Recognition: no theorem link
Multi-Granularity Reasoning for Image Quality Assessment via Attribute-Aware Reinforcement Learning to Rank
Pith reviewed 2026-05-10 19:57 UTC · model grok-4.3
The pith
MG-IQA extends RL2R with attribute prompting and a multi-dimensional Thurstone reward model to assess both overall image quality and specific attributes like sharpness in one pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
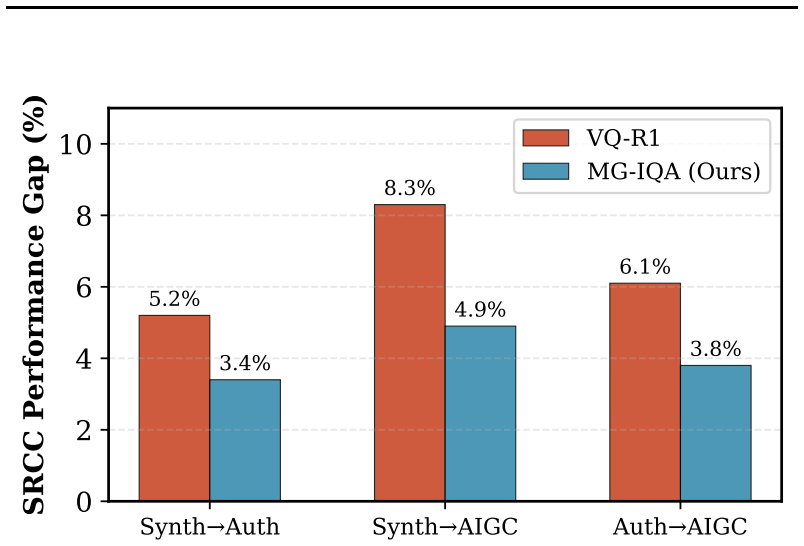
MG-IQA is a multi-granularity reasoning framework that extends reinforcement learning to rank so that a single inference pass on a vision-language model produces both an overall quality score and fine-grained attribute assessments. It achieves this through three components: an attribute-aware prompt that elicits structured reasoning about multiple perceptual dimensions, a multi-dimensional Thurstone reward model that supplies attribute-specific fidelity signals for group relative policy optimization, and a cross-domain alignment mechanism that stabilizes joint training across synthetic, authentic, and AI-generated datasets without perceptual scale re-alignment.
What carries the argument
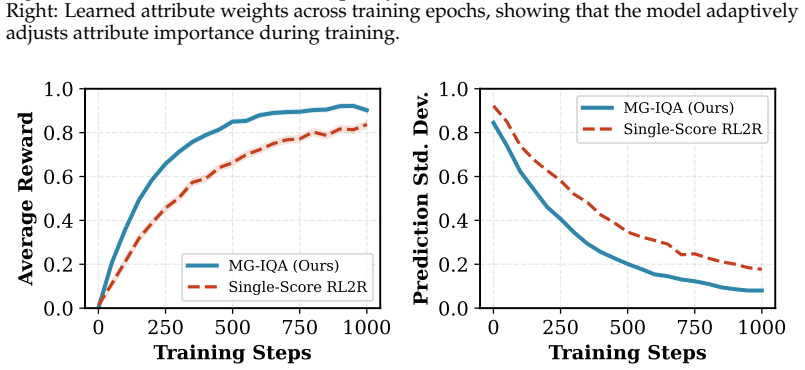
The multi-dimensional Thurstone reward model that computes attribute-specific fidelity rewards for group relative policy optimization, enabled by attribute-aware prompting and cross-domain alignment.
