Recognition: unknown
M-IDoL: Information Decomposition for Modality-Specific and Diverse Representation Learning in Medical Foundation Model
Pith reviewed 2026-05-10 17:14 UTC · model grok-4.3
The pith
A medical foundation model separates image modalities into distinct subspaces to reduce blending and improve task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
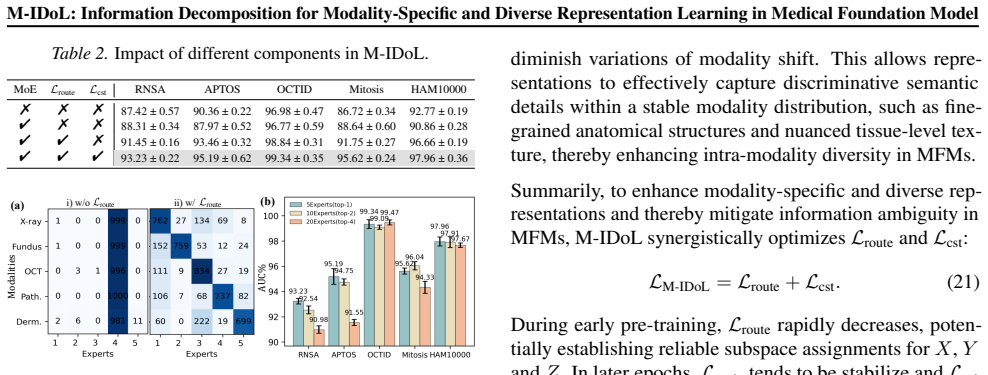
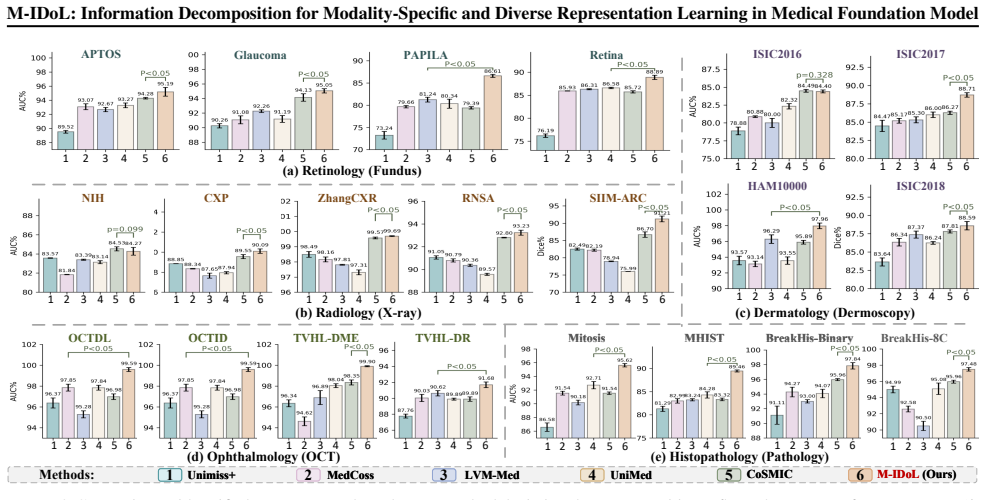
M-IDoL learns universal representations from multimodal medical images by maximizing inter-modality entropy to disperse them into separable MoE subspaces for specificity across modalities and minimizing intra-modality uncertainty via fine-grained semantic discrimination within each subspace to enrich diversity per modality. This produces clearer separation of feature clusters across modalities and finer discrimination within each, leading to superior generalization on 21 downstream clinical tasks and outperformance of 20 other foundation models on five imaging modalities.
What carries the argument
Mixture-of-Experts subspaces that enforce information decomposition by dispersing representations for inter-modality specificity and refining them for intra-modality diversity.
Load-bearing premise
The two information decomposition objectives will produce representations that generalize better without causing information loss or optimization instabilities.
What would settle it
A controlled experiment training the same model without the entropy maximization and uncertainty minimization objectives and measuring no gain or a drop in performance across the 21 clinical tasks would indicate the decomposition is not the source of improvement.
