Recognition: unknown
Camera Artist: A Multi-Agent Framework for Cinematic Language Storytelling Video Generation
Pith reviewed 2026-05-10 16:47 UTC · model grok-4.3
The pith
A dedicated Cinematography Shot Agent with recursive storyboarding and cinematic language injection improves narrative consistency and film quality in multi-agent video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
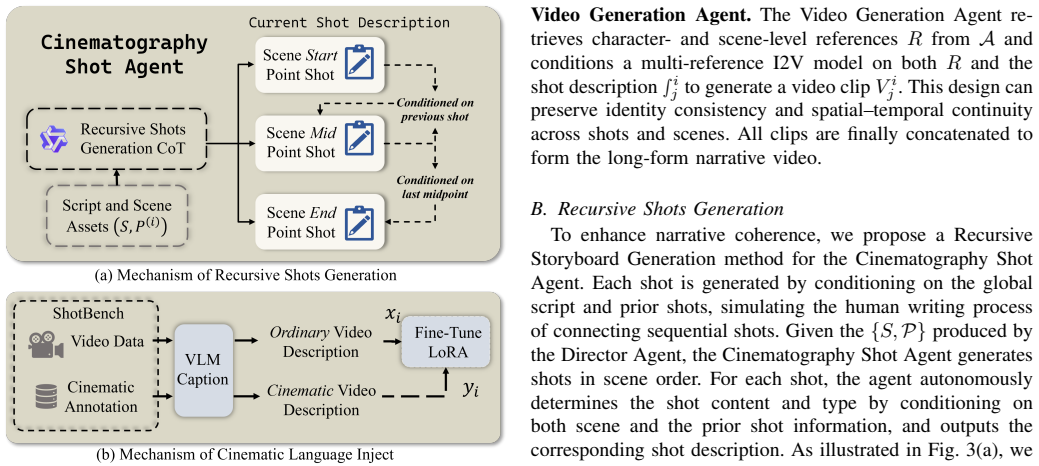
Camera Artist builds upon established agentic pipelines and introduces a dedicated Cinematography Shot Agent, which integrates recursive storyboard generation to strengthen shot-to-shot narrative continuity and cinematic language injection to produce more expressive, film-oriented shot designs.
What carries the argument
The Cinematography Shot Agent, which performs recursive storyboard generation for narrative continuity between shots and injects cinematic language to create more deliberate, expressive shot designs.
If this is right
- Generated videos maintain stronger narrative progression across consecutive shots due to the recursive storyboard process.
- Individual shots incorporate more deliberate cinematic techniques, increasing dynamic expressiveness.
- Human viewers rate the output higher in perceived film quality compared with baseline multi-agent outputs.
- The framework demonstrates consistent outperformance on both automated metrics and qualitative assessments of storytelling coherence.
Where Pith is reading between the lines
- Embedding explicit cinematography rules as structured agent behavior could transfer to other generative media tasks that benefit from domain conventions, such as animation or interactive storytelling.
- The recursive storyboard mechanism suggests a general pattern for maintaining long-range coherence in sequential generation systems without requiring full re-planning at every step.
- If the cinematic language injection proves robust, similar lightweight domain-knowledge modules might reduce reliance on ever-larger base models for creative control.
Load-bearing premise
The specific combination of recursive storyboard generation and cinematic language injection inside the Cinematography Shot Agent is required to achieve the reported gains in continuity and quality, rather than these gains being obtainable through simpler additions to existing multi-agent systems.
What would settle it
An ablation or extension experiment on a baseline multi-agent pipeline that adds general storyboard planning and shot selection but omits the recursive continuity loop and explicit cinematic language rules, then measures whether narrative consistency and film-quality scores reach the same level as Camera Artist.
