Recognition: 2 theorem links
· Lean TheoremWhat and Where to Adapt: Structure-Semantics Co-Tuning for Machine Vision Compression via Synergistic Adapters
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
Coordinated adapters in encoder-decoder and entropy model enable efficient fine-tuning of image codecs for machine vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that effective adapter-based tuning of compression pipelines requires explicit coordination between structural adaptation in the encoder-decoder and semantic adaptation in the entropy model. The Structure-Semantics Co-Tuning framework realizes this by placing a Structural Fidelity Adapter inside the encoder-decoder to fuse spatial and frequency information dynamically and a Semantic Context Adapter inside the entropy model to refine channel context predictions, so that the probability model remains aligned with the modified latent features. Joint optimization converts what would otherwise be performance loss into measurable gains, delivering state-of-the-art results on a
What carries the argument
Structure-Semantics Co-Tuning (S2-CoT) realized by the Structural Fidelity Adapter (SFA) inserted in the encoder-decoder for spatial-frequency fusion and the Semantic Context Adapter (SCA) inserted in the entropy model for channel-context refinement, optimized jointly.
If this is right
- Existing codecs can be adapted for new vision tasks without retraining the entire network.
- Entropy-model statistics must be updated whenever backbone features change, otherwise coding efficiency drops.
- The same coordination principle can be applied to other base codecs beyond the four tested.
- Only a small fraction of parameters need updating to reach near full-tuning quality.
- Joint optimization of the two adapter types converts potential interference into additive gains.
Where Pith is reading between the lines
- The result implies that entropy models act as sensitive statistical mirrors of the backbone; any structural change must be mirrored semantically or rate-distortion suffers.
- The placement rule may generalize to video codecs or learned compression of other modalities where both spatial structure and probability modeling are present.
- Designers of future parameter-efficient methods for generative or reconstruction models should test whether naive insertion harms the distribution predictor before assuming adapters are plug-and-play.
- The observed synergy suggests that explicit cross-module alignment losses or constraints could further reduce the remaining gap to full fine-tuning.
Load-bearing premise
That the specific pairing of a spatial-frequency fusion adapter with a channel-context refinement adapter, when trained together, will consistently overcome the degradation observed from uncoordinated adapter placement.
What would settle it
An experiment on the same four base codecs in which S2-CoT either fails to exceed the performance of naive single-adapter insertion or falls substantially short of full fine-tuning accuracy while still using only a small parameter budget.
Figures




















read the original abstract
Parameter-efficient fine-tuning of pre-trained codecs is a promising direction in image compression for human and machine vision. While most existing works have primarily focused on tuning the feature structure within the encoder-decoder backbones, the adaptation of the statistical semantics within the entropy model has received limited attention despite its function of predicting the probability distribution of latent features. Our analysis reveals that naive adapter insertion into the entropy model can lead to suboptimal outcomes, underscoring that the effectiveness of adapter-based tuning depends critically on the coordination between adapter type and placement across the compression pipeline. Therefore, we introduce Structure-Semantics Co-Tuning (S2-CoT), a novel framework that achieves this coordination via two specialized, synergistic adapters: the Structural Fidelity Adapter (SFA) and the Semantic Context Adapter (SCA). SFA is integrated into the encoder-decoder to preserve high-fidelity representations by dynamically fusing spatial and frequency information; meanwhile, the SCA adapts the entropy model to align with SFA-tuned features by refining the channel context for more efficient statistical coding. Through joint optimization, S2-CoT turns potential performance degradation into synergistic gains, achieving state-of-the-art results across four diverse base codecs with only a small fraction of trainable parameters, closely matching full fine-tuning performance. Code is available at https://github.com/Brock-bit4/S2-CoT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Structure-Semantics Co-Tuning (S2-CoT) as a parameter-efficient fine-tuning framework for pre-trained image codecs targeting machine vision. It identifies that naive adapter placement in the entropy model yields suboptimal results and proposes two coordinated adapters: the Structural Fidelity Adapter (SFA), inserted into the encoder-decoder to dynamically fuse spatial and frequency information for high-fidelity representations, and the Semantic Context Adapter (SCA), applied to the entropy model to refine channel context and align statistical semantics with the SFA-tuned latents. Joint optimization of these adapters is shown to convert potential degradation into gains, delivering state-of-the-art rate-distortion performance across four diverse base codecs while training only a small fraction of parameters and approaching the results of full fine-tuning. Code is released at a public GitHub repository.
