Recognition: no theorem link
Hierarchical Alignment: Enforcing Hierarchical Instruction-Following in LLMs through Logical Consistency
Pith reviewed 2026-05-10 16:52 UTC · model grok-4.3
The pith
A neuro-symbolic training method lets LLMs resolve conflicting instructions by learned priority without an external solver at runtime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
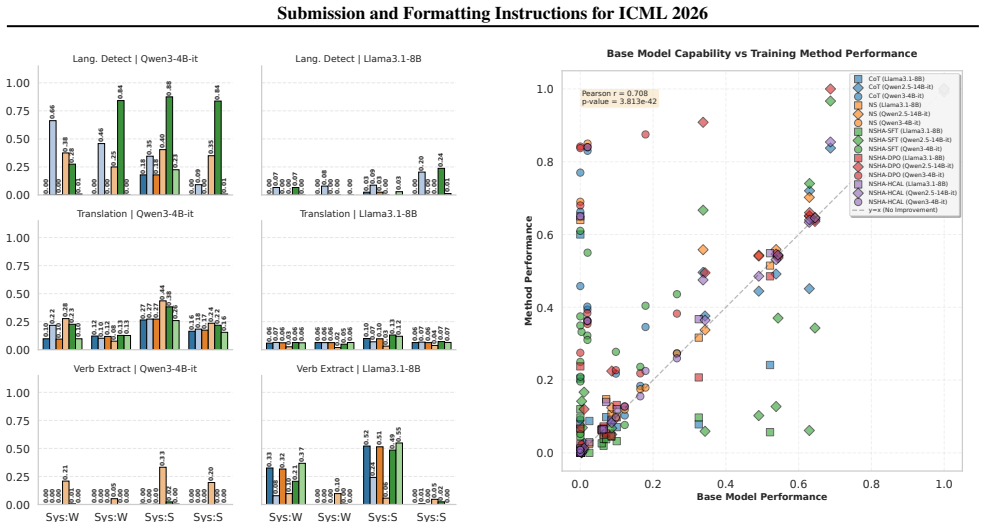
NSHA improves instruction-following under hierarchical conflicts by combining solver-guided reasoning at inference time with distillation of solver decisions into model parameters at training time, allowing the model to derive maximally consistent instruction sets without runtime solver access.
What carries the argument
Neuro-Symbolic Hierarchical Alignment (NSHA), which formulates instruction resolution as a constraint satisfaction problem and distills the solver's priority resolutions into the LLM.
If this is right
- Models can handle multi-source instructions from policies, users, tools, and context while respecting explicit priority orders.
- Performance on conflicting inputs rises without degrading results on standard, non-conflicting benchmarks.
- The approach extends to both single-turn and multi-turn dialogues by maintaining logical consistency across turns.
- Safety and utility are balanced because the model learns to drop lower-priority instructions only when they conflict with higher ones.
Where Pith is reading between the lines
- If the distillation step succeeds, the same technique could be applied to other logical constraints beyond hierarchy, such as temporal or causal consistency in agent planning.
- The method suggests a path toward models that internalize external reasoning engines for domains where full symbolic solving remains too slow at inference.
- Real deployments might still need occasional solver fallback for novel conflict types not seen in training.
Load-bearing premise
That the patterns of hierarchical resolution produced by the solver can be reliably internalized by the model so it reproduces them without the solver present.
What would settle it
A held-out test set of instruction conflicts whose resolution patterns differ from the automatically generated training supervision, where the distilled model shows no gain over the baseline.
Figures






read the original abstract
Large language models increasingly operate under multiple instructions from heterogeneous sources with different authority levels, including system policies, user requests, tool outputs, and retrieved context. While prior work on instruction hierarchy highlights the importance of respecting instruction priorities, it mainly focuses on adversarial attacks and overlooks the benign but common instruction conflicts that arise in real-world applications. In such settings, models must not only avoid security violations but also preserve task utility and behavioral consistency when instructions partially or implicitly conflict. We propose Neuro-Symbolic Hierarchical Alignment (NSHA) for hierarchical instruction-following by explicitly modeling and enforcing instruction priorities. At inference time, we introduce solver-guided reasoning that formulates instruction resolution as a constraint satisfaction problem, enabling the model to derive a maximally consistent set of applicable instructions under hierarchical constraints. At training time, NSHA distills solver-based decisions into model parameters using automatically constructed supervision. We evaluate our approach on rule following, task execution, tool use, and safety, covering both single-turn and multi-turn interactions, and show that NSHA significantly improves performance under such conflicts while maintaining competitive utility in reference settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Neuro-Symbolic Hierarchical Alignment (NSHA) to address instruction conflicts in LLMs arising from heterogeneous sources with differing authority levels. It formulates resolution as a constraint satisfaction problem solved via solver-guided reasoning at inference time to produce a maximally consistent set of instructions, while at training time it automatically constructs supervision from the solver's decisions and distills this into the model parameters. Evaluations across rule following, task execution, tool use, and safety tasks (single- and multi-turn) claim that NSHA yields significant gains under conflicts while preserving competitive performance in reference (non-conflict) settings.
