Recognition: unknown
Low-Data Supervised Adaptation Outperforms Prompting for Cloud Segmentation Under Domain Shift
Pith reviewed 2026-05-10 16:57 UTC · model grok-4.3
The pith
Supervised fine-tuning with minimal labeled data outperforms every prompting strategy for cloud segmentation in satellite imagery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
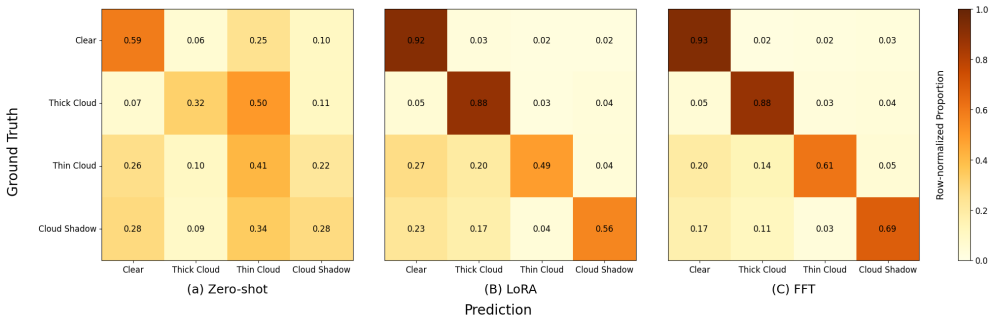
On the CloudSEN12+ benchmark, every one of the sixty prompt variants tested with CLIPSeg yields an mIoU below the zero-shot value of 0.255, with the weakest variants reaching only 0.07. Supervised fine-tuning on approximately 0.1 percent of the labeled data, or about eight images, surpasses the zero-shot score overall. Training on five to ten percent of the labels recovers roughly eighty-five percent of the maximum achievable mIoU. Full fine-tuning consistently exceeds low-rank adaptation by 0.03 to 0.09 mIoU, with the largest differences appearing on spectrally ambiguous classes, and very low supervision can produce a temporary performance dip on those classes before recovery.
What carries the argument
The direct comparison of sixty linguistic prompt variants against low-data supervised fine-tuning and low-rank adaptation applied to CLIPSeg for satellite cloud segmentation under domain shift.
Load-bearing premise
The sixty prompt variants and the CloudSEN12+ benchmark together represent the full range of useful language guidance and the complete extent of domain shift present in remote sensing imagery.
What would settle it
A single prompt variant that exceeds the zero-shot mIoU of 0.255 on the CloudSEN12+ test set, or a replication showing that fine-tuning on 0.1 percent labeled data fails to surpass zero-shot performance on a comparable satellite cloud segmentation dataset.
Figures





read the original abstract
Adapting vision-language models to remote sensing imagery presents a fundamental challenge: both the visual and linguistic distributions of satellite data lie far outside natural image pretraining corpora. Despite this, prompting remains the dominant deployment paradigm, driven by the assumption that domain-specific language can guide frozen model representations toward specialized tasks. We test this assumption directly on a domain where the mismatch is prominent: cloud segmentation for satellite imagery. Using CLIPSeg on the CloudSEN12+ cloud segmentation benchmark, we evaluate 60 prompt variants spanning simple labels, domain terminology, appearance descriptors, and contextual cues, finding that every variant underperforms the zero-shot baseline (0.255 mIoU), with engineered prompts scoring as low as 0.07 mIoU. No amount of linguistic refinement bridges the gap between CLIP's natural image representations and satellite spectral imagery. In contrast, supervised fine-tuning with just 0.1% labeled data (~8 images) surpasses zero-shot performance overall, and 5-10% data recovers ~85% of maximum achievable mIoU. Full fine-tuning consistently outperforms low-rank adaptation by 0.03-0.09 mIoU, with the largest gaps for spectrally ambiguous classes, and at 0.5 to 1% labeled data, fine-tuning temporarily degrades performance on these classes before recovering, a supervision dip that aggregate mIoU can mask. For practitioners adapting vision-language models to specialized imagery, our results deliver a clear message: labeled data is not the expensive alternative to prompting; it is the worthwhile path.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically evaluates prompting versus low-data supervised fine-tuning for adapting the CLIPSeg model to cloud segmentation in satellite imagery on the CloudSEN12+ benchmark. It tests 60 prompt variants and finds all underperform the zero-shot baseline of 0.255 mIoU. In contrast, fine-tuning with 0.1% labeled data surpasses zero-shot performance, with 5-10% data recovering approximately 85% of the maximum mIoU. Additional findings include full fine-tuning outperforming LoRA and a temporary 'supervision dip' in low-data regimes for certain classes.
