Recognition: unknown
SSA without Dominance for Higher-Order Programs
Pith reviewed 2026-05-10 15:47 UTC · model grok-4.3
The pith
Free-variable sets can replace dominance as the basis for SSA in higher-order programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Phi-functions and function parameters already express data dependencies via their free-variable sets; dominance is therefore unnecessary, and analyses built on it can be recovered more precisely while the same representation works directly for higher-order programs.
What carries the argument
Free-variable sets maintained across a mutable IR, together with the nesting tree constructed from variable dependencies rather than control flow.
If this is right
- Control-flow overapproximation disappears from analyses, so results such as constant propagation become strictly more precise.
- Programs containing closures and first-class functions receive the same SSA treatment without first lowering to an explicit CFG.
- Compiler passes that once required a dominator tree can instead consult the nesting tree built from variable nesting.
- Mutable IR updates remain efficient because free-variable sets can be maintained in log-linear time.
Where Pith is reading between the lines
- Existing SSA-based tools for functional languages could be simplified by dropping dominator computations entirely.
- The nesting tree might serve as a lightweight substitute in other contexts where only variable liveness, not full control order, matters.
- Higher-order SSA could enable direct optimization of languages whose intermediate forms never produce a traditional CFG.
Load-bearing premise
Maintaining free-variable sets during IR mutations is enough to recover every analysis that previously depended on dominance, without loss of precision or need for any further structure.
What would settle it
A higher-order program rewritten in the new IR on which a standard data-flow analysis (such as live-variable or constant-propagation) yields a different result from the same analysis run on an equivalent first-order CFG under dominance.
Figures










read the original abstract
Dominance is a fundamental concept in compilers based on static single assignment (SSA) form. It underpins a wide range of analyses and transformations and defines a core property of SSA: every use must be dominated by its definition. We argue that this reliance on dominance has become increasingly problematic -- both in terms of precision and applicability to modern higher-order languages. First, control flow overapproximates data flow, which makes dominance-based analyses inherently imprecise. Second, dominance is well-defined only for first-order control-flow graphs (CFGs). More critically, higher-order programs violate the assumptions underlying SSA and classic CFGs: without an explicit CFG, the very notion that all uses of a variable must be dominated by its definition loses meaning. We propose an alternative foundation based on free variables. In this view, $\phi$-functions and function parameters directly express data dependencies, enabling analyses traditionally built on dominance while improving precision and naturally extending to higher-order programs. We further present an efficient technique for maintaining free-variable sets in a mutable intermediate representation (IR). For analyses requiring additional structure, we introduce the nesting tree -- a relaxed analogue of the dominator tree constructed from variable dependencies rather than control flow. Our benchmarks demonstrate that the algorithms and data structures presented in this paper scale log-linearly with program size in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that dominance in SSA form is limited in precision (due to control flow overapproximating data flow) and inapplicable to higher-order programs (where explicit CFGs are absent). It proposes replacing dominance with a free-variable foundation in which φ-functions and function parameters directly encode data dependencies, enabling traditional analyses with improved precision and natural extension to higher-order code. The paper presents an efficient algorithm for maintaining free-variable sets in a mutable IR and introduces the nesting tree as a relaxed analogue of the dominator tree constructed from variable dependencies rather than control flow. Benchmarks demonstrate log-linear scaling with program size.
Significance. If the central claims hold, the work could be significant for compiler IR design in higher-order and functional languages by reducing imprecision from dominance and eliminating the need for explicit CFGs. Credit is given for the practical free-variable maintenance technique and for the empirical demonstration of log-linear scalability.
major comments (2)
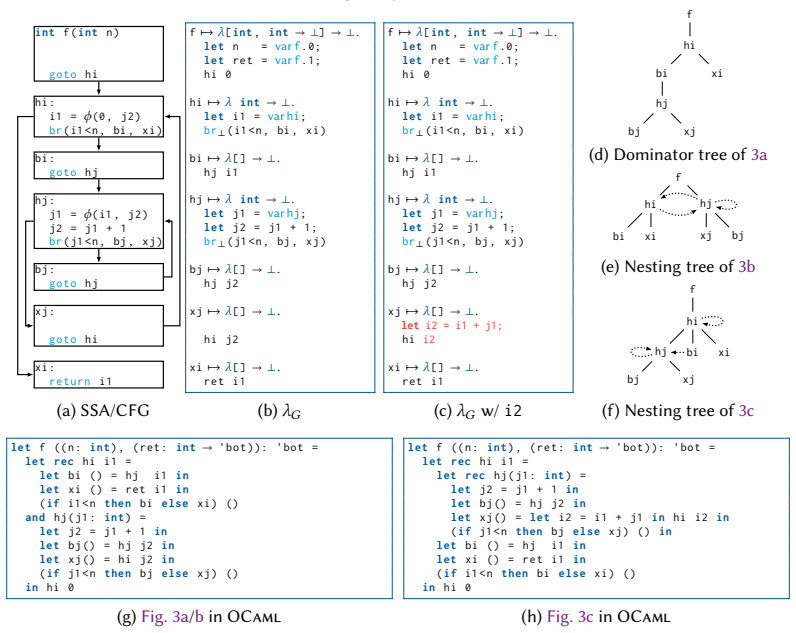
- Abstract and nesting-tree section: the claim that the nesting tree (a relaxed analogue built from variable dependencies) recovers the reachability and ordering properties needed for analyses such as live-variable computation, available expressions, and code-motion transformations is load-bearing for the central thesis, yet no equivalence argument, preservation proof, or counter-example analysis is supplied to bound possible loss of precision in higher-order programs.
