Recognition: unknown
ActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning
Pith reviewed 2026-05-10 16:41 UTC · model grok-4.3
The pith
ActFER turns facial expression recognition into an active process of tool-guided local inspection and reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
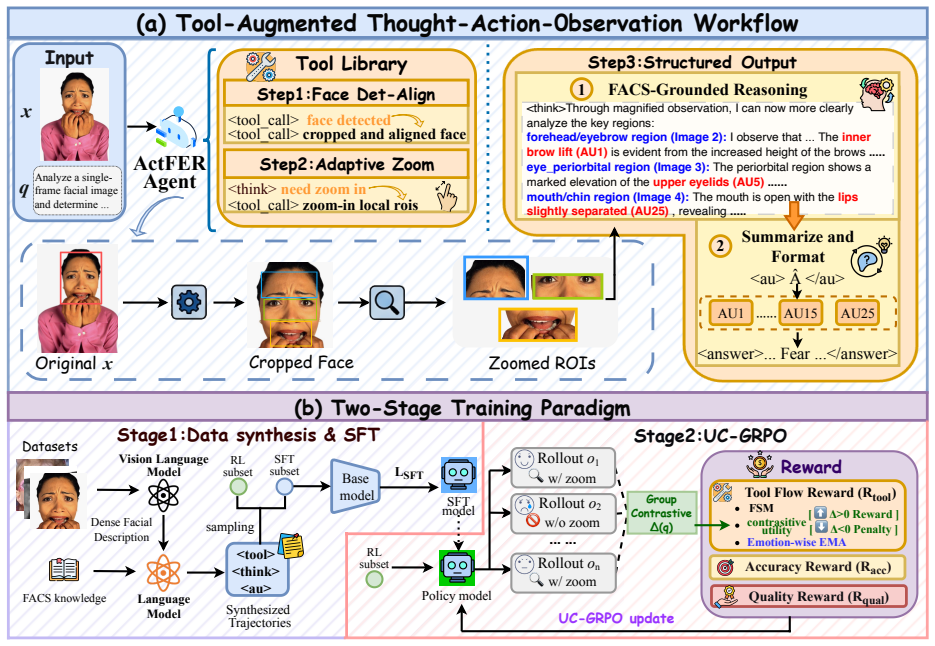
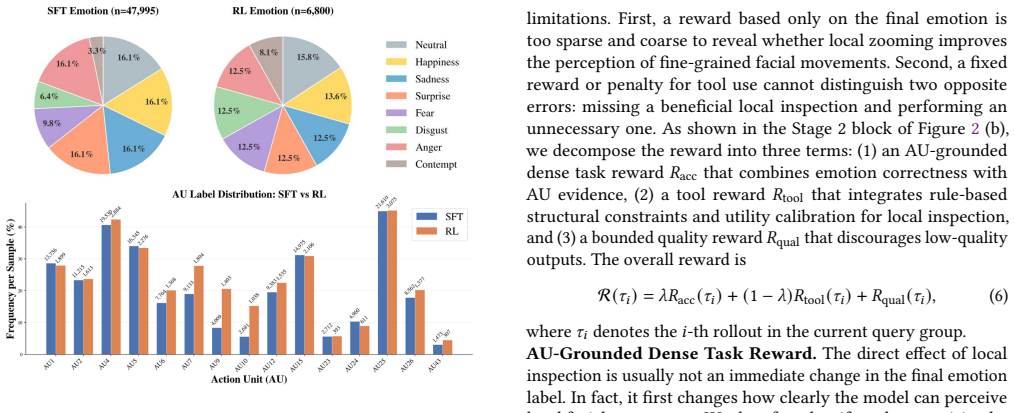
ActFER reformulates FER as active visual evidence acquisition followed by multimodal reasoning. The agent dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units and emotions through a visual Chain-of-Thought. UC-GRPO supplies the necessary training signal by using AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation for sample-aware dynamic credit assignment, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies.
What carries the argument
Utility-Calibrated GRPO (UC-GRPO), an RL algorithm that combines multi-level AU-grounded verifiable rewards, query-conditional contrastive utility estimation for credit assignment, and emotion-aware EMA calibration to enable learning of when and how to perform local visual inspections.
If this is right
- The agent learns to invoke local inspection tools only when they are expected to improve downstream reasoning accuracy.
- Action unit prediction accuracy increases substantially because supervision is provided at the level of individual facial regions rather than whole-face labels alone.
- Visual chain-of-thought reasoning becomes more reliable once the model can acquire fresh evidence for each reasoning step.
- The same training procedure produces both the policy for tool use and the final emotion and AU predictions.