If this is right
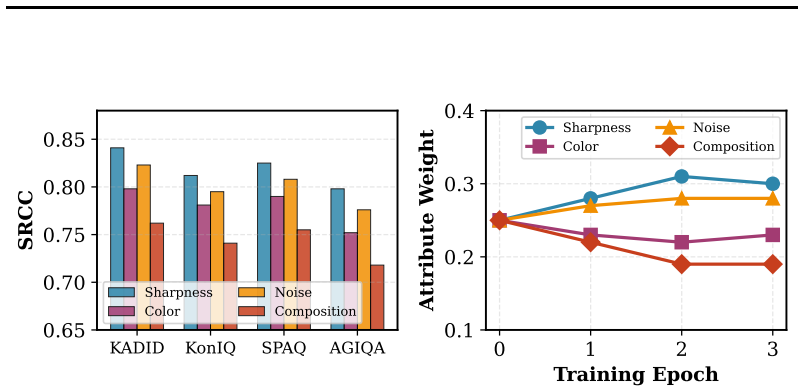
- Average 2.1 percent SRCC gain on overall quality prediction across eight benchmarks
- Measurable gains in accuracy for each attribute-level judgment
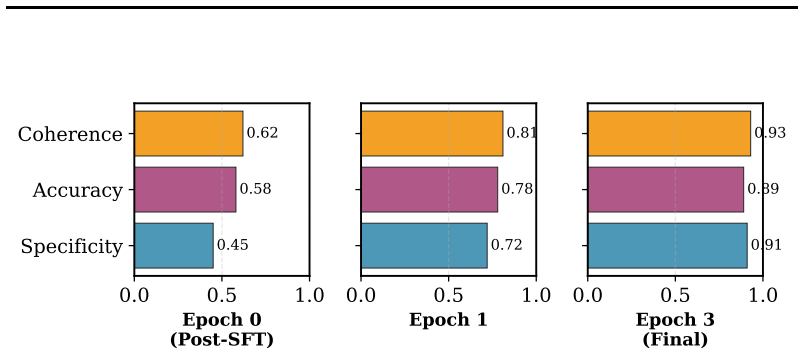
- Production of interpretable, human-aligned textual quality descriptions
- Stable joint training across synthetic distortion, authentic distortion, and AI-generated image collections without extra alignment steps
Where Pith is reading between the lines
- The same attribute-specific reward structure could be reused for other perceptual ranking tasks such as video or audio quality assessment.
- Attribute-level feedback might be fed back directly into generative image models to target corrections on particular dimensions rather than global quality.
- Cross-domain alignment without re-scaling may reduce the data-collection burden when new IQA datasets appear.
Load-bearing premise
The multi-dimensional Thurstone reward model combined with cross-domain alignment accurately captures human perceptual judgments across attributes and datasets without requiring perceptual scale re-alignment.
What would settle it
Human raters separately scoring individual attributes on a fresh image set where each attribute is varied independently; if MG-IQA's attribute predictions then fail to correlate with those ratings while single-granularity baselines do not improve, the joint multi-granularity claim is refuted.
Figures

read the original abstract
Recent advances in reasoning-induced image quality assessment (IQA) have demonstrated the power of reinforcement learning to rank (RL2R) for training vision-language models (VLMs) to assess perceptual quality. However, existing approaches operate at a single granularity, predicting only an overall quality score, while overlooking the multi-dimensional nature of human quality perception, which encompasses attributes such as sharpness, color fidelity, noise level, and compositional aesthetics. In this paper, we propose MG-IQA (Multi-Granularity IQA), a multi-granularity reasoning framework that extends RL2R to jointly assess overall image quality and fine-grained quality attributes within a single inference pass. Our approach introduces three key innovations: (1) an attribute-aware prompting strategy that elicits structured multi-attribute reasoning from VLMs; (2) a multi-dimensional Thurstone reward model that computes attribute-specific fidelity rewards for group relative policy optimization; and (3) a cross-domain alignment mechanism that enables stable joint training across synthetic distortion, authentic distortion, and AI-generated image datasets without perceptual scale re-alignment. Extensive experiments on eight IQA benchmarks demonstrate that MG-IQA consistently outperforms state-of-the-art methods in both overall quality prediction (average SRCC improvement of 2.1\%) and attribute-level assessment, while generating interpretable, human-aligned quality descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MG-IQA, a multi-granularity reasoning framework for image quality assessment that extends reinforcement learning to rank (RL2R) for vision-language models. It incorporates an attribute-aware prompting strategy, a multi-dimensional Thurstone reward model for attribute-specific fidelity rewards, and a cross-domain alignment mechanism to enable joint training across synthetic distortion, authentic distortion, and AI-generated image datasets without perceptual scale re-alignment. The central claims are consistent outperformance of state-of-the-art methods on eight IQA benchmarks, with an average SRCC improvement of 2.1% for overall quality prediction, plus gains in attribute-level assessment and generation of interpretable human-aligned quality descriptions.
Significance. If the performance gains and alignment mechanism are rigorously validated, the work would advance reasoning-induced IQA by unifying overall and multi-attribute assessment in a single VLM inference pass via RL2R. The cross-domain training without re-alignment, if effective, addresses a practical barrier in handling diverse image sources. Credit is given for the broad evaluation across eight benchmarks and the focus on interpretability, which aligns with needs in explainable perceptual modeling.
major comments (3)
- Abstract: The reported average SRCC improvement of 2.1% is presented without error bars, details on dataset splits or runs, statistical significance tests, or implementation specifics for the reward model. This directly undermines verification of the central outperformance claim.
- Method section (multi-dimensional Thurstone reward model and cross-domain alignment): The multi-dimensional extension and alignment mechanism are defined interdependently with the training process, creating a risk of circularity where attribute rewards may reduce to fitted parameters rather than independent predictions of human judgments across attributes.
