Recognition: unknown
Integrated electro-optic attention nonlinearities for transformers
Pith reviewed 2026-05-10 17:35 UTC · model grok-4.3
The pith
Thin-film lithium niobate modulators implement analog Softmax for transformers with competitive accuracy at 4-bit quantization
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
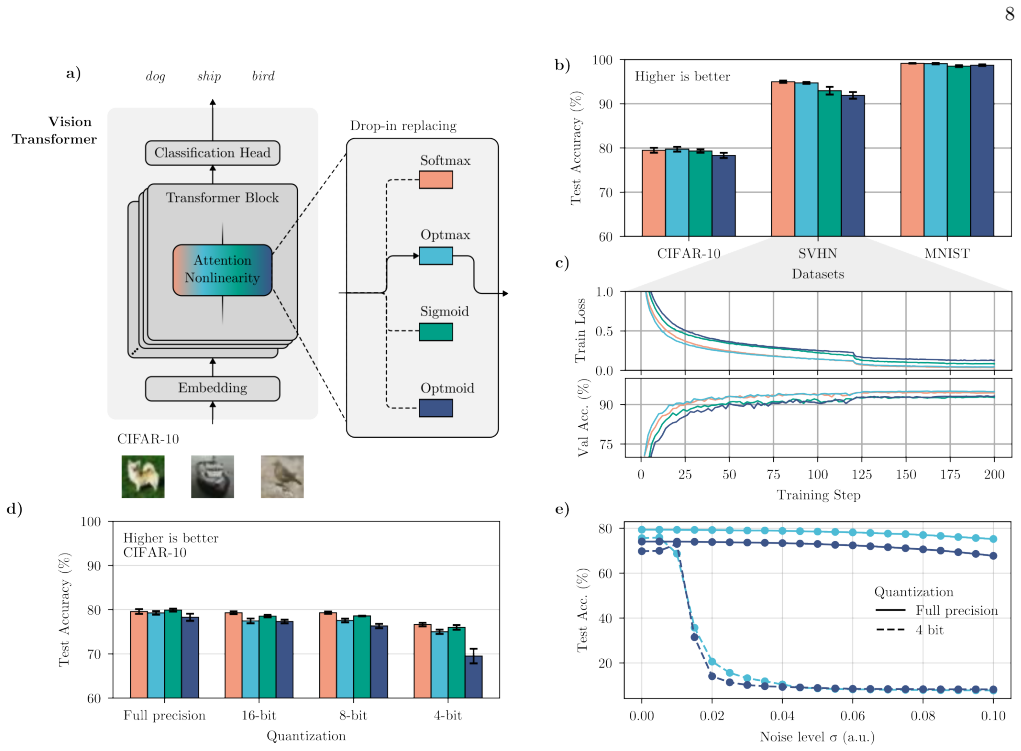
Thin-film lithium niobate Mach-Zehnder modulators serve as electro-optic nonlinear function units that replace digital Softmax and Sigmoid operations in transformers. The analog implementations maintain competitive accuracy in Vision Transformers and Large Language Models under 4-bit input-output quantization, with system noise characterized at speeds up to 10 GBaud.
What carries the argument
Thin-film lithium niobate Mach-Zehnder modulators configured as analog nonlinear computational elements for attention mechanisms
Load-bearing premise
The analog electro-optic implementations integrate into full transformer pipelines at scale without introducing unacceptable cumulative noise, calibration drift, or accuracy loss beyond the characterized conditions.
What would settle it
A full-scale transformer model using the TFLN modulators for all nonlinearities shows significant accuracy degradation compared to digital baseline under realistic noise levels.
