Recognition: unknown
Do AI Coding Agents Log Like Humans? An Empirical Study
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
The pith
AI coding agents modify logging statements less frequently than humans and often disregard explicit logging instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
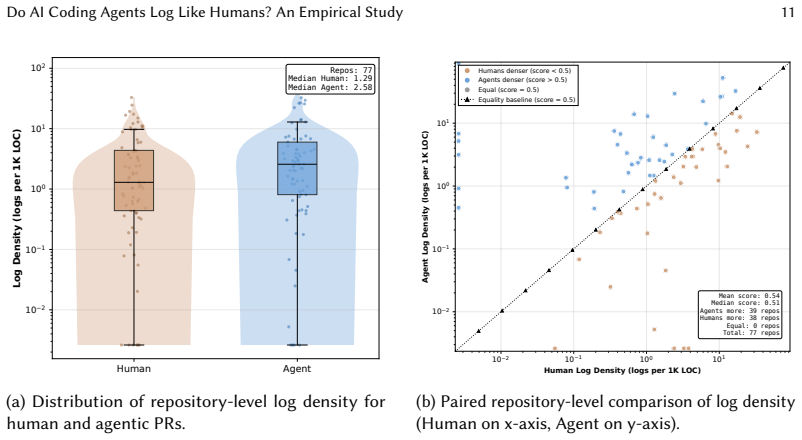
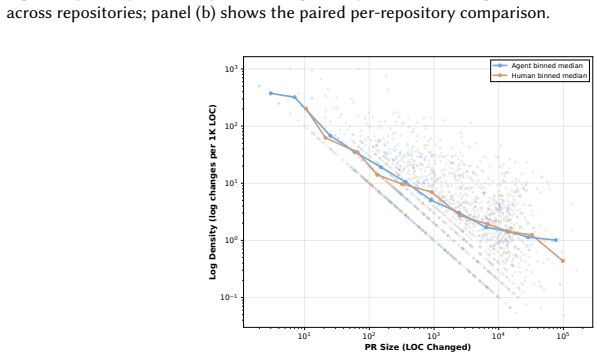
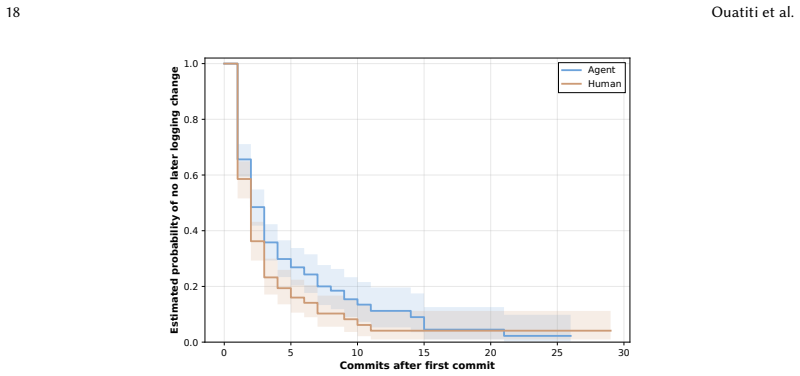
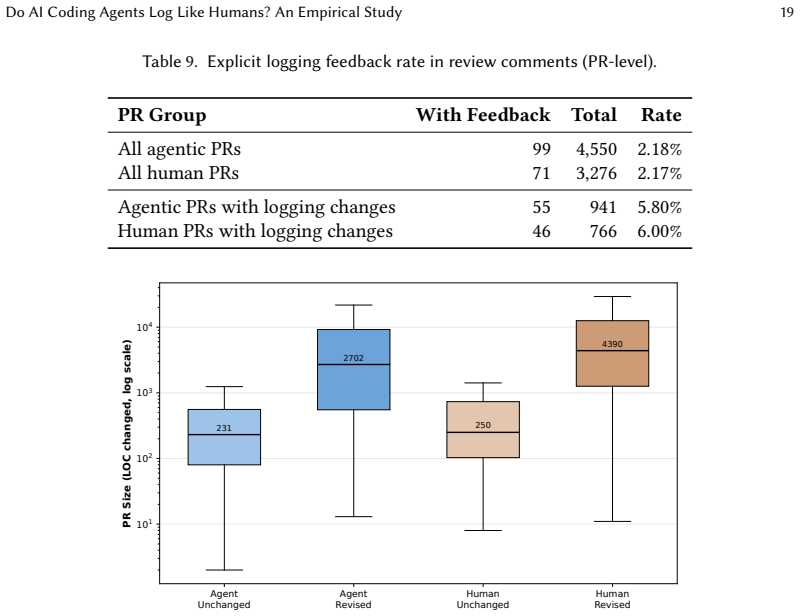
Across 4,550 agentic pull requests in 81 repositories, agents change logging less often than humans in 58.4 percent of cases, though they produce higher log density when changes occur. Explicit logging instructions appear in only 4.7 percent of cases and agents fail to follow constructive requests 67 percent of the time. Humans perform 72.5 percent of post-generation log repairs, functioning as silent janitors who address observability problems without explicit review signals. These patterns point to a dual shortfall in natural language guidance: scarcity of instructions and low agent compliance.
What carries the argument
The side-by-side comparison of logging modifications in agentic pull requests versus human baselines, combined with detection of explicit natural-language instructions and measurement of compliance and repair rates.
If this is right
- Natural language instructions alone do not reliably govern non-functional requirements such as logging.
- Agents produce code that may require subsequent human fixes to maintain observability.
- Consistent logging practices could depend on mechanisms other than prompts.
- Human review continues to play a central role in correcting AI-generated logging issues.
Where Pith is reading between the lines
- AI coding tools might benefit from built-in defaults or templates for logging instead of relying solely on user prompts.
- Similar patterns could appear in other non-functional areas such as error handling or performance instrumentation.
- Controlled experiments could test whether adding deterministic checks improves logging outcomes beyond what natural language achieves.
Load-bearing premise
The 4,550 pull requests can be accurately labeled as AI-generated and logging changes can be detected and classified without systematic bias from repository selection or detection methods.
