Recognition: unknown
DRBENCHER: Can Your Agent Identify the Entity, Retrieve Its Properties and Do the Math?
Pith reviewed 2026-05-10 16:42 UTC · model grok-4.3
The pith
Even top AI agents succeed on only 20 percent of tasks that combine web browsing with multi-step calculation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
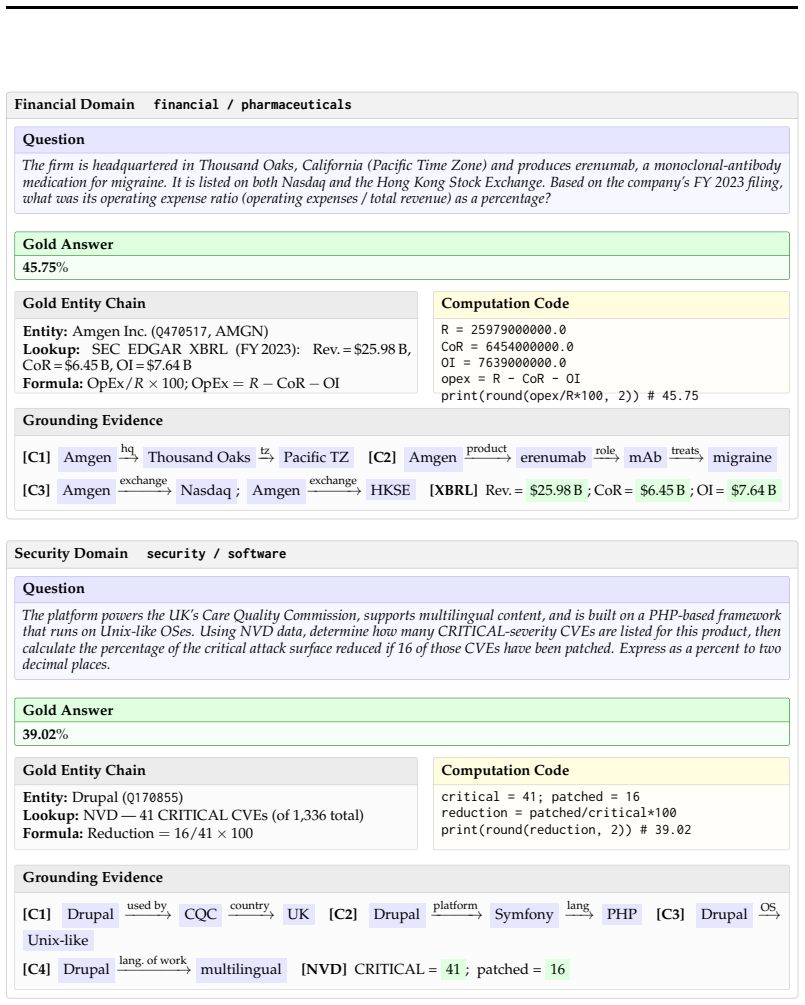
DRBENCHER is a synthetic benchmark generator that produces questions requiring multi-hop entity identification, property retrieval from knowledge graphs, and domain-specific computation. It realizes this through an answer-first pipeline that executes parameterized code to obtain gold answers, then applies a two-stage verification cascade and a greedy max-min embedding filter to enforce difficulty and diversity. The resulting questions span biochemistry, financial, geophysical, security, and history domains, yield 76 percent human validity, and expose that the strongest frontier models achieve only 20 percent answer accuracy.
What carries the argument
The answer-first pipeline that first computes gold answers by running parameterized code over knowledge-graph values, then applies verifiability, complexity, difficulty, and diversity filters to the generated questions.
If this is right
- Isolated benchmarks for browsing or computation overestimate current agent readiness for realistic research tasks.
- Agent systems must develop tighter integration between information retrieval and mathematical execution steps.
- Synthetic generation pipelines can produce test sets with higher semantic diversity and built-in verifiability than manual construction.
- The gap between model performance on separate skills and on combined tasks will persist until training addresses interleaved workflows directly.
Where Pith is reading between the lines
- Training regimens for agents may need to incorporate more synthetic or simulated interleaved examples to close the observed performance gap.
- The presence of stale knowledge-graph entries points to a need for agents that can detect and update against live data sources.
- Applying the same generation approach to new domains could test whether the low accuracy is a general limitation or varies by subject area.
