Recognition: 2 theorem links
· Lean TheoremNeighbourhood Transformer: Switchable Attention for Monophily-Aware Graph Learning
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
Neighbourhood Transformers use local self-attention to handle both homophilic and heterophilic graphs while matching message-passing expressiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neighbourhood Transformer applies self-attention within every local neighbourhood instead of aggregating messages to the central node. This design makes the model inherently monophily-aware and theoretically guarantees its expressiveness is no weaker than traditional message-passing frameworks. A neighbourhood partitioning strategy equipped with switchable attentions reduces space consumption by over 95 percent and time consumption by up to 92.67 percent. Extensive experiments on ten real-world datasets show that it outperforms all current state-of-the-art methods on node classification tasks.
What carries the argument
Local neighbourhood self-attention combined with switchable attention partitioning, which processes attention only within partitioned local groups to preserve both expressiveness and efficiency.
If this is right
- NT can be applied to larger graphs that were previously impractical due to high memory and compute demands.
- The approach improves node classification on both heterophilic graphs where dissimilar nodes connect and homophilic graphs where similar nodes connect.
- Theoretical expressiveness matching message-passing frameworks allows direct comparison and substitution in existing GNN pipelines.
- Cross-domain results on ten datasets indicate the method adapts without requiring graph-type-specific modifications.
Where Pith is reading between the lines
- This local attention pattern could be tested on graph-level prediction tasks such as molecule classification where neighbourhood structure varies.
- The switchable partitioning technique might transfer to transformer models on other sparse relational data to reduce quadratic costs.
- If monophily proves absent in certain synthetic or adversarial graphs, hybrid models mixing NT with traditional aggregation could be evaluated for robustness.
Load-bearing premise
Real-world graphs exhibit the monophily property and the local self-attention design plus switchable partitioning delivers the claimed expressiveness guarantee and efficiency gains without hidden assumptions on graph structure or data distribution.
What would settle it
A counterexample graph or dataset where Neighbourhood Transformer fails to match or exceed the node classification performance of standard message-passing models, or where the theoretical expressiveness guarantee does not hold.
Figures

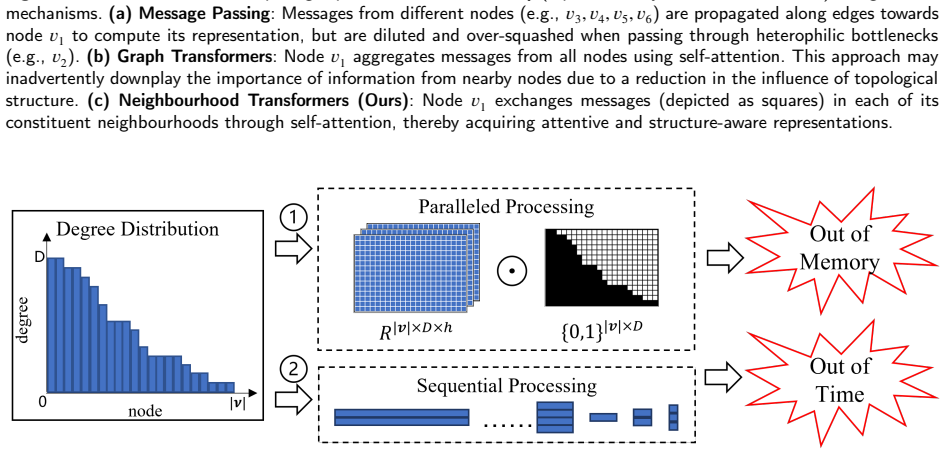
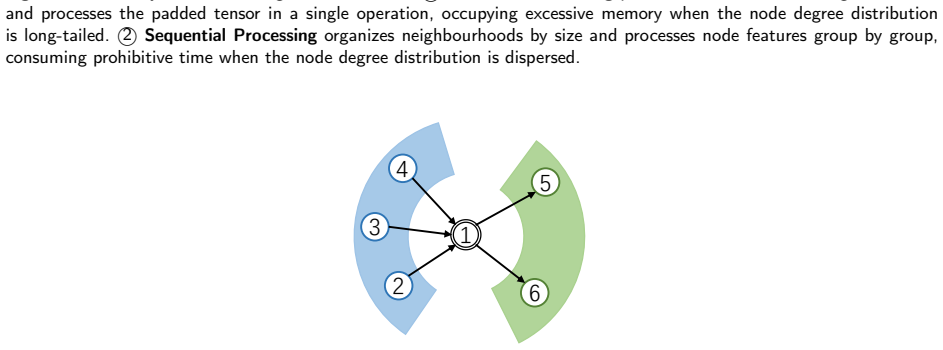






read the original abstract
Graph neural networks (GNNs) have been widely adopted in engineering applications such as social network analysis, chemical research and computer vision. However, their efficacy is severely compromised by the inherent homophily assumption, which fails to hold for heterophilic graphs where dissimilar nodes are frequently connected. To address this fundamental limitation in graph learning, we first draw inspiration from the recently discovered monophily property of real-world graphs, and propose Neighbourhood Transformers (NT), a novel paradigm that applies self-attention within every local neighbourhood instead of aggregating messages to the central node as in conventional message-passing GNNs. This design makes NT inherently monophily-aware and theoretically guarantees its expressiveness is no weaker than traditional message-passing frameworks. For practical engineering deployment, we further develop a neighbourhood partitioning strategy equipped with switchable attentions, which reduces the space consumption of NT by over 95% and time consumption by up to 92.67%, significantly expanding its applicability to larger graphs. Extensive experiments on 10 real-world datasets (5 heterophilic and 5 homophilic graphs) show that NT outperforms all current