Recognition: no theorem link
SHIFT: Steering Hidden Intermediates in Flow Transformers
Pith reviewed 2026-05-10 18:30 UTC · model grok-4.3
The pith
SHIFT steers intermediate activations in DiT diffusion models to remove unwanted concepts at inference time without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SHIFT learns steering vectors from intermediate activations and applies them dynamically to chosen layers and timesteps in DiT models, thereby suppressing target visual concepts, moving generations into desired style domains, or biasing samples toward specific objects, all while preserving prompt adherence and sample quality.
What carries the argument
Steering vectors applied to hidden intermediate activations in the DiT flow transformer to guide concept presence during inference.
If this is right
- DiT models can be adapted for concept removal or style control without any retraining step.
- The same steering mechanism works for suppressing targets, adding styles, or changing object content.
- Effective control holds across varied prompts and different target concepts.
- Generation quality and adherence to the original prompt remain largely unchanged.
Where Pith is reading between the lines
- The approach could be tested on other transformer-based image or video generators beyond DiT.
- Deployed systems might use similar vectors for on-the-fly content moderation.
- The vectors may encode interpretable directions in the model's internal representation of scenes.
- Pairing SHIFT with existing prompt techniques could produce finer-grained edits.
Load-bearing premise
Steering vectors can be found that selectively suppress or shift only the intended concept without harming image quality, prompt fidelity, or consistency across prompts and timesteps.
What would settle it
Applying the learned vectors to a fresh set of prompts produces images that either retain the target concept or show clear losses in visual quality and prompt match compared with the unsteered baseline.
Figures































read the original abstract
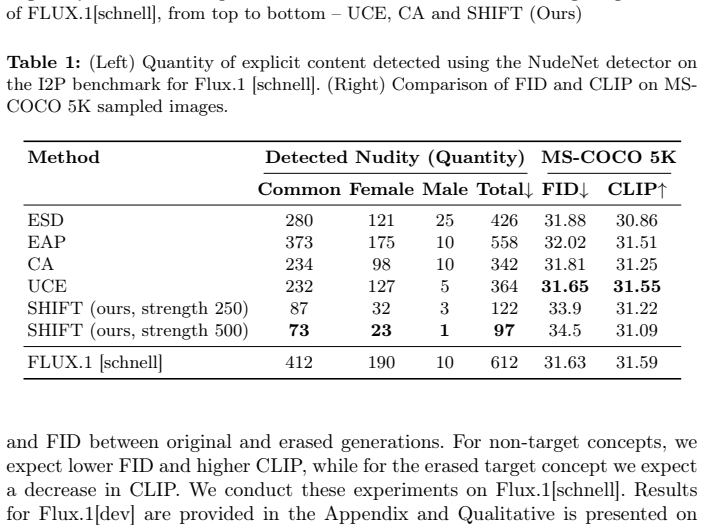
Diffusion models have become leading approaches for high-fidelity image generation. Recent DiT-based diffusion models, in particular, achieve strong prompt adherence while producing high-quality samples. We propose SHIFT, a simple but effective and lightweight framework for concept removal in DiT diffusion models via targeted manipulation of intermediate activations at inference time, inspired by activation steering in large language models. SHIFT learns steering vectors that are dynamically applied to selected layers and timesteps to suppress unwanted visual concepts while preserving the prompt's remaining content and overall image quality. Beyond suppression, the same mechanism can shift generations into a desired \emph{style domain} or bias samples toward adding or changing target objects. We demonstrate that SHIFT provides effective and flexible control over DiT generation across diverse prompts and targets without time-consuming retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SHIFT, a lightweight inference-time framework for DiT-based diffusion models that learns steering vectors from intermediate activations and applies them dynamically to selected layers and timesteps. The goal is to suppress target visual concepts (or shift style/object presence) while preserving prompt adherence and sample quality, without any retraining or fine-tuning of the underlying model.
Significance. If the empirical claims hold, the work would be significant for practical control of large generative models: it offers a training-free alternative to concept erasure or editing that is both computationally cheap and flexible across prompts. The approach builds on activation-steering ideas from LLMs and adapts them to the diffusion trajectory, which could generalize to other transformer-based generators.
major comments (2)
- [Method] The central claim that steering vectors can be learned to selectively suppress concepts without side effects on fidelity or adherence rests on an unstated assumption that concepts are additively separable in the chosen intermediate activations. No derivation or analysis is provided showing why this holds for DiT blocks across timesteps; the method description would benefit from an explicit statement of the optimization objective used to obtain the vectors.
