Recognition: unknown
How Should Video LLMs Output Time? An Analysis of Efficient Temporal Grounding Paradigms
Pith reviewed 2026-05-10 16:46 UTC · model grok-4.3
The pith
Continuous temporal decoding gives the best efficiency-accuracy balance for video temporal grounding in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across identical compact VLMs (SmolVLM2, FastVLM, Molmo2) and consistent LoRA fine-tuning on Charades-STA, QVHighlights, and YouCook2, the continuous distribution paradigm consistently reaches the most favorable efficiency-accuracy trade-off on the Pareto frontier, delivering robust localization with minimal latency overhead compared with text numeral generation and temporal token generation.
What carries the argument
Continuous temporal decoding, which models output time as a continuous distribution instead of discrete numerals or tokens.
If this is right
- The output formulation alone changes both grounding accuracy and computational cost even when model size stays fixed.
- Continuous distribution yields robust localization while keeping inference latency and training throughput low.
- The results supply concrete guidelines for choosing an output method when building deployment-ready video temporal grounding systems.
- Text numeral and temporal token approaches incur measurable overhead relative to the continuous baseline under matched conditions.
Where Pith is reading between the lines
- Designers of edge video systems could prioritize continuous decoding to cut power use without sacrificing time localization.
- The same controlled setup could be reused to test whether the advantage persists when models are scaled up or when new video domains are added.
- If latency measurements include full system overhead rather than just model forward passes, the continuous method's edge may become even clearer for real-time use.
Load-bearing premise
That holding the compact VLMs, LoRA protocols, and datasets exactly the same fully removes any unmeasured differences in how the three output paradigms are implemented or optimized.
What would settle it
A replication on the same three datasets and models that finds another paradigm matching or beating the continuous distribution on both accuracy and latency at the same time.
Figures



read the original abstract
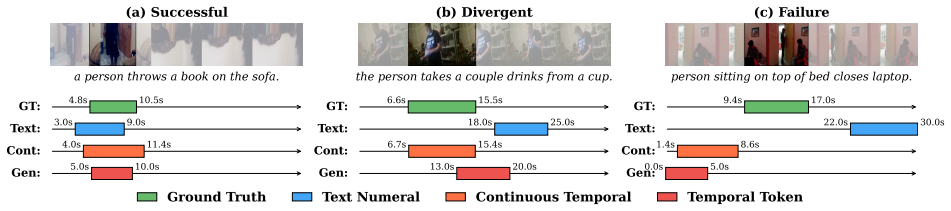
While Multimodal Large Language Models (MLLMs) have advanced Video Temporal Grounding (VTG), existing methods often couple output paradigms with different backbones, datasets, and training protocols. This makes it challenging to isolate the specific impact of the output design. Additionally, as VTG systems are increasingly considered for resource-constrained edge deployment, the trade-off between output formulation and system-level efficiency requires systematic investigation. In this paper, we present a controlled empirical study comparing three dominant VTG output paradigms: Text Numeral Generation, Temporal Token Generation, and Continuous Temporal Decoding. We evaluate these paradigms across identical compact VLMs (SmolVLM2, FastVLM, and Molmo2) using consistent datasets and LoRA fine-tuning protocols. Evaluations on Charades-STA, QVHighlights, and YouCook2 measure both localization accuracy and system efficiency, including inference latency, training throughput, and parameter overhead. Our results demonstrate that the choice of output formulation significantly affects both grounding accuracy and computational cost, independent of model scale. Specifically, the continuous distribution paradigm consistently achieves the most favorable efficiency-accuracy trade-off on the Pareto frontier, delivering robust localization with minimal latency overhead. These findings provide objective empirical guidelines for designing efficient, deployment-ready VTG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical study isolating the effects of three video temporal grounding (VTG) output paradigms—Text Numeral Generation, Temporal Token Generation, and Continuous Temporal Decoding—on identical compact VLMs (SmolVLM2, FastVLM, Molmo2) with consistent LoRA fine-tuning protocols and evaluation on Charades-STA, QVHighlights, and YouCook2. It reports both localization accuracy and system-level efficiency metrics (inference latency, training throughput, parameter overhead), concluding that the continuous distribution paradigm achieves the most favorable efficiency-accuracy trade-off on the Pareto frontier with robust localization and minimal latency overhead.
Significance. If the results hold under the reported controls, the work supplies actionable empirical guidelines for designing deployment-ready VTG systems, particularly for resource-constrained edge settings. The controlled ablation—standardizing backbones, training protocols, and datasets—directly strengthens isolation of output-paradigm effects compared with prior mixed-variable comparisons, and the explicit Pareto-frontier analysis adds practical value for efficiency-accuracy trade-offs.
minor comments (3)
- [§4.2] §4.2 (Experimental Setup): Provide the exact LoRA rank, target modules, and learning-rate schedule for each paradigm to ensure full reproducibility of the claimed isolation.
