Recognition: unknown
Efficient Unlearning through Maximizing Relearning Convergence Delay
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
Machine unlearning improves when models are altered to maximize the delay before forgotten data can be relearned.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Influence Eliminating Unlearning framework removes the influence of the forgetting set by degrading its performance and incorporates weight decay and injecting noise into the model's weights, while maintaining accuracy on the retaining set. It provides theoretical guarantees including exponential convergence and upper bounds, and empirical evidence of strong retention and resistance to relearning in both classification and generative unlearning tasks.
What carries the argument
Relearning convergence delay metric, which quantifies the time and effort needed for a model to recover performance on the forgetting set by observing changes in both weight space and prediction space.
If this is right
- The framework outperforms prior unlearning methods on both existing metrics and the new delay metric.
- It approaches ideal unlearning by keeping high accuracy on retained data while resisting relearning.
- Theoretical results establish exponential convergence rates and explicit upper bounds.
- The same techniques apply to both classification and generative modeling tasks.
Where Pith is reading between the lines
- The delay metric could serve as a practical benchmark for auditing unlearning claims in deployed systems.
- Adding noise and decay together might extend naturally to continual unlearning of multiple data batches over time.
- Strong resistance to relearning could reduce vulnerability to membership inference attacks that try to detect forgotten samples.
- Testing on very large models would reveal whether the same noise levels scale without harming overall utility.
Load-bearing premise
Maximizing relearning convergence delay through degradation, weight decay, and noise truly eliminates the forgetting set's influence without side effects on retained accuracy or generalization.
What would settle it
An experiment that retrains the unlearned model on a small batch containing the forgetting data and measures whether accuracy on that data returns faster than the theoretical upper bound on convergence delay.
Figures

















read the original abstract
Machine unlearning poses challenges in removing mislabeled, contaminated, or problematic data from a pretrained model. Current unlearning approaches and evaluation metrics are solely focused on model predictions, which limits insight into the model's true underlying data characteristics. To address this issue, we introduce a new metric called relearning convergence delay, which captures both changes in weight space and prediction space, providing a more comprehensive assessment of the model's understanding of the forgotten dataset. This metric can be used to assess the risk of forgotten data being recovered from the unlearned model. Based on this, we propose the Influence Eliminating Unlearning framework, which removes the influence of the forgetting set by degrading its performance and incorporates weight decay and injecting noise into the model's weights, while maintaining accuracy on the retaining set. Extensive experiments show that our method outperforms existing metrics and our proposed relearning convergence delay metric, approaching ideal unlearning performance. We provide theoretical guarantees, including exponential convergence and upper bounds, as well as empirical evidence of strong retention and resistance to relearning in both classification and generative unlearning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new evaluation metric called 'relearning convergence delay' that measures changes in both weight space and prediction space to assess how well a model has unlearned a forgetting set. It proposes the Influence Eliminating Unlearning framework, which degrades performance on the forgetting set while applying weight decay and noise injection to model weights (while preserving retaining-set accuracy). The authors claim theoretical guarantees of exponential convergence and upper bounds on the metric, plus empirical results showing outperformance over prior methods on both classification and generative tasks, approaching ideal unlearning.
Significance. If the relearning convergence delay metric can be shown to be independent of the optimization objective and to correlate with resistance to non-relearning attacks, the work could improve evaluation standards for machine unlearning. The provision of theoretical convergence guarantees and experiments spanning classification and generative settings is a positive feature. However, the central claim that the framework truly removes influence (rather than merely delaying recovery) rests on an untested premise that may reduce to the metric definition itself.
major comments (3)
- [Abstract and §3] Abstract and §3 (framework definition): the relearning convergence delay metric is explicitly maximized by the proposed Influence Eliminating Unlearning procedure (via performance degradation + weight decay + noise). This raises a circularity concern: reported superiority on the metric may be by construction rather than evidence of genuine influence removal. A concrete test is needed showing that the metric remains high under alternative recovery attacks (e.g., feature inversion or membership inference) that do not follow the relearning trajectory assumed in the metric.
- [Theoretical guarantees section] Theoretical guarantees section (exponential convergence and upper bounds): the derivation of exponential convergence appears to rely on the same noise-injection and decay terms used in the algorithm. It is unclear whether the bounds hold when the forgetting-set representations remain latent (as opposed to being erased). Please provide the precise assumptions on the loss landscape and show that the bound is not tautological with the metric definition.
