Recognition: 2 theorem links
· Lean TheoremEDFNet: Early Fusion of Edge and Depth for Thin-Obstacle Segmentation in UAV Navigation
Pith reviewed 2026-05-10 19:00 UTC · model grok-4.3
The pith
Early fusion of RGB, depth and edge maps improves thin-obstacle segmentation for UAVs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EDFNet performs early fusion of RGB, depth, and edge channels and feeds the combined input into U-Net or DeepLabV3 backbones. When evaluated on the DDOS dataset, the pretrained RGBDE U-Net records the top Thin-Structure Evaluation Score of 0.244, mean IoU of 0.219, and boundary IoU of 0.234, with the largest and most consistent gains appearing in boundary-sensitive and recall metrics across the tested configurations.
What carries the argument
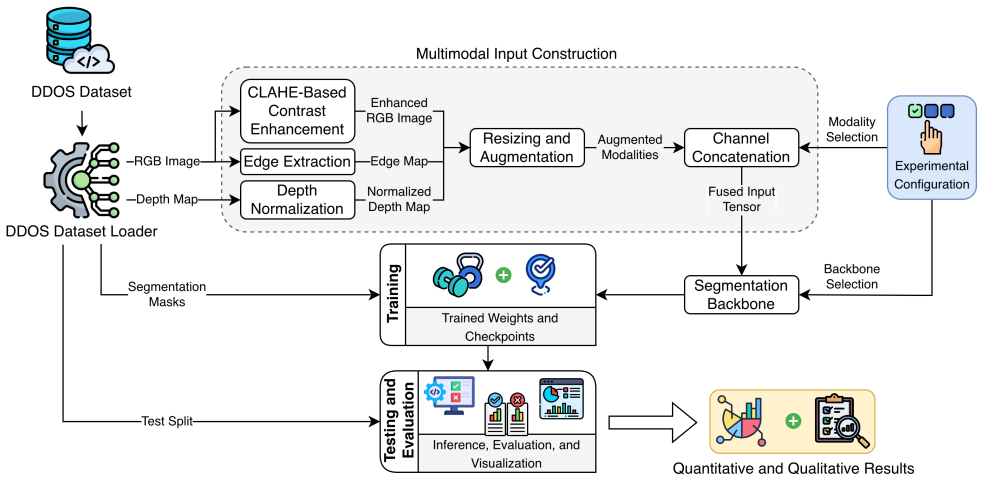
Early RGB-Depth-Edge (RGBDE) fusion, which concatenates the three modalities at the network input so that complementary cues are processed jointly from the first layer onward.
If this is right
- Early RGB-Depth-Edge fusion produces the most stable gains on boundary IoU and recall for thin structures.
- Pretrained backbones outperform randomly initialized ones in every modality combination tested.
- Ultra-thin obstacle categories still yield low performance across all models, leaving reliable detection of the thinnest objects unsolved.
- The RGBDE U-Net configuration maintains competitive runtime at 19.62 FPS on standard evaluation hardware.
Where Pith is reading between the lines
- The same early-fusion pattern could be tested on other aerial datasets that include power lines or thin vegetation to check generalization beyond DDOS.
- Adding temporal information from consecutive frames might help recover ultra-thin structures that remain difficult in single-frame segmentation.
- The modular design allows swapping in newer backbones while keeping the RGBDE input stage fixed, offering a low-cost way to measure progress on thin-obstacle tasks.
Load-bearing premise
That the measured improvements arise specifically from the complementary information supplied by early multimodal fusion rather than from differences in training schedules or dataset biases.
What would settle it
Reproduce the exact sixteen configurations while replacing early fusion with late fusion or single-modality baselines and check whether the boundary IoU and Thin-Structure Evaluation Score fall below the reported RGBDE U-Net values.
