Recognition: unknown
GeoPAS: Geometric Probing for Algorithm Selection in Continuous Black-Box Optimisation
Pith reviewed 2026-05-10 17:00 UTC · model grok-4.3
The pith
Coarse geometric slices of problems allow better selection among optimization algorithms than always using the strongest single solver.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
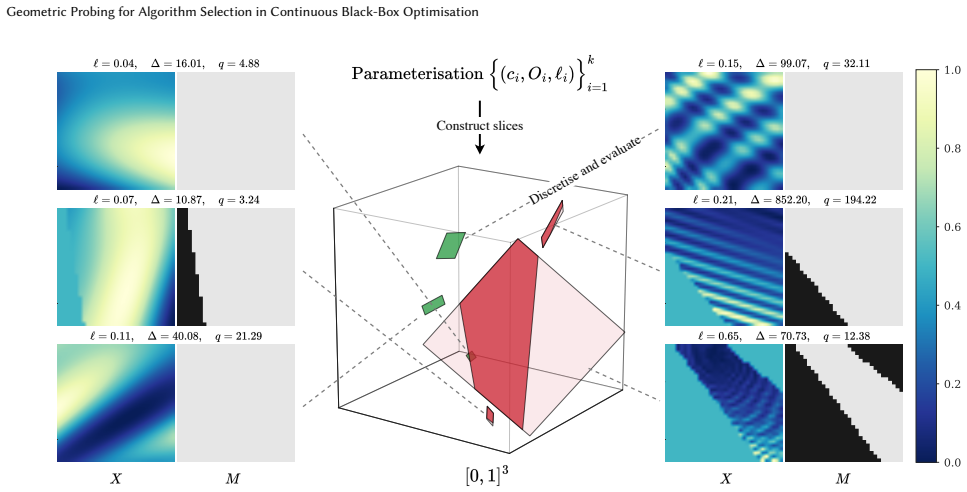
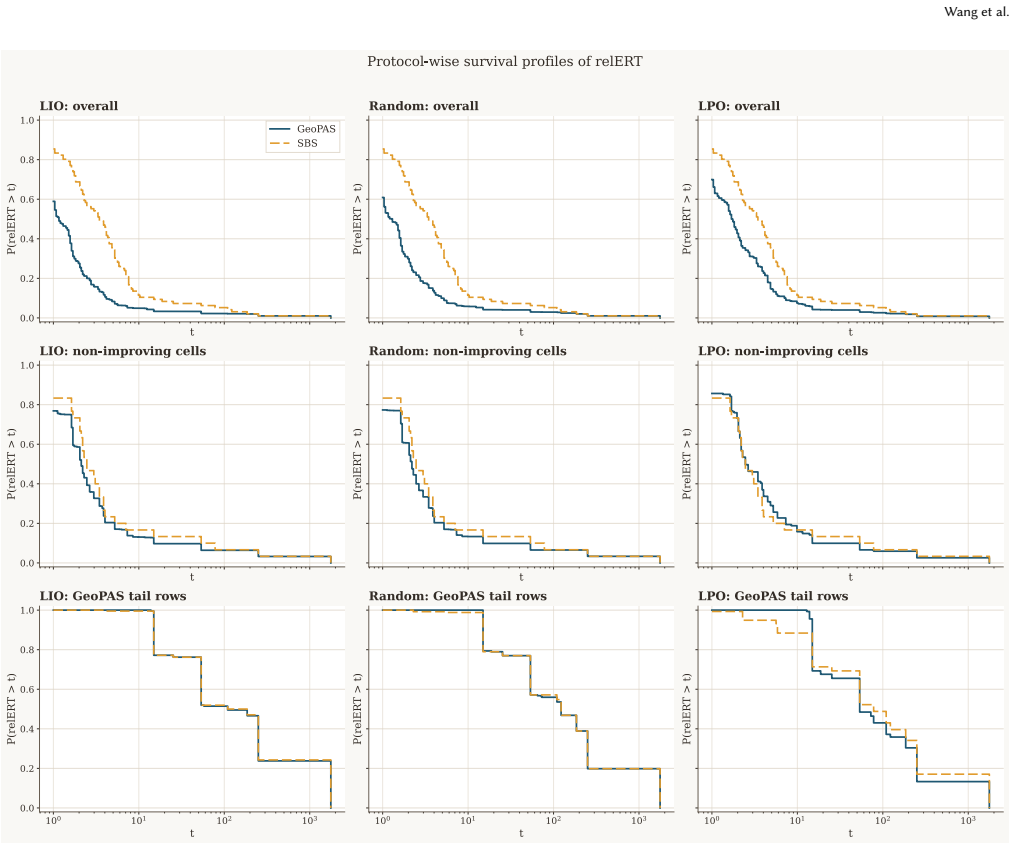
GeoPAS represents a problem instance by multiple coarse two-dimensional slices sampled across locations, orientations, and logarithmic scales. A shared validity-aware convolutional encoder maps each slice to an embedding, conditions it on slice-scale and amplitude statistics, and aggregates the resulting features permutation-invariantly for risk-aware solver selection via log-scale performance prediction with an explicit penalty on tail failures. On the COCO/BBOB benchmark with a 12-solver portfolio in dimensions 2--10, this method improves over the single best solver under leave-instance-out, grouped random, and leave-problem-out evaluation.