Figures




read the original abstract
Transformers have emerged as the dominant neural-network architecture, achieving state-of-the-art performance in language processing and computer vision. At the core of these models lies the attention mechanism, which requires a nonlinear, non-negative mapping using the Softmax function. However, although Softmax operations account for less than 1% of the total operation count, they can disproportionately bottleneck overall inference latency. Here, we use thin-film lithium niobate (TFLN) Mach-Zehnder modulators (MZMs) as analog nonlinear computational elements to drastically reduce the latency of nonlinear computations. We implement electro-optic alternatives to digital Softmax and Sigmoid, and evaluate their performance in Vision Transformers and Large Language Models. Our system maintains highly competitive accuracy, even under aggressive 4-bit input-output quantization of the analog units. We further characterize system noise at encoding speeds up to 10 GBaud and assess model robustness under various noise conditions. Our findings suggest that TFLN modulators can serve as nonlinear function units within hybrid co-packaged hardware, enabling high-speed and energy-efficient nonlinear computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript demonstrates the use of thin-film lithium niobate (TFLN) Mach-Zehnder modulators (MZMs) as analog electro-optic nonlinear units to approximate Softmax and Sigmoid functions for transformer attention mechanisms. It reports competitive accuracy in Vision Transformers and Large Language Models under aggressive 4-bit input-output quantization, along with noise characterization of the modulators at encoding speeds up to 10 GBaud, and concludes that such devices can enable high-speed, energy-efficient hybrid co-packaged hardware for nonlinear computation.
Significance. If the central claims hold, the work provides an experimental path toward photonic acceleration of the nonlinear components in attention, which can bottleneck latency despite low operation count. The demonstration of TFLN-based analog nonlinearities under quantization and high-speed noise conditions is a concrete hardware contribution that could inform co-packaged electro-optic AI accelerators, though its impact depends on scalability to full pipelines.
major comments (2)
- [Abstract] Abstract: The claim that the system 'maintains highly competitive accuracy' under 4-bit quantization is not supported by quantitative error bars, explicit baseline comparisons to digital implementations, or details on how the analog Softmax is exactly realized, leaving the central claim only partially substantiated.
- [Evaluation] Evaluation in ViTs and LLMs: The reported results appear limited to isolated modulator characterizations or small test conditions; no end-to-end pipeline measurements or noise-propagation analysis across multi-layer attention blocks, residual connections, and layer stacking are provided, which is load-bearing for the claim that TFLN units can be integrated into full transformers without unacceptable cumulative errors.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the exact functional mapping implemented by the TFLN MZM (e.g., how input voltage maps to the nonlinear output) to clarify the electro-optic Softmax approximation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We have revised the manuscript to address the concerns about quantitative support in the abstract and the scope of the evaluations, adding clarifications, comparisons, and analyses while maintaining an accurate representation of our experimental contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the system 'maintains highly competitive accuracy' under 4-bit quantization is not supported by quantitative error bars, explicit baseline comparisons to digital implementations, or details on how the analog Softmax is exactly realized, leaving the central claim only partially substantiated.
Authors: We agree that the abstract would benefit from stronger quantitative backing. In the revised manuscript, we have added error bars from repeated experimental runs to the accuracy results. We have also included explicit side-by-side comparisons to digital 4-bit Softmax baselines under identical quantization, showing our electro-optic approach remains within 1-2% accuracy. The methods section has been expanded with the precise electro-optic mapping (MZM transfer function approximation to Softmax) and calibration procedure used. revision: yes
-
Referee: [Evaluation] Evaluation in ViTs and LLMs: The reported results appear limited to isolated modulator characterizations or small test conditions; no end-to-end pipeline measurements or noise-propagation analysis across multi-layer attention blocks, residual connections, and layer stacking are provided, which is load-bearing for the claim that TFLN units can be integrated into full transformers without unacceptable cumulative errors.
