Recognition: unknown
ChatGPT, is this real? The influence of generative AI on writing style in top-tier cybersecurity papers
Pith reviewed 2026-05-10 17:10 UTC · model grok-4.3
The pith
Top cybersecurity papers show rising lexical complexity and a sharp post-2022 increase in AI marker words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
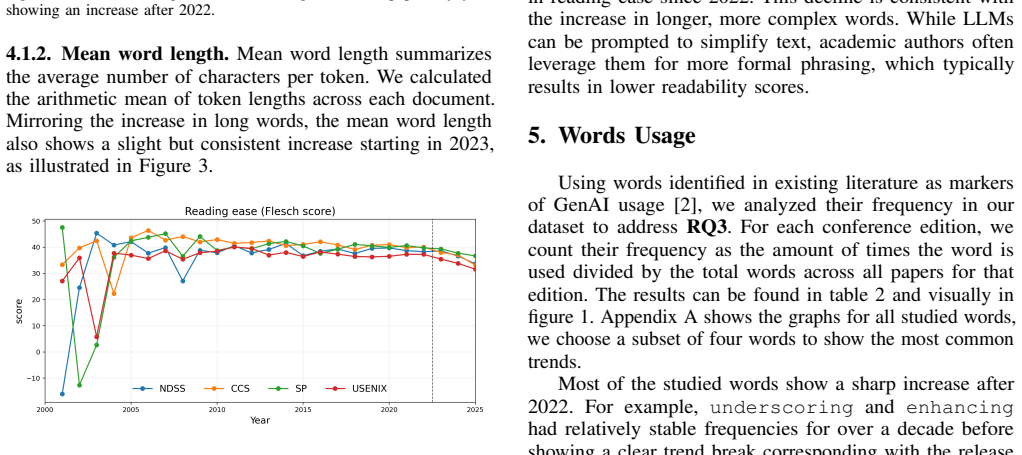
Text extracted from PDFs of papers at NDSS, USENIX Security, IEEE S&P, and ACM CCS is used to compute lexical and syntactic metrics and to measure usage of a curated list of marker words. The analysis finds a gradual long-run drift toward higher lexical complexity together with a pronounced post-2022 increase in marker-word usage that holds across all four venues.
What carries the argument
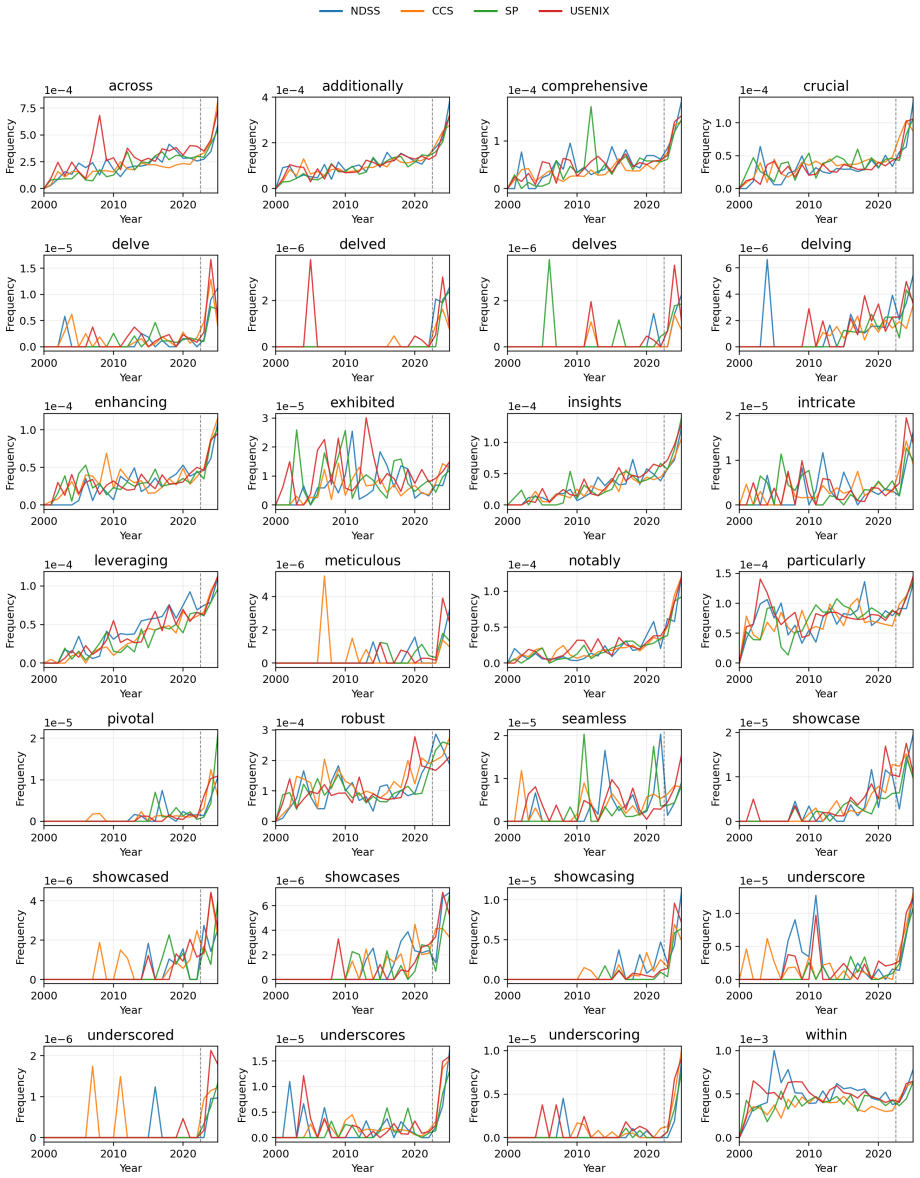
A curated list of marker words commonly associated with generative-AI text, tracked together with standard lexical-complexity metrics to detect stylistic shifts.