What carries the argument
Multi-scale geometric slicing of the search space, processed by a validity-aware convolutional encoder with permutation-invariant aggregation to produce embeddings for solver performance prediction.
If this is right
- The approach delivers higher average performance than any fixed solver choice across multiple evaluation protocols.
- Transferable signals from the slices support selection even when problems are split by type or instance.
- Penalizing tail failures in the prediction reduces the chance of selecting solvers that fail badly on certain instances.
- Results in dimensions 2 to 10 indicate the method applies to moderate-dimensional continuous problems.
Where Pith is reading between the lines
- If geometric slices capture key landscape properties, the same probing strategy could support selection in other optimization domains such as noisy or constrained problems.
- Heavy-tail regimes that still dominate suggest combining the initial static selection with limited online adaptation during the run.
- Applying similar slice-based representations to higher dimensions would reveal whether logarithmic scaling continues to provide useful signals.
- The encoder architecture could be adapted for direct landscape feature extraction beyond algorithm selection.
Load-bearing premise
That sparse sampling of coarse two-dimensional slices at different scales and orientations extracts sufficient information about the full problem landscape to predict solver suitability across instances.
What would settle it
Running the selection on a held-out set of problems where the geometric slices fail to correlate with actual solver performance differences, resulting in no improvement or degradation relative to the best single solver.
Figures







read the original abstract
Automated algorithm selection in continuous black-box optimisation typically relies on fixed landscape descriptors computed under a limited probing budget, yet such descriptors can degrade under problem-split or cross-benchmark evaluation. We propose GeoPAS, a geometric probing approach that represents a problem instance by multiple coarse two-dimensional slices sampled across locations, orientations, and logarithmic scales. A shared validity-aware convolutional encoder maps each slice to an embedding, conditions it on slice-scale and amplitude statistics, and aggregates the resulting features permutation-invariantly for risk-aware solver selection via log-scale performance prediction with an explicit penalty on tail failures. On COCO/BBOB with a 12-solver portfolio in dimensions 2--10, GeoPAS improves over the single best solver under leave-instance-out, grouped random, and leave-problem-out evaluation. These results suggest that multi-scale geometric slices provide a useful transferable static signal for algorithm selection, although a small number of heavy-tail regimes remain and continue to dominate the mean. Our code is available at https://github.com/BradWangW/GeoPAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoPAS for automated algorithm selection in continuous black-box optimization. It represents problem instances via multiple coarse 2D geometric slices sampled across locations, orientations, and logarithmic scales; a validity-aware CNN encoder produces embeddings conditioned on scale and amplitude statistics, which are aggregated permutation-invariantly. These features are used for risk-aware log-scale performance prediction with an explicit tail penalty to select from a 12-solver portfolio. On COCO/BBOB benchmarks in dimensions 2-10, the method is reported to improve over the single-best solver under leave-instance-out, grouped-random, and leave-problem-out protocols, though a small number of heavy-tail regimes continue to dominate the mean.
Significance. If the reported gains hold under detailed scrutiny, GeoPAS would demonstrate that multi-scale geometric probing can yield transferable static signals for solver selection that generalize better than fixed landscape descriptors across problem splits. The open-source code strengthens reproducibility. However, the abstract's own caveat on heavy-tail regimes dominating the mean limits the practical significance for overall mean performance, and the lack of reported error bars, statistical tests, or tail-specific breakdowns reduces confidence in the transferability claim.
major comments (2)
- [Abstract] Abstract: The central claim of consistent improvement over the single-best solver under leave-problem-out evaluation is load-bearing for the transferability argument, yet no quantitative effect sizes, confidence intervals, or statistical significance tests are provided; without these, it is impossible to determine whether gains are robust or driven by the bulk of easier instances.