- Free-variable maintenance section: the description of incremental free-variable set maintenance in a mutable IR does not address how mutations involving closures or higher-order control are handled without introducing over-approximation or dropped dependencies; this directly affects the claim that the approach extends dominance-based analyses without new imprecision.
minor comments (1)
- Notation for free-variable sets and nesting-tree edges could be clarified with a small running example early in the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our approach to replacing dominance with free-variable sets and the nesting tree in higher-order SSA. We address the major comments below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: Abstract and nesting-tree section: the claim that the nesting tree (a relaxed analogue built from variable dependencies) recovers the reachability and ordering properties needed for analyses such as live-variable computation, available expressions, and code-motion transformations is load-bearing for the central thesis, yet no equivalence argument, preservation proof, or counter-example analysis is supplied to bound possible loss of precision in higher-order programs.
Authors: We agree that a more explicit argument is needed to support the claim that the nesting tree preserves the necessary properties for these analyses. The nesting tree is defined such that a node nests another if there is a free-variable dependency chain, which directly encodes the data-flow reachability without control-flow overapproximation. For live-variable analysis, a variable is live at a point if it appears in the free-variable set of the enclosing scope. We will add a new subsection after the nesting tree definition providing a preservation argument by construction and a brief analysis of potential precision differences in higher-order settings, including an example where dominance would be imprecise but our approach is not. This revision will bound any loss of precision. revision: partial
-
Referee: Free-variable maintenance section: the description of incremental free-variable set maintenance in a mutable IR does not address how mutations involving closures or higher-order control are handled without introducing over-approximation or dropped dependencies; this directly affects the claim that the approach extends dominance-based analyses without new imprecision.
Authors: The incremental maintenance algorithm handles higher-order constructs by treating closure creations as introducing new free-variable sets that are computed from the captured variables and updated on mutations to the closure body or environment. Dependencies are not dropped because updates propagate through the nesting tree to all affected free-variable sets. However, we acknowledge the description in the current manuscript is brief and does not include explicit handling for higher-order control mutations. We will revise this section to include detailed pseudocode and an example demonstrating mutation of a closure without introducing over-approximation. revision: yes
Circularity Check
No circularity; conceptual re-foundation with no fitted quantities or self-referential reductions
full rationale
The paper presents a direct proposal to replace dominance with free-variable tracking and a nesting tree in SSA for higher-order programs. No equations, parameters fitted to data subsets, or 'predictions' appear that reduce by construction to the inputs. The nesting tree is explicitly introduced as a new, relaxed structure rather than derived from prior results. No load-bearing self-citations or uniqueness theorems from the authors' own prior work are invoked to force the choice. Benchmarks report empirical scaling behavior, which is independent of the foundational claim. The derivation chain is therefore self-contained as an alternative foundation without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Higher-order programs violate the assumptions underlying SSA and classic CFGs
- domain assumption φ-functions and function parameters directly express data dependencies
invented entities (1)
-
nesting tree
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Andrew W. Appel. 1992.Compiling with Continuations. Cambridge University Press
1992
- [2]
-
[3]
Zena M. Ariola and Jan Willem Klop. 1996. Equational Term Graph Rewriting.Fundam. Informaticae26, 3/4 (1996), 207–240. doi:10.3233/FI-1996-263401
-
[4]
Saurabh Bhat and Yuheng Niu. 2023. (Correctly) Extending Dominance to MLIR Regions. InLLVM Develop- ers’ Meeting 2023. San Diego, California, USA. https://www.llvm.org/devmtg/2023-10/slides/techtalks/Bhat-Niu- ExtendingDominanceToMLIRRegions.pdf Presentation slides
2023
-
[5]
Matthias Braun, Sebastian Buchwald, Sebastian Hack, Roland Leißa, Christoph Mallon, and Andreas Zwinkau. 2013. Simple and Efficient Construction of Static Single Assignment Form. InCompiler Construction - 22nd International Conference, CC 2013, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2013, Rome, Italy, Marc...