Figures

read the original abstract
Autonomous Unmanned Aerial Vehicles (UAVs) must reliably detect thin obstacles such as wires, poles, and branches to navigate safely in real-world environments. These structures remain difficult to perceive because they occupy few pixels, often exhibit weak visual contrast, and are strongly affected by class imbalance. Existing segmentation methods primarily target coarser obstacles and do not fully exploit the complementary multimodal cues needed for thin-structure perception. We present EDFNet, a modular early-fusion segmentation framework that integrates RGB, depth, and edge information for thin-obstacle perception in cluttered aerial scenes. We evaluate EDFNet on the Drone Depth and Obstacle Segmentation (DDOS) dataset across sixteen modality-backbone configurations using U-Net and DeepLabV3 in pretrained and non-pretrained settings. The results show that early RGB-Depth-Edge fusion provides a competitive and well-balanced baseline, with the most consistent gains appearing in boundary-sensitive and recall-oriented metrics. The pretrained RGBDE U-Net achieves the best overall performance, with the highest Thin-Structure Evaluation Score (0.244), mean IoU (0.219), and boundary IoU (0.234), while maintaining competitive runtime performance (19.62 FPS) on our evaluation hardware. However, performance on the rarest ultra-thin categories remains low across all models, indicating that reliable ultra-thin segmentation is still an open challenge. Overall, these findings position early RGB-Depth-Edge fusion as a practical and modular baseline for thin-obstacle segmentation in UAV navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EDFNet, a modular early-fusion segmentation network that integrates RGB, depth, and edge modalities for thin-obstacle detection (wires, poles, branches) in UAV navigation. It evaluates the framework on the DDOS dataset across sixteen modality-backbone configurations (U-Net and DeepLabV3, pretrained and non-pretrained), reporting that early RGB-Depth-Edge fusion yields the most consistent gains in boundary-sensitive and recall-oriented metrics, with the pretrained RGBDE U-Net achieving the highest Thin-Structure Evaluation Score (0.244), mean IoU (0.219), and boundary IoU (0.234) while running at 19.62 FPS.
Significance. If the empirical results hold after addressing the ablation gap, the work supplies a practical, modular baseline for thin-structure perception in cluttered aerial scenes—an important safety component for UAVs where class imbalance and weak contrast make standard segmentation unreliable. The focus on boundary IoU and recall metrics, together with the runtime numbers, directly supports deployability claims.
major comments (2)
- [Experiments] Experiments section: the manuscript evaluates sixteen modality-backbone combinations but provides no ablation that isolates the early-fusion operator itself (e.g., simple channel-wise concatenation versus a learned early-fusion module, or early versus late fusion). Without such controls it remains possible that performance differences arise from the sheer increase in input channels or from pretraining rather than from complementary multimodal cues, weakening the central claim that early RGB-Depth-Edge fusion is the source of the observed gains.
- [Results] Results and Tables: no error bars, standard deviations across runs, or statistical significance tests accompany the reported metrics (Thin-Structure Evaluation Score, mIoU, boundary IoU). Given the high variability typical of thin-structure segmentation on imbalanced data, single-point estimates limit the strength of the cross-configuration comparisons.
minor comments (2)
- [Methods] Methods: the exact early-fusion implementation (concatenation order, normalization, or any learned projection) is only sketched; a diagram or pseudocode would improve reproducibility.
- [Abstract] Abstract and Introduction: the claim that 'performance on the rarest ultra-thin categories remains low across all models' is important but would benefit from a per-category breakdown table to quantify the remaining open challenge.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements, which will strengthen the empirical support for our claims about early RGB-Depth-Edge fusion.
read point-by-point responses
-
Referee: Experiments section: the manuscript evaluates sixteen modality-backbone combinations but provides no ablation that isolates the early-fusion operator itself (e.g., simple channel-wise concatenation versus a learned early-fusion module, or early versus late fusion). Without such controls it remains possible that performance differences arise from the sheer increase in input channels or from pretraining rather than from complementary multimodal cues, weakening the central claim that early RGB-Depth-Edge fusion is the source of the observed gains.
Authors: We acknowledge this is a valid limitation in the current experiments. While the 16 configurations demonstrate consistent benefits from adding depth and edge modalities under early fusion (with pretraining controlled separately), we did not ablate the fusion operator itself against alternatives like late fusion or learned fusion modules. This leaves open the possibility that gains stem partly from input dimensionality. In the revised manuscript, we will add targeted ablation studies: (1) replacing channel-wise concatenation with a learned early-fusion module (e.g., 1x1 conv or cross-attention), (2) comparing to late fusion of modality-specific encoders, and (3) a control using duplicated channels to isolate dimensionality effects. These will directly test whether complementary multimodal cues drive the improvements. revision: yes
-
Referee: Results and Tables: no error bars, standard deviations across runs, or statistical significance tests accompany the reported metrics (Thin-Structure Evaluation Score, mIoU, boundary IoU). Given the high variability typical of thin-structure segmentation on imbalanced data, single-point estimates limit the strength of the cross-configuration comparisons.
