Recognition: unknown
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
Pith reviewed 2026-05-10 18:15 UTC · model grok-4.3
The pith
StreamMeCo compresses vision agent memory graphs by 70 percent to speed retrieval while holding or improving video understanding accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
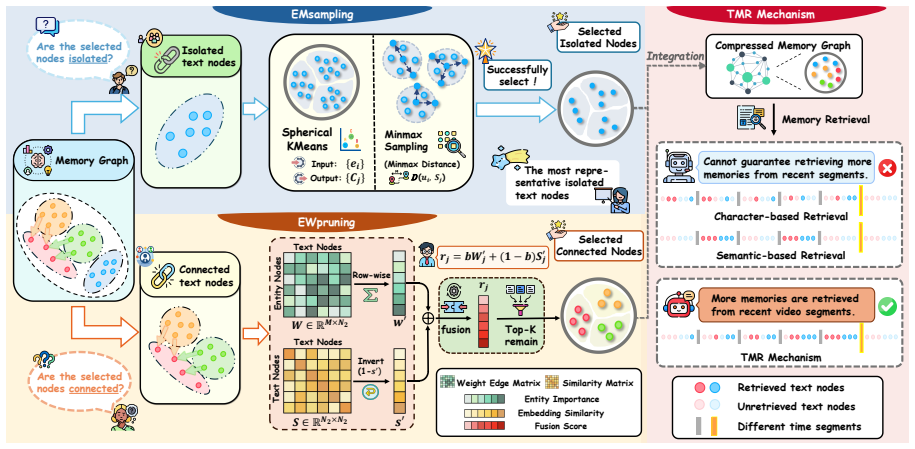
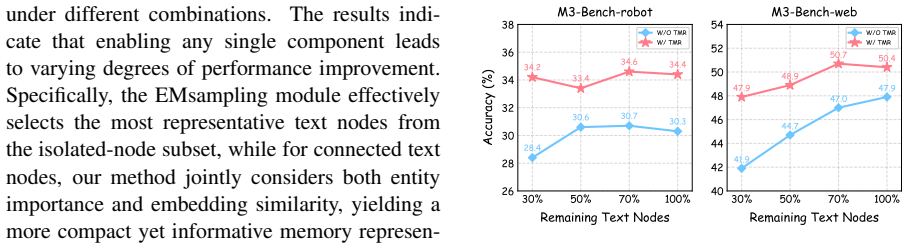
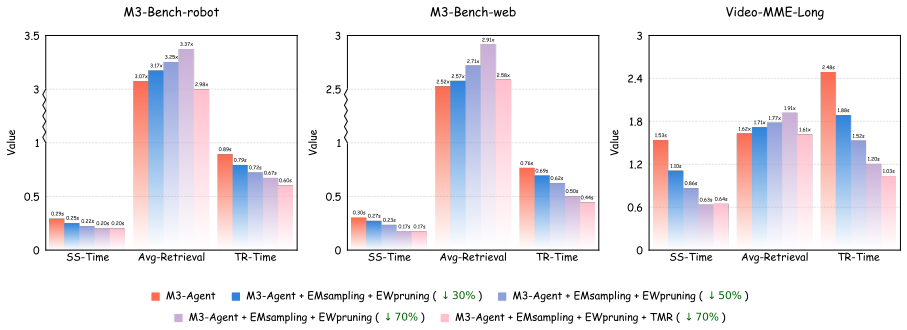
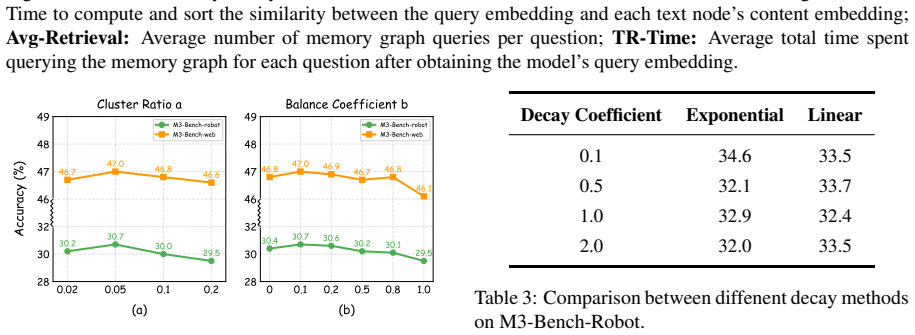
StreamMeCo is an efficient Stream Agent Memory Compression framework that evicts redundant memory nodes based on the connectivity of the memory graph. Isolated nodes are removed via edge-free minmax sampling and connected nodes via edge-aware weight pruning, while a time-decay memory retrieval mechanism compensates for any resulting performance degradation. On the M3-Bench-robot, M3-Bench-web and Video-MME-Long datasets this approach sustains accuracy under 70 percent memory graph compression and produces a 1.87 times speedup in memory retrieval together with a 1.0 percent average accuracy improvement.