What would settle it
A follow-up analysis that uses an independent method to identify AI-generated code and finds agents changing logging more often than humans across a comparable set of repositories.
Figures








read the original abstract
Software logging is essential for maintaining and debugging complex systems, yet it remains unclear how AI coding agents handle this non-functional requirement. While prior work characterizes human logging practices, the behaviors of AI coding agents and the efficacy of natural language instructions in governing them are unexplored. To address this gap, we conduct an empirical study of 4,550 agentic pull requests across 81 open-source repositories. We compare agent logging patterns against human baselines and analyze the impact of explicit logging instructions. We find that agents change logging less often than humans in 58.4% of repositories, though they exhibit higher log density when they do. Furthermore, explicit logging instructions are rare (4.7%) and ineffective, as agents fail to comply with constructive requests 67% of the time. Finally, we observe that humans perform 72.5% of post-generation log repairs, acting as "silent janitors" who fix logging and observability issues without explicit review feedback. These findings indicate a dual failure in natural language instruction (i.e., scarcity of logging instructions and low agent compliance), suggesting that deterministic guardrails might be necessary to ensure consistent logging practices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study of logging behaviors in 4,550 agentic pull requests across 81 open-source repositories. It compares AI coding agents to human baselines, finding that agents alter logging less frequently than humans in 58.4% of repositories (but with higher log density when they do), that explicit logging instructions appear in only 4.7% of cases and are followed only 33% of the time, and that humans perform 72.5% of subsequent log repairs. The authors interpret these results as evidence of a dual failure of natural-language instructions and recommend deterministic guardrails instead.
