Recognition: no theorem link
Confident in a Confidence Score: Investigating the Sensitivity of Confidence Scores to Supervised Fine-Tuning
Pith reviewed 2026-05-10 17:33 UTC · model grok-4.3
The pith
Supervised fine-tuning degrades the correlation between confidence scores and language model output quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-supervised fine-tuning, the correlation of various confidence scores with output quality degrades because the scores change in response to factors other than quality, such as the similarity of outputs to the training distribution. This miscorrelation reduces the practical usefulness of the scores on downstream tasks, as shown in a case study where it impairs reliable uncertainty detection.
What carries the argument
The correlation between confidence scores and output quality, which degrades after supervised fine-tuning due to score shifts driven by training-distribution similarity rather than quality alone.
If this is right
- Confidence scores cannot be applied directly after supervised fine-tuning without first verifying their correlation with output quality.
- Downstream uses such as hallucination detection or alerting users to uncertain outputs become less reliable following fine-tuning.
- New confidence metrics must be designed to remain aligned with quality even after the model has been fine-tuned on a specific distribution.
- Case-study evidence on one task implies that similar miscorrelation effects may appear across other tasks that rely on post-fine-tuning uncertainty estimates.
Where Pith is reading between the lines
- Developers may need to insert explicit recalibration or validation steps for confidence scores inside standard fine-tuning pipelines.
- The training-distribution similarity effect could be tested by measuring how much outputs resemble the fine-tuning data before and after training.
- Similar degradation might occur with other adaptation methods that alter output distributions, such as continued pre-training or preference tuning.
Load-bearing premise
The observed degradation in correlation stems directly from the supervised fine-tuning step itself rather than from differences in data selection, model size, evaluation metrics, or other experimental variables.
What would settle it
Repeating the experiments while holding data selection, model size, and evaluation metrics fixed but varying only the presence of supervised fine-tuning, and checking whether the correlation drop disappears or persists.
Figures

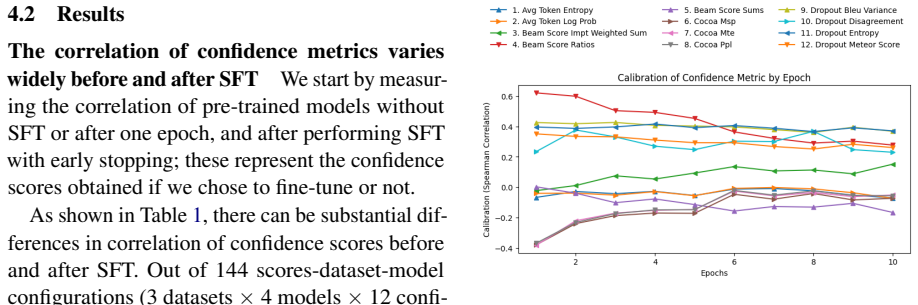
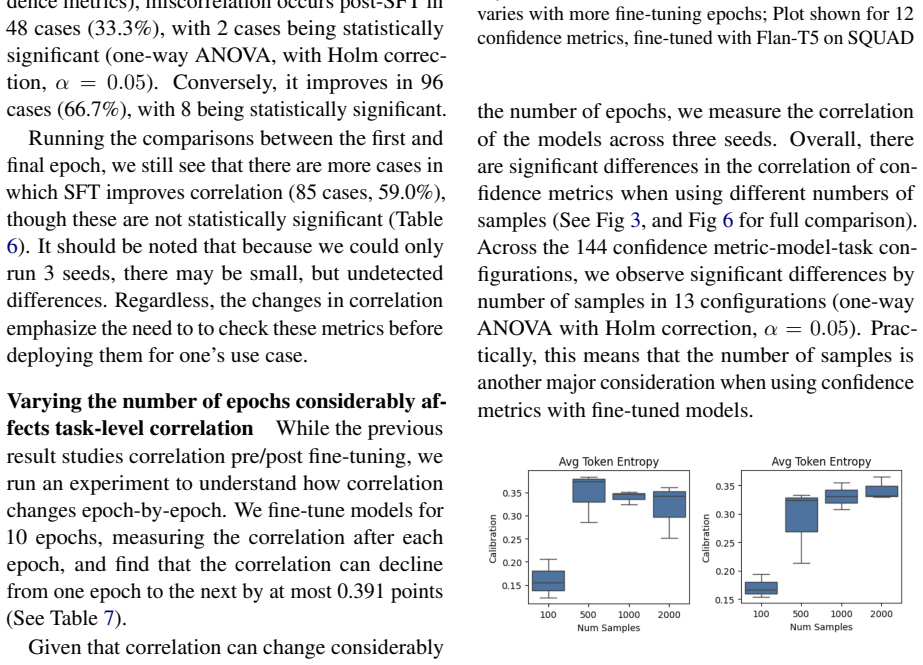

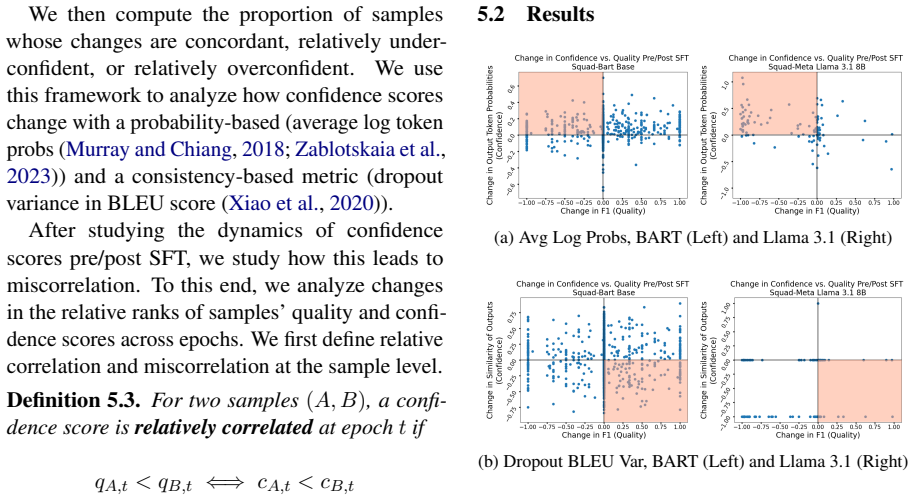



read the original abstract
Uncertainty quantification is a set of techniques that measure confidence in language models. They can be used, for example, to detect hallucinations or alert users to review uncertain predictions. To be useful, these confidence scores must be correlated with the quality of the output. However, recent work found that fine-tuning can affect the correlation between confidence scores and quality. Hence, we investigate the underlying behavior of confidence scores to understand its sensitivity to supervised