What carries the argument
Memory graph connectivity that identifies redundant nodes for eviction, implemented through edge-free minmax sampling on isolated nodes and edge-aware weight pruning on connected nodes, together with time-decay retrieval to preserve task performance.
If this is right
- Agents can maintain memory of much longer video streams without exhausting available storage or compute.
- Memory retrieval operations complete faster, supporting lower-latency responses during streaming tasks.
- Removal of certain nodes can reduce noise and produce small accuracy gains rather than losses.
- The same compression pipeline works across robot navigation, web interaction, and extended video benchmarks.
- Overall system costs for storage and repeated retrieval drop substantially for continuous video input.
Where Pith is reading between the lines
- Graph connectivity rules for eviction could transfer to memory management in non-video agents that store sequences of observations or actions.
- Making the compression ratio adjust automatically to video length or scene complexity would address cases where fixed 70 percent reduction is too aggressive.
- Pairing the method with low-precision storage formats might multiply the memory savings beyond the reported compression level.
- Experiments on videos with higher levels of irrelevant detail would reveal whether connectivity alone continues to separate signal from noise.
Load-bearing premise
The memory graph's connectivity accurately identifies which nodes are redundant without removing information that remains necessary for correct video understanding.
What would settle it
If a new long streaming video dataset shows that 70 percent compression under StreamMeCo produces a consistent accuracy drop larger than 2 percent even after applying the time-decay retrieval, the claim that graph connectivity safely guides eviction would be contradicted.
Figures





read the original abstract
Vision agent memory has shown remarkable effectiveness in streaming video understanding. However, storing such memory for videos incurs substantial memory overhead, leading to high costs in both storage and computation. To address this issue, we propose StreamMeCo, an efficient Stream Agent Memory Compression framework. Specifically, based on the connectivity of the memory graph, StreamMeCo introduces edge-free minmax sampling for the isolated nodes and an edge-aware weight pruning for connected nodes, evicting the redundant memory nodes while maintaining the accuracy. In addition, we introduce a time-decay memory retrieval mechanism to further eliminate the performance degradation caused by memory compression. Extensive experiments on three challenging benchmark datasets (M3-Bench-robot, M3-Bench-web and Video-MME-Long) demonstrate that under 70% memory graph compression, StreamMeCo achieves a 1.87* speedup in memory retrieval while delivering an average accuracy improvement of 1.0%. Our code is available at https://github.com/Celina-love-sweet/StreamMeCo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StreamMeCo, a framework for compressing long-term agent memory graphs in streaming video understanding. It evicts nodes via edge-free minmax sampling on isolated nodes and edge-aware weight pruning on connected components (targeting 70% compression), while adding a time-decay retrieval mechanism to offset potential accuracy loss. On M3-Bench-robot, M3-Bench-web, and Video-MME-Long, it reports 1.87× memory retrieval speedup and 1.0% average accuracy gain.
Significance. If the graph-based eviction reliably preserves task-critical information and the accuracy lift is attributable to the method rather than the time-decay component alone, the work could enable scalable long-horizon video agents by cutting storage and retrieval costs. Code release at the cited GitHub repository is a clear strength for reproducibility and follow-up work.
major comments (2)
- [Method description (abstract and §3)] The central claim that connectivity-based eviction (minmax sampling on isolates and weight pruning on connected components) safely removes 70% of nodes without losing critical video-understanding information is load-bearing but unsupported. No analysis, ablation, or correlation study is provided showing that low-connectivity or low-weight nodes are informationally redundant rather than task-critical.
- [Experiments (abstract and §4)] Experimental evaluation: the reported 1.0% average accuracy improvement and 1.87× speedup lack any description of baselines, number of runs, error bars, statistical significance, or ablations that isolate the contribution of graph pruning versus the separately introduced time-decay retrieval. This prevents attribution of gains to the compression step and makes the counter-intuitive accuracy lift under aggressive compression difficult to evaluate.
minor comments (2)
- [Abstract] The abstract introduces terms such as 'edge-free minmax sampling' and 'edge-aware weight pruning' without a concise definition or high-level intuition, which would aid readers unfamiliar with the memory-graph construction.
- [Method] No mention of how the memory graph is initially constructed (node embeddings, edge weighting criteria) or any hyper-parameters controlling the 70% target compression rate.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will make substantial revisions to strengthen the methodological justification and experimental reporting in the manuscript.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The central claim that connectivity-based eviction (minmax sampling on isolates and weight pruning on connected components) safely removes 70% of nodes without losing critical video-understanding information is load-bearing but unsupported. No analysis, ablation, or correlation study is provided showing that low-connectivity or low-weight nodes are informationally redundant rather than task-critical.