Where Pith is reading between the lines
- The active-inspection pattern could be applied to other fine-grained visual tasks that benefit from selective high-resolution processing, such as medical or satellite imagery analysis.
- In resource-constrained settings the selective-zoom policy may lower average compute cost by avoiding full-resolution processing of every image.
- Extending the utility estimator to handle sequences of dependent inspections might further improve performance on expressions that require multiple glances.
Load-bearing premise
The multi-level rewards and query-conditional utility estimates produced by UC-GRPO will continue to produce useful behavior on new data without overfitting to the action unit annotations seen during training.
What would settle it
Run the trained ActFER agent on a new facial expression dataset that contains no action unit annotations and check whether the reported gains in both emotion accuracy and AU prediction accuracy over passive baselines disappear.
Figures



read the original abstract
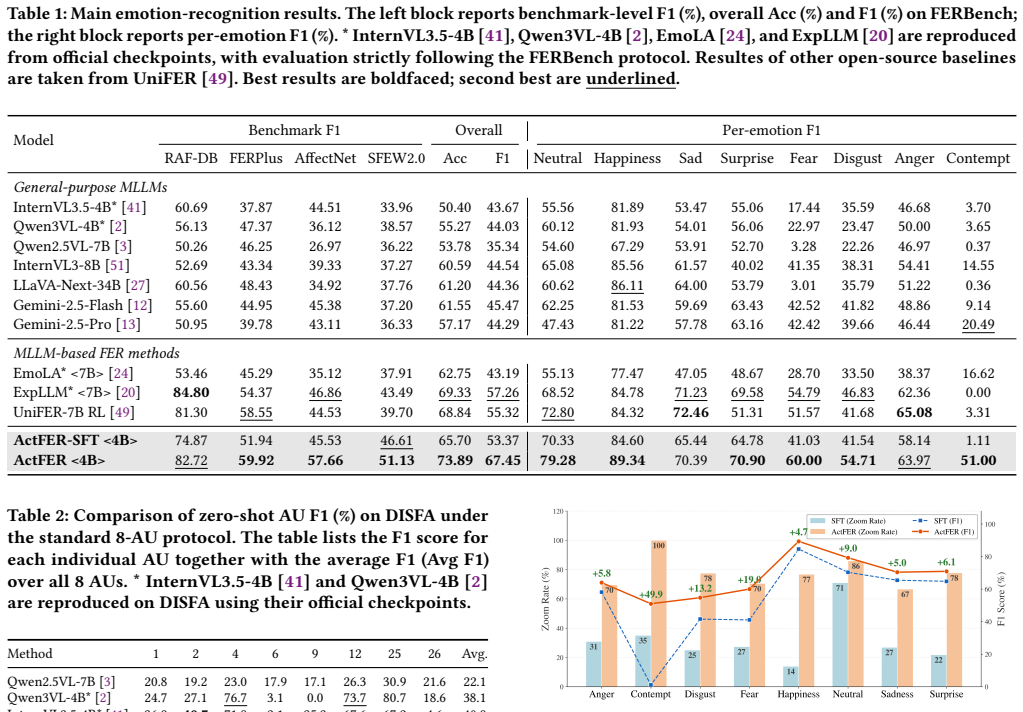
Recent advances in Multimodal Large Language Models (MLLMs) have created new opportunities for facial expression recognition (FER), moving it beyond pure label prediction toward reasoning-based affect understanding. However, existing MLLM-based FER methods still follow a passive paradigm: they rely on externally prepared facial inputs and perform single-pass reasoning over fixed visual evidence, without the capability for active facial perception. To address this limitation, we propose ActFER, an agentic framework that reformulates FER as active visual evidence acquisition followed by multimodal reasoning. Specifically, ActFER dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units (AUs) and emotions through a visual Chain-of-Thought. To realize such behavior, we further develop Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm tailored to agentic FER. UC-GRPO uses AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation to enable sample-aware dynamic credit assignment for local inspection, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies. This algorithm enables ActFER to learn both when local inspection is beneficial and how to reason over the acquired evidence. Comprehensive experiments show that ActFER trained with UC-GRPO consistently outperforms passive MLLM-based FER baselines and substantially improves AU prediction accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActFER, an agentic framework for facial expression recognition that reformulates the task as active visual evidence acquisition (via tools for face detection, alignment, and selective zooming into local regions) followed by multimodal reasoning over Action Units (AUs) and emotions using visual Chain-of-Thought. It introduces Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm that employs AU-grounded multi-level verifiable rewards, query-conditional contrastive utility estimation, and emotion-aware EMA calibration to learn when and how to perform local inspection. Experiments claim consistent outperformance over passive MLLM-based FER baselines along with substantial gains in AU prediction accuracy.