Figures












read the original abstract
We propose Camera Artist, a multi-agent framework that models a real-world filmmaking workflow to generate narrative videos with explicit cinematic language. While recent multi-agent systems have made substantial progress in automating filmmaking workflows from scripts to videos, they often lack explicit mechanisms to structure narrative progression across adjacent shots and deliberate use of cinematic language, resulting in fragmented storytelling and limited filmic quality. To address this, Camera Artist builds upon established agentic pipelines and introduces a dedicated Cinematography Shot Agent, which integrates recursive storyboard generation to strengthen shot-to-shot narrative continuity and cinematic language injection to produce more expressive, film-oriented shot designs. Extensive quantitative and qualitative results demonstrate that our approach consistently outperforms existing baselines in narrative consistency, dynamic expressiveness, and perceived film quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Camera Artist, a multi-agent framework for generating narrative storytelling videos with explicit cinematic language. It extends prior agentic pipelines by introducing a dedicated Cinematography Shot Agent that performs recursive storyboard generation to improve shot-to-shot narrative continuity and cinematic language injection to enhance dynamic expressiveness and filmic quality. The authors state that extensive quantitative and qualitative results show consistent outperformance over existing baselines in narrative consistency, dynamic expressiveness, and perceived film quality.
Significance. If the empirical claims hold under controlled evaluation, the work could advance multi-agent systems for creative video generation by providing structured mechanisms for cinematic techniques and narrative progression, addressing fragmentation issues in current approaches to automated filmmaking workflows.
major comments (2)
- Abstract: The claim that the approach 'consistently outperforms existing baselines' in narrative consistency, dynamic expressiveness, and perceived film quality is not accompanied by any specific metrics, baseline names, dataset details, or ablation results. This makes it impossible to verify whether gains are attributable to the Cinematography Shot Agent's recursive storyboard generation and cinematic language injection rather than confounding factors such as base model choice or overall prompt complexity.
- Experiments section (inferred from abstract's reference to quantitative/qualitative results): No ablation studies are described that isolate the recursive storyboard generation (e.g., full model vs. non-recursive storyboard variant) or the cinematic language injection (e.g., vs. generic shot prompts). Without these controls, the central attribution of improvements to the new agent's specific mechanisms remains untested and load-bearing for the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. These observations highlight opportunities to improve clarity and empirical rigor. We address each major comment point by point below, indicating the revisions we will make to the next version of the paper.
read point-by-point responses
-
Referee: Abstract: The claim that the approach 'consistently outperforms existing baselines' in narrative consistency, dynamic expressiveness, and perceived film quality is not accompanied by any specific metrics, baseline names, dataset details, or ablation results. This makes it impossible to verify whether gains are attributable to the Cinematography Shot Agent's recursive storyboard generation and cinematic language injection rather than confounding factors such as base model choice or overall prompt complexity.
Authors: We agree that the abstract, as currently written, is too high-level to allow immediate verification of the claims. The Experiments section of the full manuscript already reports the specific metrics (narrative consistency, dynamic expressiveness, and film quality scores), baseline names, dataset details, and controls that use identical base video-generation models across comparisons. To address the referee's concern directly, we will revise the abstract to concisely summarize these key quantitative results and explicitly note that the same underlying models were used to isolate the contributions of the Cinematography Shot Agent. revision: yes
-
Referee: Experiments section (inferred from abstract's reference to quantitative/qualitative results): No ablation studies are described that isolate the recursive storyboard generation (e.g., full model vs. non-recursive storyboard variant) or the cinematic language injection (e.g., vs. generic shot prompts). Without these controls, the central attribution of improvements to the new agent's specific mechanisms remains untested and load-bearing for the outperformance claim.