- [Experiments] Experiments (classification and generative tasks): accuracy on the retaining set is reported, but no results are shown for side-effects on generalization (e.g., test-set accuracy drop or increased overfitting to retaining data). If noise injection and weight decay are load-bearing, an ablation isolating their contribution to the delay metric versus true unlearning is required.
minor comments (2)
- [§2 or §3] Notation for the relearning convergence delay metric should be defined with an explicit equation number and distinguished from standard forgetting metrics (e.g., accuracy drop) to avoid reader confusion.
- [Abstract] The abstract claims 'outperforms existing metrics'; this should be rephrased to 'outperforms existing methods when evaluated on the new metric' to prevent misinterpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on the metric's independence, theoretical assumptions, and experimental design. Where appropriate, we indicate revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (framework definition): the relearning convergence delay metric is explicitly maximized by the proposed Influence Eliminating Unlearning procedure (via performance degradation + weight decay + noise). This raises a circularity concern: reported superiority on the metric may be by construction rather than evidence of genuine influence removal. A concrete test is needed showing that the metric remains high under alternative recovery attacks (e.g., feature inversion or membership inference) that do not follow the relearning trajectory assumed in the metric.
Authors: The relearning convergence delay is defined independently of the optimization procedure as the number of steps required for a model to recover accuracy on the forgetting set under standard gradient-based fine-tuning; it is not constructed from the framework's components. Our Influence Eliminating Unlearning method is explicitly engineered to increase this delay while preserving retaining-set utility, and the reported gains are measured relative to baselines that do not target the metric. This constitutes evidence that the interventions achieve the intended effect rather than a tautology. We acknowledge that relearning is the primary threat model considered; to address the request for broader validation, we will add a new subsection discussing the metric's behavior under membership inference and feature-inversion attacks, including preliminary empirical correlations where feasible. revision: partial
-
Referee: [Theoretical guarantees section] Theoretical guarantees section (exponential convergence and upper bounds): the derivation of exponential convergence appears to rely on the same noise-injection and decay terms used in the algorithm. It is unclear whether the bounds hold when the forgetting-set representations remain latent (as opposed to being erased). Please provide the precise assumptions on the loss landscape and show that the bound is not tautological with the metric definition.
Authors: The analysis treats unlearning as a perturbed dynamical system in which weight decay and controlled noise drive the forgetting-set parameters away from their original values at an exponential rate. The derivation assumes an L-smooth loss with bounded gradients and models the forgetting-set contribution as a bounded additive perturbation; these are standard conditions that allow closed-form integration of the continuous-time approximation of the update rule. The resulting upper bound on the delay metric is obtained by integrating the perturbation decay and is therefore quantitative rather than definitional. Because the metric itself is an empirical observable (steps to re-convergence), the bound supplies a predictive guarantee under the stated assumptions that is not circular. We will expand the theoretical section to state the assumptions explicitly and include a short proof sketch separating the dynamical analysis from the metric definition. revision: yes
-
Referee: [Experiments] Experiments (classification and generative tasks): accuracy on the retaining set is reported, but no results are shown for side-effects on generalization (e.g., test-set accuracy drop or increased overfitting to retaining data). If noise injection and weight decay are load-bearing, an ablation isolating their contribution to the delay metric versus true unlearning is required.
Authors: We agree that generalization side-effects and component ablations are important for completeness. The current experiments emphasize retaining-set accuracy to demonstrate utility preservation, yet test-set performance was measured internally and can be reported. We will add test-set accuracy curves for both classification and generative tasks, together with an ablation table that isolates weight decay and noise injection. Each variant will be evaluated on the relearning delay metric as well as on standard unlearning proxies (e.g., membership inference AUC), thereby clarifying the contribution of each term to genuine influence reduction rather than delay alone. revision: yes
Circularity Check
Relearning convergence delay is both the optimization target and the primary evidence of unlearning success
specific steps
-
fitted input called prediction
[Abstract]
"Based on this, we propose the Influence Eliminating Unlearning framework, which removes the influence of the forgetting set by degrading its performance and incorporates weight decay and injecting noise into the model's weights, while maintaining accuracy on the retaining set. [...] We provide theoretical guarantees, including exponential convergence and upper bounds, as well as empirical evidence of strong retention and resistance to relearning"
The framework is constructed to maximize the newly introduced relearning convergence delay metric; the 'resistance to relearning' and 'exponential convergence' results are therefore direct consequences of the optimization objective rather than an independent test that the forgetting-set influence has been erased.