Significance. If the reported gains hold under the stated experimental conditions, the work is significant for demonstrating that coordinated structure-semantics adaptation can achieve near full-fine-tuning performance at <<1% parameter cost in learned compression pipelines. The explicit analysis of naive entropy-model adaptation and the synergistic SFA/SCA design fill a gap in existing adapter literature for codecs. Public code availability supports reproducibility and enables direct comparison on additional datasets or tasks.
major comments (2)
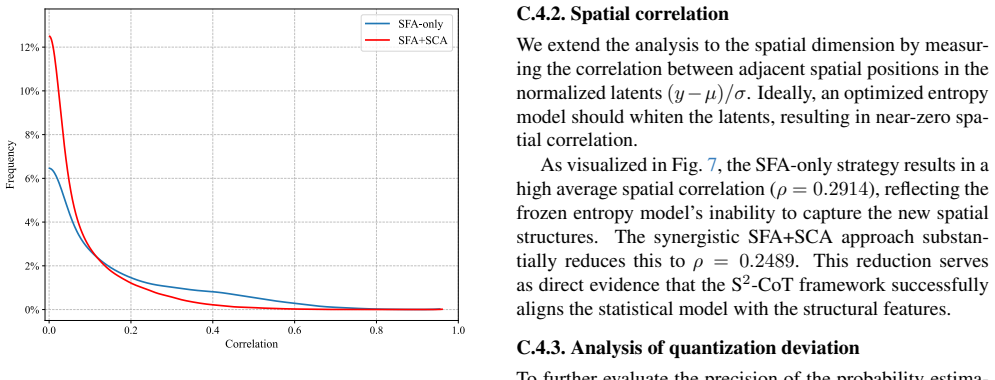
- [§4] §4 (Experiments), Table 2 and Figure 4: the claim of 'closely matching full fine-tuning' is supported by RD curves on four codecs, yet the manuscript does not report per-image or per-dataset variance, confidence intervals, or statistical tests comparing S2-CoT against full fine-tuning; without these, the equivalence cannot be rigorously assessed and the SOTA assertion remains sensitive to post-hoc baseline selection.
- [§3.2] §3.2 (SCA design): the channel-context refinement is described qualitatively, but the precise modification to the entropy model's context model (e.g., which layers receive SCA and how the updated context is fed back into the arithmetic coder) is not formalized; this detail is load-bearing for reproducing the reported bit-rate savings.
minor comments (3)
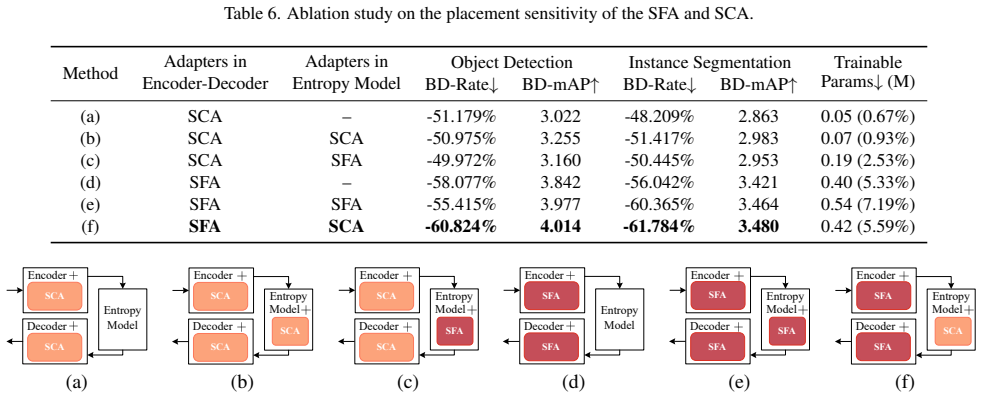
- [Figure 1] Figure 1: the pipeline diagram does not annotate the exact insertion points of SFA and SCA relative to the hyperprior and context model; a clearer overlay would improve readability.
- [§2] §2 (Related Work): the discussion of prior adapter methods in compression omits recent works on entropy-model adaptation (e.g., those using hypernetworks or conditional entropy models); adding 2-3 citations would better situate the novelty of the coordination claim.
- [Abstract] Abstract and §1: the phrase 'small fraction of trainable parameters' is used without a concrete percentage or comparison table in the opening; moving the parameter count summary from §4.1 into the introduction would strengthen the efficiency narrative.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address the two major comments point-by-point below, agreeing to strengthen the manuscript with additional details and analyses while preserving the core contributions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments), Table 2 and Figure 4: the claim of 'closely matching full fine-tuning' is supported by RD curves on four codecs, yet the manuscript does not report per-image or per-dataset variance, confidence intervals, or statistical tests comparing S2-CoT against full fine-tuning; without these, the equivalence cannot be rigorously assessed and the SOTA assertion remains sensitive to post-hoc baseline selection.