Authors: We appreciate the emphasis on cumulative effects. Our work experimentally characterizes the individual TFLN nonlinear units and evaluates them within attention blocks under measured noise conditions up to 10 GBaud. In the revision, we have added a noise-propagation simulation that models error accumulation across stacked attention layers and residual connections, confirming robustness within the reported accuracy margins. Full end-to-end hardware measurements of a complete multi-layer pipeline exceed the scope of the current device-level demonstration and are identified as future work in the updated discussion. revision: partial
Circularity Check
No circularity: experimental hardware demonstration is self-contained
full rationale
The paper reports direct experimental measurements of TFLN MZM-based analog nonlinear units implementing electro-optic Softmax/Sigmoid approximations, with accuracy evaluated on ViTs and LLMs under 4-bit I/O quantization and noise characterized up to 10 GBaud. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps exist; claims rest on hardware test results rather than any self-referential equations or uniqueness theorems. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is All you Need. InProc. Neural Information Processing Systems (NeurIPS), 2017
2017
-
[2]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
Daya et al Guo. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645 (8081):633–638, 2025. doi:10.1038/s41586-025-09422-z
-
[3]
An im- age is worth 16x16 words: Transformers for image recog- nition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An im- age is worth 16x16 words: Transformers for image recog- nition at scale. InProc. Int. Conf. on Learning Repre- sentations (ICLR), 2021
2021
-
[4]
Theory, analysis, and best practices for sigmoid self-attention
Jason Ramapuram, Federico Danieli, Eeshan Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, and Russ Webb. Theory, analysis, and best practices for sigmoid self-attention. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[5]
cosformer: Rethinking softmax in attention
Zhen Qin, Weixuan Sun, Hui Deng, Dongxu Li, Yunshen Wei, Baohong Lv, Junjie Yan, Lingpeng Kong, and Yiran Zhong. cosformer: Rethinking softmax in attention. In Proc. Int. Conf. on Learning Representations (ICLR), 2022
2022
-
[6]
Rodriguez Condia, Juan-David Guerrero- Balaguera, Edwar J
Josie E. Rodriguez Condia, Juan-David Guerrero- Balaguera, Edwar J. Pati˜ no N´ u˜ nez, Robert Limas, and Matteo Sonza Reorda. Investigating and Reducing the Architectural Impact of Transient Faults in Special Func- tion Units for GPUs.Journal of Electronic Testing, 40 (2):215–228, 2024. doi:10.1007/s10836-024-06107-9
-
[7]
Flashattention- 3: fast and accurate attention with asynchrony and low- precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention- 3: fast and accurate attention with asynchrony and low- precision. InProc. Neural Information Processing Sys- tems (NeurIPS), 2024
2024
-
[8]
Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. Flashattention-4: Al- gorithm and kernel pipelining co-design for asymmetric hardware scaling. arXiv preprint, 2026. URLhttps: //arxiv.org/abs/2603.05451
-
[9]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InProc. Neural Information Processing Systems (NeurIPS), 2022
2022
-
[11]
Stevens, Rangharajan Venkatesan, Steve Dai, Brucek Khailany, and Anand Raghunathan
Jacob R. Stevens, Rangharajan Venkatesan, Steve Dai, Brucek Khailany, and Anand Raghunathan. Softer- max: Hardware/software co-design of an efficient soft- max for transformers. InProceedings of the 58th Annual ACM/IEEE Design Automation Conference, 2022