Significance. This result, if robust, is significant for the field of domain adaptation in vision-language models, particularly for remote sensing applications where domain shift is severe. It challenges the reliance on prompting and demonstrates the practicality of low-data supervision, providing actionable insights for practitioners. The inclusion of detailed comparisons and identification of nuanced effects like the supervision dip adds depth to the empirical contribution.
major comments (1)
- The central negative finding on prompting—that 'no amount of linguistic refinement bridges the gap between CLIP's natural image representations and satellite spectral imagery'—rests on the 60 tested variants being representative of the space. The paper should explicitly discuss or test whether unexamined strategies (e.g., multi-sentence context, negation, or explicit spectral-band references) could improve zero-shot mIoU beyond 0.255 and narrow the gap to low-data fine-tuning; without this, the conclusion that prompting is unsuitable rather than merely ineffective for these variants is not fully supported (see abstract and prompting results section).
minor comments (2)
- The description of the 0.1% labeled data regime (~8 images) and how subsets are selected (random, stratified, etc.) should be expanded in the methods for reproducibility, including any reporting of variance across seeds or runs.
- Per-class mIoU tables or supplementary figures would strengthen the claims about the supervision dip on spectrally ambiguous classes and ensure aggregate mIoU does not mask class-specific effects.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and rigor of our work. We respond to the major comment point-by-point below.
read point-by-point responses
-
Referee: The central negative finding on prompting—that 'no amount of linguistic refinement bridges the gap between CLIP's natural image representations and satellite spectral imagery'—rests on the 60 tested variants being representative of the space. The paper should explicitly discuss or test whether unexamined strategies (e.g., multi-sentence context, negation, or explicit spectral-band references) could improve zero-shot mIoU beyond 0.255 and narrow the gap to low-data fine-tuning; without this, the conclusion that prompting is unsuitable rather than merely ineffective for these variants is not fully supported (see abstract and prompting results section).
Authors: We agree that the strong phrasing in the abstract and prompting results section—that 'no amount of linguistic refinement bridges the gap'—is not fully supported without addressing the representativeness of the 60 variants. Our variants were systematically chosen to span four categories: basic labels, remote-sensing domain terminology, visual appearance descriptors, and contextual cues (including some negations and compound phrases). However, we did not exhaustively test multi-sentence contexts or explicit spectral-band references. In the revised manuscript we will add a dedicated paragraph in the prompting results section that (1) explicitly lists the categories and examples tested, (2) acknowledges that the prompt space is infinite, and (3) explains why more elaborate strategies are unlikely to succeed given that CLIP's vision encoder was trained only on natural RGB images. We will also moderate the abstract claim to 'no tested linguistic refinement bridges the gap.' This is a partial revision focused on discussion rather than new experiments. revision: partial
Circularity Check
No circularity: purely empirical comparison of measured mIoU values
full rationale
The paper reports direct experimental measurements of mIoU on the CloudSEN12+ benchmark for 60 prompt variants versus zero-shot CLIPSeg baseline and multiple supervised fine-tuning regimes (0.1% to full data, full vs LoRA). No equations, parameter fits, predictions derived from inputs, or self-citations appear in the derivation chain. All claims are observations from held-out test performance; the negative result on prompting is an empirical finding on the tested variants rather than a self-referential reduction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The CloudSEN12+ dataset and its splits accurately capture the visual and spectral domain shift between natural images and satellite imagery for cloud segmentation.
