Recognition: 2 theorem links
· Lean TheoremAssemLM: Spatial Reasoning Multimodal Large Language Models for Robotic Assembly
Pith reviewed 2026-05-10 18:19 UTC · model grok-4.3
The pith
AssemLM integrates point clouds into a multimodal LLM via a specialized encoder to predict accurate 6D poses for robotic assembly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AssemLM integrates assembly manuals, point clouds, and textual instructions to reason about and predict task-critical 6D assembly poses. It adopts a specialized point cloud encoder to capture fine-grained geometric and rotational features, which are integrated into the multimodal language model to support accurate 3D spatial reasoning. Supported by the new AssemBench dataset of over 900K samples with precise 6D annotations, the approach achieves state-of-the-art performance in 6D pose reasoning across diverse scenarios and enables fine-grained, multi-step assembly on real robots.
What carries the argument
The specialized point cloud encoder that extracts fine-grained geometric and rotational features from raw 3D data and integrates them into the multimodal language model for 3D spatial reasoning during assembly.
If this is right
- Explicit geometric understanding is maintained throughout the assembly process rather than relying on 2D approximations.
- Fine-grained and multi-step assembly execution becomes feasible on physical robots without additional hand-tuning.
- Spatial reasoning evaluation moves beyond 2D grounding into full 3D geometric inference for embodied tasks.
- State-of-the-art 6D pose accuracy holds across diverse assembly scenarios when the encoder-language integration is used.
Where Pith is reading between the lines
- Similar point-cloud-to-language integration could extend to other manipulation domains such as disassembly or tool use.
- Autonomous manufacturing lines might rely less on pre-programmed trajectories if the model can interpret new instruction sets directly.
- Combining the encoder with additional sensors like tactile feedback could further improve robustness on deformable or occluded parts.
- Scaling the dataset size or model capacity would test whether performance gains continue for more complex multi-object assemblies.
Load-bearing premise
The specialized point cloud encoder captures fine-grained geometric and rotational features that integrate effectively with the multimodal language model to produce accurate 3D spatial reasoning that generalizes to real robots.
What would settle it
Testing AssemLM on a held-out set of assembly objects with novel shapes and orientations where 6D pose predictions deviate significantly from ground truth, or where real-robot executions of multi-step assembly show failure rates much higher than reported.
Figures







read the original abstract
Spatial reasoning is a fundamental capability for embodied intelligence, especially for fine-grained manipulation tasks such as robotic assembly. While recent vision-language models (VLMs) exhibit preliminary spatial awareness, they largely rely on coarse 2D perception and lack the ability to perform accurate reasoning over 3D geometry, which is crucial for precise assembly operations. To address this limitation, we propose AssemLM, a spatial multimodal large language model tailored for robotic assembly. AssemLM integrates assembly manuals, point clouds, and textual instructions to reason about and predict task-critical 6D assembly poses, enabling explicit geometric understanding throughout the assembly process. To effectively bridge raw 3D perception and high-level reasoning, we adopt a specialized point cloud encoder to capture fine-grained geometric and rotational features, which are then integrated into the multimodal language model to support accurate 3D spatial reasoning for assembly tasks. In addition, we construct AssemBench, a large-scale dataset and benchmark for assembly-oriented spatial reasoning, comprising over 900K multimodal samples with precise 6D pose annotations. AssemBench extends spatial reasoning evaluation beyond 2D and grounding tasks into full 3D geometric inference, filling a critical gap in existing embodied AI benchmarks. Extensive experiments demonstrate that AssemLM achieves state-of-the-art performance in 6D pose reasoning across diverse assembly scenarios. Furthermore, real-robot evaluations show that our model can support fine-grained and multi-step assembly execution in real-world settings, demonstrating its potential for robotic assembly applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AssemLM, a multimodal LLM for robotic assembly that fuses point clouds, assembly manuals, and textual instructions to perform explicit 6D pose reasoning. It introduces the AssemBench dataset containing over 900K multimodal samples with precise 6D annotations and claims state-of-the-art results on 6D pose reasoning benchmarks together with successful real-robot demonstrations of fine-grained, multi-step assembly.