2022
-
[12]
Fanqi Yan, Huy Nguyen, Pedram Akbarian, Nhat Ho, and Alessandro Rinaldo. Sigmoid self-attention has lower sample complexity than softmax self-attention: A mixture-of-experts perspective. arXiv preprint, 2025. URLhttps://arxiv.org/abs/2502.00281
-
[13]
URLhttps://docs.pytorch.org/docs/stable/ generated/torch.nn.attention.SDPBackend.html
SDPBackend — PyTorch 2.11 documentation, 2026. URLhttps://docs.pytorch.org/docs/stable/ generated/torch.nn.attention.SDPBackend.html
2026
-
[14]
Language models are unsupervised multitask learners, 2019
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. URLhttps:// cdn.openai.com/better-language-models/language_ models_are_unsupervised_multitask_learners.pdf
2019
-
[15]
H100 tensor core gpu, 2022
NVIDIA. H100 tensor core gpu, 2022. URLhttps:// resources.nvidia.com/en-us-hopper-architecture/ nvidia-h100-tensor-c?ncid=no-ncid
2022
-
[16]
PyTorch: An Impera- tive Style, High-Performance Deep Learning Library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, and Natalia Gimelshein. PyTorch: An Impera- tive Style, High-Performance Deep Learning Library. In Proc. Neural Information Processing Systems (NeurIPS), 2019
2019
-
[17]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. FlashAttention: Fast and memory- efficient exact attention with IO-awareness. InProc. Neu- ral Information Processing Systems (NeurIPS), 2022
2022
-
[18]
VEXP: A Low-Cost RISC-V ISA Extension for Ac- celerated Softmax Computation in Transformers
Run Wang, Gamze Islamoglu, Andrea Belano, and et al. VEXP: A Low-Cost RISC-V ISA Extension for Ac- celerated Softmax Computation in Transformers. In 2025 IEEE 32nd Symposium on Computer Arithmetic (ARITH), 2025
2025
-
[19]
Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads
Rachid Karami, Sheng-Chun Kao, and Hyoukjun Kwon. Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads. In2025 IEEE International Symposium on Performance Analy- sis of Systems and Software (ISPASS), May 2025
2025
-
[20]
SOLE: Hardware-Software Co-design of Softmax and LayerNorm for Efficient Transformer In- ference
Wenxun Wang, Shuchang Zhou, Wenyu Sun, Peiqin Sun, and Yongpan Liu. SOLE: Hardware-Software Co-design of Softmax and LayerNorm for Efficient Transformer In- ference. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 2023
2023
-
[21]
Hyft: A Reconfig- urable Softmax Accelerator with Hybrid Numeric For- mat for both Training and Inference
Tianhua Xia and Sai Qian Zhang. Hyft: A Reconfig- urable Softmax Accelerator with Hybrid Numeric For- mat for both Training and Inference. InProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design, 2024
2024
-
[22]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InProc. Int. Conf. on Learning Representations (ICLR), 2024
2024
-
[23]
Schraudolph
Nicol N. Schraudolph. A Fast, Compact Approximation of the Exponential Function.Neural Computation, 1999
1999
-
[24]
NN- LUT: neural approximation of non-linear operations for efficient transformer inference
Joonsang Yu, Junki Park, Seongmin Park, Minsoo Kim, Sihwa Lee, Dong Hyun Lee, and Jungwook Choi. NN- LUT: neural approximation of non-linear operations for efficient transformer inference. InProceedings of the 59th ACM/IEEE Design Automation Conference. Association for Computing Machinery, 2022
2022
-
[25]
PEANO-ViT: Power- Efficient Approximations of Non-Linearities in Vision Transformers
Mohammad Erfan Sadeghi, Arash Fayyazi, Seyedarmin Azizi, and Massoud Pedram. PEANO-ViT: Power- Efficient Approximations of Non-Linearities in Vision Transformers. InProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design. ACM, 2024