fine-tuning (SFT). We find that post-SFT, the correlation of various confidence scores degrades, which can stem from changes in confidence scores due to factors other than the output quality, such as the output's similarity to the training distribution. We demonstrate via a case study how failing to address this miscorrelation reduces the usefulness of the confidence scores on a downstream task. Our findings show how confidence metrics cannot be used off-the-shelf without testing, and motivate the need for developing metrics which are more robust to fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that supervised fine-tuning (SFT) degrades the correlation between multiple confidence scores and output quality in language models. It attributes this degradation in part to confidence scores responding to output similarity with the training distribution rather than to output quality. A case study illustrates how this miscorrelation harms performance on a downstream task, and the authors conclude that confidence metrics cannot be used off-the-shelf after SFT and that more robust metrics are required.
Significance. If the central empirical finding is robust, the work is significant for uncertainty quantification in LLMs: SFT is ubiquitous, and reliable confidence scores are needed for hallucination detection and safe deployment. The case study supplies a concrete downstream consequence. The paper correctly notes the role of training-distribution similarity but does not yet isolate it from the SFT step itself.
major comments (2)
- [§4 and case study] §4 (Experimental Results) and the case-study section: the manuscript reports degradation in confidence-quality correlation after SFT but provides no ablation that holds output distribution similarity fixed while varying only the presence of the SFT step (or vice versa). Without this isolation, the causal attribution of the observed miscorrelation specifically to SFT rather than to data-distribution shift remains unestablished.
- [Abstract and §3] Abstract and §3 (Methodology): the abstract states clear findings yet supplies no details on experimental controls, statistical tests (e.g., significance of correlation changes), or data-exclusion rules. This absence prevents assessment of whether the reported degradation is robust or could be an artifact of particular choices in data, model size, or evaluation metrics.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly list the concrete confidence scores examined and the precise downstream task used in the case study.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important opportunities to strengthen the clarity and causal claims of our work. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§4 and case study] §4 (Experimental Results) and the case-study section: the manuscript reports degradation in confidence-quality correlation after SFT but provides no ablation that holds output distribution similarity fixed while varying only the presence of the SFT step (or vice versa). Without this isolation, the causal attribution of the observed miscorrelation specifically to SFT rather than to data-distribution shift remains unestablished.