-
[6]
Cooper, Timothy J
Preston Briggs, Keith D. Cooper, Timothy J. Harvey, and L. Taylor Simpson. 1998. Practical Improvements to the Construction and Destruction of Static Single Assignment Form.Softw. Pract. Exp.28, 8 (1998), 859–881
1998
-
[7]
Cliff Click and Keith D. Cooper. 1995. Combining Analyses, Combining Optimizations.ACM Trans. Program. Lang. Syst.17, 2 (1995), 181–196. doi:10.1145/201059.201061
-
[8]
Jesper Cockx. 2021. 1001 Representations of Syntax with Binding. https://jesper.sikanda.be/posts/1001-syntax- representations.html. Blog post, November 4, 2021
2021
-
[9]
Keith Cooper, Timothy Harvey, and Ken Kennedy. 2006. A Simple, Fast Dominance Algorithm.Rice University, CS Technical Report 06-33870(01 2006)
2006
-
[10]
Cooper, Timothy J
Keith D. Cooper, Timothy J. Harvey, and Ken Kennedy. 2004.Iterative Data-flow Analysis, Revisited. Technical Report. Department of Computer Science, Rice University. Available from Rice University
2004
-
[11]
Ron Cytron, Jeanne Ferrante, Barry K. Rosen, Mark N. Wegman, and F. Kenneth Zadeck. 1991. Efficiently Computing Static Single Assignment Form and the Control Dependence Graph.ACM Trans. Program. Lang. Syst.13, 4 (1991), 451–490. doi:10.1145/115372.115320
-
[12]
Delphine Demange, Yon Fernández de Retana, and David Pichardie. 2018. Semantic reasoning about the sea of nodes. InProceedings of the 27th International Conference on Compiler Construction, CC 2018, February 24-25, 2018, Vienna, Austria, Christophe Dubach and Jingling Xue (Eds.). ACM, 163–173. doi:10.1145/3178372.3179503
-
[13]
Philipp Fent, Guido Moerkotte, and Thomas Neumann. 2023. Asymptotically Better Query Optimization Using Indexed Algebra.Proc. VLDB Endow.16, 11 (2023), 3018–3030. doi:10.14778/3611479.3611505
-
[14]
Sebastian Hack, Daniel Grund, and Gerhard Goos. 2006. Register Allocation for Programs in SSA-Form. InCompiler Construction, 15th International Conference, CC 2006 , Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2006, Vienna, Austria, March 30-31 , 2006, Proceedings (Lecture Notes in Computer Science, Vol. 3923),...
-
[15]
John B. Kam and Jeffrey D. Ullman. 1976. Global Data Flow Analysis and Iterative Algorithms.J. ACM23, 1 (1976), 158–171. doi:10.1145/321921.321938
-
[16]
Richard Kelsey. 1995. A Correspondence between Continuation Passing Style and Static Single Assignment Form. In Proceedings ACM SIGPLAN Workshop on Intermediate Representations (IR’95), San Francisco, CA, USA, January 22, 1995. 13–23. doi:10.1145/202529.202532
-
[17]
Andrew Kennedy. 2007. Compiling with continuations, continued. InProceedings of the 12th ACM SIGPLAN International Conference on Functional Programming, ICFP 2007, Freiburg, Germany, October 1-3, 2007, Ralf Hinze and Norman Ramsey (Eds.). ACM, 177–190. doi:10.1145/1291151.1291179 24 Roland Leißa and Johannes Griebler
-
[18]
Piotr Kuderski. 2017. Dominator Trees and incremental updates that transcend time. InLLVM Developers’ Meeting
2017
-
[19]
https://llvm.org/devmtg/2017-10/slides/Kuderski-Dominator_Trees.pdf Presentation slides
San Jose, California, USA. https://llvm.org/devmtg/2017-10/slides/Kuderski-Dominator_Trees.pdf Presentation slides
2017
-
[20]
Chris Lattner and Vikram S. Adve. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. In2nd IEEE / ACM International Symposium on Code Generation and Optimization (CGO 2004), 20-24 March 2004, San Jose, CA, USA. IEEE Computer Society, 75–88. doi:10.1109/CGO.2004.1281665
-
[21]
Mlir: Scaling compiler infrastructure for domain specific computation,
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques A. Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. InIEEE/ACM International Symposium on Code Generation and Optimization, CGO 2021, Seoul, South Korea, February 27 ...