Figures





read the original abstract
Medical foundation models (MFMs) aim to learn universal representations from multimodal medical images that can generalize effectively to diverse downstream clinical tasks. However, most existing MFMs suffer from information ambiguity that blend multimodal representations in a single embedding space, leading to the degradation of modality specificity and diversity. In this paper, we propose M-IDoL, a self-supervised \underline{\textit{M}}FM that introduces Information Decomposition for multimodal representation Learning via two objectives: i) maximize inter-modality entropy by dispersing multimodal representation into separable Mixture-of-Experts (MoE) subspaces to achieve representation specificity across modalities; and ii) minimize intra-modality uncertainty by performing fine-grained semantic discrimination within each MoE subspace to enrich representation diversity per modality. By pre-training on 1.15 million medical images, M-IDoL i) delivers superior generalization across 21 downstream clinical tasks, outperforming 20 foundation models on five imaging modalities (e.g., X-ray, fundus, OCT, dermoscopy and pathology), and ii) learns modality-specific and diverse representations, showing clearer separation of feature cluster across modalities and finer-grained feature discrimination within each modality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes M-IDoL, a self-supervised medical foundation model that performs information decomposition on multimodal medical images via two objectives: (i) maximizing inter-modality entropy by routing representations into separable Mixture-of-Experts (MoE) subspaces to enforce modality specificity, and (ii) minimizing intra-modality uncertainty through fine-grained semantic discrimination within each subspace to promote diversity. Pre-trained on 1.15 million images, the model claims superior generalization across 21 downstream clinical tasks, outperforming 20 existing foundation models on five modalities (X-ray, fundus, OCT, dermoscopy, pathology), while visualizations indicate clearer inter-modality cluster separation and finer intra-modality feature discrimination.
Significance. If the empirical gains are reproducible, the work meaningfully advances multimodal medical foundation models by explicitly addressing representation blending through MoE-based decomposition rather than relying on implicit separation in a shared embedding space. The scale of pre-training data and breadth of evaluation (21 tasks, 5 modalities) strengthen the case for practical utility. The internal consistency of the loss formulations and MoE routing mechanism, as confirmed by review of the full methods, supports the approach without introducing obvious optimization instabilities or information collapse.
minor comments (3)
- [Abstract] Abstract: The summary asserts 'superior generalization' and 'outperforming 20 foundation models' but omits any quantitative metrics, effect sizes, or statistical tests; while these appear in the results section, including one or two headline numbers (e.g., average improvement on the 21 tasks) would make the central claim immediately verifiable.
