Recognition: no theorem link
Do Vision Language Models Need to Process Image Tokens?
Pith reviewed 2026-05-10 18:20 UTC · model grok-4.3
The pith
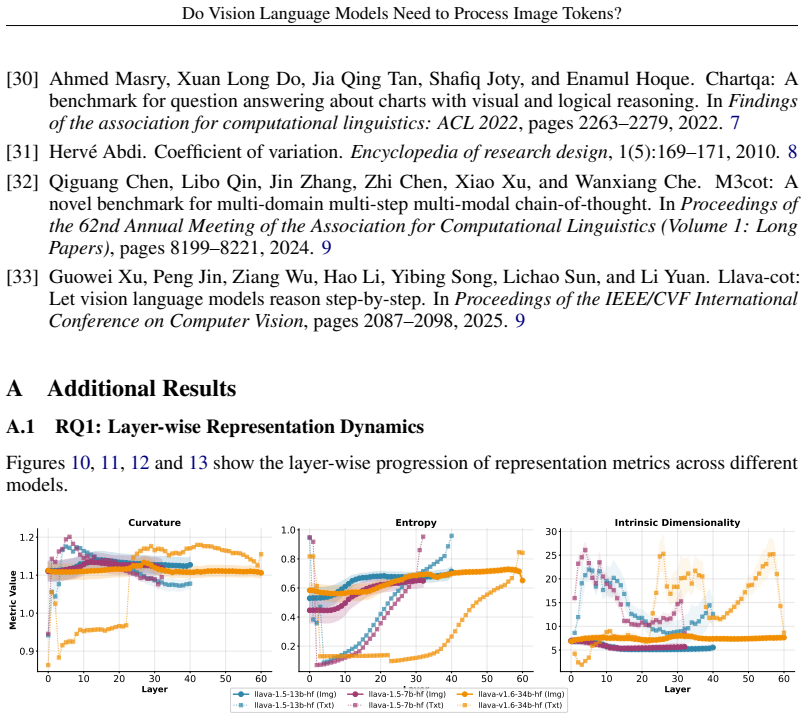
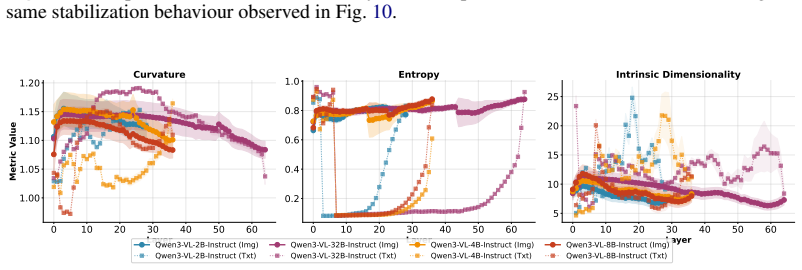
Visual representations in VLMs converge to a stable low-complexity regime after early layers, unlike text, so deeper image-token processing adds little value for many tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
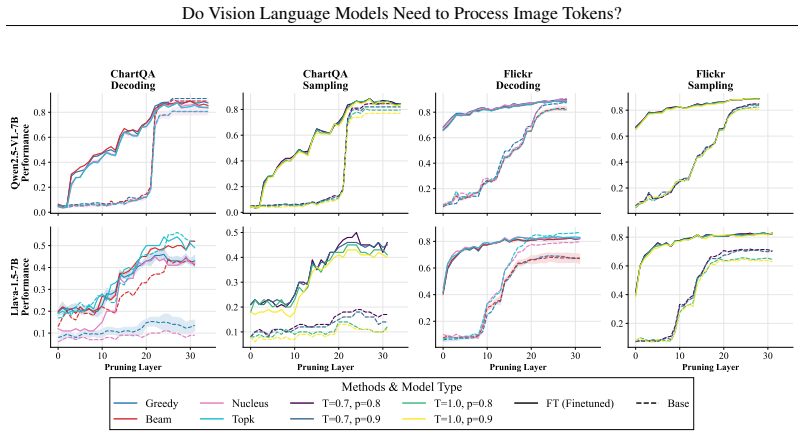
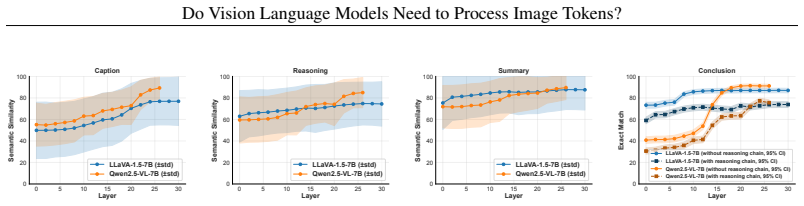
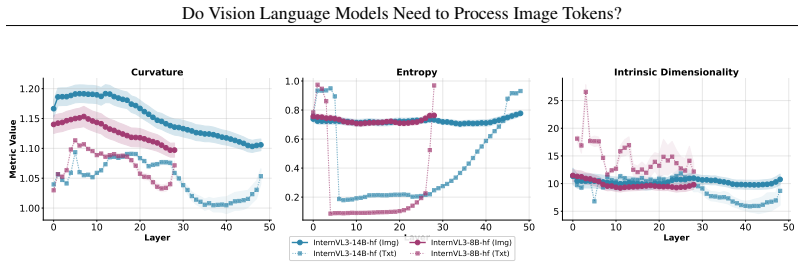
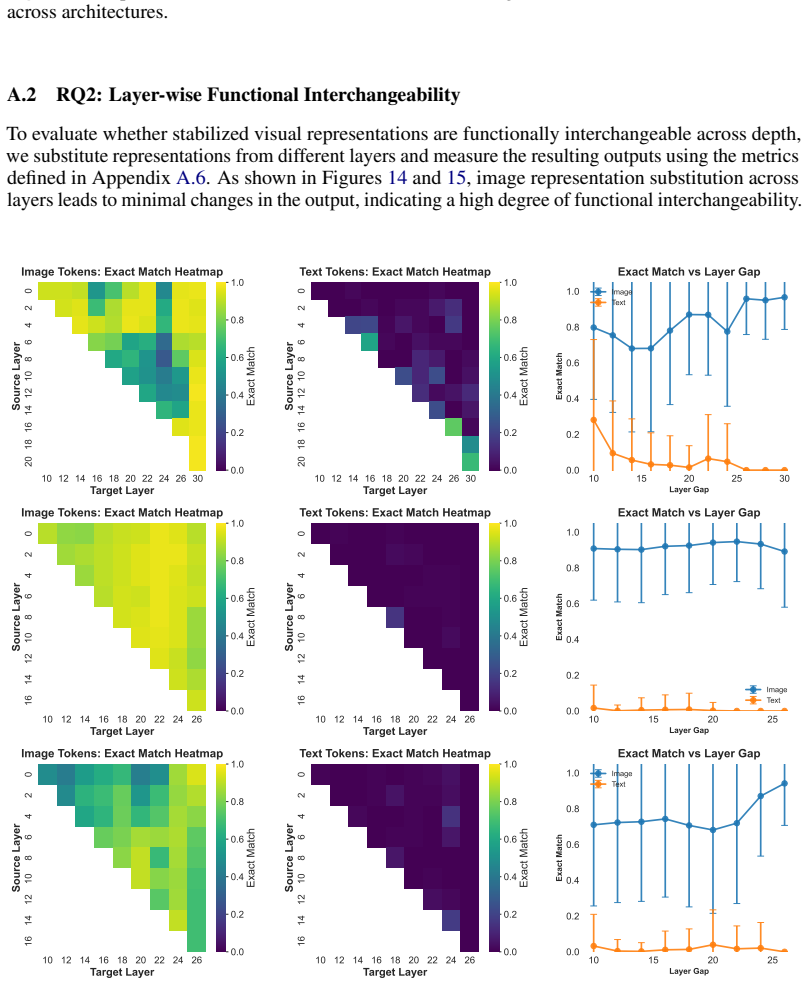
Visual token representations in VLMs rapidly converge to a bounded-complexity regime in which entropy stabilizes, intrinsic dimensionality compresses, and trajectory curvature flattens to a near-constant profile, while textual representations continue substantial restructuring across depth. After stabilization, visual representations from different layers become largely interchangeable. Depth-wise truncation shows that single-token predictions remain robust to reduced visual depth, whereas multi-token generation requires sustained visual access; under deterministic decoding, truncation perturbs reasoning trajectories more than final outputs.