- Experiments section: The core assumption that attribute-specific perceptual judgments (e.g., sharpness, noise) share commensurate scales and variances across synthetic, authentic, and AI-generated domains without re-alignment lacks explicit validation or ablation. Domain-specific biases could miscalibrate the fidelity rewards, affecting both overall SRCC gains and attribute-level accuracy.
minor comments (2)
- Notation in the reward model equations would benefit from explicit definitions of all variables, including how group-relative policy optimization incorporates the multi-dimensional scores.
- Tables reporting SRCC/PLCC values should include standard deviations or confidence intervals to support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We address each of the major comments below and have updated the manuscript accordingly to improve its rigor and clarity.
read point-by-point responses
-
Referee: Abstract: The reported average SRCC improvement of 2.1% is presented without error bars, details on dataset splits or runs, statistical significance tests, or implementation specifics for the reward model. This directly undermines verification of the central outperformance claim.
Authors: We acknowledge the lack of these details in the abstract. To address this, we have revised the manuscript to include error bars from multiple runs in the results tables, detailed the dataset splits and experimental runs in Section 4, added statistical significance tests in the experiments, and provided implementation specifics for the reward model in Section 3.2 and the supplementary material. revision: yes
-
Referee: Method section (multi-dimensional Thurstone reward model and cross-domain alignment): The multi-dimensional extension and alignment mechanism are defined interdependently with the training process, creating a risk of circularity where attribute rewards may reduce to fitted parameters rather than independent predictions of human judgments across attributes.
Authors: While we understand the concern about potential circularity, the multi-dimensional Thurstone reward model is derived from independent human judgment data for each attribute, as the Thurstone model parameters are estimated from pairwise preference annotations collected from human raters. The cross-domain alignment mechanism operates on these pre-estimated parameters to normalize scales without involving the RL training loop in the reward computation itself. We have added a paragraph in Section 3.2 clarifying this independence and included an analysis showing correlation between the computed rewards and held-out human attribute ratings to demonstrate they are not reduced to fitted parameters from the policy optimization. revision: partial
-
Referee: Experiments section: The core assumption that attribute-specific perceptual judgments (e.g., sharpness, noise) share commensurate scales and variances across synthetic, authentic, and AI-generated domains without re-alignment lacks explicit validation or ablation. Domain-specific biases could miscalibrate the fidelity rewards, affecting both overall SRCC gains and attribute-level accuracy.
Authors: We agree that explicit validation of the scale commensurability assumption is important. In the revised manuscript, we have added an ablation study in Section 4.4 that evaluates the impact of the cross-domain alignment by comparing aligned vs. unaligned training. The results show that alignment improves overall performance and enhances attribute accuracy, particularly for AI-generated images. Furthermore, we include a cross-domain correlation analysis on a small set of images assessed across domains, supporting the assumption of shared scales. We note that while more extensive human studies could further validate this, the current evidence from the ablations supports the approach. revision: yes
Circularity Check
No significant circularity; method innovations are externally validated
full rationale
The paper introduces an attribute-aware prompting strategy, multi-dimensional Thurstone reward model, and cross-domain alignment as design choices within an RL2R framework for IQA. These components are presented as extensions to enable joint training and multi-granularity assessment, with performance claims resting on empirical SRCC improvements across eight benchmarks rather than any self-referential derivation. No equations or sections in the provided text reduce a prediction or reward to a fitted input by construction, nor do self-citations serve as load-bearing uniqueness theorems. The Thurstone model is invoked as a standard tool, and cross-domain alignment is described as a mechanism to avoid re-alignment, but without internal reduction to the training targets themselves. This is the common case of an independent empirical method.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-dimensional Thurstone model can be extended to compute attribute-specific fidelity rewards that align with human perception
- ad hoc to paper Cross-domain alignment mechanism stabilizes joint training across synthetic, authentic, and AI-generated datasets without scale re-alignment
Reference graph
Works this paper leans on
-
[1]
doi: 10.1109/TIP .2012.2214050. Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. Making a “completely blind” image quality analyzer.IEEE Signal Processing Letters, 20(3):209–212, 2013. Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. MUSIQ: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference...
work page doi:10.1109/tip 2012
-
[2]
Sharpness: Assess clarity, edge definition, and detail
-
[3]
Color Fidelity: Evaluate color accuracy and naturalness
-
[4]
Noise Level: Identify noise, artifacts, or compression
-
[5]
After analyzing each attribute, provide an overall quality assessment that synthesizes your findings
Composition: Judge aesthetic arrangement and balance. After analyzing each attribute, provide an overall quality assessment that synthesizes your findings. Format your response as: <think> [Sharpness analysis] [Color Fidelity analysis] [Noise Level analysis] [Composition analysis] [Overall synthesis] </think> Sharpness: [1-5], Color: [1-5], Noise: [1-5], ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.