2024
-
[26]
Nathan Leroux, Paul-Philipp Manea, Chirag Sudarshan, Jan Finkbeiner, Sebastian Siegel, John Paul Strachan, 12 and Emre Neftci. Analog in-memory computing atten- tion mechanism for fast and energy-efficient large lan- guage models.Nature Computational Science, 5(9):813– 824, 2025. doi:10.1038/s43588-025-00854-1
-
[27]
Ziyu Zhan, Hao Wang, Qiang Liu, and Xing Fu. Opto- electronic nonlinear Softmax operator based on diffrac- tive neural networks.Optics Express, 32(15):26458, 2024. doi:10.1364/OE.527843
-
[28]
SOFTONIC: A Photonic Design Approach to Softmax Activation for High-Speed Fully Analog AI Acceleration
Priyabrata Dash, Anxiao Jiang, and Dharanidhar Dang. SOFTONIC: A Photonic Design Approach to Softmax Activation for High-Speed Fully Analog AI Acceleration. InProceedings of the Great Lakes Symposium on VLSI 2025, 2025
2025
-
[29]
Photonic exponen- tial approximation via cascaded tfln microring resonators toward softmax
Hyoseok Park and Yeonsang Park. Photonic exponen- tial approximation via cascaded tfln microring resonators toward softmax. arXiv preprint, 2026. URLhttps: //arxiv.org/abs/2603.12934
-
[30]
A case study on the performance metrics of in- tegrated photonic computing
Frank Br¨ uckerhoff-Pl¨ uckelmann, Jelle Dijkstra, Julian B¨ uchel, Bottyan Batkai, Falk Ebert, Luis Mickeler, Urs Egger, Abu Sebastian, Wolfram Pernice, and Ghazi Sar- wat Syed. A case study on the performance metrics of in- tegrated photonic computing. arXiv preprint, 2025. URL https://arxiv.org/abs/2511.00186
- [31]
-
[32]
240 gbps high-efficiency opti- cal interconnection with tfln transmitter and ge-pd re- ceiver.Opt
Zhipei Wang, Xuanhao Wang, Jinwen Song, Xu Wang, Aoxue Wang, Shuai Yuan, Xiao Hu, Fangchen Hu, Hai- wen Cai, and Wei Chu. 240 gbps high-efficiency opti- cal interconnection with tfln transmitter and ge-pd re- ceiver.Opt. Lett., 50(21):6469–6472, Nov 2025. doi: 10.1364/OL.575339
-
[33]
Chapman, Giovanni Finco, Tristan Kut- tner, Andreas Maeder, and Rachel Grange
Alessandra Sabatti, Jost Kellner, Fabian Kaufmann, Robert J. Chapman, Giovanni Finco, Tristan Kut- tner, Andreas Maeder, and Rachel Grange. Extremely high extinction ratio electro-optic modulator via fre- quency upconversion to visible wavelengths.Optics Let- ters, 49(14):3870–3873, 2024. doi:10.1364/OL.525733. URLhttps://opg.optica.org/ol/abstract.cfm?ur...
-
[34]
Fabian Kaufmann, Giovanni Finco, Andreas Maeder, and Rachel Grange. Redeposition-free inductively-coupled plasma etching of lithium niobate for integrated pho- tonics.Nanophotonics, 12(8):1601–1611, 2023. doi: doi:10.1515/nanoph-2022-0676
-
[35]
Yann LeCun, Corinna Cortes, and Christopher J.C. Burges. Mnist handwritten digit database, 2010. URL http://yann.lecun.com/exdb/mnist/
2010
-
[36]
Learning multiple layers of fea- tures from tiny images
Alex Krizhevsky. Learning multiple layers of fea- tures from tiny images. Technical report, University of Toronto, 2009. URLhttps://www.cs.toronto.edu/ ~kriz/cifar.html
2009
-
[37]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Bo Wu, and Andrew Y. Ng. Reading digits in nat- ural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
2011
-
[38]
Fineweb-edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024. URLhttps://huggingface. co/datasets/HuggingFaceFW/fineweb-edu
2024
-
[39]
I-bert: Integer-only bert quan- tization.Proc
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W Ma- honey, and Kurt Keutzer. I-bert: Integer-only bert quan- tization.Proc. Int. Conf. on Machine Learning (ICML), 2021