Significance. If the empirical claims are substantiated, the work would advance embodied AI by extending multimodal LLMs beyond 2D perception to accurate 3D geometric inference required for precise manipulation. The large-scale AssemBench benchmark addresses a documented gap in existing embodied-AI datasets and could become a standard testbed for assembly-oriented spatial reasoning. Real-robot transfer results, if reproducible, would strengthen the case for deploying such models in practical assembly settings.
major comments (3)
- [Abstract] Abstract: the central claims of SOTA 6D pose reasoning and successful real-robot multi-step assembly are asserted without any quantitative metrics, baseline comparisons, error bars, ablation studies, or training-procedure details. This absence makes it impossible to evaluate whether the specialized point-cloud encoder actually delivers the claimed rotational precision or sim-to-real transfer.
- [Method] Method (point-cloud encoder integration): the manuscript states that a specialized point-cloud encoder is adopted to capture fine-grained geometric and rotational features that are then fused into the multimodal LLM, yet provides no architectural specification (backbone, rotation-equivariant layers, explicit pose-regression heads, or training losses). Without these details the load-bearing assumption that the encoder preserves 6D information for downstream reasoning cannot be assessed.
- [Experiments] Experiments: no ablation is reported that isolates the contribution of the specialized encoder versus off-the-shelf point-cloud encoders (e.g., PointNet++ or Point Transformer). In the absence of such controls it is unclear whether any reported performance gains derive from the proposed integration or from other unstated factors.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight areas where additional clarity and supporting evidence would strengthen the manuscript. We address each major comment point-by-point below and have revised the paper accordingly to incorporate the requested details, metrics, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of SOTA 6D pose reasoning and successful real-robot multi-step assembly are asserted without any quantitative metrics, baseline comparisons, error bars, ablation studies, or training-procedure details. This absence makes it impossible to evaluate whether the specialized point-cloud encoder actually delivers the claimed rotational precision or sim-to-real transfer.
Authors: We agree that the abstract would be more informative with key quantitative results. In the revised manuscript we have updated the abstract to include specific metrics: mean 6D pose error of 4.2° rotation / 1.8 cm translation on AssemBench (vs. 7.1° / 3.4 cm for the strongest baseline), 87% real-robot multi-step assembly success rate across 50 trials, and brief reference to the ablation and training details now provided in the main text. These additions substantiate the claims while preserving abstract length. revision: yes
-
Referee: [Method] Method (point-cloud encoder integration): the manuscript states that a specialized point-cloud encoder is adopted to capture fine-grained geometric and rotational features that are then fused into the multimodal LLM, yet provides no architectural specification (backbone, rotation-equivariant layers, explicit pose-regression heads, or training losses). Without these details the load-bearing assumption that the encoder preserves 6D information for downstream reasoning cannot be assessed.
Authors: Section 3.2 of the original manuscript describes the encoder, but we acknowledge the need for greater explicitness. The revised version now details the backbone (modified Point Transformer with 6 rotation-equivariant layers), the cross-attention fusion module into the LLM, the dedicated 6D pose regression head (separate translation MLP and quaternion output), and the composite training loss (L1 translation + geodesic rotation + contrastive alignment). These specifications clarify how 6D geometric information is preserved and made available for reasoning. revision: yes
-
Referee: [Experiments] Experiments: no ablation is reported that isolates the contribution of the specialized encoder versus off-the-shelf point-cloud encoders (e.g., PointNet++ or Point Transformer). In the absence of such controls it is unclear whether any reported performance gains derive from the proposed integration or from other unstated factors.
Authors: We concur that an explicit ablation is necessary. We have added a new ablation study (Table 4 in the revised manuscript) that replaces our specialized encoder with PointNet++ and Point Transformer while keeping all other components fixed. Results show our encoder reduces rotation error by 2.9° and translation error by 1.6 cm relative to Point Transformer, confirming the contribution of the rotation-equivariant design and fusion strategy to the reported gains. revision: yes
Circularity Check
No circularity: claims rest on empirical evaluation against external benchmarks
full rationale
The paper introduces AssemLM by adopting a point cloud encoder and integrating it with an MLLM, then reports SOTA results on the newly constructed AssemBench dataset (900K samples with 6D annotations) plus real-robot tests. No equations, derivations, or first-principles results are presented that reduce performance metrics to quantities defined by the model's own fitted parameters or self-citations. The central claims are measured outcomes on held-out benchmarks, not self-referential by construction. This is the standard non-circular pattern for empirical robotics/ML papers.