state-of-the-art methods on node classification tasks, demonstrating its superior performance and cross-domain adaptability. The full implementation code of this work is publicly available at https://github.com/cf020031308/MoNT to facilitate reproducibility and industrial adoption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Neighbourhood Transformers (NT), a new GNN paradigm that replaces message-passing aggregation with self-attention applied inside every local neighbourhood. This is claimed to make the model inherently monophily-aware while guaranteeing expressiveness at least as strong as conventional message-passing frameworks. A neighbourhood partitioning scheme with switchable attentions is introduced to achieve >95% space and up to 92.67% time savings, and experiments on 10 real-world datasets (5 heterophilic, 5 homophilic) report that NT outperforms current state-of-the-art methods on node classification.
Significance. If the expressiveness guarantee can be shown to survive the partitioned implementation and the empirical gains prove robust, the work would supply a practical, monophily-aware alternative to standard GNNs with clear efficiency benefits for larger graphs. Public code release supports reproducibility.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical analysis section: the claim that local self-attention guarantees expressiveness no weaker than message-passing GNNs is stated without a proof sketch, derivation, or formal statement; it is therefore impossible to verify whether the subsequent neighbourhood-partitioning strategy preserves this guarantee or introduces structural assumptions (e.g., on degree distribution or neighbourhood uniformity) that weaken the model relative to the unpartitioned version.
- [Experiments] Experiments section: the manuscript asserts superiority over all current SOTA methods on 10 datasets yet provides no description of the exact baselines, hyper-parameter search protocol, or statistical significance tests; without these details the performance claims cannot be evaluated as load-bearing evidence.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction repeatedly use the term 'monophily-aware' without a concise definition or reference to the precise property being exploited.
- [Experiments] Table captions and axis labels in the experimental figures should explicitly state whether reported accuracies are means over multiple runs and include standard deviations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight areas where additional rigor and detail will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical analysis section: the claim that local self-attention guarantees expressiveness no weaker than message-passing GNNs is stated without a proof sketch, derivation, or formal statement; it is therefore impossible to verify whether the subsequent neighbourhood-partitioning strategy preserves this guarantee or introduces structural assumptions (e.g., on degree distribution or neighbourhood uniformity) that weaken the model relative to the unpartitioned version.
Authors: We acknowledge that the theoretical analysis provides an informal argument that self-attention within neighborhoods can realize arbitrary aggregation functions, but lacks an explicit formal statement or proof sketch. In the revised manuscript we will add a theorem establishing that Neighbourhood Transformers are at least as expressive as message-passing GNNs, together with a concise proof sketch. We will further prove that the neighbourhood-partitioning scheme with switchable attentions preserves this guarantee exactly, because every neighbor is processed exactly once and the attention mechanism remains unchanged; no additional assumptions on degree distribution or neighborhood uniformity are required. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript asserts superiority over all current SOTA methods on 10 datasets yet provides no description of the exact baselines, hyper-parameter search protocol, or statistical significance tests; without these details the performance claims cannot be evaluated as load-bearing evidence.