Reference graph
Works this paper leans on
-
[1]
Pan, Negar Arabzadeh, Riccardo Cogo, Yuxuan Zhu, Alexander Xiong, Lakshya A
Melissa Z. Pan, Negar Arabzadeh, Riccardo Cogo, Yuxuan Zhu, Alexander Xiong, Lakshya A. Agrawal, Huanzhi Mao, Emma Shen, Sid Pallerla, Liana Patel, Shu Liu, Tianneng Shi, Xiaoyuan Liu, Jared Quincy Davis, Emmanuele Lacav- alla, Alessandro Basile, Shuyi Yang, Paul Castro, Daniel Kang, Joseph E. Gonzalez, Koushik Sen, Dawn Song, Ion Stoica, Matei Zaharia, a...
-
[3]
PhraseCut: Language-Based Image Seg- mentation in the Wild
Chenyun Wu, Zhe Lin, Scott Cohen, Trung Bui, and Subhransu Maji. PhraseCut: Language-Based Image Seg- mentation in the Wild. 1, 3
-
[4]
Cesar Aybar, Lesly Bautista, David Montero, Julio Contr- eras, Daryl Ayala, Fernando Prudencio, Jhomira Loja, Luis Ysuhuaylas, Fernando Herrera, Karen Gonzales, Jeanett Val- ladares, Lucy A. Flores, Evelin Mamani, Maria Qui ˜nonez, Rai Fajardo, Wendy Espinoza, Antonio Limas, Roy Yali, Alejandro Alc ´antara, Martin Leyva, Ra ´ul Loayza-Muro, Bram Willems, ...
-
[5]
Learning Transferable Vi- sual Models From Natural Language Supervision, February
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Vi- sual Models From Natural Language Supervision, February
-
[6]
Learning Transferable Visual Models From Natural Language Supervision
URLhttp://arxiv.org/abs/2103.00020. arXiv:2103.00020 [cs]. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Conditional Prompt Learning for Vision-Language Models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Zi- wei Liu. Conditional Prompt Learning for Vision-Language Models. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16795– 16804, New Orleans, LA, USA, June 2022. IEEE. ISBN 978-1-6654-6946-3. doi: 10 . 1109 / CVPR52688 . 2022 . 01631. URLhttps : / / ieeexplore . ieee ....
-
[8]
MaPLe: Multi-modal Prompt Learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muham- mad Maaz, Salman Khan, and Fahad Shahbaz Khan. MaPLe: Multi-modal Prompt Learning. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19113–19122, Vancouver, BC, Canada, June 2023. IEEE. ISBN 979-8-3503-0129-8. doi: 10 . 1109 / CVPR52729 . 2023 . 01832. URLhttps : / / ieeexpl...
-
[9]
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18061–18070, New Orleans, LA, USA, June 2022. IEEE. ISBN 978-1-6654-6946-3. doi: 10.1109/CVPR52...
-
[10]
Salim Khazem. TopoLoRA-SAM: Topology-Aware Parameter-Efficient Adaptation of Foundation Segmenters for Thin-Structure and Cross-Domain Binary Semantic Seg- mentation, January 2026. URLhttp://arxiv.org/ abs/2601.02273. arXiv:2601.02273 [cs]. 2
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, October 2021. URLhttp://arxiv.org/abs/2106. 09685. arXiv:2106.09685 [cs]. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Lora vs full fine-tuning: An illusion of equivalence
Reece Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. LoRA vs Full Fine-tuning: An Illusion of Equivalence, October 2025. URLhttp://arxiv.org/ abs/2410.21228. arXiv:2410.21228 [cs]. 2
-
[13]
PEFT-Bench: A Parameter-Efficient Fine-Tuning Methods Benchmark, November 2025
Robert Belanec, Branislav Pecher, Ivan Srba, and Maria Bielikova. PEFT-Bench: A Parameter-Efficient Fine-Tuning Methods Benchmark, November 2025. URLhttp:// arxiv.org/abs/2511.21285. arXiv:2511.21285 [cs] version: 1. 2
work page internal anchor Pith review arXiv 2025
-
[14]
Xiang Li, Congcong Wen, Yuan Hu, and Nan Zhou. RS-CLIP: Zero shot remote sensing scene classification via contrastive vision-language supervision.International Journal of Applied Earth Observation and Geoinforma- tion, 124:103497, November 2023. ISSN 15698432. doi: 10 . 1016 / j . jag . 2023 . 103497. URLhttps : //linkinghub.elsevier.com/retrieve/pii/ S15...