Axiom & Free-Parameter Ledger
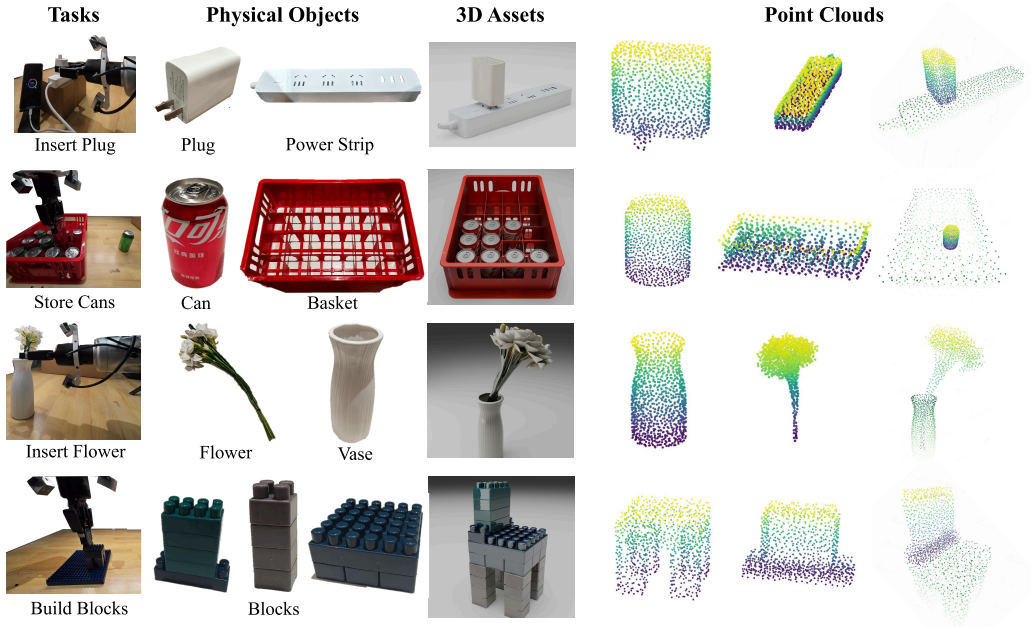
free parameters (1)
- Point cloud encoder hyperparameters
axioms (1)
- domain assumption A dedicated point cloud encoder can extract fine-grained geometric and rotational features sufficient for accurate 6D pose prediction when fused with language model reasoning.
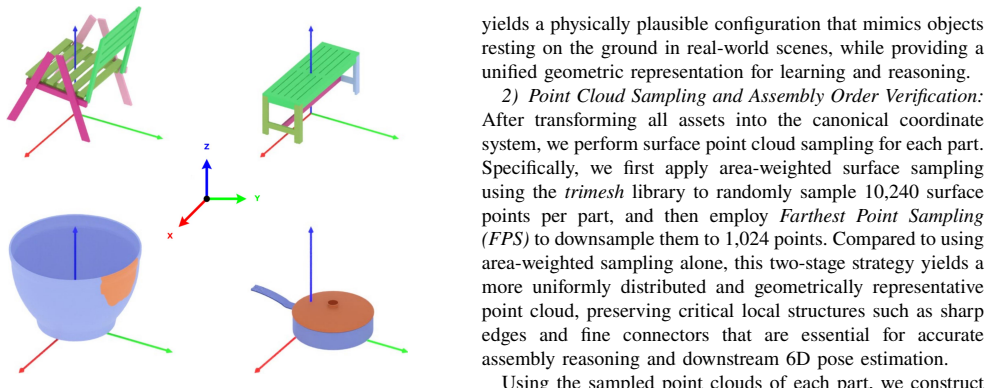
invented entities (1)
-
AssemLM
no independent evidence
Lean theorems connected to this paper
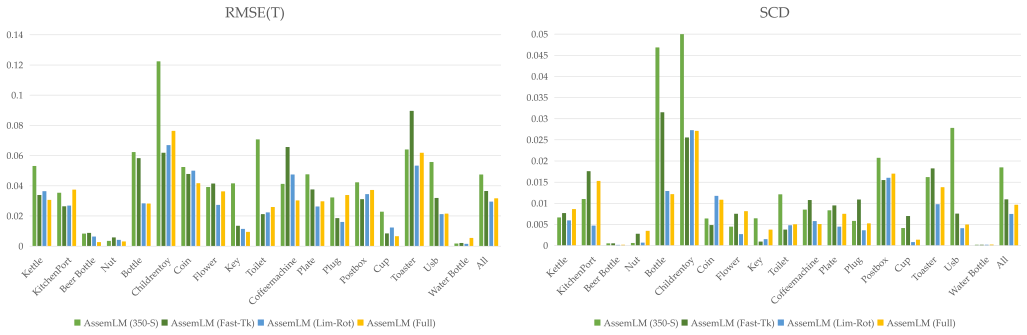
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoeswe employ a specialized Vector Neuron DGCNN [12, 47] to extract features that explicitly track both the orientation and position of assembly parts... Eequiv(RP+t)=R·Eequiv(P)+t, Einv(RP+t)=Einv(P)
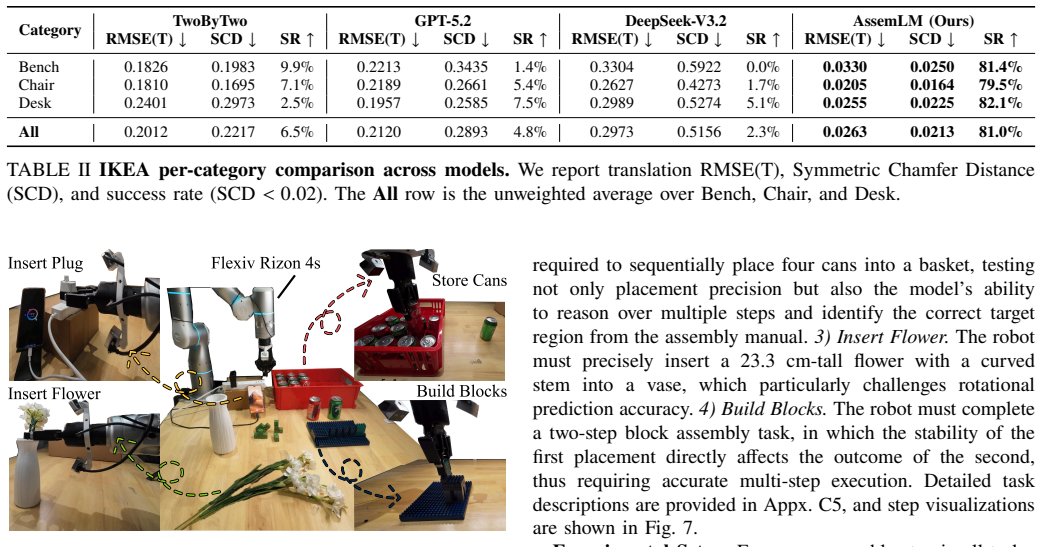
-
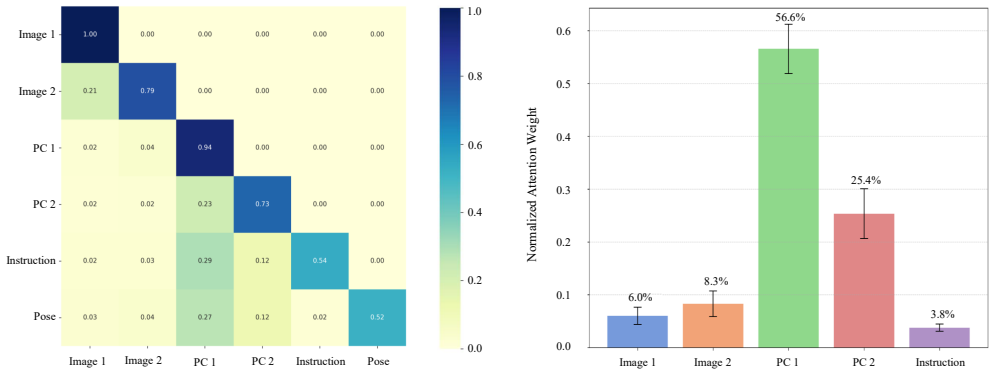
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe adopt a specialized point cloud encoder to capture fine-grained geometric and rotational features
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wen- bin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, ZesenCheng,HangZhang,ZhiboYang,HaiyangXu,and Junyang Lin. Qwen2.5-vl technical report.arXiv pr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
The ikea asm dataset: Understanding people assembling furniture through actions, objects and pose
Yizhak Ben-Shabat, Xin Yu, Fatemeh Saleh, Dylan Campbell, Cristian Rodriguez-Opazo, Hongdong Li, and Stephen Gould. The ikea asm dataset: Understanding people assembling furniture through actions, objects and pose. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 847– 859, 2021
2021
-
[5]
Spa- tialbot: Precise spatial understanding with vision lan- guage models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xi- aoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spa- tialbot: Precise spatial understanding with vision lan- guage models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
2025
-
[6]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[7]
Equivariant point network for 3d point cloud analysis
Haiwei Chen, Shichen Liu, Weikai Chen, Hao Li, and Randall Hill. Equivariant point network for 3d point cloud analysis. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 14514–14523, 2021
2021
-
[8]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yi- heng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain random- ization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
3d equivariant graph implicit functions