2021
-
[40]
Softmax Bias Correction for Quan- tized Generative Models
Nilesh Prasad Pandey, Marios Fournarakis, Chirag Patel, and Markus Nagel. Softmax Bias Correction for Quan- tized Generative Models. In2023 IEEE/CVF Interna- tional Conference on Computer Vision Workshops (IC- CVW), 2023
2023
-
[41]
Nayem Al-Kayed, Charles St-Arnault, Hugh Morison, A. Aadhi, Chaoran Huang, Alexander N. Tait, David V. Plant, and Bhavin J. Shastri. Programmable 200 GOPS Hopfield-inspired photonic Ising machine.Nature, 648 (8094):576–584, December 2025. doi:10.1038/s41586- 025-09838-7
-
[42]
Analog implementation of the softmax function
Jacob Sillman. Analog implementation of the softmax function. arXiv preprint, 2023. URLhttps://arxiv. org/abs/2305.13649
-
[43]
firwin — SciPy v1.17.0 Manual, 2026
SciPy. firwin — SciPy v1.17.0 Manual, 2026. URLhttps://docs.scipy.org/doc/scipy/reference/ generated/scipy.signal.firwin.html
2026
-
[44]
CTL 1550, 2026
TOPTICA Photonics. CTL 1550, 2026. URLhttps://www.toptica.com/products/ narrow-linewidth-lasers/ctl
2026
-
[45]
E36106A DC power sup- ply, 100V, 0.4A, 40W [Obsolete], 2026
Keysight Technologies. E36106A DC power sup- ply, 100V, 0.4A, 40W [Obsolete], 2026. URL https://www.keysight.com/us/en/product/E36106A/ dc-power-supply-100v-0-4a-40w.html
2026
-
[46]
Jiang.High Data Rate DMT SERDES Design
Z. Jiang.High Data Rate DMT SERDES Design. PhD thesis, Carleton University, Ottawa, Ontario, 2022
2022
-
[47]
A 128 gb/s, 11.2 mw single-ended pam4 linear tia with 2.7µarms input noise in 22 nm finfet cmos
Saeid Daneshgar, Hao Li, Taehwan Kim, and Ganesh Balamurugan. A 128 gb/s, 11.2 mw single-ended pam4 linear tia with 2.7µarms input noise in 22 nm finfet cmos. IEEE Journal of Solid-State Circuits, 57(5):1397–1408,
-
[48]
doi:10.1109/JSSC.2022.3147467. AUTHOR CONTRIBUTIONS COMPETING INTEREST The authors declare no competing financial or nonfinan- cial interests. ACKNOWLEDGMENTS This work was supported by the Swiss National Science Foundation SNSF Consolidator Grant APIC (TMCG- 2 213713), by Sinergia LION (CRII5-216600), and by the European Union’s Horizon Europe research a...
-
[49]
Setup and Measurement We perform high-speed measurements of a Mach-Zehnder modulator (MZM) response to compare the experiment with the simulations used within Transformer training. Fig. S1a illustrates the experimental setup. BothOpt- maxandOptmoidare designed to perform a nonlinear transform on a sequence of valuesx i withi∈[1, n]. To test this, a 5-bit ...
2048
-
[50]
S1b displays the response of a uniformly-sampled 10 GBaud 4-bit sequences atV π at three stages: (1) DAC output, (2) RF amplifier output, and (3) photo- diode output
Experimental Noise Fig. S1b displays the response of a uniformly-sampled 10 GBaud 4-bit sequences atV π at three stages: (1) DAC output, (2) RF amplifier output, and (3) photo- diode output. We observe additive noise introduced by the RF amplifier, which is most pronounced at the MZM quadrature point where the voltage-to-power transcon- ductance is maximi...
-
[51]
The input encoding range [x min, xmax], which maps onto the rising slope of the first MZM’s transfer function
-
[52]
The normalization range [z min, zmax], which maps the accumulated optical power onto the falling slope of the second MZM. To translate from the digital simulation domain w∈[w min, wmax] to the physical voltage inputV∈ [Vmin, Vmax] driving the MZM, we define a fixed, range- preserving affine transformation: V(w) =γw+δ,(S22) where the scaling factorγand the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.