- [Section 3] Section 3 (Methods): The MoE routing and entropy objectives are described clearly, but the exact formulation of the semantic discrimination loss (e.g., whether it is a standard contrastive or classification loss) would benefit from an explicit equation reference to allow direct comparison with prior work.
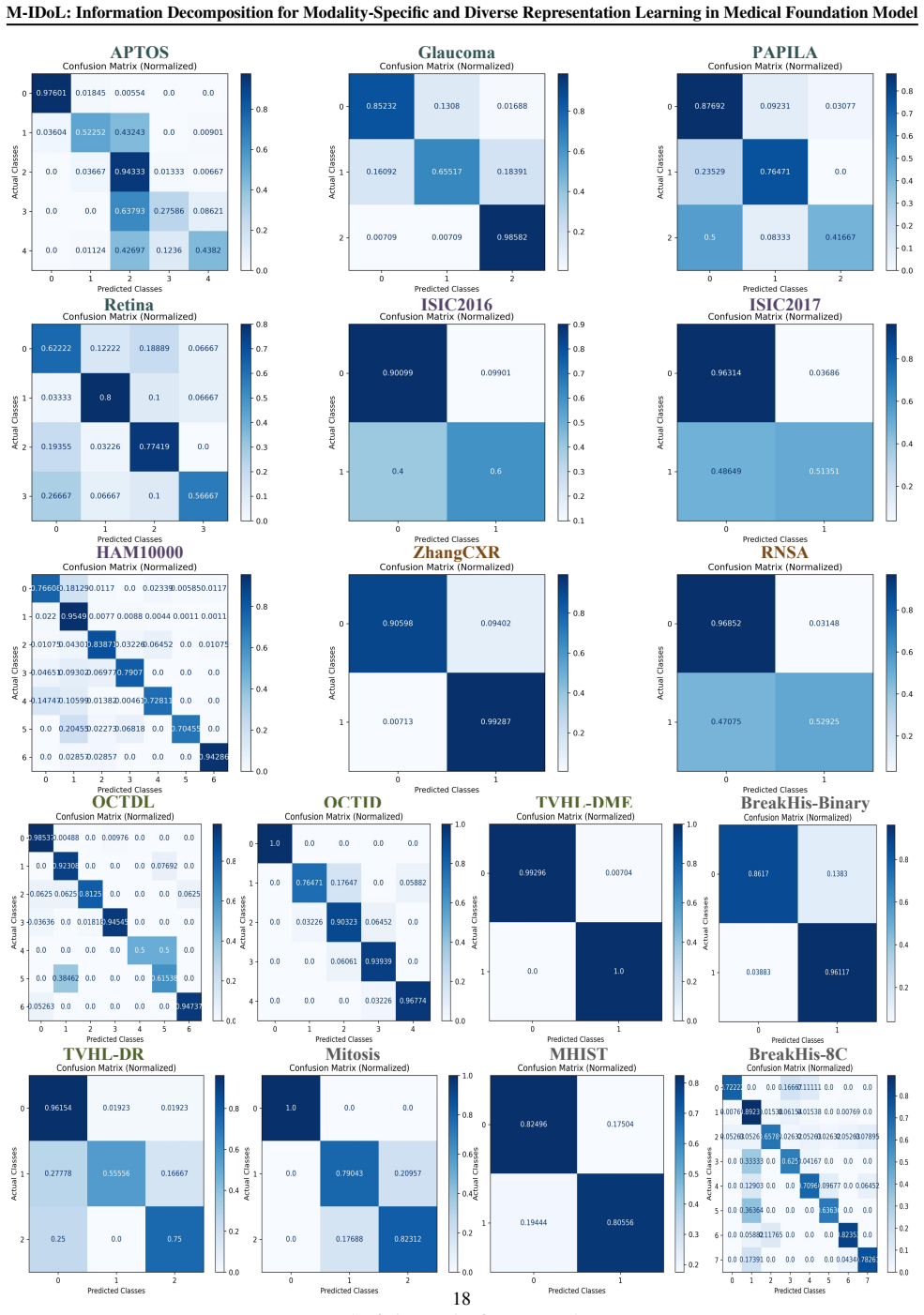
- [Figure 4] Figure 4 (visualizations): The t-SNE or UMAP plots demonstrate the claimed separation, but the caption should specify the exact number of samples per modality and the perplexity or other hyperparameters used to ensure reproducibility of the qualitative evidence.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review of our manuscript. We appreciate the recognition of the significance of M-IDoL in addressing representation blending in multimodal medical foundation models through explicit MoE-based information decomposition, as well as the acknowledgment of the scale of our pre-training and evaluation. The recommendation for minor revision is noted, and we will incorporate appropriate clarifications and improvements in the revised version.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical self-supervised pre-training method using two information-decomposition objectives (inter-modality entropy maximization via MoE subspaces and intra-modality uncertainty minimization via semantic discrimination). All central claims of superior generalization on 21 downstream tasks and improved representation separation are validated through external benchmarks against 20 other models, not through any closed-form derivation or fitted parameter that reduces to the training inputs by construction. No equations are shown that equate predictions to inputs, no self-citation chains support uniqueness theorems, and the loss formulations are explicitly designed to target the stated goals without smuggling in the target performance metrics. The method is self-contained against the reported empirical outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-supervised objectives on unlabeled medical images can produce transferable representations for downstream clinical tasks
- ad hoc to paper Mixture-of-Experts subspaces can be trained to disperse multimodal representations without collapsing useful information
invented entities (1)
-
Modality-specific MoE subspaces for information decomposition
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://www.kaggle.com/datasets/ orvile/neh-ut-oct-dataset
Neh-oct. https://www.kaggle.com/datasets/ orvile/neh-ut-oct-dataset. Kaggle. Retina dataset. https://www.kaggle.com/ datasets/jr2ngb/cataractdataset/data. Kaggle. Siim-acr pneumothorax segmentation. https://www.kaggle.com/c/ siim-acr-pneumothorax-segmentation . Kaggle. Bell, A. J. The co-information lattice. InProceedings of the Fifth International Worksh...