- [Figure 3] Figure 3 (Pareto frontier): Label the axes with explicit units (e.g., latency in ms, mIoU in percent) and indicate whether error bars reflect multiple random seeds or cross-validation folds.
- [§5.1] §5.1 (Results): Report the precise statistical test and p-values used to support the claim that continuous decoding is “consistently” superior across all three datasets.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our controlled study on VTG output paradigms and for the recommendation of minor revision. The noted significance regarding actionable guidelines for efficiency-accuracy trade-offs in resource-constrained settings aligns with our goals. Since no specific major comments were provided in the report, we have no point-by-point responses and will incorporate any minor revisions as appropriate.
Circularity Check
No significant circularity: pure empirical comparison with no derivations or self-referential reductions
full rationale
The paper conducts a controlled empirical ablation of three VTG output paradigms (Text Numeral Generation, Temporal Token Generation, Continuous Temporal Decoding) on identical compact VLMs (SmolVLM2, FastVLM, Molmo2), datasets (Charades-STA, QVHighlights, YouCook2), and LoRA fine-tuning protocols. No mathematical derivations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the abstract or described methodology. The central claim—that continuous distribution yields the best efficiency-accuracy Pareto trade-off—rests directly on measured localization accuracy, latency, throughput, and parameter overhead from standardized experiments, without reducing to quantities defined by the authors' own prior equations or inputs. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Using the same compact VLMs, LoRA fine-tuning, and datasets across paradigms removes confounding factors and isolates the impact of output formulation.
Reference graph
Works this paper leans on
-
[1]
Localizing mo- ments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing mo- ments in video with natural language. InProceedings of the IEEE international conference on computer vision, pages 5803–5812, 2017. 1, 11
2017
-
[2]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 11
2015
-
[3]
Sharegpt4video: Improving video understand- ing and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2024
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understand- ing and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2024. 11
2024
-
[4]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In Proceedings of the IEEE international conference on com- puter vision, pages 5267–5275, 2017. 1, 5
2017
-
[5]
Trace: Temporal grounding video llm via causal event modeling,
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang. Trace: Temporal grounding video llm via causal event modeling.arXiv preprint arXiv:2410.05643,
-
[6]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xi- aoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 3302–3310, 2025. 1, 3, 14
2025
-
[7]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022. 5
2022
-
[8]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024. 1, 2, 3, 5, 14
2024
-
[9]
Lita: Language instructed temporal-localization assistant
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. In European Conference on Computer Vision, pages 202–218. Springer, 2024. 3
2024
-
[10]
Multimodal pretraining for dense video cap- tioning
Gabriel Huang, Bo Pang, Zhenhai Zhu, Clara Rivera, and Radu Soricut. Multimodal pretraining for dense video cap- tioning. InProceedings of the 1st Conference of the Asia- Pacific Chapter of the Association for Computational Lin- guistics and the 10th International Joint Conference on Nat- ural Language Processing, pages 470–490, 2020. 11
2020
-
[11]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on com- puter vision, pages 706–715, 2017. 1
2017
-
[12]
Detecting mo- ments and highlights in videos via natural language queries
Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting mo- ments and highlights in videos via natural language queries. Advances in Neural Information Processing Systems, 34: 11846–11858, 2021. 1, 2, 5
2021
-
[13]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10):200102, 2025. 11
2025
-
[14]
Ground- inggpt: Language enhanced multi-modal grounding model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Vu Tu, et al. Ground- inggpt: Language enhanced multi-modal grounding model. InProceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 6657–6678, 2024. 1, 3, 14
2024
-
[15]
Univtg: Towards unified video- language temporal grounding
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shra- man Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video- language temporal grounding. InProceedings of the IEEE/CVF international conference on computer vision, pages 2794–2804, 2023. 3
2023
-
[16]
Videomind: A chain-of-lora agent for temporal-grounded video reasoning
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. Videomind: A chain-of-lora agent for temporal-grounded video reasoning. InNeurIPS 2025 Work- shop on Bridging Language, Agent, and World Models for Reasoning and Planning. 3, 14
2025
-
[17]
Valley: Video assistant with large language model enhanced ability.ACM Transactions on Multimedia Computing, Com- munications and Applications, 2023
Ruipu Luo, Ziwang Zhao, Min Yang, Zheming Yang, Minghui Qiu, Zhongyu Wei, Yanhao Wang, and Cen Chen. Valley: Video assistant with large language model enhanced ability.ACM Transactions on Multimedia Computing, Com- munications and Applications, 2023. 11