Authors: We agree that a more explicit isolation of the SFT step from output-distribution similarity would strengthen the causal interpretation. Our experiments compare the identical base model and evaluation prompts before and after SFT, thereby holding model architecture, prompt distribution, and quality metrics fixed while varying only the application of SFT. Additional analyses in the paper link the observed degradation to similarity with the training distribution. Nevertheless, we acknowledge the referee’s point and will add a dedicated subsection in the revised §4 that (i) reports similarity-matched subsets of outputs across pre- and post-SFT regimes and (ii) explicitly discusses the practical difficulty of fully disentangling SFT-induced distributional change from the fine-tuning process itself. If perfect matching proves infeasible, we will state this limitation transparently. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (Methodology): the abstract states clear findings yet supplies no details on experimental controls, statistical tests (e.g., significance of correlation changes), or data-exclusion rules. This absence prevents assessment of whether the reported degradation is robust or could be an artifact of particular choices in data, model size, or evaluation metrics.
Authors: We appreciate this observation. In the revised manuscript we will expand the abstract to include a concise summary of the experimental controls (models, datasets, confidence-score families, and evaluation metrics). Section 3 will be augmented with (i) explicit statements of statistical procedures used to test the significance of pre- versus post-SFT correlation differences (e.g., bootstrap confidence intervals and paired permutation tests), (ii) data-exclusion criteria (filtering rules for invalid generations, annotation quality thresholds, and handling of edge cases), and (iii) sensitivity checks across model scales. These additions will allow readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: purely empirical investigation with no derivations or self-referential reductions
full rationale
The paper is an empirical study examining how supervised fine-tuning affects the correlation between confidence scores and output quality in language models. It reports experimental observations, including degradation in correlations post-SFT and a case study on downstream task impact, without any mathematical derivations, equations, fitted parameters presented as predictions, or ansatzes. No load-bearing steps reduce claims to inputs by construction, and self-citations (if present) do not form a chain that substitutes for independent evidence. The work remains self-contained as an observational analysis rather than a deductive chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in NLP experiments about model training and evaluation
Reference graph
Works this paper leans on
-
[1]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, and 12 others. 2022. https://doi.org/10.48550/ARXIV.2210.11416 Scaling instruction-fine...
work page internal anchor Pith review doi:10.48550/arxiv.2210.11416 2022
-
[2]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Nico Daheim, Clara Meister, Thomas M \"o llenhoff, and Iryna Gurevych. 2025. https://openreview.net/forum?id=hPpyUv1XyQ Uncertainty-aware decoding with minimum bayes risk . In The Thirteenth International Conference on Learning Representations
2025
- [4]
-
[5]
Lorenzo Jaime Yu Flores, Ori Ernst, and Jackie CK Cheung. 2025. https://doi.org/10.18653/v1/2025.acl-short.15 Improving the calibration of confidence scores in text generation using the output distribution ' s characteristics . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 172--1...
-
[6]
Naman Goyal, Cynthia Gao, Vishrav Chaudhary, Peng-Jen Chen, Guillaume Wenzek, Da Ju, Sanjana Krishnan, Marc'Aurelio Ranzato, Francisco Guzm\' a n, and Angela Fan. 2021. The flores-101 evaluation benchmark for low-resource and multilingual machine translation
2021
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [8]
- [9]
-
[10]
Amita Kamath, Robin Jia, and Percy Liang. 2020. https://doi.org/10.18653/v1/2020.acl-main.503 Selective question answering under domain shift . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5684--5696, Online. Association for Computational Linguistics
-
[11]
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. 2024. https://arxiv.org/abs/2406.08391 Large language models must be taught to know what they don't know . Preprint, arXiv:2406.08391
- [12]
-
[13]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. https://openreview.net/forum?id=VD-AYtP0dve Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation . In The Eleventh International Conference on Learning Representations
2023
- [14]
-
[15]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. https://arxiv.org/abs/1612.01474 Simple and scalable predictive uncertainty estimation using deep ensembles . Preprint, arXiv:1612.01474
work page Pith review arXiv 2017
- [16]
-
[17]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. https://arxiv.org/abs/1910.13461 BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension . CoRR, abs/1910.13461
work page internal anchor Pith review arXiv 2019
-
[18]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022 a . https://openreview.net/forum?id=8s8K2UZGTZ Teaching models to express their uncertainty in words . Transactions on Machine Learning Research
2022
-
[19]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022 b . https://arxiv.org/abs/2109.07958 Truthfulqa: Measuring how models mimic human falsehoods . Preprint, arXiv:2109.07958
work page internal anchor Pith review arXiv 2022
-
[20]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2023. https://api.semanticscholar.org/CorpusID:258967487 Generating with confidence: Uncertainty quantification for black-box large language models . Trans. Mach. Learn. Res., 2024
2023
- [21]
- [22]
- [23]
-
[24]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.557 S elf C heck GPT : Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017, Singapore. Association for Computational...