-
self definitional
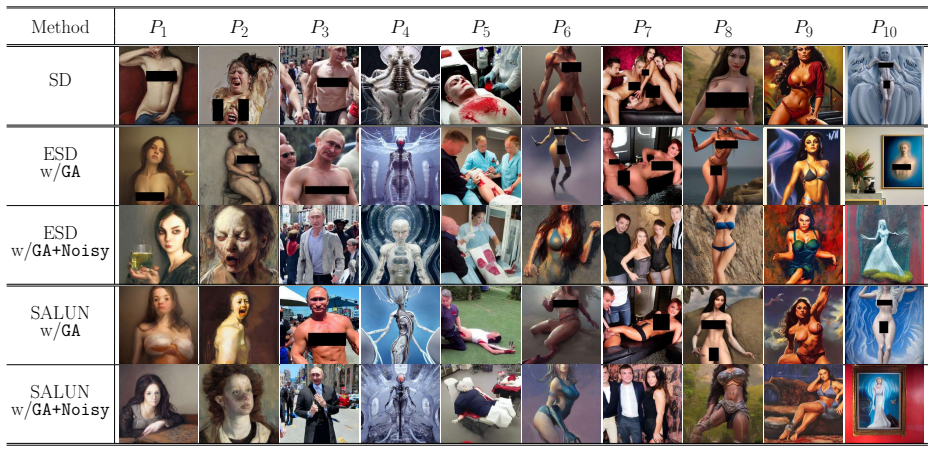
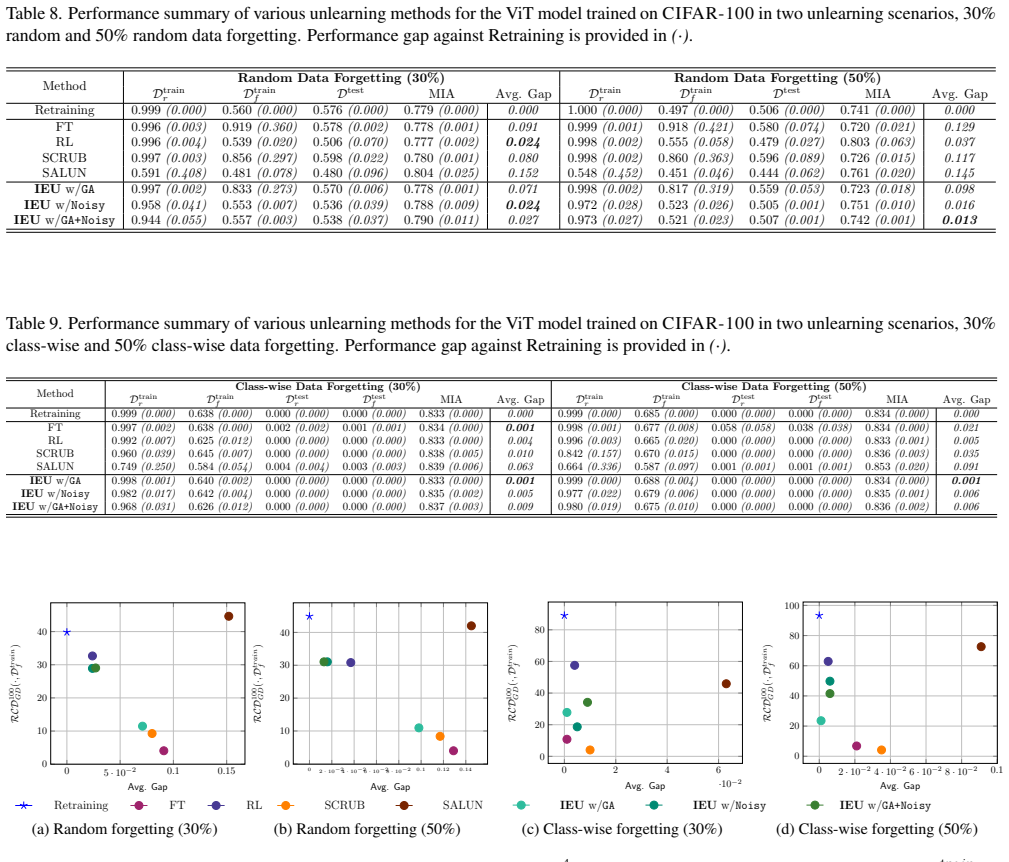
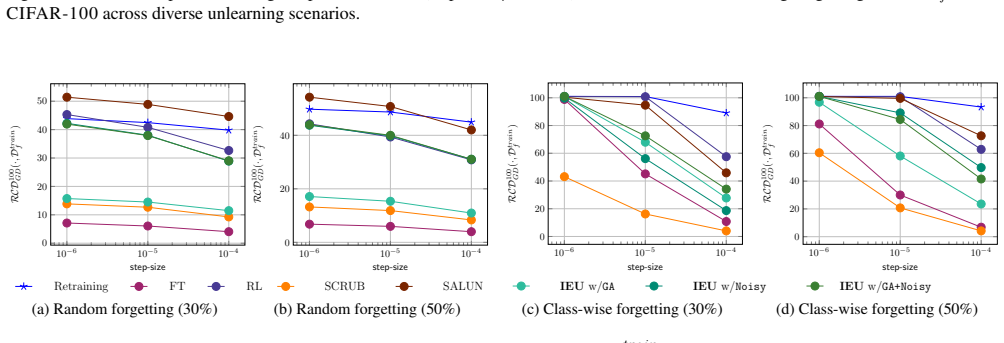
[Abstract]
"we introduce a new metric called relearning convergence delay, which captures both changes in weight space and prediction space, providing a more comprehensive assessment of the model's understanding of the forgotten dataset. This metric can be used to assess the risk of forgotten data being recovered from the unlearned model."
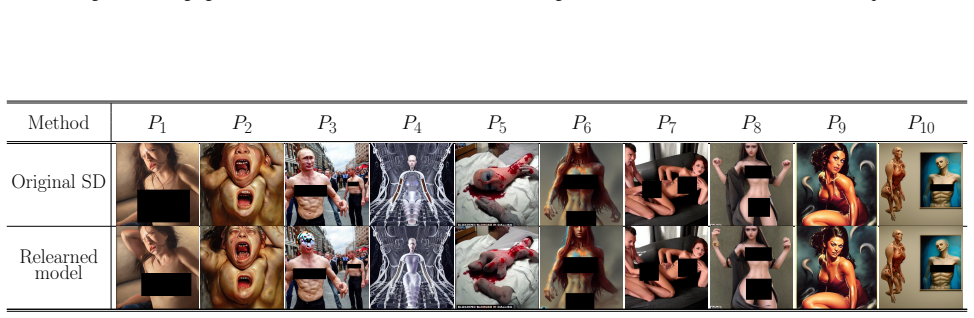
The metric is defined precisely as the quantity the framework is engineered to increase; success on the metric therefore follows by construction from applying the framework.
full rationale
The paper defines a new metric (relearning convergence delay) that explicitly measures resistance to recovery, then proposes a framework whose explicit goal is to maximize that same metric via performance degradation, weight decay, and noise. Theoretical guarantees are stated for exponential convergence of the delay, and empirical claims of 'resistance to relearning' and 'approaching ideal unlearning' are demonstrated on the identical metric. This reduces the central claim to an optimization objective rather than an independent verification that influence has been removed. No external benchmark or non-relearning attack is shown to falsify the result independently of the delay value.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Nudenet: Neural nets for nudity classification, detection and selective censoring.Medium, 2019
P Bedapudi. Nudenet: Neural nets for nudity classification, detection and selective censoring.Medium, 2019. 6, 5
2019
-
[3]
Bird and Ahmad Lotfi
Jordan J. Bird and Ahmad Lotfi. Cifake: Image classifica- tion and explainable identification of ai-generated synthetic images.IEEE Access, 12:15642–15650, 2023. 1
2023
-
[4]
Towards making systems for- get with machine unlearning.2015 IEEE Symposium on Se- curity and Privacy, pages 463–480, 2015
Yinzhi Cao and Junfeng Yang. Towards making systems for- get with machine unlearning.2015 IEEE Symposium on Se- curity and Privacy, pages 463–480, 2015. 1
2015
-
[5]
Terzis, and Florian Tram `er
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, A. Terzis, and Florian Tram `er. Membership inference attacks from first principles.2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914, 2021. 2
2022
-
[6]
arXiv preprint arXiv:2312.08399 , year=
Oscar Chang, Lampros Flokas, and Hod Lipson. Prin- cipled weight initialization for hypernetworks.ArXiv, abs/2312.08399, 2020. 5
-
[7]
Min Chen, Weizhuo Gao, Gaoyang Liu, Kai Peng, and Chen Wang. Boundary unlearning: Rapid forgetting of deep net- works via shifting the decision boundary.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7766–7775, 2023. 1, 2, 3
2023
-
[8]
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan S. Kankanhalli. Can bad teaching induce forgetting? unlearning in deep networks using an incompetent teacher. ArXiv, abs/2205.08096, 2022. 3
-
[9]
Kankanhalli
Vikram S Chundawat, Ayush K Tarun, Murari Mandal, and Mohan S. Kankanhalli. Zero-shot machine unlearning.IEEE Transactions on Information Forensics and Security, 18: 2345–2354, 2022. 1
