Recognition: unknown
Muon²: Boosting Muon via Adaptive Second-Moment Preconditioning
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
Muon² preconditions momentum with second moments to accelerate orthogonalization and cut Newton-Schulz iterations by 40 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
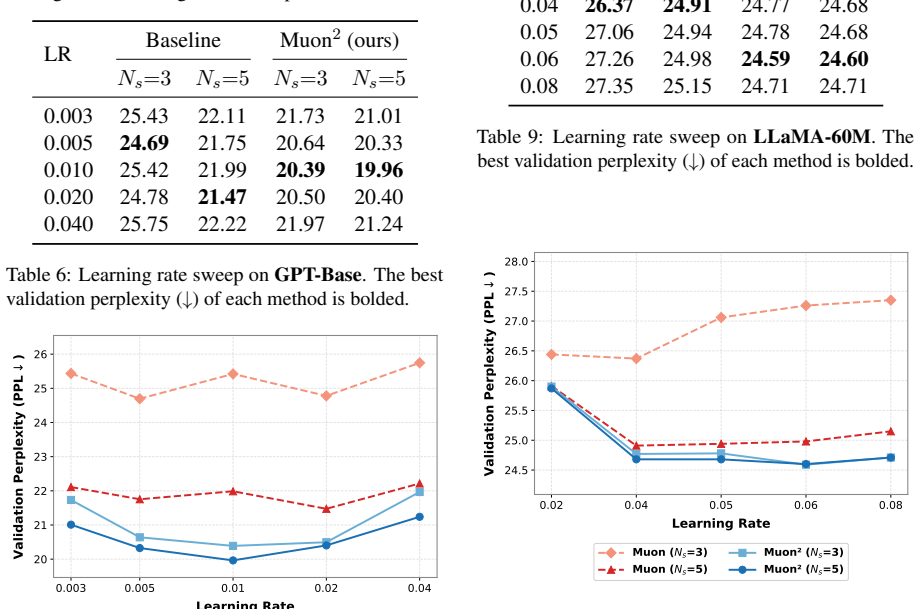
Muon² applies adaptive second-moment preconditioning to the momentum matrix before Newton-Schulz orthogonalization. This step improves the matrix spectrum and thereby accelerates convergence to a practically sufficient orthogonalization quality, measured by directional alignment. The result is better pre-training performance on GPT and LLaMA models across 60M to 1.3B parameters together with a 40 percent reduction in Newton-Schulz iterations per step. The authors also introduce Muon²-F, a memory-efficient factorized form that preserves most of the advantage.
What carries the argument
Adaptive second-moment preconditioning applied to the momentum matrix before Newton-Schulz iterative orthogonalization, which improves conditioning and speeds polar approximation.
If this is right
- Fewer Newton-Schulz iterations per step lower both computation and communication cost during large-scale training.
- Consistent gains appear across GPT and LLaMA architectures and across model sizes from 60M to 1.3B parameters.
- Directional alignment serves as a practical proxy for orthogonalization quality.
- A factorized implementation can retain most benefits while keeping memory overhead negligible.
Where Pith is reading between the lines
- The same preconditioning step could accelerate other iterative matrix approximations used inside optimizers.
- Lower per-step iteration counts may ease scaling of matrix-aware optimizers to models beyond 1.3B parameters.
- Combinations of second-moment preconditioning with alternative orthogonalization schemes remain unexplored and could yield additional savings.
Load-bearing premise
That the spectrum improvement from second-moment preconditioning reliably produces orthogonalization quality sufficient to deliver better end-to-end training performance.
What would settle it
A controlled pre-training run on a 1.3B-parameter LLaMA model in which Muon² with 40 percent fewer Newton-Schulz iterations reaches equal or higher final validation loss than standard Muon under identical settings.
Figures








read the original abstract
Muon has emerged as a promising optimizer for large-scale foundation model pre-training by exploiting the matrix structure of neural network updates through iterative orthogonalization. However, its practical efficiency is limited by the need for multiple Newton--Schulz (NS) iterations per optimization step, which introduces non-trivial computation and communication overhead. We propose Muon$^2$, an extension of Muon that applies Adam-style adaptive second-moment preconditioning before orthogonalization. Our key insight is that the core challenge of polar approximation in Muon lies in the ill-conditioned momentum matrix, of which the spectrum is substantially improved by Muon$^2$, leading to faster convergence toward a practically sufficient orthogonalization. We further characterize the practical orthogonalization quality via directional alignment, under which Muon$^2$ demonstrates dramatic improvement over Muon at each polar step. Across GPT and LLaMA pre-training experiments from 60M to 1.3B parameters, Muon$^2$ consistently outperforms Muon and recent Muon variants while reducing NS iterations by 40\%. We further introduce Muon$^2$-F, a memory-efficient factorized variant that preserves most of the gains of Muon$^2$ with negligible memory overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Muon², an extension of the Muon optimizer that applies Adam-style adaptive second-moment preconditioning to the momentum matrix prior to Newton-Schulz (NS) orthogonalization. The central claim is that this improves the spectrum of the ill-conditioned matrix, yielding faster NS convergence to a practically sufficient orthogonal update (characterized via directional alignment), which in turn produces better end-to-end pre-training performance. Experiments on GPT and LLaMA models (60M–1.3B parameters) report consistent outperformance over Muon and recent variants together with a 40% reduction in required NS iterations; a memory-efficient factorized variant (Muon²-F) is also introduced.