2023
-
[18]
Chrono: A simple blueprint for representing time in mllms.arXiv preprint arXiv:2406.18113, 2024
Boris Meinardus, Hector Rodriguez, Anil Batra, Anna Rohrbach, and Marcus Rohrbach. Chrono: A simple blueprint for representing time in mllms.arXiv preprint arXiv:2406.18113, 2024. 3, 5, 14
-
[19]
arXiv preprint arXiv:2311.08835 (2023)
WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae- Pil Heo. Correlation-guided query-dependency calibra- tion for video temporal grounding.arXiv preprint arXiv:2311.08835, 2023. 1, 2, 3
-
[20]
Slowfocus: Enhancing fine-grained temporal understanding in video llm.Advances in Neural Information Processing Systems, 37:81808–81835,
Ming Nie, Dan Ding, Chunwei Wang, Yuanfan Guo, Jian- hua Han, Hang Xu, and Li Zhang. Slowfocus: Enhancing fine-grained temporal understanding in video llm.Advances in Neural Information Processing Systems, 37:81808–81835,
-
[21]
Queryd: A video dataset with high-quality text and audio narrations
Andreea-Maria Oncescu, Joao F Henriques, Yang Liu, Andrew Zisserman, and Samuel Albanie. Queryd: A video dataset with high-quality text and audio narrations. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2265–2269. IEEE, 2021. 11
2021
-
[22]
Momentor: Ad- vancing video large language model with fine-grained temporal reasoning,
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat- Seng Chua, Yueting Zhuang, and Siliang Tang. Momen- tor: Advancing video large language model with fine-grained temporal reasoning.arXiv preprint arXiv:2402.11435, 2024. 1, 3, 14
-
[23]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024. 3, 14
2024
-
[24]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207– 1216, 2019. 11
2019
-
[25]
Grounded- videollm: Sharpening fine-grained temporal grounding in video large language models,
Haibo Wang, Zhiyang Xu, Yu Cheng, Shizhe Diao, Yu- fan Zhou, Yixin Cao, Qifan Wang, Weifeng Ge, and Lifu Huang. Grounded-videollm: Sharpening fine-grained tem- poral grounding in video large language models.arXiv preprint arXiv:2410.03290, 2024. 3, 14
-
[26]
Timerefine: Temporal grounding with time refining video llm
Xizi Wang, Feng Cheng, Ziyang Wang, Huiyu Wang, Md Mohaiminul Islam, Lorenzo Torresani, Mohit Bansal, Gedas Bertasius, and David Crandall. Timerefine: Temporal grounding with time refining video llm. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pages 5067–5078, 2026. 3, 4, 14
2026
-
[27]
arXiv preprint arXiv:2307.06942 (2023)
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023. 11
-
[28]
Hawkeye: Training video-text llms for grounding text in videos,
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. Hawkeye: Training video- text llms for grounding text in videos.arXiv preprint arXiv:2403.10228, 2024. 3, 14
-
[29]
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xi- angyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025. 1, 3, 14
-
[30]
A survey on video temporal grounding with multimodal large language model
Jianlong Wu, Wei Liu, Ye Liu, Meng Liu, Liqiang Nie, Zhouchen Lin, and Chang Wen Chen. A survey on video temporal grounding with multimodal large language model. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025. 1, 2, 3, 4
2025
-
[31]
A large cross- modal video retrieval dataset with reading comprehension
Weijia Wu, Yuzhong Zhao, Zhuang Li, Jiahong Li, Hong Zhou, Mike Zheng Shou, and Xiang Bai. A large cross- modal video retrieval dataset with reading comprehension. Pattern Recognition, 157:110818, 2025. 11
2025
-
[32]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9777–9786, 2021. 1
2021
-
[33]
Can i trust your answer? visually grounded video question answering
Junbin Xiao, Angela Yao, Yicong Li, and Tat-Seng Chua. Can i trust your answer? visually grounded video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13204– 13214, 2024. 1
2024
-
[34]
Vid2seq: Large-scale pretraining of a vi- sual language model for dense video captioning
Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, An- toine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid. Vid2seq: Large-scale pretraining of a vi- sual language model for dense video captioning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10714–10726, 2023. 1
2023
-
[35]
Self-chained image-language model for video localization and question answering.Advances in Neural Information Processing Systems, 36:76749–76771, 2023
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering.Advances in Neural Information Processing Systems, 36:76749–76771, 2023. 3, 14
2023
-
[36]
Mer- lot: Multimodal neural script knowledge models.Advances in neural information processing systems, 34:23634–23651,
Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. Mer- lot: Multimodal neural script knowledge models.Advances in neural information processing systems, 34:23634–23651,
-
[37]
Distime: Distribution- based time representation for video large language models
Yingsen Zeng, Zepeng Huang, Yujie Zhong, Chengjian Feng, Jie Hu, Lin Ma, and Yang Liu. Distime: Distribution- based time representation for video large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21961–21971, 2025. 1, 2, 3, 4, 5, 14
2025
-
[38]
from X to Y seconds
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. InProceedings of the AAAI conference on artificial intelligence, 2018. 5 Appendix Overview This supplementary material provides additional details and comprehensive benchmarks omitted from the main text due to space constraints. The contents...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.