Authors: We agree that single-run results are insufficient given the known variability in thin-structure segmentation on imbalanced datasets. The reported numbers reflect single training runs per configuration. In the revision, we will retrain the primary models (U-Net and DeepLabV3 variants, focusing on the top RGBDE configurations) using at least three random seeds and report mean values with standard deviations for Thin-Structure Evaluation Score, mIoU, and boundary IoU. This will allow more reliable cross-configuration comparisons and better quantify variability. revision: yes
Circularity Check
No circularity: purely empirical evaluation with direct ground-truth metrics
full rationale
The paper presents an empirical segmentation framework (EDFNet) and reports performance numbers obtained by training and testing models on the DDOS dataset. No mathematical derivation, parameter fitting, or self-referential equations are present; all reported scores (Thin-Structure Evaluation Score, mIoU, boundary IoU, FPS) are computed directly from model outputs versus human-annotated ground truth. The central claim is therefore a set of measured empirical outcomes rather than a derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EDFNET adopts an early-fusion design in which multiple input modalities are concatenated along the channel dimension before feature extraction... RGBDE combines all three sources of information into a unified five-channel representation.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate EDFNET on the Drone Depth and Obstacle Segmentation (DDOS) dataset across sixteen modality-backbone configurations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aerial autonomy under adversity: Advances in obstacle and aircraft detection techniques for unmanned aerial vehicles,
C. Randieri, S. V . Ganesh, R. D. A. Raj, R. M. R. Yanamala, A. Pallakonda, and C. Napoli, “Aerial autonomy under adversity: Advances in obstacle and aircraft detection techniques for unmanned aerial vehicles,”Drones, vol. 9, no. 8, 2025. [Online]. Available: https://www.mdpi.com/2504-446X/9/8/549
2025
-
[2]
Fast, accurate thin-structure obstacle detection for autonomous mobile robots,
C. Zhou, J. Yang, C. Zhao, and G. Hua, “Fast, accurate thin-structure obstacle detection for autonomous mobile robots,” pp. 318–327, 2017
2017
-
[3]
Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles,
R. Madaan, D. Maturana, and S. Scherer, “Wire detection using synthetic data and dilated convolutional networks for unmanned aerial vehicles,” in2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 3487–3494
2017
-
[4]
Ttpla: An aerial-image dataset for detection and segmentation of transmission towers and power lines,
R. Abdelfattah, X. Wang, and S. Wang, “Ttpla: An aerial-image dataset for detection and segmentation of transmission towers and power lines,” inComputer Vision – ACCV 2020, H. Ishikawa, C.-L. Liu, T. Pajdla, and J. Shi, Eds. Cham: Springer International Publishing, 2021, pp. 601–618
2020
-
[5]
A. L. B. Vieira e Silva, H. de Castro Felix, F. P. M. Sim ˜oes, V . Teichrieb, M. dos Santos, H. Santiago, V . Sgotti, and H. Lott Neto, “Insplad: A dataset and benchmark for power line asset inspection in uav images,”International Journal of Remote Sensing, vol. 44, no. 23, p. 7294–7320, Nov. 2023. [Online]. Available: http: //dx.doi.org/10.1080/01431161...
-
[6]
Fast depth prediction and obstacle avoidance on a monocular drone using probabilistic convolutional neural network,
X. Yang, J. Chen, Y . Dang, H. Luo, Y . Tang, C. Liao, P. Chen, and K.-T. Cheng, “Fast depth prediction and obstacle avoidance on a monocular drone using probabilistic convolutional neural network,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 1, pp. 156–167, 2021
2021
-
[7]
Depthcut: improved depth edge estimation using multiple unreliable channels,
P. Guerrero, H. Winnem ¨oller, W. Li, and N. J. Mitra, “Depthcut: improved depth edge estimation using multiple unreliable channels,” Vis. Comput., vol. 34, no. 9, p. 1165–1176, Sep. 2018. [Online]. Available: https://doi.org/10.1007/s00371-018-1551-5
-
[8]
Swinnet: Swin transformer drives edge-aware rgb-d and rgb-t salient object detection,
Z. Liu, Y . Tan, Q. He, and Y . Xiao, “Swinnet: Swin transformer drives edge-aware rgb-d and rgb-t salient object detection,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 7, pp. 4486– 4497, 2022
2022
-
[9]
Stn plad: A dataset for multi-size power line assets detection in high-resolution uav images,
A. L. B. Vieira-e Silva, H. de Castro Felix, T. de Menezes Chaves, F. P. M. Sim˜oes, V . Teichrieb, M. M. dos Santos, H. da Cunha Santiago, V . A. C. Sgotti, and H. B. D. T. L. Neto, “Stn plad: A dataset for multi-size power line assets detection in high-resolution uav images,” in2021 34th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), 2...
