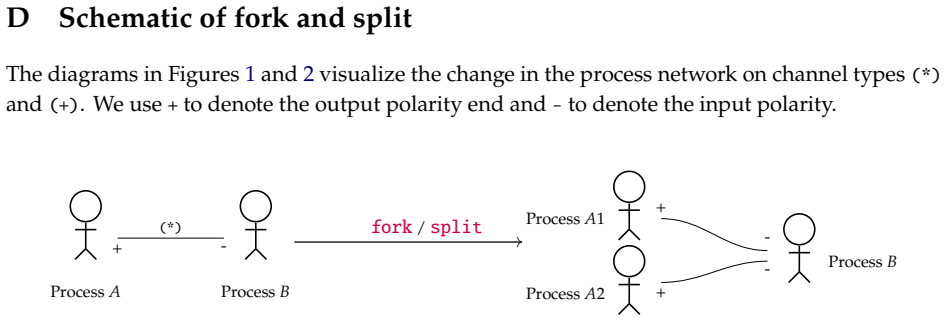
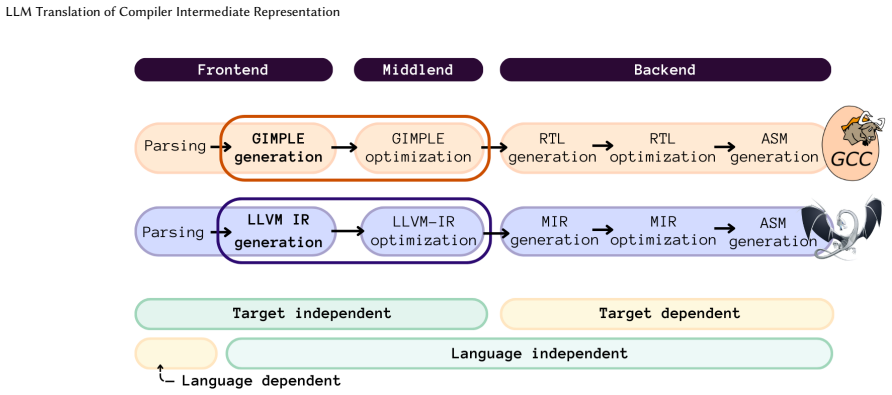
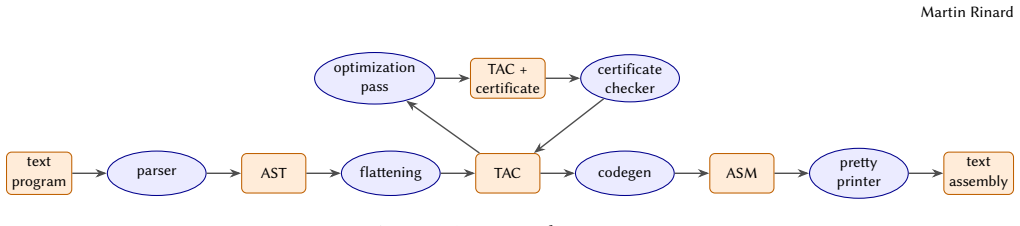
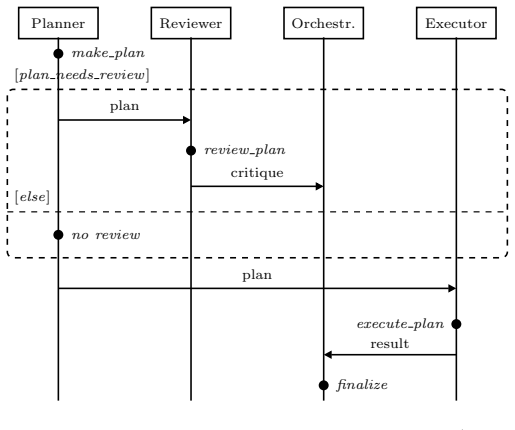
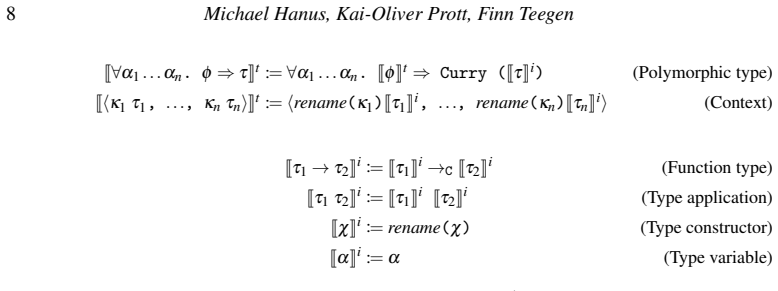0
Categorical triple formalizes LLM agent harness design
Harness Engineering as Categorical Architecture
The (G, Know, Phi) structure maps memory, skills, and protocols to components whose guarantees are preserved by compiler identity and replay
abstract click to expand
The agent harness, the system layer comprising prompts, tools, memory, and orchestration logic that surrounds the model, has emerged as the central engineering abstraction for LLMbased agents. Yet harness design remains ad hoc, with no formal theory governing composition, preservation of properties under compilation, or systematic comparison across frameworks. We show that the categorical Architecture triple (G, Know, Phi) from the ArchAgents framework provides exactly this formalization. The four pillars of agent externalization (Memory, Skills, Protocols, Harness Engineering) map onto the triple's components: Memory as coalgebraic state, Skills as operad-composed objects, Protocols as syntactic wiring G, and the full Harness as the Architecture itself. Structural guarantees-integrity gates, quality-based escalation, supported convergence checks-are Know-level certificates whose preservation is structural replay: our compiler checks identity and verifier replay, not output-layer correctness or model behavior. We validate this correspondence with a reference implementation featuring compiler functors targeting Swarms, DeerFlow, Ralph, Scion, and LangGraph: the four configuration compilers preserve three named certificate types by identity or replay, and LangGraph preserves the same certificates through its shared per-stage execution path. The LangGraph compiler creates one node per stage using the same per-stage method as the native runtime, providing LangGraph-native observability without reimplementing harness logic. An end-to-end escalation experiment with real LLM agents confirms that the quality-based escalation control path is model-parametric in this two-model, one-task experiment. The result positions categorical architecture as the formal theory behind harness engineering.