Load-bearing premise
That the synthetic questions generated by the answer-first pipeline with the stated filters accurately represent the difficulty and structure of real-world tasks that interleave web browsing with multi-step computation.
What would settle it
Testing the same frontier models on a collection of human-written questions drawn from actual research workflows that require comparable entity identification, property lookup, and calculation would show whether accuracy stays near 20 percent or rises substantially.
Figures



read the original abstract
Deep research agents increasingly interleave web browsing with multi-step computation, yet existing benchmarks evaluate these capabilities in isolation, creating a blind spot in assessing real-world performance. We introduce DRBENCHER, a synthetic benchmark generator for questions that require both browsing and computation. It enforces four criteria: verifiability (gold answers are computed by executing parameterized code over knowledge-graph values), complexity (multi-hop entity identification, property retrieval, and domain-specific computation), difficulty (a two-stage verification cascade filters out questions solvable by the generating model), and diversity (a greedy max-min embedding filter maximizes coverage). These criteria are realized via a unified answer-first pipeline spanning five domains: biochemistry, financial, geophysical, security, and history. Human evaluation shows 76% validity (84% excluding stale data), with 35% of errors due to outdated knowledge-graph entries, highlighting an inherent limitation of systems that reason over evolving data. Automatic evaluation shows that the strongest frontier model achieves only 20% answer accuracy. Compared to manually constructed benchmarks (BrowseComp+, MATH-500, GPQA), DRBENCHER achieves the highest semantic diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRBENCHER, a synthetic benchmark generator for questions requiring interleaved web browsing, entity identification, property retrieval, and domain-specific multi-step computation. It employs an answer-first pipeline that generates verifiable gold answers via parameterized code over a knowledge graph, applies a two-stage verification cascade to filter out questions solvable by the generator model, and uses embedding-based diversity filtering. Across five domains, human evaluation reports 76% validity (84% excluding stale data) with 35% of errors from outdated KG entries, while the strongest frontier model achieves 20% answer accuracy; DRBENCHER is claimed to have higher semantic diversity than BrowseComp+, MATH-500, and GPQA.
Significance. If the questions reliably require live web retrieval interleaved with computation and the gold labels are robust, DRBENCHER would be significant for exposing limitations in current agents on realistic deep-research tasks and for offering a scalable, verifiable method to generate such benchmarks. The synthetic construction with explicit verifiability criteria is a clear methodological strength.
major comments (3)
- The 76% human validity rate (with 35% of errors due to stale knowledge-graph entries) directly affects the reliability of the reported 20% model accuracy, because agents performing live web browsing would be penalized on questions where the KG is outdated relative to current data.
- The answer-first pipeline with verification cascade and diversity filter guarantees verifiability and removes easy cases for the generator, but provides no analysis or ablation showing that the resulting questions cannot be solved via parametric knowledge, pattern matching on synthetic templates, or domain-specific memorized facts rather than requiring open-ended web retrieval interleaved with computation.
- The claim that DRBENCHER achieves the highest semantic diversity lacks accompanying quantitative metrics, embedding model details, or a table comparing diversity scores against BrowseComp+, MATH-500, and GPQA, making the comparison difficult to evaluate.
minor comments (2)
- The abstract and evaluation sections would benefit from reporting the total number of questions, full error breakdowns by domain, and statistical significance tests for the 20% accuracy figure.
- Additional details on the exact prompts and models used in the two-stage verification cascade would improve reproducibility.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our work. Below, we address each of the major comments point by point, indicating where revisions will be made.
read point-by-point responses
-
Referee: The 76% human validity rate (with 35% of errors due to stale knowledge-graph entries) directly affects the reliability of the reported 20% model accuracy, because agents performing live web browsing would be penalized on questions where the KG is outdated relative to current data.
Authors: We agree that the presence of stale data in the knowledge graph introduces a limitation for evaluating live web-browsing agents, as they may retrieve more current information than what is encoded in the KG at the time of benchmark generation. In the original manuscript, we already report the 84% validity rate excluding stale data and note that 35% of errors stem from outdated entries. To further address this, we will expand the discussion section to analyze the impact on model accuracy metrics and propose that future iterations of DRBENCHER could incorporate mechanisms for dynamic KG updates or time-stamped questions. This will provide a more nuanced interpretation of the 20% accuracy figure. revision: yes
-
Referee: The answer-first pipeline with verification cascade and diversity filter guarantees verifiability and removes easy cases for the generator, but provides no analysis or ablation showing that the resulting questions cannot be solved via parametric knowledge, pattern matching on synthetic templates, or domain-specific memorized facts rather than requiring open-ended web retrieval interleaved with computation.