Significance. If the empirical results hold under rigorous controls, the work would be significant for large-scale optimization: it directly targets the computational and communication overhead of iterative orthogonalization in matrix-structured optimizers while preserving or improving training dynamics. The introduction of directional alignment as a practical metric for orthogonalization quality is a useful conceptual contribution. The scale of the reported experiments (up to 1.3B parameters) and the introduction of a low-memory variant add practical value, though the absence of detailed protocols limits immediate assessment of reproducibility.
major comments (2)
- [§5 (Experiments)] §5 (Experiments) and abstract: the headline claims of consistent outperformance across model scales and a 40% reduction in NS iterations are presented without error bars, standard deviations across seeds, or full hyperparameter and baseline implementation details. This is load-bearing for the central empirical claim, as the reader's assessment already notes the lack of verifiable experimental protocol.
- [§3 (Method)] §3 (Method) and §4 (Analysis): the argument that spectrum improvement via second-moment preconditioning produces higher-quality updates rests on directional alignment as a proxy, yet no ablation isolates this mechanism from side-effects such as changes in effective step norms or interactions with the learning-rate schedule. The skeptic's concern is therefore material: the link between alignment gains and end-to-end loss reduction is asserted but not demonstrated to be causal.
minor comments (2)
- [Abstract] Abstract and §4: the phrase 'dramatic improvement' in directional alignment is qualitative; the corresponding figures or tables should report precise quantitative values (e.g., cosine similarity or Frobenius distance to the true polar factor) at each NS step.
- Notation for the preconditioned matrix and the exact NS iteration count used in each experiment should be defined once and used consistently; the current presentation leaves the convergence threshold for 'practically sufficient' orthogonalization implicit.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's recognition of the potential significance of Muon² for large-scale optimization and the value of directional alignment as a metric. We address each major comment below and commit to revisions that strengthen the empirical and mechanistic claims.
read point-by-point responses
-
Referee: §5 (Experiments) and abstract: the headline claims of consistent outperformance across model scales and a 40% reduction in NS iterations are presented without error bars, standard deviations across seeds, or full hyperparameter and baseline implementation details. This is load-bearing for the central empirical claim, as the reader's assessment already notes the lack of verifiable experimental protocol.
Authors: We agree that the lack of error bars, seed-wise standard deviations, and exhaustive protocol details weakens the strength of the reported claims. In the revised version we will re-run the primary GPT and LLaMA experiments (60 M–1.3 B) with at least three independent random seeds, report means and standard deviations for all metrics, add error bars to the relevant figures, and append a detailed experimental protocol section containing full hyperparameter tables, baseline implementation notes, and training schedules. These additions will directly address reproducibility concerns. revision: yes
-
Referee: §3 (Method) and §4 (Analysis): the argument that spectrum improvement via second-moment preconditioning produces higher-quality updates rests on directional alignment as a proxy, yet no ablation isolates this mechanism from side-effects such as changes in effective step norms or interactions with the learning-rate schedule. The skeptic's concern is therefore material: the link between alignment gains and end-to-end loss reduction is asserted but not demonstrated to be causal.
Authors: This point is well taken. While the manuscript analytically shows spectrum improvement and empirically links it to higher directional alignment and better final loss, it does not contain a controlled ablation that holds effective step norm and learning-rate schedule fixed. In revision we will add a targeted ablation subsection that normalizes update norms across Muon and Muon² variants and sweeps learning-rate schedules independently, thereby isolating the contribution of the second-moment preconditioning to alignment quality and training dynamics. revision: yes
Circularity Check
No circularity; empirical claims rest on independent experiments
full rationale
The paper proposes Muon² as a practical extension of Muon that preconditions the momentum matrix with Adam-style second moments to improve spectral conditioning and accelerate Newton-Schulz iterations. The justification is an empirical observation about spectrum improvement and directional alignment, followed by direct pre-training comparisons on GPT and LLaMA models from 60M to 1.3B parameters showing consistent gains and 40% fewer NS steps. No derivation chain exists that reduces a claimed result to a fitted parameter, self-definition, or load-bearing self-citation; all performance assertions are externally verifiable via the reported training runs rather than tautological.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
PolarAdamW: Disentangling Spectral Control and Schur Gauge-Equivariance in Matrix Optimisation
PolarAdamW disentangles spectral control from gauge-equivariance in matrix optimizers, with experiments demonstrating their distinct roles on standard versus symmetry-aware neural networks.
Reference graph
Works this paper leans on
-
[1]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. 2024. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321. Zhengyang Wang, Ziyue Liu, Ruijie Zhang, Avinash Maurya, Paul Hovland, Bogdan Nicolae, Fra...
work page internal anchor Pith review arXiv 2024
-
[2]
Galore: Memory-efficient llm training by gradient low-rank projection.arXiv preprint arXiv:2403.03507. A Discussion on Cosine Similarity To elaborate, cosine similarity [Eq. (15)] is ro- bust against adversarial settings, such as in Eq. (8) where a global scaling exists. Furthermore, it deliv- ers an interpretable measurement that lies in [0,1] which refl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.