Recognition: 3 theorem links
· Lean TheoremThe Myth of Expert Specialization in MoEs: Why Routing Reflects Geometry, Not Necessarily Domain Expertise
Pith reviewed 2026-05-10 17:49 UTC · model grok-4.3
The pith
Because MoE routers are linear, expert usage similarity is fully determined by hidden-state similarity, making apparent specialization an emergent property of the model's representation geometry rather than any domain-specific expertise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Since MoE routers are linear maps, hidden state similarity is both necessary and sufficient to explain expert usage similarity, and specialization is therefore an emergent property of the representation space, not of the routing architecture itself. This relation holds at token and sequence levels in five pre-trained models. The load-balancing loss is shown to suppress shared hidden-state directions in order to maintain routing diversity, offering a possible explanation for collapse under low-diversity training regimes such as small batches. Despite the clean mechanistic story, specialization patterns resist human interpretation: expert overlap across models on the same question is no higher
What carries the argument
Linear router maps that equate expert-activation similarity with hidden-state similarity via dot-product geometry.
If this is right
- Load-balancing loss preserves routing diversity by actively suppressing directions that would otherwise be shared across many hidden states.
- Specialization patterns are expected to collapse when training data lack diversity, such as in small-batch regimes.
- Prompt-level routing decisions do not reliably predict the routing observed over a full generated sequence.
