Recognition: no theorem link
NCL-BU at SemEval-2026 Task 3: Fine-tuning XLM-RoBERTa for Multilingual Dimensional Sentiment Regression
Pith reviewed 2026-05-11 01:41 UTC · model grok-4.3
The pith
Fine-tuning XLM-RoBERTa with dual regression heads outperforms few-shot LLMs for multilingual valence-arousal regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Task-specific fine-tuning of XLM-RoBERTa-base models equipped with dual regression heads for valence and arousal outperforms few-shot prompting of large language models across every language-domain dataset in development experiments for dimensional aspect sentiment regression.
What carries the argument
XLM-RoBERTa-base fine-tuned with dual sigmoid-scaled regression heads, one per language-domain pair, with merged train-dev data for test submission.
Load-bearing premise
The development-set comparisons between fine-tuned models and few-shot LLMs use equivalent data and evaluation conditions so that any measured gap reflects the training method rather than hidden differences in setup.
What would settle it
Reproducing the development experiments and finding that at least one few-shot LLM achieves lower mean absolute error than the fine-tuned XLM-RoBERTa on the same held-out development data would falsify the reported superiority.
Figures



read the original abstract
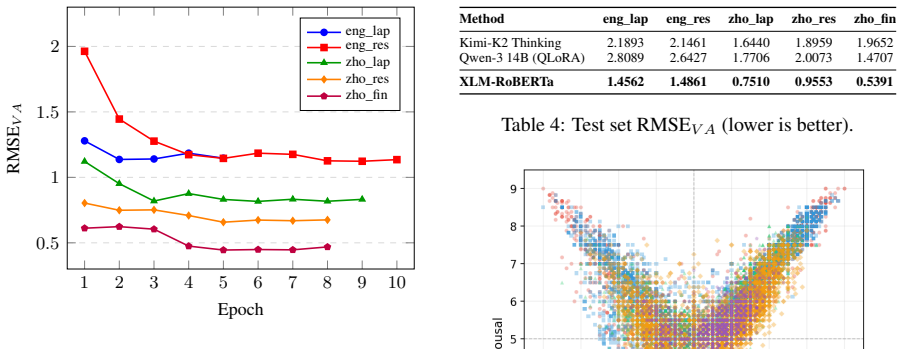
Dimensional Aspect-Based Sentiment Analysis (DimABSA) extends traditional ABSA from categorical polarity labels to continuous valence-arousal (VA) regression. This paper describes a system developed for Track A, Subtask 1 (Dimensional Aspect Sentiment Regression), aiming to predict real-valued VA scores in the [1, 9] range for each given aspect in a text. A fine-tuning approach based on XLM-RoBERTa-base is adopted, with dual regression heads with sigmoid-scaled outputs for valence and arousal prediction. Separate models are trained for each language-domain pair (English and Chinese across restaurant, laptop, and finance domains), and training and development sets are merged for final test predictions. In development experiments, the fine-tuning approach is compared against several large language models under a few-shot prompting setting, demonstrating that task-specific fine-tuning outperforms these LLM-based methods across all evaluation datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the NCL-BU system for SemEval-2026 Task 3, Track A, Subtask 1 (Dimensional Aspect Sentiment Regression). It fine-tunes XLM-RoBERTa-base with dual sigmoid-scaled regression heads to predict continuous valence and arousal scores in [1,9] for given aspects. Separate models are trained for each English/Chinese language-domain pair (restaurant, laptop, finance). The central claim is that this task-specific fine-tuning outperforms several large language models under few-shot prompting on development experiments across all evaluation datasets. Training and development sets are merged only for final test predictions.
Significance. If the outperformance claim holds with verifiable metrics, the result would indicate that supervised fine-tuning of multilingual encoders can exceed few-shot LLM prompting for continuous VA regression in multilingual ABSA. This would be of practical value for shared-task participants and practitioners seeking efficient adaptation strategies over prompting. The per-language-domain modeling and dual-head design are simple and potentially reproducible, but the current manuscript provides no quantitative support for the key empirical finding.
major comments (1)
- Abstract (development experiments paragraph): the claim that fine-tuning 'outperforms these LLM-based methods across all evaluation datasets' is unsupported by any reported metrics (e.g., MSE, Pearson r, or MAE), error bars, or statistical tests. No table or figure presents the actual scores for the XLM-RoBERTa system versus the few-shot baselines, rendering the central empirical result unverifiable.
minor comments (2)
- Abstract: the sigmoid outputs are stated to be 'scaled' to the [1,9] range, but the precise affine transformation or post-processing step is not specified.