Significance. If the measurements hold after validation, the work provides concrete data on how current AI agents handle a key non-functional requirement (logging) that prior human-focused studies have characterized. The scale (81 repos, thousands of PRs) and the observation that humans act as post-hoc “silent janitors” are useful for tool builders and for organizations adopting agentic workflows. The practical suggestion for guardrails is directly actionable.
major comments (4)
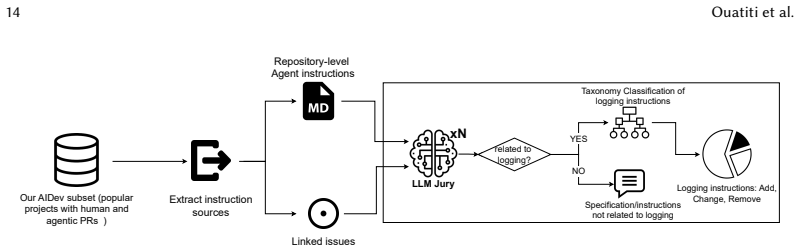
- [§3] §3 (or Methods section on data collection): The identification of the 4,550 agentic PRs is described as relying on repository selection plus detection rules (likely commit/PR metadata or tool signatures), yet no precision, recall, inter-rater agreement, or sensitivity analysis is reported. Because every comparative statistic (58.4%, 67%, 72.5%) depends on correct partitioning of PRs into agentic vs. human, the absence of validation metrics makes the central claims unverifiable from the given evidence.
- [§3.2] §3.2 (logging-change detection): The rules used to extract and classify logging edits from diffs (keyword, AST, or other patterns) are not accompanied by accuracy figures or manual audit results. Systematic under-detection of conditional, refactored, or framework-specific logging statements would directly bias the reported frequencies and the inference of non-compliance.
- [§4] §4 (results on instruction compliance): The claim that agents “fail to comply with constructive requests 67% of the time” rests on an operational definition of “explicit logging instructions” and “constructive requests” that is not detailed; without inter-annotator reliability or a clear coding scheme, the 67% figure cannot be assessed for reproducibility or selection bias.
- [§4, §5] §4 and §5: No statistical tests, confidence intervals, or controls for confounders (repository language, size, agent tool, PR age) are mentioned for the key percentages. The 58.4% “less often” claim and the 72.5% human-repair claim therefore lack evidence that the observed differences are not artifacts of the sampled repositories or detection heuristics.
minor comments (2)
- [Introduction] The abstract and introduction cite prior human logging studies but do not explicitly contrast the current detection heuristics with those used in the cited works; a short methods-comparison paragraph would improve context.
- [Results] Table or figure captions that report the 58.4%, 67%, and 72.5% figures should also state the exact denominators and any filtering steps applied.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments help us improve the transparency and rigor of our empirical analysis. We respond to each major comment below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (or Methods section on data collection): The identification of the 4,550 agentic PRs is described as relying on repository selection plus detection rules (likely commit/PR metadata or tool signatures), yet no precision, recall, inter-rater agreement, or sensitivity analysis is reported. Because every comparative statistic (58.4%, 67%, 72.5%) depends on correct partitioning of PRs into agentic vs. human, the absence of validation metrics makes the central claims unverifiable from the given evidence.
Authors: We agree that validation metrics are important for establishing the reliability of our agentic PR identification. The method in §3 used a combination of automated detection based on known AI coding agent signatures in commit messages, PR titles, and author metadata, cross-referenced with repository selection criteria. While we did not report precision and recall in the initial submission, we will add a sensitivity analysis and manual validation results on a sample of PRs in the revised manuscript to quantify the accuracy of this partitioning. revision: yes
-
Referee: [§3.2] §3.2 (logging-change detection): The rules used to extract and classify logging edits from diffs (keyword, AST, or other patterns) are not accompanied by accuracy figures or manual audit results. Systematic under-detection of conditional, refactored, or framework-specific logging statements would directly bias the reported frequencies and the inference of non-compliance.