- [Experiments] The abstract asserts effectiveness 'across diverse prompts and targets' and preservation of image quality, yet the visible text contains no quantitative metrics, ablation tables, or failure-case analysis. Without reported numbers (e.g., concept-suppression accuracy, FID, CLIP similarity, or human preference scores) it is impossible to assess whether the steering introduces artifacts or prompt drift.
minor comments (2)
- [Title/Abstract] The title refers to 'Flow Transformers' while the abstract discusses DiT diffusion models; a brief clarification of the relationship (or whether 'Flow' denotes a specific variant) would avoid confusion.
- [Method] Notation for the steering vector application (e.g., which exact layers and timestep ranges are selected) should be formalized with an equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below, clarifying the method and committing to strengthened experimental reporting in the revision.
read point-by-point responses
-
Referee: [Method] The central claim that steering vectors can be learned to selectively suppress concepts without side effects on fidelity or adherence rests on an unstated assumption that concepts are additively separable in the chosen intermediate activations. No derivation or analysis is provided showing why this holds for DiT blocks across timesteps; the method description would benefit from an explicit statement of the optimization objective used to obtain the vectors.
Authors: The steering vectors are obtained by computing the difference between mean activations conditioned on prompts that include versus exclude the target concept, at the selected layers and timesteps. This direction is then scaled and added during inference. While the approach is primarily empirical and draws from successful activation steering in LLMs, we agree that the manuscript would be improved by an explicit statement of the objective (maximizing concept suppression subject to bounded deviation from the original activation trajectory) and a short discussion of the additive separability assumption. We will add this clarification and a brief supporting analysis in the revised method section. revision: yes
-
Referee: [Experiments] The abstract asserts effectiveness 'across diverse prompts and targets' and preservation of image quality, yet the visible text contains no quantitative metrics, ablation tables, or failure-case analysis. Without reported numbers (e.g., concept-suppression accuracy, FID, CLIP similarity, or human preference scores) it is impossible to assess whether the steering introduces artifacts or prompt drift.
Authors: The current version emphasizes qualitative results to demonstrate flexibility across prompts and targets. We acknowledge that quantitative support is necessary to substantiate the claims of preserved fidelity and adherence. In the revision we will add tables reporting CLIP-based concept suppression scores, FID and CLIP similarity for image quality and prompt adherence, ablation studies on layer/timestep selection, and a discussion of observed failure cases. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes SHIFT as an empirical framework for steering intermediate activations in DiT models to suppress concepts at inference time. No mathematical derivations, equations, first-principles results, or prediction claims appear in the abstract or described content. The method is framed as learning and applying steering vectors without any self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim to its own inputs. The approach is self-contained as a practical technique with no derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Science391(6787), 787–792 (2026)
Beaglehole, D., Radhakrishnan, A., Boix-Adsera, E., Belkin, M.: Toward universal steering and monitoring of ai models. Science391(6787), 787–792 (2026)
2026
-
[2]
arXiv preprint arXiv:2212.06013 (2022)
Brack, M., Schramowski, P., Friedrich, F., Hintersdorf, D., Kersting, K.: The stable artist: Steering semantics in diffusion latent space. arXiv preprint arXiv:2212.06013 (2022)
-
[3]
Bui, A., Vuong, L., Doan, K., Le, T., Montague, P., Abraham, T., Phung, D.: Erasing undesirable concepts in diffusion models with adversarial preservation. arXiv preprint arXiv:2410.15618 (2024)
-
[4]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[5]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[6]
arXiv e-prints pp
Gaintseva, T., Ma, C., Liu, Z., Benning, M., Slabaugh, G., Deng, J., Elezi, I.: Casteer: Steering diffusion models for controllable generation. arXiv e-prints pp. arXiv–2503 (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2426–2436 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 5111–5120 (2024)
2024
-
[9]
In: Forty-second International Conference on Machine Learning (2025)
Gao, D., Lu, S., Zhou, W., Chu, J., Zhang, J., Jia, M., Zhang, B., Fan, Z., Zhang, W.: Eraseanything: Enabling concept erasure in rectified flow transformers. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[10]
Hernandez, E., Li, B.Z., Andreas, J.: Inspecting and editing knowledge represen- tations in language models. arXiv preprint arXiv:2304.00740 (2023)
-
[11]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[12]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Editing Models with Task Arithmetic
Ilharco, G., Ribeiro, M.T., Wortsman, M., Gururangan, S., Schmidt, L., Ha- jishirzi, H., Farhadi, A.: Editing models with task arithmetic. arXiv preprint arXiv:2212.04089 (2022) 16 Konovalova et al
work page internal anchor Pith review arXiv 2022
-
[14]
In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Khashabi, D., Lyu, X., Min, S., Qin, L., Richardson, K., Welleck, S., Hajishirzi, H., Khot, T., Sabharwal, A., Singh, S., et al.: Prompt waywardness: The curious case of discretized interpretation of continuous prompts. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tec...