What carries the argument
Depth-wise measurement of representation complexity (entropy, intrinsic dimensionality, curvature) together with interchangeability tests and visual-depth truncation experiments.
If this is right
- Single-token predictions tolerate early truncation of visual depth with little loss.
- Multi-token generation requires continued access to visual representations across more layers.
- Truncation affects intermediate reasoning trajectories more than final outputs under deterministic decoding.
- Visual and textual streams evolve on different depth scales, so uniform deep multimodal stacks may be over-engineered for vision.
Where Pith is reading between the lines
- Architectures could process images only in early layers and reuse the stabilized features, lowering compute.
- The same convergence pattern may appear in other multimodal setups, allowing layer pruning or sharing.
- Task-specific visual depth could be chosen at inference time rather than fixed at training time.
Load-bearing premise
Stabilization of entropy, dimensionality, and curvature plus layer interchangeability directly means deeper visual layers contribute little additional functional value.
What would settle it
Measure accuracy and reasoning-path divergence on single-token and multi-token VLM tasks when visual processing is truncated exactly after the observed convergence point.
Figures












read the original abstract
Vision Language Models (VLMs) have achieved remarkable success by integrating visual encoders with large language models (LLMs). While VLMs process dense image tokens across deep transformer stacks (incurring substantial computational overhead), it remains fundamentally unclear whether sustained image-token processing is necessary for their performance or visual representations meaningfully evolve from early to later layers. In this work, we systematically investigate the functional role of image tokens in VLMs and show that visual representations rapidly converge to a bounded-complexity regime, \ie their entropy stabilizes, intrinsic dimensionality compresses, and trajectory curvature approaches a near-constant profile. In contrast, textual representations continue to undergo substantial restructuring across depth. Once stabilized, visual representations become largely interchangeable between layers, indicating limited additional transformation in deeper stages. Further, depth-wise visual truncation reveals that the necessity of visual processing is task-dependent, where single-token predictions remain comparatively robust to truncated visual depth, but multi-token generation require sustained access to visual representations. Under deterministic decoding, reducing visual depth perturbs intermediate reasoning trajectories more strongly than final outputs, suggesting that image tokens influence the structure of reasoning more than the ultimate conclusions. Collectively, these findings \textbf{question the assumption} that deeper visual processing is uniformly essential in VLMs, challenging the current paradigm of multimodal LLM architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether sustained processing of image tokens across deep layers is necessary in Vision Language Models. It reports that visual representations rapidly stabilize according to entropy, intrinsic dimensionality, and trajectory curvature metrics, in contrast to ongoing changes in textual representations; stabilized visual features are largely interchangeable across layers. Depth-wise truncation experiments indicate task-dependent effects, with single-token predictions remaining robust to reduced visual depth while multi-token generation suffers, and that truncation perturbs reasoning trajectories more than final outputs under deterministic decoding. The work concludes that deeper visual processing is not uniformly essential.
Significance. If substantiated, the results could support more efficient VLM designs by allowing shallower visual stacks for many tasks, reducing compute without proportional performance loss. The combination of descriptive representation metrics with direct functional truncation tests is a strength, as is the explicit comparison of visual versus textual dynamics and the attention to reasoning trajectories. These elements provide empirical grounding for questioning uniform deep multimodal fusion.
major comments (2)
- [§4] §4 (Experimental Setup and Truncation): the manuscript supplies no details on the specific VLMs tested, datasets used, number of runs, statistical controls, or the precise implementation of depth-wise visual truncation (e.g., token removal vs. masking, handling of positional encodings, or layer selection). This absence prevents verification of the reported stabilization thresholds and task-dependent performance differences.
- [§5] §5 (Results on Interchangeability): the claim that stabilized visual representations are 'largely interchangeable' between layers requires quantitative support (e.g., similarity scores or performance deltas when swapping layers); without reported effect sizes or controls for prompt length, it is unclear whether the interchangeability is functionally meaningful or merely statistical.
minor comments (2)
- [Abstract] Abstract: the notation 'i.e.' appears as LaTeX command 'ie' without proper rendering; minor typographical consistency issues appear in the description of curvature profiles.