2023
-
[15]
Remoteclip: A vision language foundation model for remote sensing, 2024
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Re- moteCLIP: A Vision Language Foundation Model for Re- mote Sensing, April 2024. URLhttp://arxiv.org/ abs/2306.11029. arXiv:2306.11029 [cs]. 3
-
[16]
SenCLIP: Enhancing Zero- Shot Land-Use Mapping for Sentinel-2 with Ground-Level Prompting
Pallavi Jain, Dino Ienco, Roberto Interdonato, Tristan Berchoux, and Diego Marcos. SenCLIP: Enhancing Zero- Shot Land-Use Mapping for Sentinel-2 with Ground-Level Prompting. 2
-
[17]
Language-driven semantic segmentation.arXiv preprint arXiv:2201.03546,
Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, and Ren ´e Ranftl. Language-driven Semantic Seg- mentation, April 2022. URLhttp://arxiv.org/abs/ 2201.03546. arXiv:2201.03546 [cs]. 3
-
[18]
Rethinking data augmentation for robust LiDAR semantic segmentation in adverse weather,
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scal- ing Open-V ocabulary Image Segmentation with Image-Level Labels. In Shai Avidan, Gabriel Brostow, Moustapha Ciss ´e, Giovanni Maria Farinella, and Tal Hassner, editors,Com- puter Vision – ECCV 2022, volume 13696, pages 540–557. Springer Nature Switzerland, Cham, 2022. ISBN 978-3- 031-20058-8 978-3-...
-
[19]
SegCLIP: Patch Aggregation with Learnable Centers for Open-V ocabulary Semantic Segmentation
Huaishao Luo. SegCLIP: Patch Aggregation with Learnable Centers for Open-V ocabulary Semantic Segmentation
-
[20]
Extract Free Dense Labels from CLIP
Chong Zhou, Chen Change Loy, and Bo Dai. Extract Free Dense Labels from CLIP. In Shai Avidan, Gabriel Brostow, Moustapha Ciss ´e, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision – ECCV 2022, vol- ume 13688, pages 696–712. Springer Nature Switzerland, Cham, 2022. ISBN 978-3-031-19814-4 978-3-031-19815-
2022
-
[21]
doi: 10.1007/978-3-031-19815-1 40. URLhttps: //link.springer.com/10.1007/978- 3- 031- 19815- 1_40. Series Title: Lecture Notes in Computer Science
-
[22]
Vision transformers are parameter- efficient audio-visual learners
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Di- ana Marculescu. Open-V ocabulary Semantic Segmentation with Mask-adapted CLIP. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7061–7070, Vancouver, BC, Canada, June 2023. IEEE. ISBN 979-8-3503-0129-8. doi: 10.1...
-
[23]
CONVOLUTION MEETS LORA: PARAME- TER EFFI- CIENT FINETUNING FOR SEGMENT ANY- THING MODEL
Zihan Zhong, Zhiqiang Tang, Tong He, Haoyang Fang, and Chun Yuan. CONVOLUTION MEETS LORA: PARAME- TER EFFI- CIENT FINETUNING FOR SEGMENT ANY- THING MODEL. 2024. 3
2024
-
[24]
https://doi.org/10.48550/arXiv.1708.02002
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ar. Focal Loss for Dense Object Detection, February 2018. URLhttp://arxiv.org/abs/1708. 02002. arXiv:1708.02002 [cs]. 4
-
[25]
Tversky loss function for image segmenta- tion using 3D fully convolutional deep networks, June
Seyed Sadegh Mohseni Salehi, Deniz Erdogmus, and Ali Gholipour. Tversky loss function for image segmenta- tion using 3D fully convolutional deep networks, June
-
[26]
Tverskylossfunctionforimagesegmentationusing3dfullyconvolutionaldeepnetworks
URLhttp://arxiv.org/abs/1706.05721. arXiv:1706.05721 [cs]. 4 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.