Authors: We acknowledge that the current manuscript does not present dedicated ablation studies that isolate the recursive storyboard generation and the cinematic language injection components. While the existing baseline comparisons and qualitative analyses provide supporting evidence, explicit ablations would strengthen the causal attribution. In the revised manuscript we will add two targeted ablation experiments: (1) a non-recursive storyboard variant and (2) a generic-prompt variant without cinematic language injection. Both will be evaluated under the same metrics, datasets, and base models as the full model to directly test the contribution of each mechanism. revision: yes
Circularity Check
No circularity: new agent components and evaluation results are independent of inputs
full rationale
The paper describes an extension of prior multi-agent video generation pipelines by adding a Cinematography Shot Agent that performs recursive storyboard generation and cinematic language injection. These are presented as novel mechanisms whose value is measured via separate quantitative and qualitative experiments on narrative consistency, dynamic expressiveness, and film quality. No equations, fitted parameters, or self-referential definitions appear; the outperformance claim is not reduced to a renaming or re-use of the input baselines by construction. The derivation chain therefore remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Established agentic pipelines provide a sufficient base that can be improved by adding domain-specific agents for cinematography and narrative continuity
invented entities (1)
-
Cinematography Shot Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang, “Modelscope text-to-video technical report,”arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al., “Hunyuanvideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Yuanhang Li, Qi Mao, Lan Chen, Zhen Fang, Lei Tian, Xinyan Xiao, Libiao Jin, and Hua Wu, “Starvid: Enhancing semantic alignment in video diffusion models via spatial and syntactic guided attention refocusing,”arXiv preprint arXiv:2409.15259, 2024
-
[5]
Captain cinema: Towards short movie generation,
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan Yuille, and Lu Jiang, “Captain cinema: Towards short movie generation,”arXiv preprint arXiv:2507.18634, 2025
-
[6]
Multi-agent systems: A survey,
Ali Dorri, Salil S Kanhere, and Raja Jurdak, “Multi-agent systems: A survey,”IEEE Access, 2018
2018
-
[7]
A survey on evaluation of large language models,
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al., “A survey on evaluation of large language models,”TIST, 2024
2024
-
[8]
Anim-director: A large multimodal model powered agent for controllable animation video generation,
Yunxin Li, Haoyuan Shi, Baotian Hu, Longyue Wang, Jiashun Zhu, Jinyi Xu, Zhen Zhao, and Min Zhang, “Anim-director: A large multimodal model powered agent for controllable animation video generation,” in SIGGRAPH Asia, 2024
2024
-
[9]
Dreamstory: Open-domain story visualization by llm-guided multi- subject consistent diffusion,
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin, “Dreamstory: Open-domain story visualization by llm-guided multi- subject consistent diffusion,”PAMI, 2025
2025
-
[10]
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Shu, Yatian Pang, Feilong Tang, et al., “Videogen-of-thought: Step-by-step generating multi-shot video with minimal manual interven- tion,”arXiv preprint arXiv:2412.02259, 2024
-
[11]
arXiv preprint arXiv:2503.07314 (2025)
Weijia Wu, Zeyu Zhu, and Mike Zheng Shou, “Automated movie gen- eration via multi-agent cot planning,”arXiv preprint arXiv:2503.07314, 2025
-
[12]
Chain-of-thought prompting elicits reasoning in large language models,
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al., “Chain-of-thought prompting elicits reasoning in large language models,” inNeurIPS, 2022
2022
-
[13]
Lora: Low-rank adaptation of large language models.,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al., “Lora: Low-rank adaptation of large language models.,” inICLR, 2022
2022
-
[14]
“Gpt-4o,” Accessed May 13, 2024 [Online] https://openai.com/index/ hello-gpt-4o/
2024
-
[15]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Shotbench: Expert-level cinematic understanding in vision-language models,
Hongbo Liu, Jingwen He, Yi Jin, Dian Zheng, Yuhao Dong, Fan Zhang, Ziqi Huang, Yinan He, Yangguang Li, Weichao Chen, et al., “Shotbench: Expert-level cinematic understanding in vision-language models,”arXiv preprint arXiv:2506.21356, 2025
-
[17]
Magref: Masked guidance for any-reference video generation,
Yufan Deng, Xun Guo, Yuanyang Yin, Jacob Zhiyuan Fang, Yiding Yang, Yizhi Wang, Shenghai Yuan, Angtian Wang, Bo Liu, Haibin Huang, et al., “Magref: Masked guidance for any-reference video generation,”arXiv preprint arXiv:2505.23742, 2025
-
[18]
Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al., “Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv e-prints, pp. arXiv–2506, 2025
2025
-
[19]
VBench: Compre- hensive benchmark suite for video generative models,
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, et al., “VBench: Compre- hensive benchmark suite for video generative models,” inCVPR, 2024
2024
-
[20]
Learning transferable visual models from natural language supervision,
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al., “Learning transferable visual models from natural language supervision,” inICML, 2021, pp. 8748–8763
2021
-
[21]
Gemini: a family of highly capable multimodal models,
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al., “Gemini: a family of highly capable multimodal models,” Tech. Rep., 2023. Camera Artist: A Multi-Agent Framework for Cinematic Language Storytelling Video Generation Supplementary Material APPENDIX...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.