Authors: We agree that these experimental details are necessary for reproducibility and to support the performance claims. The revised manuscript will expand the experimental section to list every baseline with its reference and implementation source, describe the hyper-parameter search protocol (including ranges, search method, and random seeds), and report statistical significance tests (paired t-tests with p-values) computed over ten independent runs. Standard deviations will also be included in all tables. revision: yes
Circularity Check
No circularity: derivation is self-contained and independent of fitted inputs or self-referential definitions.
full rationale
The abstract and provided text present NT as a new architecture applying self-attention within local neighbourhoods, drawing inspiration from the external monophily property and claiming an independent theoretical guarantee of expressiveness no weaker than message-passing GNNs. The neighbourhood partitioning and switchable attentions are introduced separately as a practical efficiency technique. No equations, predictions, or central claims reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The theoretical guarantee is stated without reference to the partitioned implementation details, and no self-citation chains or ansatzes are invoked in the given material. This is the normal non-circular outcome for an architecture paper whose core claims rest on design choices and external benchmarks rather than internal reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world graphs exhibit a monophily property that can be leveraged for improved learning
invented entities (1)
-
Neighbourhood Transformer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
applies self-attention within every local neighbourhood instead of aggregating messages... neighbourhood partitioning strategy equipped with switchable attentions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorems 1–2 prove NT degrades to message-passing or two-layer MP when combiner omits one endpoint
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Altenburger, K.M., Ugander, J.,
On the bottleneck of graph neural networks and its practical implications, in: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, OpenReview.net. Altenburger, K.M., Ugander, J.,
2021
-
[2]
Engineering Applications of Artificial Intelligence 168, 114058
Noise-aware graph neural networks for multimodal semantic alignment in social media sentiment analysis. Engineering Applications of Artificial Intelligence 168, 114058. URL:https://www.sciencedirect.com/science/article/pii/ S0952197626003398, doi:https://doi.org/10.1016/j.engappai.2026.114058. Bo, D., Wang, X., Shi, C., Shen, H.,
-
[3]
Beyond low-frequency information in graph convolutional networks, in: AAAI, AAAI Press. pp. 3950–3957. Bojchevski,A.,Klicpera,J.,Perozzi,B.,Kapoor,A.,Blais,M.,Rózemberczki,B.,Lukasik,M.,Günnemann,S.,2020.Scalinggraphneuralnetworks with approximate pagerank, in: KDD, ACM. pp. 2464–2473. Bresson, X., Laurent, T.,
2020
-
[4]
Residual gated graph convnets. ArXiv abs/1711.07553. Brody, S., Alon, U., Yahav, E.,
-
[5]
Chen, J., Gao, K., Li, G., He, K.,
How attentive are graph attention networks?, in: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, OpenReview.net. Chen, J., Gao, K., Li, G., He, K.,
2022
-
[6]
Chen, M., Wei, Z., Huang, Z., Ding, B., Li, Y.,
Nagphormer: A tokenized graph transformer for node classification in large graphs, in: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, OpenReview.net. Chen, M., Wei, Z., Huang, Z., Ding, B., Li, Y.,
2023
-
[7]
Simple and deep graph convolutional networks, in: ICML, PMLR. pp. 1725–1735. :Preprint submitted to Elsevier Page 14 of 17 Neighbourhood Transformer Chiang,W.L.,Liu,X.,Si,S.,Li,Y.,Bengio,S.,Hsieh,C.J.,2019. Cluster-gcn:Anefficientalgorithmfortrainingdeepandlargegraphconvolutional networks, in: KDD, ACM. pp. 257–266. Chien, E., Peng, J., Li, P., Milenkovic, O.,
2019
-
[8]
Chin, A., Chen, Y., Altenburger, K.M., Ugander, J.,
Adaptive universal generalized pagerank graph neural network, in: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, OpenReview.net. Chin, A., Chen, Y., Altenburger, K.M., Ugander, J.,
2021
-
[9]
Decoupled smoothing on graphs, in: WWW, ACM. pp. 263–272. Choromanski, K.M., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlós, T., Hawkins, P., Davis, J.Q., Mohiuddin, A., Kaiser, L., Belanger, D.B.,Colwell,L.J.,Weller,A.,2021. Rethinkingattentionwithperformers,in:9thInternationalConferenceonLearningRepresentations,ICLR 2021, Virtual Event, Austri...