Significance. If the empirical claims hold under rigorous controls, the work would advance MLLM-based FER by demonstrating the value of active, tool-augmented perception over passive single-pass reasoning, potentially improving robustness in unconstrained settings. The UC-GRPO algorithm contributes a tailored RL method for densifying supervision and dynamic credit assignment in agentic visual tasks; the provision of a new framework with explicit tool-use policies is a concrete step toward more interpretable affect understanding.
major comments (2)
- [§4] §4 (UC-GRPO algorithm): the multi-level verifiable rewards are explicitly AU-grounded and the utility estimation is query-conditional; this design choice makes the central generalization claim load-bearing. If the learned inspection policies primarily exploit dataset-specific AU co-occurrence statistics or annotation artifacts rather than transferable visual evidence, the reported outperformance over passive baselines and AU accuracy gains would not transfer. A cross-dataset evaluation (e.g., training on one corpus and testing on another with different AU annotation protocols) or an ablation that removes the AU-specific reward terms is required to substantiate robustness.
- [§5] Experimental section (likely §5): the abstract and high-level claims assert consistent outperformance and AU gains, yet the provided description lacks explicit data splits, baseline implementations, error bars, or statistical significance tests. Without these, it is impossible to rule out post-hoc selection or overfitting to the training distribution, directly undermining the headline comparison to passive MLLM baselines.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence summarizing the datasets used and the magnitude of the reported AU accuracy improvement (e.g., mean F1 or accuracy delta).
- [§3] Notation for the contrastive utility estimator and EMA calibration should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will incorporate revisions to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [§4] §4 (UC-GRPO algorithm): the multi-level verifiable rewards are explicitly AU-grounded and the utility estimation is query-conditional; this design choice makes the central generalization claim load-bearing. If the learned inspection policies primarily exploit dataset-specific AU co-occurrence statistics or annotation artifacts rather than transferable visual evidence, the reported outperformance over passive baselines and AU accuracy gains would not transfer. A cross-dataset evaluation (e.g., training on one corpus and testing on another with different AU annotation protocols) or an ablation that removes the AU-specific reward terms is required to substantiate robustness.
Authors: We agree that isolating the contribution of AU-grounded rewards is necessary to support claims of transferable visual reasoning. In the revision we will add a dedicated ablation that disables the AU-specific reward terms while retaining the remaining UC-GRPO components, allowing direct comparison of inspection policies and downstream AU/emotion accuracy. Cross-dataset transfer is complicated by differing AU annotation protocols and label distributions across corpora; we will therefore include a limitations paragraph discussing this issue and report preliminary results on one additional dataset where protocol alignment is feasible. These additions will clarify the extent to which performance relies on dataset-specific statistics versus general visual evidence. revision: partial
-
Referee: [§5] Experimental section (likely §5): the abstract and high-level claims assert consistent outperformance and AU gains, yet the provided description lacks explicit data splits, baseline implementations, error bars, or statistical significance tests. Without these, it is impossible to rule out post-hoc selection or overfitting to the training distribution, directly undermining the headline comparison to passive MLLM baselines.
Authors: We acknowledge that the current experimental description is insufficient for full reproducibility and statistical assessment. The revised manuscript will expand §5 to specify the exact train/validation/test splits for each dataset, provide complete implementation details and hyperparameters for all baselines, report mean and standard deviation across at least three random seeds with error bars, and include paired statistical significance tests (e.g., t-tests with p-values) for the key comparisons against passive MLLM baselines. These changes will directly address concerns about post-hoc selection or overfitting. revision: yes
Circularity Check
No significant circularity: ActFER framework and UC-GRPO are novel algorithmic proposals validated empirically against external baselines.
full rationale
The paper introduces ActFER as a new agentic reformulation of FER involving tool invocation for face detection/alignment, local zooming, and visual CoT reasoning over AUs/emotions. It then defines UC-GRPO with three explicit components (AU-grounded multi-level verifiable rewards, query-conditional contrastive utility estimation, emotion-aware EMA calibration) to train active inspection policies. These are presented as newly developed mechanisms, not derived from prior self-citations or by re-expressing fitted parameters. Claims of outperformance and improved AU accuracy rest on comprehensive experiments versus passive MLLM baselines, with no equations or self-referential reductions shown in the provided text. The derivation chain is self-contained as an empirical engineering contribution rather than a tautological renaming or fit.
