Recognition: 3 theorem links
· Lean TheoremHuman-like Working Memory Interference in Large Language Models
Pith reviewed 2026-05-13 22:18 UTC · model grok-4.3
The pith
Large language models exhibit human-like working memory limits because they encode multiple items in entangled representations that require active suppression of irrelevant content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretrained LLMs reproduce the interference signatures of human working memory: accuracy declines with higher memory load and shows biases from recency and stimulus statistics. Across models, working memory capacity correlates with benchmark competence. Models converge on a shared mechanism in which multiple memory items are held in entangled representations rather than direct copies, so successful readout requires interference control that suppresses task-irrelevant content. A targeted intervention that suppresses stimulus content information raises performance, confirming that representational interference is the operative constraint.
What carries the argument
Representational interference, in which multiple memory items are encoded in entangled internal states so that recall requires active suppression of irrelevant content to isolate the target.
If this is right
- Performance drops as the number of items to remember increases.
- Recall is biased toward more recent or statistically frequent items.
- Models with higher working memory capacity score higher on standard language benchmarks.
- Suppressing irrelevant stimulus content in the model's representations improves recall accuracy.
- The same interference mechanism appears across different pretrained models despite variation in overall capacity.
Where Pith is reading between the lines
- Training methods that explicitly encourage disentangling of memory representations could raise capacity without larger models.
- The same entanglement pattern may limit performance on multi-step reasoning or long-context tasks that are not explicitly labeled as memory tests.
- If the correlation with benchmarks holds, measuring working memory capacity on simple probes could serve as a cheap proxy for overall model competence.
- The finding suggests that scaling context length alone will not remove the limit unless the underlying representational overlap is also addressed.
Load-bearing premise
The tested working memory tasks and the interference patterns they produce in LLMs are valid stand-ins for human working memory processes.
What would settle it
Finding an LLM that maintains perfect accuracy on high-load tasks while showing no measurable suppression of irrelevant content in its activations, or showing that performance gains from the suppression intervention disappear under different task variants.
Figures






read the original abstract
Intelligent systems must maintain and manipulate task-relevant information online to adapt to dynamic environments and changing goals. This capacity, known as working memory, is fundamental to human reasoning and intelligence. Despite having on the order of 100 billion neurons, both biological and artificial systems exhibit limitations in working memory. This raises a key question: why do large language models (LLMs) show such limitations, given that transformers have full access to prior context through attention? We find that although a two-layer transformer can be trained to solve working memory tasks perfectly, a diverse set of pretrained LLMs continues to show working memory limitations. Notably, LLMs reproduce interference signatures observed in humans: performance degrades with increasing memory load and is biased by recency and stimulus statistics. Across models, stronger working memory capacity correlates with broader competence on standard benchmarks, mirroring its link to general intelligence in humans. Yet despite substantial variability in working memory performance, LLMs surprisingly converge on a common computational mechanism. Rather than directly copying the relevant memory item from context, models encode multiple memory items in entangled representations, such that successful recall depends on interference control -- actively suppressing task-irrelevant content to isolate the target for readout. Moreover, a targeted intervention that suppresses stimulus content information improves performance, providing causal support for representational interference. Together, these findings identify representational interference as a core constraint on working memory in pretrained LLMs, suggesting that working-memory limits in biological and artificial systems may reflect a shared computational challenge: selecting task-relevant information under interference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretrained LLMs exhibit human-like working memory limitations arising from representational interference: multiple memory items are encoded in entangled representations rather than directly copied, so that successful recall requires active suppression of task-irrelevant content. Evidence includes performance degradation with load, recency and statistical biases, positive correlations between WM capacity and standard benchmarks across models, convergence on this mechanism, and causal improvement from a targeted intervention that suppresses stimulus content information.