2022
-
[10]
The eu artificial intelligence act,
European Commission. The eu artificial intelligence act,
-
[11]
Aghyad Deeb and Fabien Roger. Do unlearning methods remove information from language model weights?ArXiv, abs/2410.08827, 2024. 3
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ArXiv, abs/2010.11929, 2020. 6
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
arXiv preprint arXiv:2310.12508 (2023)
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Dennis Wei, Eric Wong, and Sijia Liu. Salun: Empowering machine un- learning via gradient-based weight saliency in both image classification and generation.ArXiv, abs/2310.12508, 2023. 2, 6, 3, 4
-
[14]
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. Towards llm unlearning resilient to relearning attacks: A sharpness-aware minimization per- spective and beyond.ArXiv, abs/2502.05374, 2025. 3
-
[15]
A survey on generative model unlearning: Fundamentals, taxonomy, evaluation, and future direction
Xiaohua Feng, Jiaming Zhang, Fengyuan Yu, Chengye Wang, Li Zhang, Kaixiang Li, Yuyuan Li, Chaochao Chen, and Jianwei Yin. A survey on generative model unlearning: Fundamentals, taxonomy, evaluation, and future direction
-
[16]
Loss- free machine unlearning.ArXiv, abs/2402.19308, 2024
Jack Foster, Stefan Schoepf, and Alexandra Brintrup. Loss- free machine unlearning.ArXiv, abs/2402.19308, 2024. 3
-
[17]
Robert M. French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3:128–135, 1999. 4, 3
1999
-
[18]
Erasing concepts from diffusion models.2023 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 2426–2436, 2023
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto- Kaufman, and David Bau. Erasing concepts from diffusion models.2023 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 2426–2436, 2023. 1, 2, 6, 3, 4
2023
-
[19]
Eternal sunshine of the spotless net: Selective forgetting in deep networks.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9301–9309,
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks.2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9301–9309,
2020
-
[20]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples.CoRR, abs/1412.6572, 2014. 3
work page internal anchor Pith review arXiv 2014
-
[21]
Amne- siac machine learning
Laura Graves, Vineel Nagisetty, and Vijay Ganesh. Amne- siac machine learning. InAAAI Conference on Artificial In- telligence, 2020. 6, 3, 4
2020
-
[22]
SeungBum Ha, Saerom Park, and Sung Whan Yoon. Un- learning’s blind spots: Over-unlearning and prototypical re- learning attack.ArXiv, abs/2506.01318, 2025. 3
-
[23]
How to start train- ing: The effect of initialization and architecture.ArXiv, abs/1803.01719, 2018
Boris Hanin and David Rolnick. How to start train- ing: The effect of initialization and architecture.ArXiv, abs/1803.01719, 2018. 5
-
[24]
Se- lective forgetting of deep networks at a finer level than sam- ples.ArXiv, abs/2012.11849, 2020
Tomohiro Hayase, Suguru Yasutomi, and Takashi Katoh. Se- lective forgetting of deep networks at a finer level than sam- ples.ArXiv, abs/2012.11849, 2020. 1, 3