Axiom & Free-Parameter Ledger
invented entities (2)
-
ActFER framework
no independent evidence
-
UC-GRPO algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-VL Technical Report. arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Emad Barsoum, Cha Zhang, Cristian Canton Ferrer, and Zhengyou Zhang. 2016. Training deep networks for facial expression recognition with crowd-sourced label distribution. InProceedings of the 18th ACM International Conference on Multimodal Interaction. 279–283
2016
-
[5]
Joyati Chattopadhyay, Souvik Kundu, Arpita Chakraborty, and Jyoti Sekhar Banerjee. 2020. Facial Expression Recognition for Human Computer Interaction. InNew Trends in Computational Vision and Bio-inspired Computing: Selected works presented at the ICCVBIC 2018, Coimbatore, India. Springer, 1181–1192
2020
-
[6]
Ashutosh Chaubey, Xulang Guan, and Mohammad Soleymani. 2026. Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 2648–2660
2026
-
[7]
Haodong Chen, Haojian Huang, Junhao Dong, Mingzhe Zheng, and Dian Shao
-
[8]
InProceedings of the 32nd ACM International Conference on Multimedia
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expres- sion Recognition with AdaptERs. InProceedings of the 32nd ACM International Conference on Multimedia. 2301–2310
-
[9]
Yin Chen, Jia Li, Shiguang Shan, Meng Wang, and Richang Hong. 2025. From Static to Dynamic: Adapting Landmark-Aware Image Models for Facial Expres- sion Recognition in Videos.IEEE Transactions on Affective Computing16, 2 (2025), 624–638
2025
-
[10]
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander G Hauptmann. 2024. Emotion- LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tun- ing.Advances in Neural Information Processing Systems37 (2024), 110805–110853
2024
-
[11]
Paul Ekman and Wallace V Friesen. 1978. Facial action coding system.Environ- mental Psychology & Nonverbal Behavior(1978)
1978
-
[12]
Baris Gecer, Jiankang Deng, and Stefanos Zafeiriou. 2021. OSTeC: One-Shot Texture Completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 7628–7638
2021
-
[13]
Google. 2025. Gemini 2.5 Flash Preview Model Card. https://storage.googleapis. com/model-cards/documents/gemini-2.5-flash-preview.pdf
2025
-
[14]
Google. 2025. Gemini 2.5 Pro Preview Model Card. https://storage.googleapis. com/model-cards/documents/gemini-2.5-pro-preview.pdf
2025
- [15]
-
[16]
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2023. ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. InAdvances in Neural Information Processing Systems, Vol. 36. 45870–45894
2023
-
[17]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. 2024. CogA- gent: A Visual Language Model for GUI Agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14281–14290
2024
-
[18]
Zhuozhao Hu, Kaishen Yuan, Xin Liu, Zitong Yu, Yuan Zong, Jingang Shi, Huan- jing Yue, and Jingyu Yang. 2025. FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning. In Proceedings of the 33rd ACM International Conference on Multimedia. 5677–5686
2025
-
[19]
Rijin Jin, Sirui Zhao, Zhongkai Hao, Yifan Xu, Tong Xu, and Enhong Chen. 2022. AVT: Au-Assisted Visual Transformer for Facial Expression Recognition. In2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2661–2665
2022
-
[20]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Vi- sualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 881–905
2024
-
[21]
Xing Lan, Jian Xue, Ji Qi, Dongmei Jiang, Ke Lu, and Tat-Seng Chua. 2025. Ex- pLLM: Towards Chain of Thought for Facial Expression Recognition.IEEE Transactions on Multimedia27 (2025), 3069–3081
2025
-
[22]
Hanting Li, Hongjing Niu, Zhaoqing Zhu, and Feng Zhao. 2023. Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild.Proceedings of the AAAI Conference on Artificial Intelligence37, 1 (Jun. 2023), 67–75
2023
-
[23]
Shan Li, Weihong Deng, and JunPing Du. 2017. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2852–2861
2017
-
[24]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025. Search-o1: Agentic Search-Enhanced Large Reasoning Models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 5420–5438
2025
-
[25]
Yifan Li, Anh Dao, Wentao Bao, Zhen Tan, Tianlong Chen, Huan Liu, and Yu Kong
-
[26]
InComputer Vision – ECCV 2024
Facial Affective Behavior Analysis with Instruction Tuning. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 165–186
2024
-
[27]