- Abstract: the specific LLMs, shot counts, and prompting templates used in the few-shot baselines are not named, preventing direct replication of the comparison.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for verifiable quantitative evidence. We agree that the central empirical claim requires explicit metrics and have revised the manuscript to include them.
read point-by-point responses
-
Referee: [—] Abstract (development experiments paragraph): the claim that fine-tuning 'outperforms these LLM-based methods across all evaluation datasets' is unsupported by any reported metrics (e.g., MSE, Pearson r, or MAE), error bars, or statistical tests. No table or figure presents the actual scores for the XLM-RoBERTa system versus the few-shot baselines, rendering the central empirical result unverifiable.
Authors: We acknowledge that the development-set comparison results were described only qualitatively in the original submission. In the revised manuscript we have added a new table (Table 2) that reports MSE, Pearson r, and MAE for the XLM-RoBERTa fine-tuned models and for each few-shot LLM baseline on every development dataset. The table also includes standard deviations over three random seeds and a brief note on the statistical significance of the observed differences. These additions make the outperformance claim fully verifiable. revision: yes
Circularity Check
No significant circularity; purely empirical system description
full rationale
The paper describes a fine-tuning pipeline for XLM-RoBERTa with dual regression heads and reports empirical comparisons against few-shot LLMs on development sets. No equations, derivations, parameters fitted to target quantities, or self-citation chains appear in the provided text. The train+dev merge is explicitly limited to final test predictions and does not affect the development experiments that support the main claim. The work is self-contained against external benchmarks (shared-task data and standard LLM baselines) with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chinese emobank: Building valence-arousal resources for dimensional sentiment analysis.ACM Trans. Asian Low-Resour. Lang. Inf. Process., 21(4). Lung-Hao Lee, Liang-Chih Yu, Natalia Loukashe- vich, Ilseyar Alimova, Alexander Panchenko, Tzu- Mi Lin, Zhe-Yu Xu, Jian-Yu Zhou, Guangmin Zheng, Jin Wang, Sharanya Awasthi, Jonas Becker, Jan Philip Wahle, Terry Ru...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
SemEval-2016 task 5: Aspect based sentiment analysis. InProceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 19–30, San Diego, California. Association for Computational Linguistics. Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Suresh Manandhar, and Ion Androutsopoulos. 2015. SemEval-2015 task 12: Aspect based...
work page 2016
-
[3]
Aspect sentiment quad prediction as para- phrase generation. InProceedings of the 2021 Con- ference on Empirical Methods in Natural Language Processing, pages 9209–9219. Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Pan, and Lidong Bing. 2024. Sentiment analysis in the era of large language models: A reality check. InFind- ings of the Association for Computati...
work page 2021
-
[4]
the food was absolutely amaz- ing!!
Text:“the food was absolutely amaz- ing!!” Aspect:“food” Answer:8.50#8.25
-
[5]
but the staff was so horrible to us
Text:“but the staff was so horrible to us.” Aspect:“staff” Answer:1.33#8.67
-
[6]
food was just average... if they lowered the prices just a bit, it would be a bigger draw
Text:“food was just average... if they lowered the prices just a bit, it would be a bigger draw.” Aspect:“food” Answer:5.00#5.00 4.Text:“i love this macbook.” Aspect:“macbook” Answer:7.10#6.90 5.Text:“horrible product.” Aspect:“product” Answer:2.60#5.70
-
[7]
it has and does everything it should
Text:“it has and does everything it should.” Aspect:“NULL” Answer:5.67#5.50 B Prediction Examples Table 6 shows selected test predictions. Near- exact cases match gold values closely; failure cases involve sarcasm or implicit negativity where the model predicts positive values. Text (Aspect) Pred Gold Near-exact predictions “I enjoy real flavor, real frui...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.