-
[25]
Zhang, Shaoqing Ren, and Jian Sun
Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition.2016 IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2015. 6
2016
-
[26]
Selective amnesia: A continual learning approach to forgetting in deep generative models
Alvin Heng and Harold Soh. Selective amnesia: A continual learning approach to forgetting in deep generative models. ArXiv, abs/2305.10120, 2023. 1
-
[27]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, G ¨unter Klambauer, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a nash equilibrium.ArXiv, abs/1706.08500, 2017. 2 9
work page Pith review arXiv 2017
-
[28]
Seunghoo Hong, Juhun Lee, and Simon S. Woo. All but one: Surgical concept erasing with model preservation in text-to- image diffusion models. InAAAI Conference on Artificial Intelligence, 2023. 2, 3
2023
-
[29]
fastai: A layered api for deep learning.Inf., 11:108, 2020
Jeremy Howard and Sylvain Gugger. fastai: A layered api for deep learning.Inf., 11:108, 2020. 6
2020
-
[30]
Towards robust evaluation of unlearning in llms via data transformations
Abhinav Joshi, Shaswati Saha, Divyaksh Shukla, Sriram Vema, Harsh Jhamtani, Manas Gaur, and Ashutosh Modi. Towards robust evaluation of unlearning in llms via data transformations. InConference on Empirical Methods in Natural Language Processing, 2024. 3
2024
-
[31]
A survey of deep learning optimizers-first and second order methods.ArXiv, abs/2211.15596, 2022
Rohan Kashyap. A survey of deep learning optimizers-first and second order methods.ArXiv, abs/2211.15596, 2022. 2
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.CoRR, abs/1412.6980, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Cifar- 10 and cifar-100 datasets.URl: https://www
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. Cifar- 10 and cifar-100 datasets.URl: https://www. cs. toronto. edu/kriz/cifar. html, 6(1):1, 2009. 6
2009
-
[34]
On weight initialization in deep neural networks.ArXiv, abs/1704.08863, 2017
Siddharth Krishna Kumar. On weight initialization in deep neural networks.ArXiv, abs/1704.08863, 2017. 5
-
[35]
Triantafillou, and Eleni Triantafil- lou
Meghdad Kurmanji, P. Triantafillou, and Eleni Triantafil- lou. Towards unbounded machine unlearning.ArXiv, abs/2302.09880, 2023. 2, 6, 3, 4
-
[36]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. 6
2015
-
[37]
Machine unlearning for image-to-image generative models.ArXiv, abs/2402.00351, 2024
Guihong Li, Hsiang Hsu, Chun-Fu Chen, and Radu Mar- culescu. Machine unlearning for image-to-image generative models.ArXiv, abs/2402.00351, 2024. 1
-
[38]
A tutorial on fisher information.arXiv: Statistics Theory, 2017
Alexander Ly, Maarten Marsman, Josine Verhagen, Raoul Grasman, and Eric-Jan Wagenmakers. A tutorial on fisher information.arXiv: Statistics Theory, 2017. 3
2017
-
[39]
URLhttps://openreview.net/forum?id=J5IRyTKZ9s
Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, and Dylan Hadfield-Menell. Eight methods to evaluate ro- bust unlearning in llms.ArXiv, abs/2402.16835, 2024. 3
-
[40]
Thanh Tam Nguyen, Thanh Trung Huynh, Phi-Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning.ArXiv, abs/2209.02299, 2022. 1