Zheng Lian, Licai Sun, Haiyang Sun, Kang Chen, Zhuofan Wen, Hao Gu, Bin Liu, and Jianhua Tao. 2024. GPT-4V with emotion: A zero-shot benchmark for Generalized Emotion Recognition.Information Fusion108 (2024), 102367
2024
-
[28]
Hanwei Liu, Rudong An, Zhimeng Zhang, Bowen Ma, Wei Zhang, Yan Song, Yujing Hu, Wei Chen, and Yu Ding. 2025. Norface: Improving Facial Expression Analysis by Identity Normalization. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 293–314
2025
-
[29]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Baselines with Visual Instruction Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26296–26306
2024
-
[30]
Brais Martinez, Michel F Valstar, Bihan Jiang, and Maja Pantic. 2017. Automatic Analysis of Facial Actions: A Survey.IEEE Transactions on Affective Computing 10, 3 (2017), 325–347
2017
-
[31]
S Mohammad Mavadati, Mohammad H Mahoor, Kevin Bartlett, Philip Trinh, and Jeffrey F Cohn. 2013. DISFA: A Spontaneous Facial Action Intensity Database. IEEE Transactions on Affective Computing4, 2 (2013), 151–160
2013
-
[32]
Ali Mollahosseini, Behzad Hasani, and Mohammad H Mahoor. 2017. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Transactions on Affective Computing10, 1 (2017), 18–31
2017
-
[33]
OpenAI. 2025. GPT-5 System Card. https://cdn.openai.com/gpt-5-system- card.pdf
2025
- [34]
-
[35]
Xingyu Ren, Alexandros Lattas, Baris Gecer, Jiankang Deng, Chao Ma, and Xi- aokang Yang. 2023. Facial Geometric Detail Recovery via Implicit Representation. In2023 IEEE 17th International Conference on Automatic Face and Gesture Recog- nition (FG)
2023
-
[36]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems, Vol. 36. 68539–68551
2023
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. HybridFlow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems. 1279–1297
2025
-
[39]
Yan Shi, Zijun Zhang, Kaining Huang, Wudi Ma, and Shanshan Tu. 2020. Human- computer interaction based on face feature localization.Journal of Visual Com- munication and Image Representation70 (2020), 102740
2020
-
[40]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. 2025. R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning. arXiv:2503.05592
work page internal anchor Pith review arXiv 2025
-
[41]
Licai Sun, Zheng Lian, Bin Liu, and Jianhua Tao. 2023. MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition. InProceedings of the 31st ACM International Conference on Multimedia. 6110–6121
2023
-
[42]
Chengpeng Wang, Li Chen, Lili Wang, Zhaofan Li, and Xuebin Lv. 2025. QCS:Feature Refining from Quadruplet Cross Similarity for Facial Expression Recognition. InProceedings of the AAAI conference on artificial intelligence, Vol. 39. 7563–7572
2025
-
[43]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. InternVL3.5: Ad- vancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. arXiv:2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Jiulong Wu, Yucheng Shen, Lingyong Yan, Haixin Sun, Deguo Xia, Jizhou Huang, and Min Cao. 2026. Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 26939–26947
2026
-
[45]
Yi Wu, Shangfei Wang, and Yanan Chang. 2023. Patch-Aware Representation Learning for Facial Expression Recognition. InProceedings of the 31st ACM Inter- national Conference on Multimedia. 6143–6151
2023
- [46]
-
[47]
Huiyuan Yang, Taoyue Wang, and Lijun Yin. 2020. Adaptive Multimodal Fusion for Facial Action Units Recognition. InProceedings of the 28th ACM International Conference on Multimedia. 2982–2990
2020
- [48]
-
[49]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models.National Science Review11, 12 (11 2024), nwae403
2024
-
[50]
Kaishen Yuan, Zitong Yu, Xin Liu, Weicheng Xie, Huanjing Yue, and Jingyu Yang
-
[51]
InComputer Vision – ECCV 2024
AUFormer: Vision Transformers Are Parameter-Efficient Facial Action Unit Detectors. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 427–445
2024
-
[52]
Fan Zhang, Haoxuan Li, Shengju Qian, Xin Wang, Zheng Lian, Hao Wu, Zhihong Zhu, Yuan Gao, Qiankun Li, Yefeng Zheng, Zhouchen Lin, and Pheng-Ann Heng
-
[53]
Rethinking Facial Expression Recognition in the Era of Multimodal Large Language Models: Benchmark, Datasets, and Beyond. arXiv:2511.00389
-
[54]
Yuhang Zhang, Xiuqi Zheng, Chenyi Liang, Jiani Hu, and Weihong Deng. 2025. Generalizable Facial Expression Recognition. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 231–248
2025
-
[55]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models. arXiv:2504.10479 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.