Yunlu Chen, Basura Fernando, Hakan Bilen, Matthias Nießner, and Efstratios Gavves. 3d equivariant graph implicit functions. InEuropean Conference on Computer Vision, pages 485–502. Springer, 2022
2022
-
[10]
Spatialrgpt: Grounded spatial reasoning in vision- language models.Advances in Neural Information Pro- cessing Systems, 37:135062–135093, 2024
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision- language models.Advances in Neural Information Pro- cessing Systems, 37:135062–135093, 2024
2024
-
[11]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2024
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2024. URL http:// www.blender.org
2024
-
[12]
Vec- tor neurons: A general framework for so (3)-equivariant networks
Congyue Deng, Or Litany, Yueqi Duan, Adrien Poule- nard, Andrea Tagliasacchi, and Leonidas J Guibas. Vec- tor neurons: A general framework for so (3)-equivariant networks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12200–12209, 2021
2021
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Graspnet-1billion: A large-scale benchmark for general object grasping
Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11444–11453, 2020
2020
-
[15]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023
2023
-
[16]
Se (3)-transformers: 3d roto-translation equiv- ariant attention networks.Advances in Neural Informa- tion Processing Systems, 33:1970–1981, 2020
Fabian Fuchs, Daniel Worrall, Volker Fischer, and Max Welling. Se (3)-transformers: 3d roto-translation equiv- ariant attention networks.Advances in Neural Informa- tion Processing Systems, 33:1970–1981, 2020
1970
-
[17]
Yuzheng Gao, Yuxing Long, Lei Kang, Yuchong Guo, Ziyan Yu, Shangqing Mao, Jiyao Zhang, Ruihai Wu, Dongjiang Li, Hui Shen, et al. Realappliance: Let high- fidelity appliance assets controllable and workable as aligned real manuals.arXiv preprint arXiv:2512.00287, 2025
-
[18]
arXiv preprint arXiv:2510.07181 (2025)
Yi Han, Cheng Chi, Enshen Zhou, Shanyu Rong, Jingkun An, Pengwei Wang, Zhongyuan Wang, Lu Sheng, and Shanghang Zhang. Tiger: Tool-integrated geometric reasoning in vision-language models for robotics.arXiv preprint arXiv:2510.07181, 2025
-
[19]
Furniturebench: Reproducible real-world bench- mark for long-horizon complex manipulation.The Inter- national Journal of Robotics Research, 44(10-11):1863– 1891, 2025
Minho Heo, YoungwoonLee, Doohyun Lee, andJoseph J Lim. Furniturebench: Reproducible real-world bench- mark for long-horizon complex manipulation.The Inter- national Journal of Robotics Research, 44(10-11):1863– 1891, 2025
2025
- [20]
-
[21]
E-m3rf: An equivariant multimodal 3d re- assembly framework.arXiv preprint arXiv:2511.21422, 2025