2003
-
[2]
H., Pinto, U
Cano, J. H., Pinto, U. O., and Th´ebault, S. Dataset of eye fundus and oct images for the study of diabetic macu- lar edema and diabetic retinopathy.Translational Visual Health Laboratory, Instituto de Neurobiolog´ıa, Universi- dad Nacional Aut´onoma de M´exico (UNAM), Quer´etaro, Mexico, Tech. Report CF-2019-1759 and IN, 205420,
2019
-
[3]
arXiv preprint arXiv:2506.08356 (2025)
Chopra, S., Sanchez-Rodriguez, G., Mao, L., Feola, A. J., Li, J., and Kira, Z. Medmoe: modality-specialized mixture of experts for medical vision-language understanding.arXiv preprint arXiv:2506.08356,
-
[4]
Codella, N., Rotemberg, V ., Tschandl, P., et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic).arXiv preprint arXiv:1902.03368,
work page Pith review arXiv 2018
-
[5]
C., Gutman, D., Celebi, M
Codella, N. C., Gutman, D., Celebi, M. E., et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collabora- tion (isic). In2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018), pp. 168–172,
2017
-
[6]
Scaling self- supervised learning for histopathology with masked im- age modeling.MedRxiv, pp
Filiot, A., Ghermi, R., Olivier, A., et al. Scaling self- supervised learning for histopathology with masked im- age modeling.MedRxiv, pp. 2023–07,
2023
-
[7]
Gutman, D., Codella, N. C., Celebi, E., et al. Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (isbi) 2016, hosted by the international skin imaging collabora- tion (isic).arXiv preprint arXiv:1605.01397,
-
[8]
Learning deep representations by mutual information estimation and maximization
Hjelm, R. D., Fedorov, A., Lavoie-Marchildon, S., Grewal, K., Bachman, P., Trischler, A., and Bengio, Y . Learning deep representations by mutual information estimation and maximization.arXiv preprint arXiv:1808.06670,
-
[9]
arXiv:1901.07042 (2019) 10 A.Rafferty et al
Irvin, J., Rajpurkar, P., Ko, M., et al. Chexpert: A large chest radiograph dataset with uncertainty labels and ex- pert comparison. InProceedings of the AAAI conference on artificial intelligence, volume 33(01), pp. 590–597, 2019a. Irvin, J., Rajpurkar, P., Ko, M., et al. Chexpert: A large chest radiograph dataset with uncertainty labels and ex- pert com...
-
[10]
Aptos 2019 blindness de- tection
Karthik, Maggie, and Dane, S. Aptos 2019 blindness de- tection. https://kaggle.com/competitions/ aptos2019-blindness-detection,
2019
-
[11]
arXiv preprint arXiv:2412.10372 (2024)
Khattak, M. U., Kunhimon, S., Naseer, M., Khan, S., and Khan, F. S. Unimed-clip: Towards a unified image-text pretraining paradigm for diverse medical imaging modal- ities.arXiv preprint arXiv:2412.10372,
-
[12]
Kovalyk, O., Morales-S ´anchez, J., Verd ´u-Monedero, R., et al
URL https: //doi.org/10.7910/DVN/1YRRAC. Kovalyk, O., Morales-S ´anchez, J., Verd ´u-Monedero, R., et al. Papila. https://doi.org/10.6084/m9. figshare.14798004.v1,
-
[13]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Lepikhin, D., Lee, H., Xu, Y ., et al. Gshard: Scaling gi- ant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review arXiv 2006
-
[14]
Ma, Z. and Collins, M. Noise contrastive estimation and neg- ative sampling for conditional models: Consistency and statistical efficiency.arXiv preprint arXiv:1809.01812, 2018a. Ma, Z. and Collins, M. Noise contrastive estimation and neg- ative sampling for conditional models: Consistency and statistical efficiency.arXiv preprint arXiv:1809.01812, 2018b....