- Deeper layers tend to activate nearly identical experts even for semantically unrelated inputs, especially in reasoning-oriented models.
Where Pith is reading between the lines
- Interpretability work on MoEs may gain more by intervening on representation geometry than by redesigning the router itself.
- The same linear-map argument could extend to other gating or routing components whose weights act as linear classifiers over hidden states.
- Scaling laws for MoE efficiency may be separable from any gains in human-interpretable specialization, since the latter depends on the still-open problem of hidden-state geometry.
Load-bearing premise
The linearity of the router together with the geometry of hidden states is sufficient to explain routing behavior without major interference from training dynamics or other non-linear components in the network.
What would settle it
Finding pairs of inputs whose hidden states are highly similar yet receive substantially different expert assignments (or vice versa) in any model whose router is a linear map would falsify the central claim.
Figures


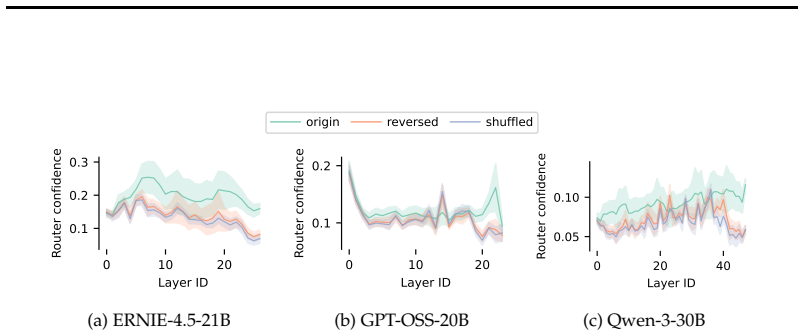






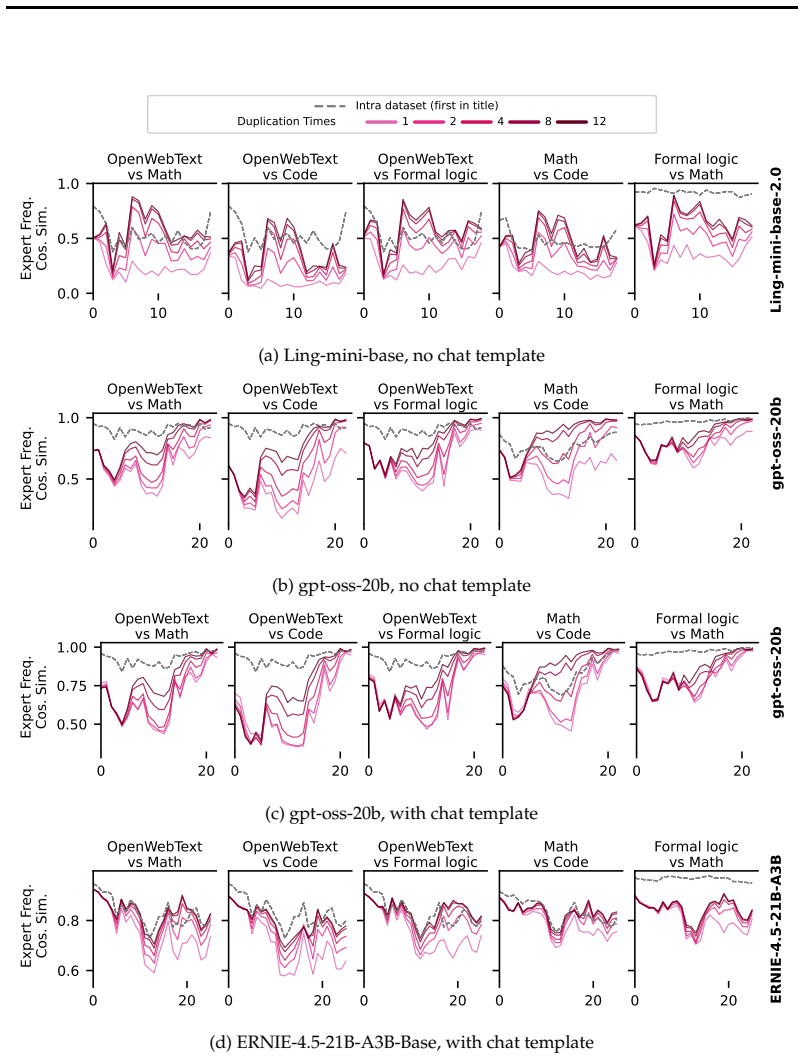







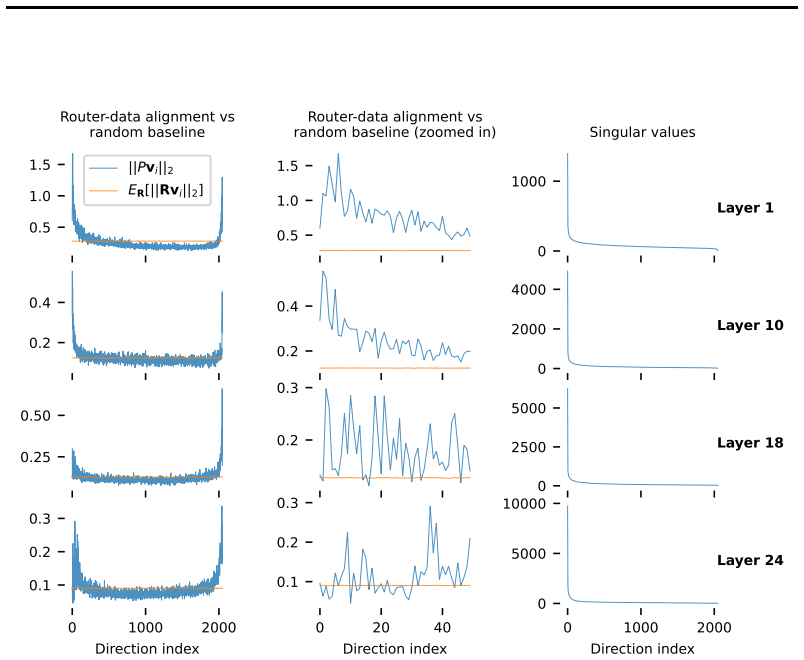


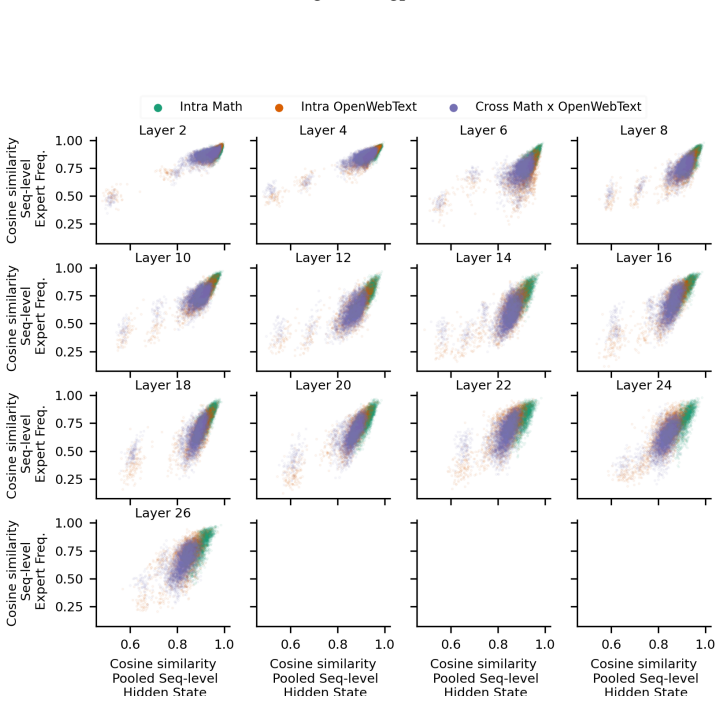

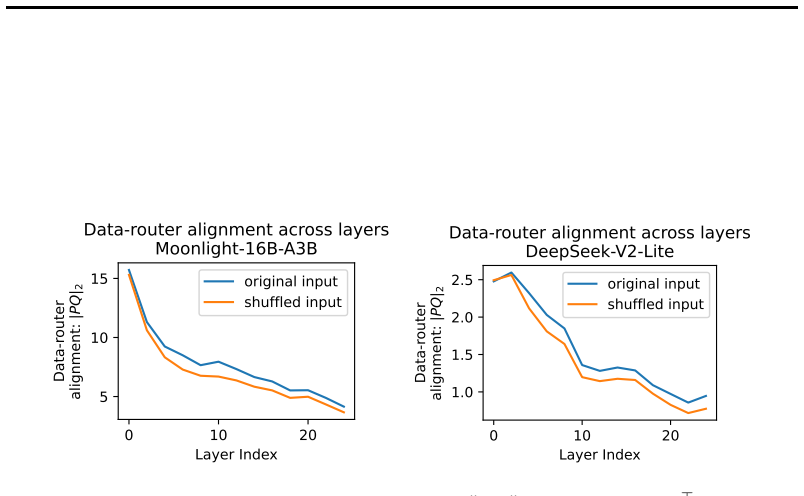
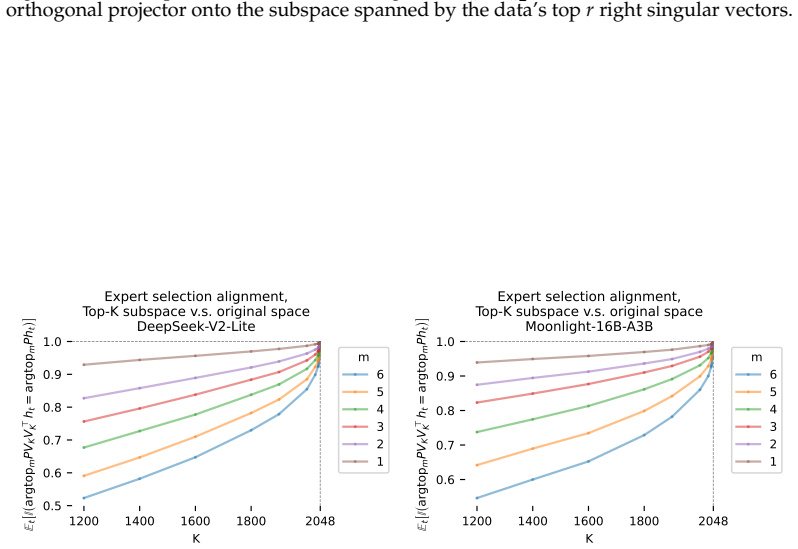





read the original abstract
Mixture of Experts (MoEs) are now ubiquitous in large language models, yet the mechanisms behind their "expert specialization" remain poorly understood. We show that, since MoE routers are linear maps, hidden state similarity is both necessary and sufficient to explain expert usage similarity, and specialization is therefore an emergent property of the representation space, not of the routing architecture itself. We confirm this at both token and sequence level across five pre-trained models. We additionally prove that load-balancing loss suppresses shared hidden state directions to maintain routing diversity, which might provide a theoretical explanation for specialization collapse under less diverse data, e.g. small batch. Despite this clean mechanistic account, we find that specialization patterns in pre-trained MoEs resist human interpretation: expert overlap between different models answering the same question is no higher than between entirely different questions ($\sim$60\%); prompt-level routing does not predict rollout-level routing; and deeper layers exhibit near-identical expert activation across semantically unrelated inputs, especially in reasoning models. We conclude that, while the efficiency perspective of MoEs is well understood, understanding expert specialization is at least as hard as understanding LLM hidden state geometry, a long-standing open problem in the literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that because MoE routers are linear maps, hidden-state similarity is both necessary and sufficient to explain expert-usage similarity, making apparent expert specialization an emergent property of the learned representation geometry rather than the routing architecture. This is supported by token- and sequence-level empirical checks across five pre-trained models, a proof that load-balancing losses suppress shared hidden-state directions to preserve routing diversity, and negative results showing that specialization patterns resist human interpretation (expert overlap ~60% across models or questions, poor prompt-to-rollout prediction, and near-uniform deep-layer activations for unrelated inputs).