If this is right
- Cybersecurity papers have become gradually more lexically complex since 2000.
- Marker-word frequency rose sharply after 2022 in every major venue studied.
- The increase in marker words and complexity is consistent across NDSS, USENIX Security, IEEE S&P, and ACM CCS.
- The observed changes may reduce how easily new readers can understand the papers.
Where Pith is reading between the lines
- Conferences could test whether stronger disclosure rules on AI use slow the rise in marker words.
- The same marker-word method could be applied to other research fields to check whether the pattern is unique to cybersecurity.
- Authors might adopt simple review steps to remove overused marker words and keep sentences clearer.
Load-bearing premise
The chosen marker words reliably point to generative-AI influence rather than ordinary changes in academic writing habits or research topics.
What would settle it
A re-analysis of the same papers that finds no post-2022 marker-word jump after controlling for author background and topic or that shows the same jump in pre-2022 papers would weaken the link to generative AI.
Figures



read the original abstract
With the release of ChatGPT in 2022, generative AI has significantly lowered the cost of polishing and rewriting text. Due to its widespread usage, conference organizers instated specific requirements researchers need to adhere to when using GenAI. When asked to rewrite text, GenAI can introduce stylistic changes, often concentrated to a handful of ``marker words`` commonly associated with AI usage. Prior large-scale studies in preprints and biomedical science report post-2022 discontinuities of those marker words and broad linguistic features. This paper investigates whether similar patterns appear in top-tier cybersecurity conference papers (NDSS, USENIX Security, IEEE S\&P, and ACM CCS) over the period 2000-2025. Using text extracted from paper PDFs, we compute lexical and syntactic metrics and track curated marker-word usage. Our findings reveal a gradual long-run drift toward higher lexical complexity and a pronounced post-2022 increase in marker-word usage across all venues showing an emerging trend towards more complex language in cybersecurity papers possibly hindering accessibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes writing style changes in top-tier cybersecurity conference papers (NDSS, USENIX Security, IEEE S&P, ACM CCS) from 2000 to 2025, focusing on the potential influence of generative AI tools like ChatGPT since 2022. Using PDF-extracted text, it calculates lexical complexity metrics and tracks the frequency of a curated set of 'marker words' associated with AI-generated content. The central findings are a gradual long-term increase in lexical complexity and a sharp post-2022 rise in marker-word usage across venues, interpreted as evidence of GenAI-driven stylistic shifts that may reduce accessibility.
Significance. If the post-2022 discontinuity can be isolated from confounding factors such as topic shifts toward AI/ML subfields, the result would extend prior observations from preprints and biomedical literature to the cybersecurity domain. This could inform policies on AI-assisted writing in conferences and highlight risks to the accessibility of technical papers. The study benefits from its focus on a well-defined corpus of high-impact venues, providing a concrete dataset for future replication.
major comments (4)
- [§3 Methods] §3 Methods: The curation process and full list of marker words are not detailed beyond their association with AI usage; this is load-bearing because the central claim relies on these words specifically indicating GenAI influence rather than general academic trends.
- [§3 Methods] §3 Methods: No quantitative assessment of PDF text extraction accuracy (e.g., word error rates or validation on a sample) is provided. Given that lexical metrics are sensitive to extraction errors, this undermines confidence in the computed trends.