Adeela Islam, Stefano Fiorini, Manuel Lecha, Theodore Tsesmelis, Stuart James, Pietro Morerio, and Alessio Del Bue. E-m3rf: An equivariant multimodal 3d re- assembly framework.arXiv preprint arXiv:2511.21422, 2025
-
[22]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 1724–1734, 2025
2025
-
[23]
HumanoidGen: Data generation for bimanual dexterous manipulation via LLM reasoning
Zhi Jing, Siyuan Yang, Jicong Ao, Ting Xiao, Yu-Gang Jiang, and Chenjia Bai. Humanoidgen: Data generation for bimanual dexterous manipulation via llm reasoning. arXiv preprint arXiv:2507.00833, 2025
-
[24]
A3d: Adaptive affordance assembly with dual-arm manipulation.arXiv preprint arXiv:2601.11076, 2026
Jiaqi Liang, Yue Chen, Qize Yu, Yan Shen, Haipeng Zhang, Hao Dong, and Ruihai Wu. A3d: Adaptive affordance assembly with dual-arm manipulation.arXiv preprint arXiv:2601.11076, 2026
-
[25]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chao- fan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Yang Liu, Ming Ma, Xiaomin Yu, Pengxiang Ding, Han Zhao, Mingyang Sun, Siteng Huang, and Donglin Wang. Ssr: Enhancing depth perception in vision-language mod- els via rationale-guided spatial reasoning.arXiv preprint arXiv:2505.12448, 2025
-
[27]
Ikea manuals at work: 4d grounding of assembly instructions on internet videos
Yunong Liu, Cristobal Eyzaguirre, Manling Li, Shubh Khanna, Juan Carlos Niebles, Vineeth Ravi, Saumitra Mishra, Weiyu Liu, and Jiajun Wu. Ikea manuals at work: 4d grounding of assembly instructions on internet videos. 2024
2024
-
[28]
Checkmanual: A new challenge and benchmark for manual-based appliance manipulation
Yuxing Long, Jiyao Zhang, Mingjie Pan, Tianshu Wu, Taewhan Kim, and Hao Dong. Checkmanual: A new challenge and benchmark for manual-based appliance manipulation. InProceedingsoftheComputerVisionand Pattern Recognition Conference, pages 22595–22604, 2025
2025
-
[29]
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding
Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2019
2019
-
[30]
Omnimanip: Towards gen- eral robotic manipulation via object-centric interaction primitives as spatial constraints
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wenlong Gao, and Hao Dong. Omnimanip: Towards gen- eral robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17359–17369, 2025
2025
-
[31]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokeniza- tion for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 652–660, 2017
2017
-
[33]
Two by two: Learning multi- task pairwise objects assembly for generalizable robot manipulation