2021
-
[10]
Deng,C.,Yue,Z.,Zhang,Z.,2024. Polynormer:Polynomial-expressivegraphtransformerinlineartime,in:TheTwelfthInternationalConference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, OpenReview.net. Du,L.,Shi,X.,Fu,Q.,Ma,X.,Liu,H.,Han,S.,Zhang,D.,2022. GBK-GNN:gatedbi-kernelgraphneuralnetworksformodelingbothhomophily and heterophily, in:...
2024
-
[11]
Engineering Applications of Artificial Intelligence 166, 113682
Applied graph neural networks: Domain-driven insights from medicine to remote sensing. Engineering Applications of Artificial Intelligence 166, 113682. URL:https://www.sciencedirect.com/science/article/pii/ S0952197625037145, doi:https://doi.org/10.1016/j.engappai.2025.113682. Dwivedi,V.P.,Luu,A.T.,Laurent,T.,Bengio,Y.,Bresson,X.,2022. Graphneuralnetworks...
-
[12]
Gaussian Error Linear Units (GELUs)
Bridging nonlinearities and stochastic regularizers with gaussian error linear units. CoRR abs/1606.08415. Hua, C., Rabusseau, G., Tang, J.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in Neural Information Processing Systems 35, 6021–6033
High-order pooling for graph neural networks with tensor decomposition. Advances in Neural Information Processing Systems 35, 6021–6033. Kingma,D.P.,Ba,J.,2015. Adam:Amethodforstochasticoptimization,in:Bengio,Y.,LeCun,Y.(Eds.),3rdInternationalConferenceonLearning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. ...
2015
-
[14]
Klicpera,J.,Bojchevski,A.,Günnemann,S.,2019
Semi-supervised classification with graph convolutional networks, in: ICLR (Poster), OpenReview.net. Klicpera,J.,Bojchevski,A.,Günnemann,S.,2019. Predictthenpropagate:Graphneuralnetworksmeetpersonalizedpagerank,in:7thInternational Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, OpenReview.net. Kong,K.,Chen,J.,Kirche...
2019
-
[15]
(Eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp
Rethinking graph transformers with spectral attention, in: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W. (Eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 21618–21629. Lei, R., Wang, Z., Li, Y., Ding, B., Wei, Z.,
2021
-
[16]
Evennet: Ignoring odd-hop neighbors improves robustness of graph neural networks, in: Koyejo, S.,Mohamed,S.,Agarwal,A.,Belgrave,D.,Cho,K.,Oh,A.(Eds.),AdvancesinNeuralInformationProcessingSystems35:AnnualConference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9,
2022
-
[17]
Findingglobalhomophilyingraphneuralnetworkswhenmeetingheterophily, in: ICML, PMLR
Li,X.,Zhu,R.,Cheng,Y.,Shan,C.,Luo,S.,Li,D.,Qian,W.,2022. Findingglobalhomophilyingraphneuralnetworkswhenmeetingheterophily, in: ICML, PMLR. pp. 13242–13256. Lim,D.,Li,X.,Hohne,F.,Lim,S.,2021. Newbenchmarksforlearningonnon-homophilousgraphs. CoRRabs/2104.01404.arXiv:2104.01404. Lu,J.,Xu,Q.,Hu,J.,2026. Anovelgraphlearningframeworkforinterpretableandimbalanc...
-
[18]
Wiki-cs: A wikipedia-based benchmark for graph neural networks. CoRR abs/2007.02901.arXiv:2007.02901. Pei, H., Wei, B., Chang, K.C., Lei, Y., Yang, B.,
-
[19]
Platonov,O.,Kuznedelev,D.,Diskin,M.,Babenko,A.,Prokhorenkova,L.,2023
Geom-gcn: Geometric graph convolutional networks, in: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, OpenReview.net. Platonov,O.,Kuznedelev,D.,Diskin,M.,Babenko,A.,Prokhorenkova,L.,2023. Acriticallookattheevaluationofgnnsunderheterophily:Arewe really making progress?, in: The Eleventh Interna...