- [§4 Results] §4 Results: The post-2022 increase in marker words and lexical complexity is presented without controls for subfield composition or topic modeling. Cybersecurity venues have experienced a surge in ML and LLM-related papers since 2022, which could independently drive higher lexical diversity and specific phrasing, confounding attribution to GenAI.
- [§4 Results] §4 Results: Details on the statistical tests, p-values, or confidence intervals supporting the 'pronounced' post-2022 discontinuity are absent, making it difficult to evaluate the robustness of the claimed jump against the gradual long-run drift.
minor comments (3)
- [Abstract] Abstract: The final sentence is a run-on; consider breaking it into two for improved readability.
- [Introduction] Introduction: The prior large-scale studies in preprints and biomedical science are referenced but not cited; adding specific references would strengthen the positioning.
- [Throughout] Throughout: Ensure all figures and tables have clear captions explaining the metrics and time periods analyzed.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below, outlining the revisions we plan to incorporate to address the concerns raised.
read point-by-point responses
-
Referee: [§3 Methods] The curation process and full list of marker words are not detailed beyond their association with AI usage; this is load-bearing because the central claim relies on these words specifically indicating GenAI influence rather than general academic trends.
Authors: We agree that providing the full details on marker word curation is essential for transparency and to allow evaluation of whether these words capture GenAI-specific effects versus broader trends. In the revised manuscript, we will expand §3 to include the complete list of marker words along with a step-by-step description of the curation process, which is grounded in prior studies of AI-generated text markers from the literature. revision: yes
-
Referee: [§3 Methods] No quantitative assessment of PDF text extraction accuracy (e.g., word error rates or validation on a sample) is provided. Given that lexical metrics are sensitive to extraction errors, this undermines confidence in the computed trends.
Authors: This is a valid concern given the sensitivity of lexical metrics. We will add a new subsection in the Methods describing our text extraction validation, including quantitative results from manual review of a random sample of papers (e.g., word error rates and agreement metrics) to demonstrate the reliability of the extracted text used for all analyses. revision: yes
-
Referee: [§4 Results] The post-2022 increase in marker words and lexical complexity is presented without controls for subfield composition or topic modeling. Cybersecurity venues have experienced a surge in ML and LLM-related papers since 2022, which could independently drive higher lexical diversity and specific phrasing, confounding attribution to GenAI.
Authors: We recognize this as a potential confounding factor. In the revision, we will add controls by classifying papers into subfields (e.g., via keyword and topic modeling approaches) and re-running the analyses on non-ML/LLM subsets to isolate the post-2022 trends. While the observed consistency across all four venues provides some support for our interpretation, these additional controls will help rule out topic-driven explanations. revision: yes
-
Referee: [§4 Results] Details on the statistical tests, p-values, or confidence intervals supporting the 'pronounced' post-2022 discontinuity are absent, making it difficult to evaluate the robustness of the claimed jump against the gradual long-run drift.
Authors: We agree that explicit statistical details are needed to assess the discontinuity. The revised Results section will report the specific tests used (including change-point analysis and trend comparisons), along with associated p-values and confidence intervals, to quantify the significance of the post-2022 shift relative to the long-term gradual increase. revision: yes
Circularity Check
No significant circularity; trends are direct corpus measurements
full rationale
The paper reports observational trends in lexical complexity and marker-word frequencies computed directly from extracted text of published cybersecurity papers (2000-2025). No equations, fitted parameters, or derivations are described that reduce the post-2022 increase or long-run drift to inputs defined by the authors themselves. Marker words are curated from prior external studies rather than fitted to this corpus, and the analysis contains no self-citation load-bearing steps or ansatz smuggling. The central findings are therefore self-contained empirical observations without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Marker word list
axioms (1)
- domain assumption PDF text extraction accurately recovers the original author prose without layout-induced artifacts
Reference graph
Works this paper leans on
-
[1]
ACM CCS History,
ACM SIGSAC, “ACM CCS History,” 2025. [Online]. Available: https://www.sigsac.org/ccs/ccs-history.html
2025
-
[2]
T. Bao, Y . Zhao, J. Mao, and C. Zhang, “Examining linguistic shifts in academic writing before and after the launch of ChatGPT: a study on preprint papers,”Scientometrics, 2025. [Online]. Available: https://link.springer.com/article/10.1007/s11192-025-05341-y
-
[3]
Artifact Evaluation: Is It a Real Incentive?