- [Abstract] Abstract and experimental evaluation: The manuscript acknowledges that 'a small number of heavy-tail regimes remain and continue to dominate the mean' even after the risk-aware log-scale prediction. No breakdown of selection accuracy or regret on tail versus bulk instances is described, so it remains unclear whether the multi-scale geometric slices (plus CNN encoder and conditioning) actually improve performance on the regimes that matter most for the mean.
minor comments (2)
- [Method] The probing budget, exact sampling procedure for the 2D slices (locations, orientations, scales), and validity-aware CNN architecture details should be expanded with pseudocode or equations for reproducibility.
- [Experiments] Figure and table captions should explicitly state the number of runs, random seeds, and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for statistical rigor and targeted analysis of heavy-tail regimes. We will revise the manuscript to incorporate effect sizes, confidence intervals, significance tests, and performance breakdowns, which will better support the transferability claims while maintaining the honest acknowledgment of limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of consistent improvement over the single-best solver under leave-problem-out evaluation is load-bearing for the transferability argument, yet no quantitative effect sizes, confidence intervals, or statistical significance tests are provided; without these, it is impossible to determine whether gains are robust or driven by the bulk of easier instances.
Authors: We agree that the absence of effect sizes, confidence intervals, and statistical tests weakens the ability to assess robustness. In the revised manuscript we will report relative improvements with standard errors or confidence intervals for the leave-problem-out protocol, together with results from paired statistical tests (e.g., Wilcoxon signed-rank) comparing GeoPAS against the single-best solver. These additions will clarify whether observed gains hold across the distribution of instances rather than being driven by easier cases. revision: yes
-
Referee: [Abstract] Abstract and experimental evaluation: The manuscript acknowledges that 'a small number of heavy-tail regimes remain and continue to dominate the mean' even after the risk-aware log-scale prediction. No breakdown of selection accuracy or regret on tail versus bulk instances is described, so it remains unclear whether the multi-scale geometric slices (plus CNN encoder and conditioning) actually improve performance on the regimes that matter most for the mean.
Authors: We accept that a disaggregated analysis is required to evaluate effectiveness on the regimes that dominate the mean. The revised version will include explicit breakdowns of selection accuracy, regret, and solver performance metrics on tail versus bulk instances under all three evaluation protocols. This will be presented in additional tables or figures that isolate the contribution of the multi-scale geometric representation and risk-aware objective on the most challenging cases. revision: yes
Circularity Check
No circularity in derivation chain; performance gains evaluated on held-out splits
full rationale
The GeoPAS pipeline extracts geometric slices, encodes them via a CNN, conditions on scale/amplitude, aggregates invariantly, and trains a log-scale performance predictor with tail penalty. All steps are trained on observed solver runs from COCO/BBOB and evaluated under explicit leave-instance-out, grouped-random, and leave-problem-out protocols. No equation reduces a claimed prediction to a fitted input by construction, no self-citation supplies a load-bearing uniqueness result, and no ansatz is smuggled via prior work. The heavy-tail caveat is an acknowledged empirical limitation rather than a definitional collapse.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-scale 2D geometric slices provide a useful transferable static signal about problem difficulty for algorithm selection.