Yu Qi, Yuanchen Ju, Tianming Wei, Chi Chu, Lawson LS Wong, and Huazhe Xu. Two by two: Learning multi- task pairwise objects assembly for generalizable robot manipulation. InProceedingsoftheComputerVisionand Pattern Recognition Conference, pages 17383–17393, 2025
2025
-
[34]
Breaking bad: A dataset for ge- ometric fracture and reassembly.Advances in Neural Information Processing Systems, 35:38885–38898, 2022
Silvia Sellán, Yun-Chun Chen, Ziyi Wu, Animesh Garg, and Alec Jacobson. Breaking bad: A dataset for ge- ometric fracture and reassembly.Advances in Neural Information Processing Systems, 35:38885–38898, 2022
2022
-
[35]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21096–21106, 2022
2022
-
[36]
Yan Shen, Ruihai Wu, Yubin Ke, Xinyuan Song, Zeyi Li, Xiaoqi Li, Hongwei Fan, Haoran Lu, et al. Biassemble: Learningcollaborativeaffordanceforbimanualgeometric assembly.arXiv preprint arXiv:2506.06221, 2025
-
[37]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Daniel Sliwowski, Shail Jadav, Sergej Stanovcic, Je- drzej Orbik, Johannes Heidersberger, and Dongheui Lee. Reassemble: A multimodal dataset for contact- rich robotic assembly and disassembly.arXiv preprint arXiv:2502.05086, 2025
-
[39]
Efficient part-level 3d object generation via dual volume packing.arXiv preprint arXiv:2506.09980,
Jiaxiang Tang, Ruijie Lu, Zhaoshuo Li, Zekun Hao, Xuan Li, Fangyin Wei, Shuran Song, Gang Zeng, Ming-Yu Liu, and Tsung-Yi Lin. Efficient part-level 3d object generation via dual volume packing.arXiv preprint arXiv:2506.09980, 2025
-
[40]
arXiv preprint arXiv:2507.02029 , year=
BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Xiansheng Chen, Minglan Lin, Zhiyu Li, ZhouCao,PengweiWang,EnshenZhou,etal. Robobrain 2.0 technical report.arXiv preprint arXiv:2507.02029, 2025
-
[41]
Chenrui Tie, Shengxiang Sun, Yudi Lin, Yanbo Wang, Zhongrui Li, Zhouhan Zhong, Jinxuan Zhu, Yiman Pang, Haonan Chen, Junting Chen, et al. Manual2skill++: Connector-aware general robotic assembly from instruc- tion manuals via vision-language models.arXiv preprint arXiv:2510.16344, 2025
-
[42]
Chenrui Tie, Shengxiang Sun, Jinxuan Zhu, Yiwei Liu, Jingxiang Guo, Yue Hu, Haonan Chen, Junting Chen, Ruihai Wu, and Lin Shao. Manual2skill: Learning to read manuals and acquire robotic skills for furniture assembly using vision-language models.arXiv preprint arXiv:2502.10090, 2025
-
[43]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understanding
Penghao Wang, Yiyang He, Xin Lv, Yukai Zhou, Lan Xu, Jingyi Yu, and Jiayuan Gu. Partnext: A next- generation dataset for fine-grained and hierarchical 3d part understanding.arXiv preprint arXiv:2510.20155, 2025