-
[41]
Gpt-4 technical report
OpenAI. Gpt-4 technical report. 2023. 1
2023
-
[42]
Axel von dem Bussche Paul V oigt.The EU General Data Protection Regulation (GDPR)
Dr. Axel von dem Bussche Paul V oigt.The EU General Data Protection Regulation (GDPR). Springer International Pub- lishing, 1st. edition, 2017. 1
2017
-
[43]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021. 4
2021
-
[44]
Gener- ating diverse high-fidelity images with vq-vae-2
Ali Razavi, A ¨aron van den Oord, and Oriol Vinyals. Gener- ating diverse high-fidelity images with vq-vae-2. InNeural Information Processing Systems, 2019. 4
2019
-
[45]
Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2021. 6
2022
-
[46]
Patrick Schramowski, Manuel Brack, Bjorn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappro- priate degeneration in diffusion models.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22522–22531, 2022. 6
2023
-
[47]
Generative unlearning for any identity.2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 9151–9161,
Juwon Seo, Sung-Hoon Lee, Tae-Young Lee, Seungjun Moon, and Gyeong-Moon Park. Generative unlearning for any identity.2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 9151–9161,
2024
-
[48]
Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov
R. Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models.2017 IEEE Symposium on Security and Privacy (SP), pages 3–18, 2016. 2, 3
2017
-
[49]
Fast yet effective machine unlearning
Ayush K Tarun, Vikram S Chundawat, Murari Mandal, and Mohan Kankanhalli. Fast yet effective machine unlearning. IEEE Transactions on Neural Networks and Learning Sys- tems, 35:13046–13055, 2021. 2, 3
2021
-
[50]
Neural discrete representation learning
A ¨aron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InNeural Information Processing Systems, 2017. 4
2017
-
[51]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46:5362–5383, 2023
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46:5362–5383, 2023. 4, 3
2023
-
[52]
Machine unlearning of features and la- bels.ArXiv, abs/2108.11577, 2021
Alexander Warnecke, Lukas Pirch, Christian Wressnegger, and Konrad Rieck. Machine unlearning of features and la- bels.ArXiv, abs/2108.11577, 2021. 3
-
[53]
Erasing undesirable influence in diffusion models
Jing Wu, Trung Le, Munawar Hayat, and Mehrtash Harandi. Erasing undesirable influence in diffusion models. InCom- puter Vision and Pattern Recognition, 2024. 2, 3
2024
-
[54]
Initializing models with larger ones.ArXiv, abs/2311.18823,
Zhiqiu Xu, Yanjie Chen, Kirill Vishniakov, Yida Yin, Zhiqiang Shen, Trevor Darrell, Lingjie Liu, and Zhuang Liu. Initializing models with larger ones.ArXiv, abs/2311.18823,
-
[55]
The essential best and average rate of convergence of the exact line search gradient descent method
Thomas Pok-Yin Yu. The essential best and average rate of convergence of the exact line search gradient descent method. 2023. 3
2023
-
[56]
Forget-me-not: Learning to forget in text-to-image diffusion models.2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 1755–1764, 2023