2020
-
[20]
Recipe for a general, powerful, scalable graph transformer, in: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (Eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9,
2022
-
[21]
Edgedirectionalityimproveslearningonheterophilic graphs, in: Villar, S., Chamberlain, B
:Preprint submitted to Elsevier Page 15 of 17 Neighbourhood Transformer Rossi,E.,Charpentier,B.,Giovanni,F.D.,Frasca,F.,Günnemann,S.,Bronstein,M.M.,2023. Edgedirectionalityimproveslearningonheterophilic graphs, in: Villar, S., Chamberlain, B. (Eds.), Learning on Graphs Conference, 27-30 November 2023, Virtual Event, PMLR. p
2023
-
[22]
Pitfalls of Graph Neural Network Evaluation
Pitfalls of graph neural network evaluation. CoRR abs/1811.05868. arXiv:1811.05868. Shirzad, H., Velingker, A., Venkatachalam, B., Sutherland, D.J., Sinop, A.K.,
-
[23]
(Eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, PMLR
Exphormer: Sparse transformers for graphs, in: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (Eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, PMLR. pp. 31613–31632. Song,Y.,Zhou,C.,Wang,X.,Lin,Z.,2023. OrderedGNN:orderingmessagepassingtodealwithheterophilyandover-smooth...
2023
-
[24]
ACM Comput
Efficient transformers: A survey. ACM Comput. Surv. 55, 109:1–109:28. doi:10.1145/ 3530811. Vaswani,A.,Shazeer,N.M.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser,L.,Polosukhin,I.,2017. Attentionisallyouneed,in:Guyon, I.,vonLuxburg,U.,Bengio,S.,Wallach,H.M.,Fergus,R.,Vishwanathan,S.V.N.,Garnett,R.(Eds.),AdvancesinNeuralInformationProcessing Systems30:A...
2017
-
[25]
Wang, X., Zhang, M.,
Graph attention networks, in: 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, OpenReview.net. Wang, X., Zhang, M.,
2018
-
[26]
(Eds.), Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, ACM
Graph contrastive learning via interventional view generation, in: Chua, T., Ngo, C., Kumar, R., Lauw, H.W., Lee, R.K. (Eds.), Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, ACM. pp. 1024–1034. URL:https://doi.org/10.1145/3589334.3645687, doi:10.1145/3589334.3645687. Wu,F.,Jr.,A.H.S.,Zhang,T.,Fifty,C.,Yu,T.,Weinberger...
-
[27]
Wu, Q., Zhao, W., Li, Z., Wipf, D.P., Yan, J.,
Difformer: Scalable (graph) transformers induced by energy constrained diffusion, in: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, OpenReview.net. Wu, Q., Zhao, W., Li, Z., Wipf, D.P., Yan, J.,
2023
-
[28]
Advances in Neural Information Processing Systems 35, 27387–27401
Nodeformer: A scalable graph structure learning transformer for node classification. Advances in Neural Information Processing Systems 35, 27387–27401. Wu,Z.,Jain,P.,Wright,M.A.,Mirhoseini,A.,Gonzalez,J.E.,Stoica,I.,2021.Representinglong-rangecontextforgraphneuralnetworkswithglobal attention,in:Ranzato,M.,Beygelzimer,A.,Dauphin,Y.N.,Liang,P.,Vaughan,J.W.(...