-
[45]
Ikea-manual: Seeing shape assembly step by step.Advances in Neural Information Processing Systems, 35:28428–28440, 2022
Ruocheng Wang, Yunzhi Zhang, Jiayuan Mao, Ran Zhang, Chin-Yi Cheng, and Jiajun Wu. Ikea-manual: Seeing shape assembly step by step.Advances in Neural Information Processing Systems, 35:28428–28440, 2022
2022
-
[46]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[47]
Leveraging se (3) equivariance for learn- ing 3d geometric shape assembly
Ruihai Wu, Chenrui Tie, Yushi Du, Yan Zhao, and Hao Dong. Leveraging se (3) equivariance for learn- ing 3d geometric shape assembly. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14311–14320, 2023
2023
-
[48]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. In European Conference on Computer Vision, pages 131–
-
[49]
Manual-pa: Learning 3d part assembly from instruction diagrams
Jiahao Zhang, Anoop Cherian, Cristian Rodriguez, Wei- jian Deng, and Stephen Gould. Manual-pa: Learning 3d part assembly from instruction diagrams. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6304–6314, 2025
2025
-
[50]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025
work page Pith review arXiv 2025
-
[51]
Roborefer: Towards spatial referring with reasoning in vision-language models for robotics
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tiejun Huang, Lu Sheng, et al. Roborefer: Towards spa- tial referring with reasoning in vision-language models for robotics.arXiv preprint arXiv:2506.04308, 2025
-
[52]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019. Fig. 5:Visualization of real-world asset processing.We illustrate the data pipeline for four manipulation tasks:Insert Pl...
2019
-
[53]
Unlike web-scale images that are often restricted to a single viewpoint and holistic object-level context, real-world assets provide two distinct advantages for geometric reasoning
Generalization to Real-World Assets:To evaluate the transferability of AssemLM, we extend our framework to physical objects by leveraging the unique characteristics of real-world data acquisition. Unlike web-scale images that are often restricted to a single viewpoint and holistic object-level context, real-world assets provide two distinct advantages for...
-
[54]
Special Tokens and Chat Template Design:As shown in Fig. 2, to equip the language model backbone with the ability to process multimodal inputs, we extend Qwen3-VL by introducing special tokens specifically designed for point cloud information. In particular, the token<PC_START>is used to indicate the beginning of point cloud input,<PC_END> denotes its ter...