2021
-
[10]
Ddos: The drone depth and obsta- cle segmentation dataset,
B. Kolbeinsson and K. Mikolajczyk, “Ddos: The drone depth and obsta- cle segmentation dataset,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024, pp. 7328– 7337
2024
-
[11]
Ddos dataset,
B. Kolbeinsson, “Ddos dataset,” https://huggingface.co/datasets/ benediktkol/DDOS, 2025, accessed: 2025-09-22
2025
-
[12]
Segformer: simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: simple and efficient design for semantic segmentation with transformers,” 2021
2021
-
[13]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2022, pp. 1280–1289
2022
-
[14]
Small obstacle avoidance based on rgb-d semantic segmentation,
M. Hua, Y . Nan, and S. Lian, “Small obstacle avoidance based on rgb-d semantic segmentation,”2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 886–894, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:201698455
2019
-
[15]
Uav environmental perception and autonomous obstacle avoidance: A deep learning and depth camera combined solution,
D. Wang, W. Li, X. Liu, N. Li, and C. Zhang, “Uav environmental perception and autonomous obstacle avoidance: A deep learning and depth camera combined solution,”Computers and Electronics in Agriculture, vol. 175, p. 105523, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0168169920303379
2020
-
[16]
Semantic segmentation of uav remote sensing images based on edge feature fusing and multi-level upsampling integrated with deeplabv3+,
X. Li, Y . Li, J. Ai, Z. Shu, J. Xia, and Y . Xia, “Semantic segmentation of uav remote sensing images based on edge feature fusing and multi-level upsampling integrated with deeplabv3+,”PLOS ONE, vol. 18, no. 1, pp. 1–16, January 2023. [Online]. Available: https://ideas.repec.org/a/plo/pone00/0279097.html
2023
-
[17]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,”2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9992–10 002, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:232352874
2021
-
[18]
Transformer fusion for indoor rgb-d semantic segmentation,
Z. Wu, Z. Zhou, G. Allibert, C. Stolz, C. Demonceaux, and C. Ma, “Transformer fusion for indoor rgb-d semantic segmentation,” Computer Vision and Image Understanding, vol. 249, p. 104174, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S1077314224002558
2024
-
[19]
F. Zhou, J. Dai, S. Xia, P. L. Rosin, and Y .-K. Lai,A Survey of RGB-D-Based Semantic Segmentation, ch. Chapter 1.3, pp. 41–67. [Online]. Available: https://www.worldscientific.com/doi/abs/10.1142/ 9789819807154 0003
-
[20]
Contrast-limited adaptive histogram equalization: speed and effective- ness,
S. Pizer, R. Johnston, J. Ericksen, B. Yankaskas, and K. Muller, “Contrast-limited adaptive histogram equalization: speed and effective- ness,” in[1990] Proceedings of the First Conference on Visualization in Biomedical Computing, 1990, pp. 337–345
1990
-
[21]
An isotropic 3×3 image gradient operator,
I. Sobel and G. M. Feldman, “An isotropic 3×3 image gradient operator,”
-
[22]
Available: https://api.semanticscholar.org/CorpusID: 59909525
[Online]. Available: https://api.semanticscholar.org/CorpusID: 59909525
-
[23]
The OpenCV library,
G. Bradski, “The OpenCV library,”Dr. Dobb’s Journal of Software Tools, 2000
2000
-
[24]
Albumentations: Fast and flexible image augmentations,
A. Buslaev, V . I. Iglovikov, E. Khvedchenya, A. Parinov, M. Druzhinin, and A. A. Kalinin, “Albumentations: Fast and flexible image augmentations,”Information, vol. 11, no. 2, 2020. [Online]. Available: https://www.mdpi.com/2078-2489/11/2/125
2020
-
[25]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, N. Navab, J. Horneg- ger, W. M. Wells, and A. F. Frangi, Eds. Cham: Springer International Publishing, 2015, pp. 234–241
2015
-
[26]
Rethinking Atrous Convolution for Semantic Image Segmentation
L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,”ArXiv, vol. abs/1706.05587, 2017. [Online]. Available: https://api.semanticscholar. org/CorpusID:22655199
work page internal anchor Pith review arXiv 2017
-
[27]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,”2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009. [Online]. Available: https://api.semanticscholar.org/CorpusID:57246310
2009
-
[28]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,”2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:206594692
2016
-
[29]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”CoRR, vol. abs/1412.6980, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:6628106
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
The cityscapes dataset for semantic urban scene understanding,
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Be- nenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 3213– 3223
2016
-
[31]
The pascal visual object classes challenge: A retrospective,
M. Everingham, S. M. A. Eslami, L. V . Gool, C. K. I. Williams, J. M. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,”International Journal of Computer Vision, vol. 111, pp. 98 – 136, 2014. [Online]. Available: https: //api.semanticscholar.org/CorpusID:207252270
2014
-
[32]
B. Cheng, R. Girshick, P. Dollar, A. C. Berg, and A. Kirillov, “ Boundary IoU: Improving Object-Centric Image Segmentation Evaluation ,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2021, pp. 15 329–15 337. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.