Significance. If the hybrid solver-plus-distillation pipeline proves robust, the work would offer a concrete mechanism for enforcing logical consistency and priority respect in LLMs without relying exclusively on prompting or post-training alignment. The automatic construction of supervision from symbolic decisions is a notable strength that could reduce the need for manual conflict annotations and improve reproducibility across domains.
major comments (2)
- [Training and inference pipeline description] The central claim that distillation enables reliable reproduction of solver resolutions rests on the assumption that automatically generated supervision covers implicit and partial conflicts sufficiently for the LLM to internalize hierarchical logic. The manuscript should provide an ablation (e.g., in the experimental section) comparing performance with and without the solver at inference to isolate the contribution of distillation versus solver guidance.
- [Evaluation section] Experimental details on conflict definition, baseline selection, and statistical significance are insufficient to assess whether reported gains are robust. The abstract and results sections should include explicit definitions of conflict types, exact baselines, number of runs, and p-values or confidence intervals for the claimed improvements.
minor comments (2)
- [Method] Notation for hierarchical constraints and the constraint satisfaction formulation could be clarified with a small example or pseudocode to aid reproducibility.
- [Abstract and §3] The abstract mentions 'automatically constructed supervision' but does not specify the exact procedure or coverage guarantees; a brief description or reference to an appendix would help.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The suggestions will help clarify the contributions of the NSHA framework and improve the robustness of the experimental presentation. We address each major comment below.
read point-by-point responses
-
Referee: The central claim that distillation enables reliable reproduction of solver resolutions rests on the assumption that automatically generated supervision covers implicit and partial conflicts sufficiently for the LLM to internalize hierarchical logic. The manuscript should provide an ablation (e.g., in the experimental section) comparing performance with and without the solver at inference to isolate the contribution of distillation versus solver guidance.
Authors: We agree that an ablation isolating the solver's contribution at inference time would strengthen the evidence for the distillation component. In the revised manuscript, we will add results comparing the full NSHA pipeline (solver-guided reasoning at inference) against the distilled model without solver guidance at inference. This will quantify how effectively the model internalizes hierarchical logic from the automatically generated supervision. revision: yes
-
Referee: Experimental details on conflict definition, baseline selection, and statistical significance are insufficient to assess whether reported gains are robust. The abstract and results sections should include explicit definitions of conflict types, exact baselines, number of runs, and p-values or confidence intervals for the claimed improvements.
Authors: We acknowledge the need for greater experimental transparency. In the revised version, we will expand the abstract and results sections to explicitly define the conflict types (explicit, implicit, and partial), list the precise baselines employed, report the number of runs per experiment, and include statistical significance measures such as p-values or confidence intervals for the reported gains. revision: yes
Circularity Check
No circularity: NSHA relies on external solver and empirical evaluation
full rationale
The paper proposes NSHA by using an external solver to formulate instruction resolution as a constraint satisfaction problem at inference and to generate supervision for distillation at training. This chain depends on an independent symbolic solver and downstream task evaluations (rule following, tool use, safety) rather than any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation reduces the claimed performance gains to the inputs by construction, so the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Red Teaming Language Models with Language Models.Proceedings of EMNLP 2022, pp
URL https://aclanthology.org/2023. findings-emnlp.182.pdf. Mitchell, E., Noh, J., Li, S., Armstrong, W., Agarwal, A., Liu, P., Finn, C., and Manning, C. Enhancing self- consistency and performance of pre-trained language models through natural language inference. In Goldberg, Y ., Kozareva, Z., and Zhang, Y . (eds.),Proceedings of the 2022 Conference on E...
-
[2]
URL https://aclanthology.org/2022. emnlp-main.115/. Mu, N., Lu, J., Lavery, M., and Wagner, D. A closer look at system message robustness. InNeurips Safe Generative AI Workshop 2024, 2024. URL https: //openreview.net/forum?id=YZqDyqYwFf. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et...
-
[3]
TPTU: Task planning and tool usage of large language model-based AI agents,
URL https://aclanthology.org/2023. findings-emnlp.248/. Qi, C., Ma, R., Li, B., Du, H., Hui, B., Wu, J., Laili, Y ., and He, C. Large language models meet symbolic provers for logical reasoning evaluation. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and F...
-
[4]
URL https://openreview.net/forum? id=sjWG7B8dvt. Xu, J., Zhang, Z., Friedman, T., Liang, Y ., and Broeck, G. A semantic loss function for deep learning with sym- bolic knowledge. InInternational conference on machine learning, pp. 5502–5511. PMLR, 2018. 10 Submission and Formatting Instructions for ICML 2026 Yang, X.-W., Shao, J.-J., Guo, L.-Z., Zhang, B....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.