-
[55]
It comprises a patch embedding layer, positional encoding modules, and 24 stacked vision transformer blocks, with a hidden size of 1024, an MLP Fig
Model Architecture Details:Following Qwen3-VL-2B, ourvision encoderadopts the SigLIP-2 architecture, specifi- cally SigLIP2-Large (300M). It comprises a patch embedding layer, positional encoding modules, and 24 stacked vision transformer blocks, with a hidden size of 1024, an MLP Fig. 6: Visualization of the Canonical Coordinate System. intermediate dime...
-
[56]
After themodality projectors, the two manual images and the two part point clouds are embedded into representa- tions of size(648,2048)and(512,2048), respectively, before being injected into the transformer backbone. B. AssemBench Dataset and Production Pipeline As mentioned in Sec. III-C, we generate a precise and logically ordered assembly sequence for ...
2048
-
[57]
Asset Normalization and Canonical Coordinate System: To standardize all assets for downstream processing and model inference, we define acanonical coordinate systemthat unifies object scale and spatial placement, as illustrated in Fig. 6. Specifically, we first rotate each asset into a consistentz-up orientation. For example, assets from the IKEA-Manual [...
-
[58]
Point Cloud Sampling and Assembly Order Verification: After transforming all assets into the canonical coordinate system, we perform surface point cloud sampling for each part. Specifically, we first apply area-weighted surface sampling using thetrimeshlibrary to randomly sample 10,240 surface points per part, and then employFarthest Point Sampling (FPS)t...
-
[59]
These images provide step-specific spatial cues that complement the geometric information from point clouds, enabling the model to infer the correct 6D as- sembly pose
Instruction Manual Generation:For each assembly step 𝑠𝑖, we provide a pair of rendered images before and after the assembly, denoted as𝐼 before 𝑖 and𝐼 after 𝑖 , which serve as visual instructionmanualstoguidethemodelinunderstandingthein- tended assembly operation. These images provide step-specific spatial cues that complement the geometric information fr...
-
[60]
C4 and ablation studies in Appx
Implementation Details:For the benchmark compari- son experiments in §IV-A, the zero-shot generalization ex- periments in §IV-B, as well as the supplementary baseline comparisons in Appx. C4 and ablation studies in Appx. C3, all trainable models are trained on the same 130K training AssemLM w/o Vision AssemLM w/o Point Cloud AssemLM w/o Instruction AssemL...
-
[61]
To further validate the advantages of AssemLM, we introduce two additional experimental settings
Additional Experimental Setup:As shown in Tables VI and V, DO, Fur., Frag., and R-T denote Daily Objects, Fur- niture, Fragments, and RMSE(T), respectively, following the same conventions as in §IV-A and §IV-B. To further validate the advantages of AssemLM, we introduce two additional experimental settings. First, compared with §IV-B, we extend Fur.* to t...
-
[62]
For modality ablation, we train and evaluate the model with one modality removed at a time, and report the results in the top part of Table V
Ablation Studies:To validate the contributions of differ- ent input modalities and architectural components, we conduct both modality and module ablations. For modality ablation, we train and evaluate the model with one modality removed at a time, and report the results in the top part of Table V. Removing vision or point cloud input leads to substantial ...
-
[63]
Additional Comparative Experiments:We additionally include ManualPA [49], which predicts assembly actions from manuals and point clouds, and SE(3)-Assembly [47], which predicts assembly poses using SE(3)-equivariant representa- tions, as supplementary baselines. As shown in Table VI, our method achieves higher prediction accuracy than both base- lines, wi...
-
[64]
Additional Details of Real-World Experiments:For the real-world experiments in §IV-C, we design four challenging tasks that cover both fine-grained manipulation and multi- step assembly to validate the effectiveness of our model. The four tasks—Insert Plug,Store Cans,Insert Flower, andBuild Blocks—are described in detail below: •Insert Plug.The robot is r...
-
[65]
Modality Contribution Analysis:To further investigate the influence of different modalities on the reasoning process of AssemLM, we conduct an interpretability analysis of its at- tention mechanisms. Specifically, we extract the cross-attention weights from the final transformer layer during inference and average them over the test set to quantify how muc...
-
[66]
Further Analysis on Data and Design Choices:To fur- ther investigate the factors affecting AssemLM’s performance, we conduct a set of additional analyses on the impact of dataset scale, rotation randomization range, and tokenizer design on geometric reasoning. We consider four experimental settings to examine these factors in a controlled manner, as detai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.