- [§5] Figure captions (assumed in §5): ensure all plots include error bars or confidence intervals for the entropy and dimensionality curves to allow assessment of stabilization significance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for improving the clarity and reproducibility of our work. We address each major comment below and will make the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup and Truncation): the manuscript supplies no details on the specific VLMs tested, datasets used, number of runs, statistical controls, or the precise implementation of depth-wise visual truncation (e.g., token removal vs. masking, handling of positional encodings, or layer selection). This absence prevents verification of the reported stabilization thresholds and task-dependent performance differences.
Authors: We agree that §4 would benefit from substantially expanded implementation details to support verification and reproducibility. The original manuscript prioritized the core findings on representation dynamics and truncation effects but did not provide sufficient granularity on the experimental protocol. In the revised version, we will add a dedicated subsection in §4 that specifies the VLMs evaluated, the datasets and tasks employed, the number of runs performed along with statistical controls (means and standard deviations), and the exact mechanics of depth-wise truncation, including the choice between token removal and masking, preservation of positional encodings, and the criteria for layer selection based on the stabilization metrics introduced in §3. These additions will directly address the referee's concerns and enable independent verification of the stabilization thresholds and task-dependent results. revision: yes
-
Referee: [§5] §5 (Results on Interchangeability): the claim that stabilized visual representations are 'largely interchangeable' between layers requires quantitative support (e.g., similarity scores or performance deltas when swapping layers); without reported effect sizes or controls for prompt length, it is unclear whether the interchangeability is functionally meaningful or merely statistical.
Authors: We acknowledge that the interchangeability claim in §5 would be strengthened by explicit quantitative metrics and controls. While the manuscript already demonstrates functional interchangeability through the truncation experiments (showing that performance remains largely intact when deeper visual layers are bypassed after stabilization), we did not include direct similarity measures or effect sizes. In the revision, we will augment §5 with cosine similarity scores between visual representations across layers, performance deltas from explicit layer-swapping experiments, and analyses that control for prompt length variations. These additions will quantify the degree of interchangeability and clarify that the observed stability is functionally meaningful rather than an artifact of statistical noise or prompt characteristics. revision: yes
Circularity Check
No significant circularity in empirical analysis
full rationale
The paper's central claims rest on direct empirical measurements of representation properties (entropy stabilization, intrinsic dimensionality compression, trajectory curvature) across layers and on controlled depth-wise truncation experiments that measure downstream task performance. These are observational and interventional results obtained from running the models, not derived quantities that reduce to the inputs by construction or via self-referential fitting. No equations, uniqueness theorems, or ansatzes are invoked that loop back to the paper's own definitions or prior self-citations in a load-bearing way. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Entropy, intrinsic dimensionality, and trajectory curvature are valid proxies for the functional complexity and necessity of visual representations.
- domain assumption Depth-wise truncation of visual tokens isolates the contribution of image processing without introducing confounding changes to the model's overall behavior.
Reference graph
Works this paper leans on
-
[1]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 2, 3, 6, 9
2024
-
[2]
Qwen2.5-vl technical report,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[3]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[5]
Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008,
Stephanie Fu, Tyler Bonnen, Devin Guillory, and Trevor Darrell. Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008, 2025. 2, 3
-
[6]
Words or vision: Do vision-language models have blind faith in text? InProceedings of the Compute r Vision and Pattern Recognition Conference, pages 3867–3876, 2025
Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi. Words or vision: Do vision-language models have blind faith in text? InProceedings of the Compute r Vision and Pattern Recognition Conference, pages 3867–3876, 2025
2025
-
[7]
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind. InProceedings of the Asian Conference on Computer Vision, pages 18–34, 2024. 3
2024
-
[8]
Nidhi Hegde, Sujoy Paul, Gagan Madan, and Gaurav Aggarwal. Analyzing the efficacy of an llm- only approach for image-based document question answering.arXiv preprint arXiv:2309.14389, 2023
-
[9]
Hallucinogen: Benchmarking hallucination in implicit reasoning within large vision language models
Ashish Seth, Dinesh Manocha, and Chirag Agarwal. Hallucinogen: Benchmarking hallucination in implicit reasoning within large vision language models. InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 89–102, 2025
2025
-
[10]
Egoillusion: Benchmark- ing hallucinations in egocentric video understanding
Ashish Seth, Utkarsh Tyagi, Ramaneswaran Selvakumar, Nishit Anand, Sonal Kumar, Sreyan Ghosh, Ramani Duraiswami, Chirag Agarwal, and Dinesh Manocha. Egoillusion: Benchmark- ing hallucinations in egocentric video understanding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28449–28468, 2025
2025
-
[11]
Rethinking explainability in the era of multimodal ai.arXiv, 2025
Chirag Agarwal. Rethinking explainability in the era of multimodal ai.arXiv, 2025. 2 11 Do Vision Language Models Need to Process Image Tokens?