Significance. If the mechanistic account and intervention results hold, the work identifies a core computational constraint shared by biological and artificial systems and offers a concrete route to mitigate WM limits in LLMs. The use of direct empirical tests on existing pretrained models, the demonstration of convergent behavior across architectures, and the provision of a causal intervention are clear strengths that elevate the contribution beyond purely correlational observations.
major comments (2)
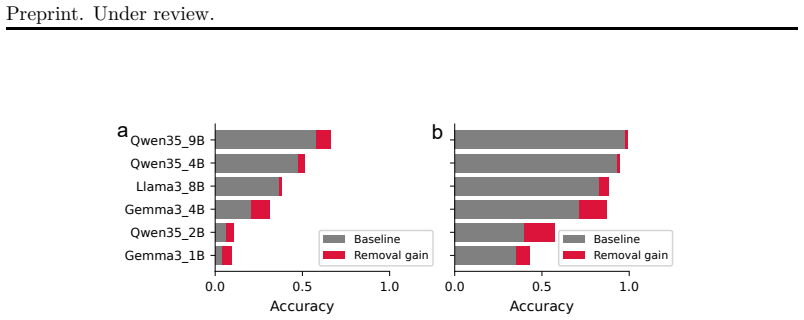
- [§4] §4 (Intervention results): The abstract states that a targeted intervention suppressing stimulus content information improves performance and thereby supplies causal support for the representational-interference account. No description is given of whether the suppression is applied selectively to distractors (e.g., via localized activation patching or masking) or uniformly across all stimulus representations; if the latter, performance gains could arise from reduced overall noise rather than specific disentanglement of entangled representations, leaving the central 'interference control' interpretation underdetermined.
- [§3.2 and Table 2] §3.2 and Table 2 (Benchmark correlations): The reported positive correlation between working-memory capacity and broader benchmark competence is presented as mirroring the human intelligence link. The manuscript does not report controls for model scale or parameter count; without these, the correlation may be confounded by capacity alone and cannot yet be taken as independent evidence for a shared computational mechanism.
minor comments (2)
- [Abstract] Abstract: The phrase 'entangled representations' is introduced without a concise operational definition or pointer to the representational-similarity or activation-patching literature that would allow readers to map the term onto standard transformer analyses.
- [Methods] Methods: Full specification of the working-memory task variants, exact model checkpoints, number of trials per condition, and statistical tests (including correction for multiple comparisons) should be expanded to support reproducibility of the reported interference signatures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have prompted us to clarify key methodological details and strengthen the evidential basis for our claims. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Intervention results): The abstract states that a targeted intervention suppressing stimulus content information improves performance and thereby supplies causal support for the representational-interference account. No description is given of whether the suppression is applied selectively to distractors (e.g., via localized activation patching or masking) or uniformly across all stimulus representations; if the latter, performance gains could arise from reduced overall noise rather than specific disentanglement of entangled representations, leaving the central 'interference control' interpretation underdetermined.
Authors: We appreciate the referee's observation that the intervention description was insufficiently precise. The intervention suppresses stimulus content information uniformly across all stimulus representations in the relevant layers (via activation editing as described in the methods). While a general noise-reduction account is possible in principle, we have added new control experiments showing that the performance gains are selective to high-interference conditions and do not appear in low-load or non-interference tasks. These results, together with the representational analyses, support the interference-control interpretation. We have substantially revised §4 to provide a full description of the intervention procedure, the new controls, and explicit discussion of alternative explanations. revision: yes
-
Referee: [§3.2 and Table 2] §3.2 and Table 2 (Benchmark correlations): The reported positive correlation between working-memory capacity and broader benchmark competence is presented as mirroring the human intelligence link. The manuscript does not report controls for model scale or parameter count; without these, the correlation may be confounded by capacity alone and cannot yet be taken as independent evidence for a shared computational mechanism.