B. R. Childers and P. K. Chrysanthis, “Artifact Evaluation: Is It a Real Incentive?” in2017 IEEE 13th International Conference on e-Science (e-Science), Oct. 2017, pp. 488–489. [Online]. Available: https://ieeexplore.ieee.org/document/8109184/
-
[4]
Simplification of flesch reading ease formula
J. N. Farr, J. J. Jenkins, and D. G. Paterson, “Simplification of flesch reading ease formula.”Journal of applied psychology, vol. 35, no. 5, p. 333, 1951
1951
-
[5]
Is ChatGPT transforming academics’ writing style?
M. Geng and R. Trotta, “Is ChatGPT transforming academics’ writing style?”arXiv, 2024. [Online]. Available: https://arxiv.org/abs/2404. 08627
2024
-
[6]
IEEE Symposium on Security and Privacy,
IEEE, “IEEE Symposium on Security and Privacy,” 2025. [Online]. Available: https://sp2026.ieee-security.org/past.html
2025
-
[7]
Previous NDSS Symposia,
Internet Society, “Previous NDSS Symposia,” 2025. [Online]. Available: https://www.ndss-symposium.org/previous-ndss-symposia/
2025
-
[8]
How Transparent is Usable Privacy and Security Research? A Meta- Study on Current Research Transparency Practices,
J. H. Klemmer, J. Schm ¨user, F. Fischer, J. Suray, J.-U. Holtgrave, S. Lenau, B. M. Lowens, F. Schaub, and S. Fahl, “How Transparent is Usable Privacy and Security Research? A Meta- Study on Current Research Transparency Practices,” 2025, pp. 5967–5986. [Online]. Available: https://www.usenix.org/conference/ usenixsecurity25/presentation/klemmer
2025
-
[9]
Giorgio Franceschelli and Mirco Musolesi
D. Kobak, R. Gonz ´alez-M´arquez, E.- ´A. Horv ´at, and J. Lause, “Delving into LLM-assisted writing in biomedical publications through excess vocabulary,”Science Advances, 2025. [Online]. Available: https://www.science.org/doi/10.1126/sciadv.adt3813
-
[10]
Quantifying the Carbon Emissions of Machine Learning
A. Lacoste, A. Luccioni, V . Schmidt, and T. Dandres, “Quanti- fying the carbon emissions of machine learning,”arXiv preprint arXiv:1910.09700, 2019
work page internal anchor Pith review arXiv 1910
-
[11]
Quantifying large language model usage in scientific papers,
W. Liang, Y . Zhang, Z. Wu, H. Lepp, W. Ji, X. Zhao, H. Cao, S. Liu, S. He, Z. Huang, D. Yang, C. Potts, C. D. Manning, and J. Zou, “Quantifying large language model usage in scientific papers,”Nature Human Behaviour, 2025. [Online]. Available: https://www.nature.com/articles/s41562-025-02273-8
2025
-
[12]
”Get in Researchers; We’re Measuring Reproducibility
D. Olszewski, A. Lu, C. Stillman, K. Warren, C. Kitroser, A. Pascual, D. Ukirde, K. Butler, and P. Traynor, “”Get in Researchers; We’re Measuring Reproducibility”: A Reproducibility Study of Machine Learning Papers in Tier 1 Security Conferences,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. Copenhagen Denmark: ...
-
[13]
USENIX Security Symposia,
USENIX, “USENIX Security Symposia,” 2025. [Online]. Available: https://www.usenix.org/conferences/byname/108
2025
-
[14]
Seqxgpt: Sentence-level AI-generated text detection,
P. Wang, L. Li, K. Ren, B. Jiang, D. Zhang, and X. Qiu, “Seqxgpt: Sentence-level AI-generated text detection,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 1144–1156. [Online]. Available: https://aclanthology.org/2023.emnlp-main.73/
2023
-
[15]
Timperley, Ben Hermann, Jürgen Cito, Jonathan Bell, Michael Hilton, and Dirk Beyer
S. Winter, C. S. Timperley, B. Hermann, J. Cito, J. Bell, M. Hilton, and D. Beyer, “A retrospective study of one decade of artifact evaluations,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the F oundations of Software Engineering, ser. ESEC/FSE 2022. New York, NY , USA: Association for Computing Machinery...
-
[16]
Faculty views on the importance of writing, the nature of academic writing, and teaching and responding to writing in the disciplines,
W. Zhu, “Faculty views on the importance of writing, the nature of academic writing, and teaching and responding to writing in the disciplines,”Journal of Second Language Writing, vol. 13, no. 1, pp. 29–48, 2004, conceptualizing Discourse/Responding to Text. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S1060374304000074 Appendix...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.