjoo Lee, Hyeonsu B Kang, Matt Latzke, Juho Kim, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. 2024. Paperweaver: Enriching topical paper alerts by contextualizing recommended papers with user-collected papers. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
2024
-
[30]
Shuyue Stella Li, Jimin Mun, Faeze Brahman, Jonathan Ilgen, Y. Tsvetkov, and Maarten Sap. 2025. ALFA: Aligning LLMs to Ask Good Questions A Case Study in Clinical Reasoning. http://arxiv.org/abs/2502.14860
-
[31]
Zhehui Liao, Maria Antoniak, Inyoung Cheong, Evie Yu-Yen Cheng, Ai-Heng Lee, Kyle Lo, Joseph Chee Chang, and Amy X Zhang. 2025. Llms as research tools: A large scale survey of researchers’ usage and perceptions.Colm(2025)
2025
-
[32]
Tianjian Liu, Hongzheng Zhao, Yuheng Liu, Xingbo Wang, and Zhenhui Peng
-
[33]
Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(2024), 1–22
ComPeer: A Generative Conversational Agent for Proactive Peer Support. Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(2024), 1–22. doi:10.1145/3654777.3676430
-
[35]
Xingyu Bruce Liu, Shitao Fang, Weiyan Shi, Chien-Sheng Wu, Takeo Igarashi, and Xiang ’Anthony’ Chen. 2025. Proactive Conversational Agents with Inner Thoughts. InProceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 184, 19 pages. doi:10.1145/3706598.3713760
-
[36]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery.arXiv preprint arXiv:2408.06292(2024)
work page internal anchor Pith review arXiv 2024
-
[37]
M. C. P. Melguizo, L. Boves, A. Deshpande, and O. M. Ramos. 2007. A proactive recommendation system for writing: helping without disrupting.European Conference on Cognitive Ergonomics(2007), 89–95. doi:10.1145/1362550.1362569
- [38]
-
[39]
Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2024. Read- ing Between the Lines: Modeling User Behavior and Costs in AI-Assisted Pro- gramming. Association for Computing Machinery, 1–16. doi:10.1145/3613904. 3641936
-
[40]
Hussein Mozannar, Gagan Bansal, Cheng Tan, Adam Fourney, Victor Dibia, Jingya Chen, Jack Gerrits, Tyler Payne, Matheus Kunzler Maldaner, Madeleine Grunde-McLaughlin, Eric Zhu, Griffin Bassman, Jacob Alber, Peter Chang, Ricky Loynd, Friederike Niedtner, Ece Kamar, Maya Murad, Rafah Hosn, and Saleema Amershi. 2025. Magentic-UI: Towards Human-in-the-loop Age...
-
[41]
Newendorp, Mohammad Hadi Sanaei, Arthur J
Amanda K. Newendorp, Mohammad Hadi Sanaei, Arthur J. Perron, Hila Sabouni, Nikoo Javadpour, Maddie Sells, Katherine Nelson, Michael C. Dorneich, and Stephen B. Gilbert. 2024. Apple’s Knowledge Navigator: Why Doesn’t that Conversational Agent Exist Yet?Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems(2024). https://api.semantics...