2022
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kumari, N., Zhang, B., Wang, S.Y., Shechtman, E., Zhang, R., Zhu, J.Y.: Ablat- ing concepts in text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 22691–22702 (2023)
2023
-
[16]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 3045–3059 (2021)
2021
-
[18]
Advances in Neural Information Processing Systems36, 41451–41530 (2023)
Li, K., Patel, O., Viégas, F., Pfister, H., Wattenberg, M.: Inference-time inter- vention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems36, 41451–41530 (2023)
2023
-
[19]
In: The Thirteenth International Conference on Learning Representations (2025)
Liu, S., Ye, H., Zou, J.: Reducing hallucinations in large vision-language models via latent space steering. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lyu, M., Yang, Y., Hong, H., Chen, H., Jin, X., He, Y., Xue, H., Han, J., Ding, G.: One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7559–7568 (2024)
2024
-
[21]
Advances in neural information processing systems35, 17359–17372 (2022)
Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and editing factual associ- ations in gpt. Advances in neural information processing systems35, 17359–17372 (2022)
2022
-
[22]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[23]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[25]
Journal of machine learning research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020)
2020
-
[26]
Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610, 2022
Rando, J., Paleka, D., Lindner, D., Heim, L., Tramèr, F.: Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610 (2022)
-
[27]
arXiv preprint arXiv:2410.23054 (2024)
Rodriguez, P., Blaas, A., Klein, M., Zappella, L., Apostoloff, N., Cuturi, M., Suau, X.: Controlling language and diffusion models by transporting activations. arXiv preprint arXiv:2410.23054 (2024)
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[29]
In: Proceedings of the SHIFT 17 IEEE/CVF conference on computer vision and pattern recognition
Schramowski, P., Brack, M., Deiseroth, B., Kersting, K.: Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In: Proceedings of the SHIFT 17 IEEE/CVF conference on computer vision and pattern recognition. pp. 22522– 22531 (2023)
2023
-
[30]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[31]
In: Findings of the Association for Computational Linguistics: ACL 2022
Subramani, N., Suresh, N., Peters, M.E.: Extracting latent steering vectors from pretrained language models. In: Findings of the Association for Computational Linguistics: ACL 2022. pp. 566–581 (2022)
2022
-
[33]
Steering Language Models With Activation Engineering
Turner, A.M., Thiergart, L., Leech, G., Udell, D., Vazquez, J.J., Mini, U., Mac- Diarmid, M.: Steering language models with activation engineering, 2024. URL https://arxiv. org/abs/2308.102482308(2024)
work page internal anchor Pith review arXiv 2024
-
[34]
arXiv preprint arXiv:2507.13386 (2025)
Zhang, Y., Jin, E., Dong, Y., Wu, Y., Torr, P., Khakzar, A., Stegmaier, J., Kawaguchi, K.: Minimalist concept erasure in generative models. arXiv preprint arXiv:2507.13386 (2025)
-
[35]
In: NeurIPS ML Safety Workshop (2022)
Zhou, Y., Muresanu, A.I., Han, Z., Paster, K., Pitis, S., Chan, H., Ba, J.: Steering large language models using ape. In: NeurIPS ML Safety Workshop (2022)
2022
-
[36]
Fine-Tuning Language Models from Human Preferences
Ziegler, D.M., Stiennon, N., Wu, J., Brown, T.B., Radford, A., Amodei, D., Chris- tiano, P., Irving, G.: Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593 (2019)
work page internal anchor Pith review arXiv 1909
-
[37]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.K., et al.: Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405 (2023) 18 Konovalova et al. 7 Appendix 7.1 Implementation details Baselines UCE.We follow the official UCE implementation. For nudity erasu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Fluffy white cat
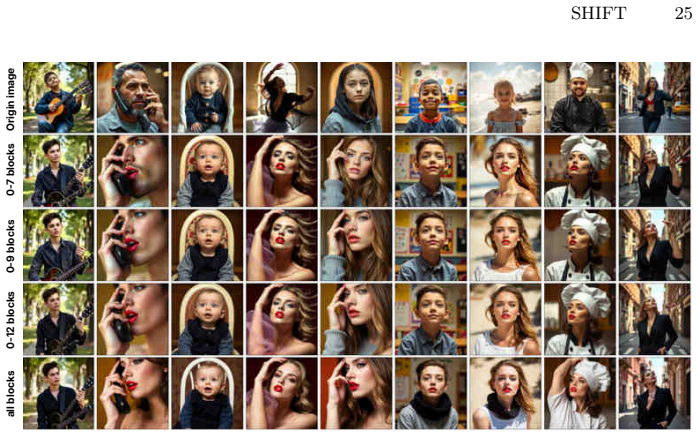
Both models were tested with DiT blocks steering strength250. Flux.1[schnell] Flux.1[dev] origin UCESteered origin ESDSteered* Steered Van Gogh style erase Fig. 9:Qualitative results for Van Gogh style erasure. First row: original Flux.1[dev] and Flux.1[schnell] generations. Second row: UCE and ESD competitors. Last rows: our steered generations, where * ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.