-
[25]
Kenton Murray and David Chiang. 2018. https://doi.org/10.18653/v1/W18-6322 Correcting length bias in neural machine translation . In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 212--223, Brussels, Belgium. Association for Computational Linguistics
- [26]
-
[27]
Team NLLB. 2022. No language left behind: Scaling human-centered machine translation
2022
-
[28]
Yotam Perlitz, Ariel Gera, Michal Shmueli-Scheuer, Dafna Sheinwald, Noam Slonim, and Liat Ein-Dor. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.611 Active learning for natural language generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9862--9877, Singapore. Association for Computational Linguistics
-
[29]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395, Lisbon, Portugal. Association for Computational Linguistics
-
[30]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. https://doi.org/10.18653/v1/D16-1264 SQ u AD : 100,000+ questions for machine comprehension of text . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383--2392, Austin, Texas. Association for Computational Linguistics
- [31]
-
[32]
Liu, and Balaji Lakshminarayanan
Jie Ren, Yao Zhao, Tu Vu, Peter J. Liu, and Balaji Lakshminarayanan. 2023. https://arxiv.org/abs/2312.09300 Self-evaluation improves selective generation in large language models . Preprint, arXiv:2312.09300
-
[33]
Bartezzaghi, Jasmina Bogojeska, Adelmo Cristiano Innocenza Malossi, and Thang Vu
Maximilian Schmidt, A. Bartezzaghi, Jasmina Bogojeska, Adelmo Cristiano Innocenza Malossi, and Thang Vu. 2022. https://api.semanticscholar.org/CorpusID:254044648 Combining data generation and active learning for low-resource question answering . In International Conference on Artificial Neural Networks
2022
-
[34]
Artem Shelmanov, Maxim Panov, Roman Vashurin, Artem Vazhentsev, Ekaterina Fadeeva, and Timothy Baldwin. 2025. https://doi.org/10.18653/v1/2025.acl-tutorials.3 Uncertainty quantification for large language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 5: Tutorial Abstracts), pages 3--4, Vienna, ...
-
[35]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.330 Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback . In Proceedings of the 2023 Conference on Em...
-
[37]
Roman Vashurin, Maiya Goloburda, Albina Ilina, Aleksandr Rubashevskii, Preslav Nakov, Artem Shelmanov, and Maxim Panov. 2025. https://arxiv.org/abs/2502.04964 Uncertainty quantification for llms through minimum bayes risk: Bridging confidence and consistency . Preprint, arXiv:2502.04964
-
[38]
Artem Vazhentsev, Akim Tsvigun, Roman Vashurin, Sergey Petrakov, Daniil Vasilev, Maxim Panov, Alexander Panchenko, and Artem Shelmanov. 2023. https://doi.org/10.18653/v1/2023.findings-acl.93 Efficient out-of-domain detection for sequence to sequence models . In Findings of the Association for Computational Linguistics: ACL 2023, pages 1430--1454, Toronto,...
-
[39]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . Preprint, arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [40]
- [41]
-
[42]
Tim Z. Xiao, Aidan N. Gomez, and Yarin Gal. 2020. https://arxiv.org/abs/2006.08344 Wat zei je? detecting out-of-distribution translations with variational transformers . Preprint, arXiv:2006.08344
-
[43]
Duygu Nur Yaldiz, Yavuz Faruk Bakman, Baturalp Buyukates, Chenyang Tao, Anil Ramakrishna, Dimitrios Dimitriadis, and Amir Salman Avestimehr. 2024. https://api.semanticscholar.org/CorpusID:270560969 Do not design, learn: A trainable scoring function for uncertainty estimation in generative llms . ArXiv, abs/2406.11278
-
[44]
Polina Zablotskaia, Du Phan, Joshua Maynez, Shashi Narayan, Jie Ren, and Jeremiah Liu. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.197 On uncertainty calibration and selective generation in probabilistic neural summarization: A benchmark study . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2980--2992, Singapore...
-
[45]
Yuekai Zhao, Haoran Zhang, Shuchang Zhou, and Zhihua Zhang. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.162 Active learning approaches to enhancing neural machine translation . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1796--1806, Online. Association for Computational Linguistics
-
[46]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[47]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.