2025
-
[12]
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013, 2025. 2, 3
-
[13]
Structures in high-dimensional data: Intrinsic dimension and cluster analysis
Kerstin Johnsson. Structures in high-dimensional data: Intrinsic dimension and cluster analysis
-
[14]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025. 3
2025
-
[15]
Jinhong Deng, Wen Li, Joey Tianyi Zhou, and Yang He. Scope: Saliency-coverage oriented token pruning for efficient multimodel llms.arXiv preprint arXiv:2510.24214, 2025
-
[16]
Pore: Position-reweighted visual token pruning for vision language models.arXiv e-prints, pages arXiv–2508, 2025
Kai Zhao, Wubang Yuan, Alex Lingyu Hung, and Dan Zeng. Pore: Position-reweighted visual token pruning for vision language models.arXiv e-prints, pages arXiv–2508, 2025
2025
-
[17]
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417,
-
[18]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021. 3
2021
-
[19]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[20]
arXiv preprint arXiv:2509.24791 (2025)
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision function layer in multimodal llms.arXiv preprint arXiv:2509.24791, 2025. 3
-
[21]
Shortv: Efficient multimodal large language models by freezing visual tokens in ineffective layers
Qianhao Yuan, Qingyu Zhang, Yanjiang Liu, Jiawei Chen, Yaojie Lu, Hongyu Lin, Jia Zheng, Xianpei Han, and Le Sun. Shortv: Efficient multimodal large language models by freezing visual tokens in ineffective layers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 329–339, 2025. 3
2025
-
[22]
Pruning all-rounder: Rethinking and improving inference efficiency for large vision language models
Wei Suo, Ji Ma, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. Pruning all-rounder: Rethinking and improving inference efficiency for large vision language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20247– 20256, 2025
2025
-
[23]
Laurens van der Maaten and Geoffrey Hinton
Jintao Tong, Wenwei Jin, Pengda Qin, Anqi Li, Yixiong Zou, Yuhong Li, Yuhua Li, and Ruixuan Li. Flowcut: Rethinking redundancy via information flow for efficient vision-language models. arXiv preprint arXiv:2505.19536, 2025. 3
-
[24]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 39, pages 5334–5342, 2025. 3
2025
-
[25]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024. 3
2024
-
[26]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 3
2024
-
[27]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002. 6
2002
-
[28]
Rogue scores
Max Grusky. Rogue scores. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 1914–1934, 2023. 6
1914
-
[29]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3,
-
[30]
7 12 Do Vision Language Models Need to Process Image Tokens?
-
[31]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022. 7
2022
-
[32]
Coefficient of variation.Encyclopedia of research design, 1(5):169–171, 2010
Hervé Abdi. Coefficient of variation.Encyclopedia of research design, 1(5):169–171, 2010. 8
2010
-
[33]
M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8199–8221, 2024. 9
2024
-
[34]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025. 9 A Additional Results A.1 RQ1: Layer-wise Representation Dynamics Figures 10, 11, 12 and 13 show the layer-wise progressio...
2087
-
[35]
Accuracy
Exact Match.Exact Match measures whether the predicted answer ˆyi exactly matches the reference answer yi. Over a dataset of N samples, the Exact Match score is defined as 1 N PN i=1 1(ˆyi =y i), where 1(·) is the indicator function that returns 1 if the predicted an- swer exactly matches the reference answer and 0 otherwise. "Accuracy" and "exact match" ...
-
[36]
Embeddings are obtained using a Sentence-Transformer model
Semantic Similarity.For open-ended generation tasks we measure semantic similarity between the generated output ˆsi and the reference output si using cosine similarity between sentence embeddings. Embeddings are obtained using a Sentence-Transformer model. The similarity is defined as: SS(ˆsi, si) = f(ˆsi)·f(s i) ∥f(ˆsi)∥ ∥f(s i)∥ ,(3) wheref(·)denotes th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.