Authors: We recognize that the logging edit detection rules require validation to rule out systematic biases. Our approach combined keyword searches for common logging APIs with AST-based diff analysis to identify changes. In the revision, we will include results from a manual audit of a random sample of diffs, reporting accuracy metrics and discussing any limitations related to framework-specific or conditional logging statements. revision: yes
-
Referee: [§4] §4 (results on instruction compliance): The claim that agents “fail to comply with constructive requests 67% of the time” rests on an operational definition of “explicit logging instructions” and “constructive requests” that is not detailed; without inter-annotator reliability or a clear coding scheme, the 67% figure cannot be assessed for reproducibility or selection bias.
Authors: The 67% figure is derived from a manual classification of PR comments and descriptions for explicit requests related to logging. We will provide a detailed coding scheme with examples in the revised §4, including the criteria for 'constructive' vs. vague requests. If the original annotation was performed by a single researcher, we will note this limitation and consider adding a second annotator for a subset to compute agreement in the revision. revision: partial
-
Referee: [§4, §5] §4 and §5: No statistical tests, confidence intervals, or controls for confounders (repository language, size, agent tool, PR age) are mentioned for the key percentages. The 58.4% “less often” claim and the 72.5% human-repair claim therefore lack evidence that the observed differences are not artifacts of the sampled repositories or detection heuristics.
Authors: We agree that adding statistical rigor would strengthen the presentation of results. In the revised manuscript, we will include appropriate statistical tests (e.g., proportion tests or chi-squared tests) with confidence intervals for the key percentages. We will also analyze and report on potential confounders such as programming language, repository size, and agent tool type, providing controlled comparisons where feasible. revision: yes
Circularity Check
No circularity: purely observational empirical measurements
full rationale
This is an empirical study that directly measures logging changes in 4,550 identified agentic PRs across 81 repositories, compares frequencies and densities to human baselines, and counts instruction compliance and repair rates. No equations, fitted parameters, derivations, predictions, or ansatzes appear; all reported percentages (58.4%, 4.7%, 67%, 72.5%) are raw observational counts. No self-citation load-bearing steps or uniqueness theorems are invoked. The derivation chain is simply data extraction followed by tabulation, with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption AI coding agents can be reliably identified from pull request metadata or commit patterns in the selected repositories
- domain assumption Changes to logging statements can be accurately and consistently detected across both agent and human contributions
- domain assumption Explicit logging instructions within PR descriptions or comments can be identified and their compliance objectively measured
Reference graph
Works this paper leans on
-
[1]
Mohamed Batoun, Mohammed Sayagh, Roozbeh Aghili, Ali Ouni, and Heng Li. 2024. A literature review and existing challenges on software logging practices.Empirical Software Engineering29 (06 2024). doi:10.1007/s10664-024-10452-w
-
[2]
Yi-Hung Chou, Yiyang Min, April Yi Wang, and James A. Jones. 2025. Learning from Mistakes: Understanding Ad-hoc Logs through Analyzing Accidental Commits . In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE Computer Society, Los Alamitos, CA, USA, 1–13. doi:10.1109/MSR66628.2025.00017
-
[3]
Patrick Loic Foalem, Foutse Khomh, and Heng Li. 2024. Studying logging practice in machine learning-based applica- tions.Information and Software Technology170, C (2024), 17 pages
2024
-
[4]
Qiang Fu, Jieming Zhu, Wenlu Hu, Jian-Guang Lou, Rui Ding, Qingwei Lin, Dongmei Zhang, and Tao Xie. 2014. Where do developers log? an empirical study on logging practices in industry. InCompanion Proceedings of the 36th International Conference on Software Engineering. 24–33
2014
-
[5]
GitHub. 2024. The State of Open Source and AI: The 2024 Octoverse Report. https://github.blog/news-insights/ octoverse/octoverse-2024/. Accessed: 2025-02-09
2024
- [6]
- [7]
-
[8]
Kabinna, W
S. Kabinna, W. Shang, C. Bezemer, and A. E. Hassan. 2016. Examining the Stabity of Logging Statements. InProceedings of the 23rd International Conference on Software Analysis, Evolution, and Reengineering, Vol. 1. 326–337
2016
-
[9]
E. L. Kaplan and Paul Meier. 1958. Nonparametric Estimation from Incomplete Observations.J. Amer. Statist. Assoc. 53, 282 (1958), 457–481. arXiv:https://www.tandfonline.com/doi/pdf/10.1080/01621459.1958.10501452 doi:10.1080/ 01621459.1958.10501452
-
[10]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. 2022. CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning. InAdvances in Neural Information , Vol. 1, No. 1, Article . Publication date: April 2026. Do AI Coding Agents Log Like Humans? An Empirical Study 23 Processing Systems (Neu...