Reference graph
Works this paper leans on
-
[1]
Mohamad Alissa, Kevin Sim, and Emma Hart. 2023. Automated algorithm selection: from feature-based to feature-free approaches.Journal of Heuristics 29, 1 (2023), 1–38
2023
-
[2]
Asma Atamna. 2015. Benchmarking IPOP-CMA-ES-TPA and IPOP-CMA-ES- MSR on the BBOB noiseless testbed. InProceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1135–1142
2015
-
[3]
Anne Auger, Dimo Brockhoff, and Nikolaus Hansen. 2013. Benchmarking the local metamodel CMA-ES on the noiseless BBOB’2013 test bed. InProceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1225–1232
2013
-
[4]
Petr Baudiš and Petr Pošík. 2015. Global line search algorithm hybridized with quadratic interpolation and its extension to separable functions. InProceedings of the 2015 annual conference on genetic and evolutionary computation. 257–264
2015
-
[5]
Albert S Berahas, Richard H Byrd, and Jorge Nocedal. 2019. Derivative-free optimization of noisy functions via quasi-Newton methods.SIAM Journal on Optimization29, 2 (2019), 965–993
2019
-
[6]
Bernd Bischl, Olaf Mersmann, Heike Trautmann, and Mike Preuß. 2012. Al- gorithm selection based on exploratory landscape analysis and cost-sensitive learning. InProceedings of the 14th annual conference on Genetic and evolutionary computation. 313–320
2012
-
[7]
Gjorgjina Cenikj, Ana Nikolikj, and Tome Eftimov. 2025. Recent Advances in Meta-features Used for Representing Black-box Single-objective Continuous Op- timization. InProceedings of the Genetic and Evolutionary Computation Conference Companion. 1471–1494
2025
-
[8]
Gjorgjina Cenikj, Ana Nikolikj, Gašper Petelin, Niki Van Stein, Carola Doerr, and Tome Eftimov. 2026. A survey of features used for representing black-box single-objective continuous optimization.Swarm and Evolutionary Computation 101 (2026), 102288
2026
-
[9]
Gjorgjina Cenikj, Gašper Petelin, and Tome Eftimov. 2024. Transoptas: Transformer-based algorithm selection for single-objective optimization. InPro- ceedings of the Genetic and Evolutionary Computation Conference Companion. 403–406
2024
-
[10]
Gjorgjina Cenikj, Gašper Petelin, Moritz Seiler, Nikola Cenikj, and Tome Eftimov
-
[11]
Landscape features in single-objective continuous optimization: Have we hit a wall in algorithm selection generalization?Swarm and Evolutionary Computation94 (2025), 101894
2025
-
[12]
Konstantin Dietrich, Diederick Vermetten, Carola Doerr, and Pascal Kerschke
-
[13]
InProceedings of the Genetic and Evolutionary Computation Conference
Impact of training instance selection on automated algorithm selection models for numerical black-box optimization. InProceedings of the Genetic and Evolutionary Computation Conference. 1007–1016
- [14]
-
[15]
Nikolaus Hansen, Anne Auger, Raymond Ros, Olaf Mersmann, Tea Tušar, and Dimo Brockhoff. 2021. COCO: A platform for comparing continuous optimizers in a black-box setting.Optimization Methods and Software36, 1 (2021), 114–144
2021
-
[16]
2009.Real- Parameter Black-Box Optimization Benchmarking 2009: Noiseless Functions Def- initions
Nikolaus Hansen, Steffen Finck, Raymond Ros, and Anne Auger. 2009.Real- Parameter Black-Box Optimization Benchmarking 2009: Noiseless Functions Def- initions. Research Report RR-6829. INRIA. https://inria.hal.science/inria- 00362633v2 Version 2, HAL Id: inria-00362633
2009
-
[17]
Frank Hutter, Holger Hoos, and Kevin Leyton-Brown. 2013. An evaluation of sequential model-based optimization for expensive blackbox functions. In Proceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1209–1216
2013
-
[18]
Waltraud Huyer and Arnold Neumaier. 2009. Benchmarking of MCS on the noiseless function testbed.Online, 2009c. URL http://www. mat. univie. ac. at/˜ neum/papers. html989 (2009)
2009
-
[19]
Stefan Ivić, Siniša Družeta, and Luka Grbčić. 2025. Randomness as Refer- ence: Benchmark Metric for Optimization in Engineering.arXiv preprint arXiv:2511.17226(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Pascal Kerschke, Holger H Hoos, Frank Neumann, and Heike Trautmann. 2019. Automated algorithm selection: Survey and perspectives.Evolutionary computa- tion27, 1 (2019), 3–45
2019
-
[21]
Pascal Kerschke and Heike Trautmann. 2019. Automated algorithm selection on continuous black-box problems by combining exploratory landscape analysis and machine learning.Evolutionary computation27, 1 (2019), 99–127
2019
-
[22]
Ana Kostovska, Carola Doerr, Sašo Džeroski, Panče Panov, and Tome Eftimov
-
[23]
InProceedings of the Genetic and Evolutionary Wang et al
Geometric Learning in Black-Box Optimization: A GNN Framework for Algorithm Performance Prediction. InProceedings of the Genetic and Evolutionary Wang et al. Computation Conference Companion. 487–490