2024
-
[42]
2026.Codex
OpenAI. 2026.Codex. https://openai.com/codex/
2026
-
[43]
Deep Anil Patel, Iain Melvin, Christopher Malon, and Martin Renqiang Min
-
[44]
https:// www.semanticscholar.org/paper/DiscussLLM%3A-Teaching-Large-Language- Models-When-to-Patel-Melvin/bb7c9c13b9b5b3ccc144931575dbcb33c7936568
DiscussLLM: Teaching Large Language Models When to Speak. https:// www.semanticscholar.org/paper/DiscussLLM%3A-Teaching-Large-Language- Models-When-to-Patel-Melvin/bb7c9c13b9b5b3ccc144931575dbcb33c7936568
-
[45]
Bigham, and Amy Pavel
Yi-Hao Peng, Dingzeyu Li, Jeffrey P. Bigham, and Amy Pavel. 2025. Morae: Proactively Pausing UI Agents for User Choices.Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology(2025). https://api. semanticscholar.org/CorpusID:280985324
2025
-
[46]
Savvas Petridis, Michael Xieyang Liu, Alexander J Fiannaca, Carrie J Cai, and Michael Terry. 2026. Compass vs Railway Tracks: Unpacking User Mental Models for Communicating Long-Horizon Work to Humans vs. AI.arXiv preprint arXiv:2601.11848(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Kevin Pu, KJ Kevin Feng, Tovi Grossman, Tom Hope, Bhavana Dalvi Mishra, Matt Latzke, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. 2025. Ideasynth: Iterative research idea development through evolving and composing idea facets with literature-grounded feedback. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–31
2025
-
[48]
Kevin Pu, Daniel Lázaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support.Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems(2025). doi:10.1145/ 3706598.3713357
- [49]
-
[50]
Omar Shaikh, Shardul Sapkota, Syed Rizvi, Eric Horvitz, Joon Sung Park, Diyi Yang, and Michael S. Bernstein. 2025. Creating General User Models from Com- puter Use. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. doi:10.1145/3746059.3747722
-
[51]
Robinson, Nilàm Ram, Byron Reeves, Sherry Yang, Michael S
Omar Shaikh, Valentin Teutschbein, Kanishk Gandhi, Yikun Chi, Nick Haber, Thomas N. Robinson, Nilàm Ram, Byron Reeves, Sherry Yang, Michael S. Bern- stein, and Diyi Yang. 2026. Learning Next Action Predictors from Human- Computer Interaction. https://api.semanticscholar.org/CorpusID:286365419
2026
-
[52]
Amanpreet Singh, Joseph Chee Chang, Dany Haddad, Aakanksha Naik, Jena D Hwang, Rodney Kinney, Daniel S Weld, Doug Downey, and Sergey Feldman. 2025. Ai2 scholar qa: Organized literature synthesis with attribution. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). 513–523
2025
-
[53]
Amanpreet Singh, Mike D’Arcy, Arman Cohan, Doug Downey, and Sergey Feld- man. 2023. SciRepEval: A Multi-Format Benchmark for Scientific Document Representations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[54]
Ayah Soufan, Ian Ruthven, and Leif Azzopardi. 2022. Searching the literature: An analysis of an exploratory search task. InProceedings of the 2022 conference on human information interaction and retrieval. 146–157
2022
-
[55]
Lu Sun, Aaron Chan, Yun Seo Chang, and Steven P. Dow. 2024. ReviewFlow: Intelligent Scaffolding to Support Academic Peer Reviewing.Proceedings of the 29th International Conference on Intelligent User Interfaces(2024). https: //api.semanticscholar.org/CorpusID:267499858
2024
-
[56]
Anfu Tang, Laure Soulier, and Vincent Guigue. 2025. Clarifying Ambiguities: on the Role of Ambiguity Types in Prompting Methods for Clarification Generation. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(2025). doi:10.1145/3726302.3729922
-
[57]
Kelly B Wagman, Matthew T Dearing, and Marshini Chetty. 2025. Generative AI uses and risks for knowledge workers in a science organization. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–17
2025
-
[58]
Ruotong Wang, Xinyi Zhou, Lin Qiu, Joseph Chee Chang, Jonathan Bragg, and Amy X. Zhang. 2025. PaperPing: A Socially-aware AI Agent that Recommends Academic Papers to Research Group Chats with Contextualized Explanations. In CSCW Companion. doi:10.1145/3715070.3757230
-
[59]
Ruotong Wang, Xinyi Zhou, Lin Qiu, Joseph Chee Chang, Jonathan Bragg, and Amy X. Zhang. 2025. Social-RAG: Retrieving from Group Interactions to Socially Ground AI Generation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 162, 25 pages. doi:10.1145/3...