2022
-
[11]
Hao Li, Cor-Paul Bezemer, and Ahmed E. Hassan. 2025. Software Engineering and Foundation Models: Insights from Industry Blogs Using a Jury of Foundation Models . In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE Computer Society, Los Alamitos, CA, USA, 307–318. doi:10.1109/ICSE-SEIP66...
-
[12]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods. arXiv:2412.05579 [cs.CL] https://arxiv.org/abs/2412.05579
work page internal anchor Pith review arXiv 2024
-
[13]
Heng Li, Weiyi Shang, Bram Adams, Mohammed Sayagh, and Ahmed E. Hassan. 2021. A Qualitative Study of the Benefits and Costs of Logging From Developers’ Perspectives .IEEE Transactions on Software Engineering47, 12 (2021), 2858–2873
2021
-
[14]
Heng Li, Weiyi Shang, and Ahmed E. Hassan. 2017. Which log level should developers choose for a new logging statement?Empirical Software Engineering22, 4 (2017), 1684–1716. doi:10.1007/s10664-016-9456-2
- [15]
-
[16]
Zhenhao Li, Heng Li, Tse-Hsun Chen, and Weiyi Shang. 2021. DeepLV: Suggesting Log Levels Using Ordinal Based Neural Networks. In2021 IEEE/ACM 43rd International Conference on Software Engineering. 1461–1472
2021
-
[17]
Licorish, Ansh Bajpai, Chetan Arora, Fanyu Wang, and Chakkrit Tantithamthavorn
Sherlock A. Licorish, Ansh Bajpai, Chetan Arora, Fanyu Wang, and Kla Tantithamthavorn. 2025. Comparing Human and LLM Generated Code: The Jury is Still Out! arXiv:2501.16857 [cs.SE] https://arxiv.org/abs/2501.16857
-
[18]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics12 (2024), 157–173
2024
-
[19]
Antonio Mastropaolo, Luca Pascarella, and Gabriele Bavota. 2022. Using deep learning to generate complete log statements. InProceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2279–2290. doi:10.1145/3510003.3511561
-
[20]
Youssef Esseddiq Ouatiti. 2026. agentic_logging_RP. https://github.com/YoussefEssDS/agentic_logging_RP/tree/main. Replication package, accessed April 1, 2026
2026
-
[21]
Youssef Esseddiq Ouatiti, Mohammed Sayagh, Noureddine Kerzazi, Bram Adams, and Ahmed E. Hassan. 2024. The impact of concept drift and data leakage on log level prediction models.Empirical Software Engineering29, 5 (July 2024), 37 pages. doi:10.1007/s10664-024-10518-9
-
[22]
Youssef Esseddiq Ouatiti, Mohammed Sayagh, Noureddine Kerzazi, and Ahmed E. Hassan. 2023. An Empirical Study on Log Level Prediction for Multi-Component Systems.IEEE Transactions on Software Engineering49, 02 (2023), 473–484
2023
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. 27730–27744
2022
-
[24]
Antonio Pecchia, Marcello Cinque, Gabriella Carrozza, and Domenico Cotroneo. 2015. Industry Practices and Event Logging: Assessment of a Critical Software Development Process. InProceedings of the 37th International Conference on Software Engineering. 169–178
2015
- [25]
-
[26]
Guoping Rong, Shenghui Gu, Haifeng Shen, He Zhang, and Hongyu Kuang. 2023. How Do Developers’ Profiles and Experiences Influence their Logging Practices? An Empirical Study of Industrial Practitioners. In2023 IEEE/ACM 45th International Conference on Software Engineering. 855–867
2023
-
[27]
Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. 2023. Lost at C: a user study on the security implications of large language model code assistants. InProceedings of the 32nd USENIX Conference on Security Symposium(Anaheim, CA, USA)(SEC ’23). USENIX Association, USA, Article 124, 18 pages
2023
-
[28]
Weiyi Shang, Meiyappan Nagappan, and Ahmed E. Hassan. 2015. Studying the Relationship between Logging Characteristics and the Code Quality of Platform Software. (2015), 1–27
2015
-
[29]
Rosalia Tufano, Antonio Mastropaolo, Federica Pepe, Ozren Dabic, Massimiliano Di Penta, and Gabriele Bavota. 2024. Unveiling ChatGPT’s Usage in Open Source Projects: A Mining-based Study. InProceedings of the 21st International Conference on Mining Software Repositories(Lisbon, Portugal)(MSR ’24). Association for Computing Machinery, New York, NY, USA, 57...