-
[15]
Peltekian, A. K., Aktas, H. E., Durak, G., Grudzinski, K., Bemiss, B. C., Richardson, C., Dematte, J. E., Budinger, G., Esposito, A. J., Misharin, A., et al. Ren: Anatomically-informed mixture-of-experts for interstitial lung disease diagnosis.arXiv preprint arXiv:2510.04923,
-
[16]
Tschannen, M., Djolonga, J., Rubenstein, P. K., Gelly, S., and Lucic, M. On mutual information maximization for representation learning.arXiv preprint arXiv:1907.13625,
-
[17]
Chestx-ray8: Hospital- scale chest x-ray database and benchmarks on weakly- supervised classification and localization of common tho- rax diseases
Wang, X., Peng, Y ., Lu, L., et al. Chestx-ray8: Hospital- scale chest x-ray database and benchmarks on weakly- supervised classification and localization of common tho- rax diseases. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2097–2106,
2097
-
[18]
Images are categorized as glaucomatous, non-glaucomatous, or suspect, based on comprehensive clinical evaluation
contains 488 retinal images collected at HGURS (Murcia, Spain) between 2018–2020. Images are categorized as glaucomatous, non-glaucomatous, or suspect, based on comprehensive clinical evaluation. Retina(Ret) is established by Seoul National University (South Korea) to support automated retinal disease detection. It includes 601 images spanning four catego...
2018
-
[19]
consists of 1,113 macular OCT images acquired between 2015 and 2022, intended for diagnosing DME or DR
2015
-
[20]
Grand Challenge
is a binary classification benchmark for colorectal polyp histology, comprising 3,152 hematoxylin-and-eosin (H&E) stained formalin-fixed, paraffin-embedded (FFPE) image patches of fixed size (224×224 pixels). Images are labeled as Hyperplastic Polyp (HP) or Sessile Serrated Adenoma (SSA). To address class imbalance, we applied random cropping and horizon-...
2016
-
[21]
We use all images for training, and evaluate on the 1,512 image test set provided by the ISIC 2018 challenge
consists of 10,015 der- matoscopic images across seven disease categories. We use all images for training, and evaluate on the 1,512 image test set provided by the ISIC 2018 challenge. ISIC2018(Codella et al.,
2018
-
[22]
Architecture.The M-IDoL pre-training framework consists of two Swin Transformer-Base (Swin-B) visual encoders, namely a student encoder Sθ and a teacher encoder Tθ
such as Horizontal Flip, Color Jitter, Gaussian Blur, and Solarization. Architecture.The M-IDoL pre-training framework consists of two Swin Transformer-Base (Swin-B) visual encoders, namely a student encoder Sθ and a teacher encoder Tθ. Both encoders share the same Swin-B architecture: the input im- age is split into non-overlapping 4×4 patches and linear...
2023
-
[23]
baseline SwinViT (Liu et al., 2021), DINO (Caron et al.,
2021
-
[24]
and MAE (He et al., 2022), and
2022
-
[25]
unified pre-training MFMs Unimoss+ (Xie et al., 2024), MedCoss (Ye et al., 2024), LVM-Med (MH Nguyen et al., 2024), UniMed (Khattak et al.,
2024
-
[26]
We include im- plementation code in https://github.com/LYH-hh/M-IDoL to demonstrate the reproducibility of M-IDoL
and Tutel (Hwang et al., 2023). We include im- plementation code in https://github.com/LYH-hh/M-IDoL to demonstrate the reproducibility of M-IDoL. 17 M-IDoL: Information Decomposition for Modality-Specific and Diverse Representation Learning in Medical Foundation Model APTOS Glaucoma PAPILA Retina ISIC2016 ISIC2017 ZhangCXR RNSAHAM10000 OCTDL OCTID TVHL-D...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.