-
[60]
Mengke Wu, Weizi Liu, Yanyun Wang, Weiyu Ding, and Mike Yao. 2026. Rethink- ing User Empowerment in AI Recommender System: Innovating Transparent and Controllable Interfaces. arXiv:2509.11098 [cs.HC] https://arxiv.org/abs/2509. 11098
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, and Zhenyu Yan. 2025. Con- textAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions.ArXiv(2025). doi:10.48550/arXiv.2505.14668
-
[62]
cc/paper_files/paper/2022/file/ 82ad13ec01f9fe44c01cb91814fd7b8c-Paper-Conference
Xuan Zhang, Yang Deng, Zifeng Ren, See-Kiong Ng, and Tat-Seng Chua. 2024. Ask-before-Plan: Proactive Language Agents for Real-World Planning.ArXiv (2024). doi:10.48550/arXiv.2406.12639 AOmakase’s extra details A.1 Implementation details We implementedOmakaseas a web application. The backend was implemented in Python using Flask for an HTTP server. The fro...
-
[63]
A short excerpt from a research project document where a paper is mentioned (or the surrounding context)
-
[64]
The paper's title and abstract
-
[65]
project relation
An optional "project relation" -- how the author of the document described or implied the paper's relevance to the project. Write a summary (1-2 sentences) that summarizes how this paper relates to the research project. Use the document context, the stated or implied relation, and the paper's content (title and abstract) to produce a concise, accurate sum...
-
[67]
The question should not be too complicated to accommodate a deep research agent that can't answer complicated questions yet
Generate relevant questions: Create a list of questions that, when answered by consulting prior work, would provide information that is useful for the researcher in the current stage of the project. The question should not be too complicated to accommodate a deep research agent that can't answer complicated questions yet. These questions should be: a) Rel...
-
[68]
question
Prioritize the questions: Order the questions from most useful to least useful, considering their potential impact on improving the research project at its current stage. Present your analysis as structured output with: - project_state: The inferred project state (a string). - why_project_state: Briefly explain your reasoning for inferring this project st...
-
[69]
How it relates to the current project state and goals
-
[70]
What specific value answering it would provide
-
[71]
How it compares in importance to the other questions
-
[72]
How likely will it be answerable by prior work
-
[73]
{project_state}
How it differs from other candidate questions (avoid clustering similar questions in the final set) </scratchpad> 18 Omakase: proactive assistance with actionable suggestions for evolving scientific research projects After your analysis, provide your final ranking. For each question in your ranked list, briefly explain why you placed it at that position a...
-
[82]
Second, carefully analyze the answer and consider how the information could be applied in various research contexts
If a paper is mentioned, you MUST use the EXACT original label as provided in citation_labels Remember, your summary should be concise yet informative, focusing on the most relevant and important information for the research project. Second, carefully analyze the answer and consider how the information could be applied in various research contexts. Genera...
-
[83]
Strengthening a claim in a research document with more documents
-
[85]
Providing ideas for solutions, methods, baselines, datasets, evaluation, or experimental design based on the current stage of a research project
-
[86]
For each suggestion:
Anchor the researcher on "why" this suggestion in the context of their project by pointing back to specific part of the research document. For each suggestion:
-
[88]
Provide at least one associated paper label (use all relevant papers if multiple apply)
-
[90]
Include relevant information from the paper(s) that supports or relates to the suggestion 19 Siangliulue et al
-
[91]
(For example, if the project is already in the paper writing stage, it is unreasonable to suggest the researcher to redesign the experiment)
Make sure that the suggestion is timely. (For example, if the project is already in the paper writing stage, it is unreasonable to suggest the researcher to redesign the experiment). Here are some topics that could be of interested for each state: - Ideation: The researcher is coming up with ideas for their project. They would want to know the novelty and...
-
[93]
ALWAYS provide citations to any information (e.g., claim, clause, method) that is from a paper with sources
-
[94]
If a paper is mentioned, you MUST use the EXACT original label as provided in citation_labels
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.