-
[24]
Manuel López-Ibáñez, Diederick Vermetten, Johann Dreo, and Carola Doerr. 2024. Using the empirical attainment function for analyzing single-objective black-box optimization algorithms.IEEE Transactions on Evolutionary Computation(2024)
2024
-
[25]
Ilya Loshchilov, Marc Schoenauer, and Michèle Sebag. 2013. Bi-population CMA-ES agorithms with surrogate models and line searches. InProceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1177–1184
2013
-
[26]
Zeyuan Ma, Hongshu Guo, Yue-Jiao Gong, Jun Zhang, and Kay Chen Tan. 2025. Toward automated algorithm design: A survey and practical guide to meta-black- box-optimization.IEEE Transactions on Evolutionary Computation(2025)
2025
-
[27]
Francesco Mezzadri. 2006. How to generate random matrices from the classical compact groups.arXiv preprint math-ph/0609050(2006)
work page Pith review arXiv 2006
-
[28]
Ana Nikolikj, Ana Kostovska, Gjorgjina Cenikj, Carola Doerr, and Tome Eftimov
-
[29]
In2024 IEEE Congress on Evolutionary Computation (CEC)
Generalization Ability of Feature-Based Performance Prediction Models: A Statistical Analysis Across Benchmarks. In2024 IEEE Congress on Evolutionary Computation (CEC). IEEE, 1–8
-
[30]
Art B Owen. 1998. Scrambling Sobol’and Niederreiter–Xing Points.Journal of complexity14, 4 (1998), 466–489
1998
-
[31]
László Pál. 2013. Benchmarking a hybrid multi level single linkage algorithm on the BBOB noiseless testbed. InProceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1145–1152
2013
-
[32]
László Pál. 2013. Comparison of multistart global optimization algorithms on the BBOB noiseless testbed. InProceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1153–1160
2013
-
[33]
Gašper Petelin and Gjorgjina Cenikj. 2024. On Generalization of ELA Feature Groups. InProceedings of the Genetic and Evolutionary Computation Conference Companion. 419–422
2024
-
[34]
Gašper Petelin and Gjorgjina Cenikj. 2025. The Pitfalls of Benchmarking in Algorithm Selection: What We Are Getting Wrong. InProceedings of the Genetic and Evolutionary Computation Conference. 1181–1189
2025
-
[35]
Gašper Petelin, Gjorgjina Cenikj, and Tome Eftimov. 2024. Tinytla: Topological landscape analysis for optimization problem classification in a limited sample setting.Swarm and Evolutionary Computation84 (2024), 101448
2024
-
[36]
Petr Pošík and Petr Baudiš. 2015. Dimension selection in axis-parallel brent- step method for black-box optimization of separable continuous functions. In Proceedings of the Annual Conference on Genetic and Evolutionary Computation (GECCO) Companion. 1151–1158
2015
-
[37]
Raphael Patrick Prager, Moritz Vinzent Seiler, Heike Trautmann, and Pascal Kerschke. 2022. Automated algorithm selection in single-objective continuous optimization: a comparative study of deep learning and landscape analysis meth- ods. InInternational Conference on Parallel Problem Solving from Nature. Springer, 3–17
2022
- [38]
-
[39]
Moritz Seiler, Urban Škvorc, Gjorgjina Cenikj, Carola Doerr, and Heike Traut- mann. 2024. Learned features vs. Classical ELA on affine BBOB functions. In International Conference on Parallel Problem Solving from Nature. Springer, 137– 153
2024
-
[40]
Moritz Seiler, Urban Škvorc, Carola Doerr, and Heike Trautmann. 2024. Synergies of deep and classical exploratory landscape features for automated algorithm selection. InInternational Conference on Learning and Intelligent Optimization. Springer, 361–376
2024
-
[41]
Moritz Vinzent Seiler, Pascal Kerschke, and Heike Trautmann. 2025. Deep-ela: Deep exploratory landscape analysis with self-supervised pretrained transform- ers for single-and multi-objective continuous optimization problems.Evolution- ary Computation(2025), 1–27
2025
-
[42]
Urban Škvorc, Tome Eftimov, and Peter Korošec. 2021. The effect of sampling methods on the invariance to function transformations when using exploratory landscape analysis. In2021 IEEE Congress on Evolutionary Computation (CEC). IEEE, 1139–1146
2021
-
[43]
Bas van Stein, Fu Xing Long, Moritz Frenzel, Peter Krause, Markus Gitterle, and Thomas Bäck. 2023. Doe2vec: Deep-learning based features for exploratory landscape analysis. InProceedings of the Companion Conference on Genetic and Evolutionary Computation. 515–518
2023
-
[44]
Diederick Vermetten, Furong Ye, Thomas Bäck, and Carola Doerr. 2025. MA- BBOB: A problem generator for black-box optimization using affine combinations and shifts.ACM Transactions on Evolutionary Learning5, 1 (2025), 1–19. Geometric Probing for Algorithm Selection in Continuous Black-Box Optimisation Table 5: Average wall-clock time (s) to generate the in...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.