Authors: We acknowledge that while the two-stage verification cascade filters out questions solvable by the generator model (a frontier LLM), additional ablations would strengthen the claim that the questions necessitate interleaved browsing and computation rather than relying on parametric knowledge alone. In the revised version, we will include an ablation study where we evaluate the same models on the DRBENCHER questions without access to browsing tools, relying solely on their internal knowledge. We expect this to show significantly lower performance, supporting the need for retrieval. We will also discuss potential template patterns and how the diversity filter and multi-domain parameterization mitigate memorization risks. revision: yes
-
Referee: The claim that DRBENCHER achieves the highest semantic diversity lacks accompanying quantitative metrics, embedding model details, or a table comparing diversity scores against BrowseComp+, MATH-500, and GPQA, making the comparison difficult to evaluate.
Authors: We agree that the diversity comparison would be more rigorous with explicit quantitative metrics. In the revised manuscript, we will provide details on the embedding model used for the diversity filter, the exact diversity metric employed (such as the max-min greedy selection score based on embeddings), and include a table comparing these scores across DRBENCHER, BrowseComp+, MATH-500, and GPQA. This will allow readers to better evaluate the claim of highest semantic diversity. revision: yes
Circularity Check
No significant circularity in DRBENCHER benchmark construction
full rationale
The paper presents DRBENCHER as a synthetic benchmark generator built via an explicit answer-first pipeline that produces verifiable gold answers by executing parameterized code over a knowledge graph, then applies two-stage model-based filtering for difficulty and embedding-based selection for diversity. All reported outcomes (76% human validity rate, 20% frontier-model accuracy, semantic diversity comparisons) are direct empirical measurements from human and automatic evaluations on the generated questions. No mathematical derivations, predictions, or first-principles results are claimed; the construction criteria are realized transparently through code and filters without reducing to fitted parameters, self-definitional loops, or load-bearing self-citations. The central claims remain independent empirical observations rather than tautological restatements of the generation process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge-graph entries provide the ground-truth values needed for verifiable answer computation
Reference graph
Works this paper leans on
-
[1]
URL https: //www.anthropic.com/news/claude-opus-4-6. Parul Awasthy, Aashka Trivedi, Yulong Li, Meet Doshi, Riyaz Bhat, Vignesh P , Vishwajeet Kumar, Yushu Yang, Bhavani Iyer, Abraham Daniels, Rudra Murthy, Ken Barker, Martin Franz, Madison Lee, Todd Ward, Salim Roukos, David Cox, Luis Lastras, Jaydeep Sen, and Radu Florian. Granite embedding r2 models.arX...
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://www.anthropic.com/engineering/ eval-awareness-browsecomp. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inder- jit Dhillon, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 2368–2378,
2019
-
[6]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. InProceedings of the 2025 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL),
2025
-
[7]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A
URL https://arxiv.org/abs/2504.01001. Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023,
-
[8]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3982–3992,
2019
-
[9]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533,
work page internal anchor Pith review arXiv
-
[10]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseC- omp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516,
work page internal anchor Pith review arXiv
-
[11]
Livebench: A challenging, contamination-free llm benchmark,
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, et al. LiveBench: A challenging, contamination-free LLM benchmark.arXiv preprint arXiv:2406.19314,
-
[12]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged re- sources to advance general chinese embedding.arXiv preprint arXiv:2309.07597,
work page internal anchor Pith review arXiv
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples.arXiv preprint arXiv:2311.04850,
-
[15]
Cohen, Ruslan Salakhut- dinov, and Christopher D
12 Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2018
-
[16]
13 A Model Configuration and Verification Hyperparameters Table 8 lists the model serving configuration
Spotlight. 13 A Model Configuration and Verification Hyperparameters Table 8 lists the model serving configuration. Table 9 summarizes the verification-stage hyperparameters. Parameter Value Architecture MoE, 120B parameters Quantization MXFP4 Precision bfloat16 Tensor parallel size 8 GPU memory utilization 0.9 Max sequence length 131,072 tokens Chunked p...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.