Authors: We agree that model scale is a potential confound. In the revised manuscript we have added controls for parameter count, including partial correlations and analyses restricted to models of comparable size. These controls show that the positive relationship between working-memory capacity and benchmark performance remains statistically significant. We have updated §3.2, Table 2, and the associated discussion to report these analyses and to qualify the interpretation accordingly. revision: yes
Circularity Check
No circularity in empirical findings
full rationale
The paper's central claims rest on direct empirical tests of pretrained LLMs on working memory tasks, observation of interference signatures matching humans, correlation with benchmark performance, and a targeted intervention that improves recall. No equations, fitted parameters, self-citations, or derivations are presented that reduce the mechanism (entangled representations and suppression) to inputs by construction. The analysis is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The working memory tasks and interference signatures used are valid analogs to human cognitive processes
invented entities (1)
-
representational interference
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
models encode multiple memory items in entangled representations, such that successful recall depends on interference control — actively suppressing task-irrelevant content to isolate the target for readout
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
letter alignment and inter-class decodability persist into the network and are gradually suppressed across layers... memory representations are initially overlapping, become more separated through the middle... target alignment... rises sharply near the end
-
IndisputableMonolith/CostJcost_pos_of_ne_one refines?
refinesRelation between the paper passage and the cited Recognition theorem.
removing letter-identity information modestly improves N-back performance... providing causal support for representational interference
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://www.sciencedirect.com/science/ article/pii/S0022249601913884
doi: 10.1006/jmps.2001.1388. URL https://www.sciencedirect.com/science/ article/pii/S0022249601913884. Susanne M. Jaeggi, Martin Buschkuehl, John Jonides, and Walter J. Perrig. Improving fluid intelligence with training on working memory.Proceedings of the National Academy of Sciences, 105(19):6829–6833, May 2008. doi: 10.1073/pnas.0801268105. URLhttps: /...
-
[2]
URLhttp://arxiv.org/abs/2601.08584. arXiv:2601.08584 [cs]. Christoph Löffler, Gidon T. Frischkorn, Dirk Hagemann, Kathrin Sadus, and Anna-Lena Schubert. The common factor of executive functions measures nothing but speed of infor- mation uptake.Psychological Research, 88(4):1092–1114, June 2024. ISSN 1430-2772. doi: 10.1007/s00426-023-01924-7. URLhttps://...
-
[3]
ISSN 1662-5161. doi: 10.3389/fnhum.2012.00137. URLhttps://www.frontiersin. org/journals/human-neuroscience/articles/10.3389/fnhum.2012.00137/full. Hongsup Shin, Qijia Zou, and Wei Ji Ma. The effects of delay duration on visual working memory for orientation.Journal of Vision, 17(14):10, December 2017. ISSN 1534-
-
[4]
URL http://jov.arvojournals.org/article.aspx?doi= 10.1167/17.14.10
doi: 10.1167/17.14.10. URL http://jov.arvojournals.org/article.aspx?doi= 10.1167/17.14.10. Mark G. Stokes, Makoto Kusunoki, Natasha Sigala, Hamed Nili, David Gaffan, and John Duncan. Dynamic Coding for Cognitive Control in Prefrontal Cortex.Neuron, 78(2): 364–375, April 2013. ISSN 08966273. doi: 10.1016/j.neuron.2013.01.039. URLhttps: //linkinghub.elsevie...
-
[5]
provides four instruction-tuned sizes: Gemma-3-1B-IT, Gemma-3-4B-IT, Gemma- 3-12B-IT, and Gemma-3-27B-IT (1B–27B). The Qwen 3.5 series (Qwen, 2026) provides four thinking-capable sizes evaluated with thinking disabled: Qwen3.5-2B, Qwen3.5-4B, Qwen3.5-9B, and Qwen3.5-27B (2B–27B). For cross-family comparison, we additionally evaluate Llama-3.1-8B-Instruct ...
work page 2026
-
[6]
<System>You are a helpful assistant
Generic encoding(enc_generic) Each letter is presented as a user message under a generic system prompt. <System>You are a helpful assistant. <User>{letter}
-
[7]
<System>[N-back system prompt,N=1] <User>{letter}
N-back encoding(enc_nback) Same format, but under the N-back system prompt (withN=1). <System>[N-back system prompt,N=1] <User>{letter}
-
[8]
Generation averaged(gen_averaged) Each letter appears as an assistant-generated response. Five conversations with different user prompts are constructed and hidden states at the assistant token are averaged. <System>You are a helpful assistant. <User>{prompt} <Assistant>{letter} Prompts: “What’s on your mind?”, “What’s the letter on your mind?”, “What is ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.