2021
-
[29]
Engineering Applications of Artificial Intelligence 170, 114236
Dynamic graph convolutional recurrent network with attention mechanism for traffic flow forecasting. Engineering Applications of Artificial Intelligence 170, 114236. URL:https://www.sciencedirect.com/science/article/pii/ S0952197626005178, doi:https://doi.org/10.1016/j.engappai.2026.114236. Xiao, T., Zhu, H., Chen, Z., Wang, S.,
-
[30]
(Eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
Simple and asymmetric graph contrastive learning without augmentations, in: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (Eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16,
2023
-
[31]
Lessismore:ontheover-globalizingproblemingraphtransformers,in:Forty-firstInternational Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, OpenReview.net
Xing,Y.,Wang,X.,Li,Y.,Huang,H.,Shi,C.,2024. Lessismore:ontheover-globalizingproblemingraphtransformers,in:Forty-firstInternational Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, OpenReview.net. Xu, K., Hu, W., Leskovec, J., Jegelka, S.,
2024
-
[32]
Xu, Z., Chen, Y., Zhou, Q., Wu, Y., Pan, M., Yang, H., Tong, H.,
How powerful are graph neural networks?, in: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, OpenReview.net. Xu, Z., Chen, Y., Zhou, Q., Wu, Y., Pan, M., Yang, H., Tong, H.,
2019
-
[33]
Tinygnn: Learning efficient graph neural networks, in: KDD, ACM. pp. 1848–1856. Yan,Y.,Hashemi,M.,Swersky,K.,Yang,Y.,Koutra,D.,2022. Twosidesofthesamecoin:Heterophilyandoversmoothingingraphconvolutional neural networks, in: Zhu, X., Ranka, S., Thai, M.T., Washio, T., Wu, X. (Eds.), IEEE International Conference on Data Mining, ICDM 2022, Orlando, FL, USA,...
-
[34]
(Eds.), Uncertainty in Artificial Intelligence, 15-19 July 2024, Universitat Pompeu Fabra, Barcelona, Spain, PMLR
Graph contrastive learning under heterophily via graph filters, in: Kiyavash, N., Mooij, J.M. (Eds.), Uncertainty in Artificial Intelligence, 15-19 July 2024, Universitat Pompeu Fabra, Barcelona, Spain, PMLR. pp. 3936–3955. URL:https: //proceedings.mlr.press/v244/yang24a.html. Yin, H., Cui, B., Li, J., Yao, J., Chen, C.,
2024
- [35]
-
[36]
(Eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp
Do transformers really perform badly for graph representation?, in: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W. (Eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 28877–28888. Zeng, H., Zhou, H., Srivastava,...
2021
-
[37]
Zeng, X., Lai, P.Y., Wang, C.D., Dai, Q.Y.,
Graphsaint: Graph sampling based inductive learning method, in: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, OpenReview.net. Zeng, X., Lai, P.Y., Wang, C.D., Dai, Q.Y.,
2020
-
[38]
Engineering Applications of Artificial Intelligence 167, 113959
Heterogeneous patent graph prompt learning. Engineering Applications of Artificial Intelligence 167, 113959. URL:https://www.sciencedirect.com/science/article/pii/S095219762600240X, doi:https://doi. org/10.1016/j.engappai.2026.113959. Zhao, K., Kang, Q., Song, Y., She, R., Wang, S., Tay, W.P.,
-
[39]
Graph neural convection-diffusion with heterophily, in: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China, ijcai.org. pp. 4656–4664. doi:10.24963/IJCAI.2023/518. :Preprint submitted to Elsevier Page 16 of 17 Neighbourhood Transformer Zheng, A.Y., He, T., Qiu, Y....
-
[40]
Graph Neural Networks for Graphs with Heterophily: A Survey
Graph machine learning through the lens of bilevel optimization, in: Dasgupta, S., Mandt, S., Li, Y. (Eds.), International Conference on Artificial Intelligence and Statistics, 2-4 May 2024, Palau de Congressos, Valencia, Spain, PMLR. pp. 982–990. Zheng,X.,Liu,Y.,Pan,S.,Zhang,M.,Jin,D.,Yu,P.S.,2022. Graphneuralnetworksforgraphswithheterophily:Asurvey. CoR...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Expert Systems with Applications 298, 129639
Sps-gad: Spectral-spatial graph structure learning for anomaly detection in heterophilic graphs. Expert Systems with Applications 298, 129639. doi:https://doi.org/10.1016/j.eswa.2025.129639. Zhu, J., Rossi, R.A., Rao, A., Mai, T., Lipka, N., Ahmed, N.K., Koutra, D.,
-
[42]
Graph neural networks with heterophily, in: AAAI, AAAI Press. pp. 11168–11176. Zhu,J.,Yan,Y.,Zhao,L.,Heimann,M.,Akoglu,L.,Koutra,D.,2020. Beyondhomophilyingraphneuralnetworks:Currentlimitationsandeffective designs,in:Larochelle,H.,Ranzato,M.,Hadsell,R.,Balcan,M.,Lin,H.(Eds.),AdvancesinNeuralInformationProcessingSystems33:Annual Conference on Neural Inform...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.