-
[22]
Roland Leißa, Marcel Köster, and Sebastian Hack. 2015. A graph-based higher-order intermediate representation. In Proceedings of the 13th Annual IEEE/ACM International Symposium on Code Generation and Optimization, CGO 2015, San Francisco, CA, USA, February 07 - 11, 2015. 202–212. doi:10.1109/CGO.2015.7054200
-
[23]
Roland Leißa, Marcel Ullrich, Joachim Meyer, and Sebastian Hack. 2025. MimIR: An Extensible and Type-Safe Intermediate Representation for the DSL Age.Proc. ACM Program. Lang.9, POPL (2025), 95–125. doi:10.1145/3704840
-
[24]
2026.Configuring Agentic AI Coding Tools: An Exploratory Study (Supplementary Material)
Roland Leißa and Johannes Griebler. 2026.SSA without Dominance for Higher-Order Programs. doi:10.5281/zenodo. 19069679
-
[25]
Matthieu Lemerre. 2023. SSA Translation Is an Abstract Interpretation.Proc. ACM Program. Lang.7, POPL (2023), 1895–1924. doi:10.1145/3571258
-
[26]
Thomas Lengauer and Robert Endre Tarjan. 1979. A Fast Algorithm for Finding Dominators in a Flowgraph.ACM Trans. Program. Lang. Syst.1, 1 (1979), 121–141. doi:10.1145/357062.357071
-
[27]
Kai Nie, Qinglei Zhou, Hong Qian, Jianmin Pang, Jinlong Xu, and Xiyan Li. 2021. Loop Selection for Multilevel Nested Loops Using a Genetic Algorithm.Mathematical Problems in Engineering2021 (2021), 1–18. doi:10.1155/2021/6643604
-
[28]
1999.Purely functional data structures
Chris Okasaki. 1999.Purely functional data structures. Cambridge University Press
1999
-
[29]
Reese T. Prosser. 1959. Applications of Boolean matrices to the analysis of flow diagrams. InPapers Presented at the December 1-3, 1959, Eastern Joint IRE-AIEE-ACM Computer Conference(Boston, Massachusetts)(IRE-AIEE-ACM ’59 (Eastern)). Association for Computing Machinery, New York, NY, USA, 133–138. doi:10.1145/1460299.1460314
-
[30]
Juan Pedro Bolívar Puente. 2017. Persistence for the masses: RRB-vectors in a systems language.Proc. ACM Program. Lang.1, ICFP (2017), 16:1–16:28. doi:10.1145/3110260
-
[31]
John H. Reif and Harry R. Lewis. 1986. Efficient Symbolic Analysis of Programs.J. Comput. Syst. Sci.32, 3 (1986), 280–314. doi:10.1016/0022-0000(86)90031-0
-
[32]
B. K. Rosen, M. N. Wegman, and F. K. Zadeck. 1988. Global value numbers and redundant computations. InProceedings of the 15th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(San Diego, California, USA) (POPL ’88). Association for Computing Machinery, New York, NY, USA, 12–27. doi:10.1145/73560.73562
-
[33]
2018.A verified compiler for a linear imperative / functional intermediate language
Sigurd Schneider. 2018.A verified compiler for a linear imperative / functional intermediate language. Ph. D. Dissertation. Saarland University, Saarbrücken, Germany. https://publikationen.sulb.uni-saarland.de/handle/20.500.11880/27296
2018
-
[34]
Daniel Dominic Sleator and Robert Endre Tarjan. 1983. A Data Structure for Dynamic Trees.J. Comput. Syst. Sci.26, 3 (1983), 362–391. doi:10.1016/0022-0000(83)90006-5
-
[35]
Daniel Dominic Sleator and Robert Endre Tarjan. 1985. Self-Adjusting Binary Search Trees.J. ACM32, 3 (1985), 652–686. doi:10.1145/3828.3835
-
[36]
Vugranam C. Sreedhar and Guang R. Gao. 1995. A Linear Time Algorithm for Placing phi-nodes. InConference Record of POPL’95: 22nd ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, San Francisco, California, USA, January 23-25, 1995, Ron K. Cytron and Peter Lee (Eds.). ACM Press, 62–73. doi:10.1145/199448.199464
-
[37]
Guy L. Steele. 1978.Rabbit: A Compiler for Scheme. Technical Report. USA
1978
-
[38]
Robert Endre Tarjan. 1972. Depth-First Search and Linear Graph Algorithms.SIAM J. Comput.1, 2 (1972), 146–160. doi:10.1137/0201010
-
[39]
Marcel Ullrich, Sebastian Hack, and Roland Leißa. 2025. MimIrADe: Automatic Differentiation in MimIR. InProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction, CC 2025, Las Vegas, NV, USA, March 1-2, 2025, Daniel Kluss, Sara Achour, and Jens Palsberg (Eds.). ACM, 70–80. doi:10.1145/3708493.3712685
-
[40]
2023.Approaching CPS Soup
Andy Wingo. 2023.Approaching CPS Soup. Igalia, S.L. / wingolog.org. https://wingolog.org/archives/2023/05/20/ approaching-cps-soup Accessed: 2026-02-25
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.