Significance. If the central equivalence holds after clarification, the work supplies a mechanistic account of MoE routing grounded in linearity and representation geometry, together with a theoretical explanation for specialization collapse under low-diversity regimes. The multi-model empirical validation and the load-balancing proof constitute clear strengths that could redirect research from architectural tweaks toward understanding hidden-state geometry.
major comments (1)
- Abstract and central theoretical claim: the assertion that hidden-state similarity is 'necessary' (as well as sufficient) for expert-usage similarity does not hold in the full space. With router logits = W h where W ∈ ℝ^{E×d} and E ≪ d, W h1 ≈ W h2 (hence similar top-k expert assignments) is equivalent only to (h1 − h2) lying in ker(W), whose dimension is at least d − E ≫ 0. Thus two hidden states can be arbitrarily dissimilar in Euclidean distance yet produce identical router outputs. Expert-usage similarity therefore does not entail full hidden-state similarity, only similarity in the row space of W. This gap directly undermines the claim that specialization is 'not of the routing architecture itself' but purely emergent from representation-space geometry. The sufficiency direction and the load-balancing proof appear independent of this issue.
minor comments (2)
- Empirical sections: the reported confirmation across five models would be strengthened by explicit statements of data exclusion criteria, the precise statistical tests underlying the ~60% overlap figures, and the full derivation of the load-balancing result so that readers can verify the necessity/sufficiency claims.
- Notation: clarify throughout whether 'hidden state similarity' refers to full-space Euclidean distance or to similarity after projection onto the router subspace; the distinction is load-bearing for the necessity direction.
Simulated Author's Rebuttal
We thank the referee for the careful and precise feedback on the central claim. We agree that the necessity direction requires clarification and will revise the manuscript to address this point directly.
read point-by-point responses
-
Referee: Abstract and central theoretical claim: the assertion that hidden-state similarity is 'necessary' (as well as sufficient) for expert-usage similarity does not hold in the full space. With router logits = W h where W ∈ ℝ^{E×d} and E ≪ d, W h1 ≈ W h2 (hence similar top-k expert assignments) is equivalent only to (h1 − h2) lying in ker(W), whose dimension is at least d − E ≫ 0. Thus two hidden states can be arbitrarily dissimilar in Euclidean distance yet produce identical router outputs. Expert-usage similarity therefore does not entail full hidden-state similarity, only similarity in the row space of W. This gap directly undermines the claim that specialization is 'not of the routing architecture itself' but purely emergent from representation-space geometry. The sufficiency direction and the load-balancing proof appear independent of this issue.
Authors: We agree with the referee's observation. Hidden-state similarity in the full Euclidean space is sufficient for similar router outputs but not necessary, as states differing only in ker(W) produce identical logits. We will revise the abstract, introduction, and theoretical discussion to state that expert-usage similarity is governed by similarity of the hidden states' projections onto the row space of W. This does not change the core conclusion: because the router is strictly linear, routing decisions are fully determined by the geometry of the learned hidden states as seen by W, rather than by any non-linear or domain-expertise mechanism internal to the routing architecture. The empirical results across models and the load-balancing proof remain independent of this clarification and continue to support the geometric account. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim follows directly from the architectural fact that MoE routers are linear maps (logits = W h), yielding a mathematical implication about projected hidden-state similarity and expert usage; this is not equivalent to its inputs by construction but is a straightforward consequence of linear algebra. The additional load-balancing result is presented as a proof derived from the properties of the loss function rather than a fit to data or a self-referential citation. No steps match the enumerated circularity patterns: there are no self-definitional equivalences, fitted inputs renamed as predictions, load-bearing self-citations, imported uniqueness theorems, smuggled ansatzes, or renamings of known results. The empirical sections across models are presented as confirmations separate from the theoretical derivations, keeping the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MoE routers are linear maps
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1. … ∥P hi − P hj∥₂ ≤ ∥P Π_r∥₂ ∥hi − hj∥_Πr + ∥P(I−Π_r)(hi − hj)∥₂ (Eq. 4); triangle shape of hidden-state vs logit distances
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 2 (Informal). … near-minimizer of L_bal(P) must satisfy Pμ ≈ Pμ 1 … shared direction does not affect the routing
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hidden state similarity is both necessary and sufficient to explain expert usage similarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
EMO: Pretraining Mixture of Experts for Emergent Modularity
EMO uses document-boundary expert pooling during pretraining to induce emergent semantic modularity in MoE models, allowing 25% expert retention with only 1% performance drop.
-
EMO: Pretraining Mixture of Experts for Emergent Modularity
EMO pretrains MoEs using document boundaries to induce semantic expert specialization, enabling modular subset deployment with minimal accuracy loss unlike standard MoEs.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.