-
[30]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. 2024. Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models. arXiv:2404.18796 [cs.CL] https://arxiv.org/abs/2404.18796 , Vol. 1, No. 1, Article . Publication date: April 2026. ...
- [31]
-
[32]
Miku Watanabe, Yutaro Kashiwa, Bin Lin, Toshiki Hirao, Ken’Ichi Yamaguchi, and Hajimu Iida. 2024. On the Use of ChatGPT for Code Review: Do Developers Like Reviews By ChatGPT?. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering(Salerno, Italy)(EASE ’24). Association for Computing Machinery, New York, NY...
- [33]
-
[34]
Junjielong Xu, Ziang Cui, Yuan Zhao, Xu Zhang, Shilin He, Pinjia He, Liqun Li, Yu Kang, Qingwei Lin, Yingnong Dang, Saravan Rajmohan, and Dongmei Zhang. 2024. UniLog: Automatic Logging via LLM and In-Context Learning. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal). Article 14, 12 pages
2024
-
[35]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, ...
2024
-
[36]
Jain, and Michael Stumm
Ding Yuan, Yu Luo, Xin Zhuang, Guilherme Renna Rodrigues, Xu Zhao, Yongle Zhang, Pranay U. Jain, and Michael Stumm. 2014. Simple testing can prevent most critical failures: an analysis of production failures in distributed data-intensive systems. InProceedings of the 11th USENIX Conference on Operating Systems Design and Implementation (Broomfield, CO)(OS...
2014
-
[37]
Lee, Xiaoming Tang, Yuanyuan Zhou, and Stefan Savage
Ding Yuan, Soyeon Park, Peng Huang, Yang Liu, Michael M. Lee, Xiaoming Tang, Yuanyuan Zhou, and Stefan Savage
-
[38]
InProceedings of the 10th USENIX Conference on Operating Systems Design and Implementation(Hollywood, CA, USA)(OSDI’12)
Be conservative: enhancing failure diagnosis with proactive logging. InProceedings of the 10th USENIX Conference on Operating Systems Design and Implementation(Hollywood, CA, USA)(OSDI’12). 293–306
-
[39]
D. Yuan, S. Park, and Y. Zhou. 2012. Characterizing logging practices in open-source software. InProc. of the 34th Int. Conf. on Software Engineering. 102–112
2012
-
[40]
Quanjun Zhang, Chunrong Fang, Yang Xie, Yaxin Zhang, Yun Yang, Weisong Sun, Shengcheng Yu, and Zhenyu Chen
-
[41]
A survey on large language models for software engineering,
A Survey on Large Language Models for Software Engineering. arXiv:2312.15223 [cs.SE] https://arxiv.org/abs/ 2312.15223
-
[42]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-Following Evaluation for Large Language Models.arXiv preprint arXiv:2311.07911(2023). , Vol. 1, No. 1, Article . Publication date: April 2026
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.