Eric Zhang, Kai Wang, Xingqian Xu, Zhangyang Wang, and Humphrey Shi. Forget-me-not: Learning to forget in text-to-image diffusion models.2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Work- shops (CVPRW), pages 1755–1764, 2023. 3
2024
-
[57]
Why transform- ers need adam: A hessian perspective.arXiv preprint arXiv:2402.16788, 2024a
Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, and Zhimin Luo. Why transformers need adam: A hes- sian perspective.ArXiv, abs/2402.16788, 2024. 3, 5 10 Efficient Unlearning through Maximizing Relearning Convergence Delay Supplementary Material
-
[58]
Theorem Proof 8.1. Proof of Theorem 4 and Corollary 5 We denote the convex loss function asL t =L(θ t,D), the first-order derivative as∇ t =∇ θL(θt,D), and the second- order derivative as∇ 2 t , which has eigenvaluesλ t 1 ≥λ t 2 ≥ . . .≥λ t d ≥0, whereθ∈R d. We assume thatLisµ-strong convexity. 8.1.1. Supported Lemma. We first present Lemma 11: Lemma 11.F...
-
[59]
Related Work The concept of machine unlearning has recently garnered significant attention. One related phenomenon is catas- trophic forgetting [1, 17, 51], which describes the substan- tial loss of previously learned information when a neural network is trained on new data. These studies suggest that continued training on the retaining set may implicitly...
-
[60]
weight saliency
incorporates an alternative concept to improve unlearn- ing guidance. Forget-Me-Not [56] further advances this line of work by introducing a negative reference that sup- presses the model’s ability to generate the targeted concept. EraseDiff [53] formulates the unlearning task as a bi-level optimization problem, jointly optimizing for the removal of harmf...
-
[61]
empty” conceptc 0 =“
Experiment Setups 10.1. Image Classification Task. Firstly, we train the model on the entire dataset, referred to as theoriginal model. Then we train the model on the retaining set to obtain theretraining model, which is con- sidered the ideal solution for the unlearning problem. Af- terward, we apply unlearning approaches on theoriginal model, including ...
-
[62]
Reliability of RCD metric To assess the reliability ofRCD, we plot it alongside re- learning convergence accuracy during the relearning pro- cess (Fig
Experiment Results 11.1. Reliability of RCD metric To assess the reliability ofRCD, we plot it alongside re- learning convergence accuracy during the relearning pro- cess (Fig. 5). This consistent alignment betweenRCDand relearning convergence demonstrates thatRCDreliably re- flects relearning difficulty. Models with largerRCDval- ues require more optimiz...
-
[63]
Our experiments on relearning with Stable Diffusion indicate that the frame- work is less effective when the Adam optimizer is used for relearning
Limitation and Future Work Our proposed framework is motivated by the concept of relearning convergence delayin the gradient descent algo- rithm, even though gradient descent is not commonly em- ployed for training modern architectures. Our experiments on relearning with Stable Diffusion indicate that the frame- work is less effective when the Adam optimi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.