Authors: We agree that the current manuscript lacks explicit supporting analysis for the eviction criteria. In the revised version, we will expand Section 3 with a new correlation analysis between node connectivity/weight and task relevance (measured via removal impact on downstream accuracy), plus an ablation comparing eviction of low- versus high-connectivity nodes. This will provide direct evidence that the pruned nodes are redundant for video-understanding tasks. revision: yes
-
Referee: [Experiments (abstract and §4)] Experimental evaluation: the reported 1.0% average accuracy improvement and 1.87× speedup lack any description of baselines, number of runs, error bars, statistical significance, or ablations that isolate the contribution of graph pruning versus the separately introduced time-decay retrieval. This prevents attribution of gains to the compression step and makes the counter-intuitive accuracy lift under aggressive compression difficult to evaluate.
Authors: We acknowledge these gaps in experimental rigor. We will revise Section 4 to: (i) fully describe all baselines, (ii) report results over multiple runs (minimum 5 seeds) with means, standard deviations, error bars, and statistical significance tests, and (iii) add ablations that isolate graph pruning from time-decay retrieval (including a no-time-decay variant). These changes will allow clear attribution of the observed accuracy gain, which we hypothesize arises from noise reduction via removal of low-relevance nodes. revision: yes
Circularity Check
Empirical compression framework with no circular derivation
full rationale
The paper proposes StreamMeCo as an empirical method: it constructs a memory graph, applies connectivity-based eviction (edge-free minmax sampling on isolates and edge-aware weight pruning on connected components), and adds a time-decay retrieval mechanism. Performance is measured directly on three external benchmarks (M3-Bench-robot, M3-Bench-web, Video-MME-Long) under 70% compression, reporting 1.87× retrieval speedup and +1.0% average accuracy. No mathematical derivation, first-principles prediction, or fitted parameter is presented whose output is definitionally equivalent to its input. No self-citations are used to justify uniqueness, ansatz, or load-bearing premises. The claims rest on experimental outcomes rather than on any reduction to the method's own definitions or prior author results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent memory for video understanding can be effectively modeled as a graph where node connectivity indicates redundancy.
Forward citations
Cited by 1 Pith paper
-
From Similarity to Structure: Training-free LLM Context Compression with Hybrid Graph Priors
A hybrid graph-based training-free framework for LLM context compression matches strong baselines and shows larger gains on long-document benchmarks.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418
Videollm-online: Online video large lan- guage model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418. Xueyi Chen, Keda Tao, Kele Shao, and Huan Wang
-
[2]
Streamingtom: Streaming token compression for efficient video understanding.arXiv preprint arXiv:2510.18269. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025a. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh...
-
[3]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 2803–2813
Learning musical representations for music performance question answering. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 2803–2813. Xingjian Diao, Chunhui Zhang, Weiyi Wu, Zhongyu Ouyang, Peijun Qing, Ming Cheng, Soroush V osoughi, and Jiang Gui. 2025c. Temporal work- ing memory: Query-guided segment refinement for enhance...
-
[4]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Moviechat: From dense token to sparse mem- ory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232. Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. 2025. Adaptive keyframe sampling for long video understanding. InProceed- ings of the Computer Vision...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu
Spark: Strategic policy-aware exploration via dynamic branching for long-horizon agentic learn- ing.arXiv preprint arXiv:2601.20209. Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu
-
[6]
arXiv preprint arXiv:2501.13468 , year=
Streaming video understanding and multi- round interaction with memory-enhanced knowl- edge.arXiv preprint arXiv:2501.13468. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, and 1 others. 2025a. Qwen2. 5-omni technical report.arXiv preprint arXiv:2503.20215. Ruyi Xu, Guangxuan Xiao, Yukang Chen...
-
[7]
Memgen: Weaving generative latent mem- ory for self-evolving agents.arXiv preprint arXiv:2509.24704. Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin
-
[8]
Flash-vstream: Memory-based real-time un- derstanding for long video streams.arXiv preprint arXiv:2406.08085. Jiaquan Zhang, Qigan Sun, Chaoning Zhang, Xudong Wang, Zhenzhen Huang, Yitian Zhou, Pengcheng Zheng, Chi lok Andy Tai, Sung-Ho Bae, Zeyu Ma, Caiyan Qin, Jinyu Guo, Yang Yang, and Heng- tao Shen. 2026a. Tda-rc: Task-driven alignment for knowledge-b...
-
[9]
E Experiments on Other Graph-Based Memory Frameworks Our method can be readily adapted to other graph- based Agent Memory frameworks
Therefore, the information loss introduced by compression is theoretically minimal. E Experiments on Other Graph-Based Memory Frameworks Our method can be readily adapted to other graph- based Agent Memory frameworks. Specifically, we adapt it to the Mem0 (graph) (Chhikara et al., 2025b) framework, whose memory paradigm in- cludes entity types (e.g., pers...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.