Authors: We acknowledge the value of statistical rigor for assessing equivalence. The RD curves in Figure 4 and BD-rate results in Table 2 demonstrate consistent performance of S2-CoT approaching full fine-tuning across four diverse base codecs and multiple datasets, with gains that convert potential degradation into improvements. However, the original manuscript omitted explicit variance, confidence intervals, and formal statistical tests. In revision, we will add error bars (standard deviation across images) to the RD curves in Figure 4, report per-dataset means with standard deviations in Table 2, and include a brief note on the consistency of gains. For baseline selection, we selected representative pre-trained codecs from the literature; the uniform superiority across them supports the SOTA claim. These additions will make the assessment more rigorous without changing the conclusions. revision: yes
-
Referee: [§3.2] §3.2 (SCA design): the channel-context refinement is described qualitatively, but the precise modification to the entropy model's context model (e.g., which layers receive SCA and how the updated context is fed back into the arithmetic coder) is not formalized; this detail is load-bearing for reproducing the reported bit-rate savings.
Authors: We agree that greater formalization will improve reproducibility. Section 3.2 describes the SCA's role in refining channel context to align statistical semantics with SFA-tuned latents, but does not provide equations for the exact layers or integration. In the revised manuscript, we will add a precise description: SCA is inserted into the channel-wise context prediction modules of the entropy model (specifically the hyperprior and autoregressive context networks), with the updated context directly modulating the probability estimation p(ŷ|context) passed to the arithmetic coder. We will include the corresponding mathematical formulation and a schematic. The public code repository already contains the exact implementation, but the paper will now be fully self-contained on this point. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical engineering contribution that proposes Structure-Semantics Co-Tuning (S2-CoT) using two synergistic adapters (SFA in the encoder-decoder and SCA in the entropy model). Central claims rest on experimental RD curves and parameter counts across four base codecs, with code released externally. No equations, predictions, or first-principles derivations are present that reduce reported gains to quantities defined by the same fitted parameters or self-citations. The mention of suboptimal naive entropy-model adapters is framed as experimental motivation rather than a load-bearing assumption or self-referential result.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
S2-CoT framework... Structural Fidelity Adapter (SFA) and Semantic Context Adapter (SCA)... joint optimization... state-of-the-art results across four diverse base codecs with only a small fraction of trainable parameters
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
naive adapter insertion into the entropy model can lead to suboptimal outcomes... coordination between adapter type and placement
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards end- to-end image compression and analysis with transformers
Yuanchao Bai, Xu Yang, Xianming Liu, Junjun Jiang, Yaowei Wang, Xiangyang Ji, and Wen Gao. Towards end- to-end image compression and analysis with transformers. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 104–112, 2022. 1, 2
2022
-
[2]
End- to-end optimized image compression
Johannes Ball ´e, Valero Laparra, and Eero P Simoncelli. End- to-end optimized image compression. InInternational Con- ference on Learning Representations, 2017. 2
2017
-
[3]
Variational image compres- sion with a scale hyperprior
Johannes Ball ´e, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compres- sion with a scale hyperprior. InInternational Conference on Learning Representations, 2018. 2
2018
-
[4]
Jpeg2000 roi coding method with perfect fine-grain accuracy and lossless recov- ery
Joan Bartrina-Rapesta, Joan Serra-Sagrista, Francesc Auli- Llinas, and Juan Munoz Gomez. Jpeg2000 roi coding method with perfect fine-grain accuracy and lossless recov- ery. In2009 Conference Record of the Forty-Third Asilomar Conference on Signals, Systems and Computers, pages 558– 562, 2009. 2
2009
-
[5]
Jean B ´egaint, Fabien Racap ´e, Simon Feltman, and Akshay Pushparaja. Compressai: a pytorch library and evalua- tion platform for end-to-end compression research.arXiv preprint arXiv:2011.03029, 2020. 5
-
[6]
Calculation of average psnr differences between rd-curves
Gisle Bjøntegaard. Calculation of average psnr differences between rd-curves. 2001. 6
2001
-
[7]
Adaptformer: Adapt- ing vision transformers for scalable visual recognition
Shoufa Chen, Chongjian GE, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapt- ing vision transformers for scalable visual recognition. In Advances in Neural Information Processing Systems, pages 16664–16678, 2022. 2
2022
-
[8]
Transtic: Transferring transformer-based image compression from hu- man perception to machine perception
Yi-Hsin Chen, Ying-Chieh Weng, Chia-Hao Kao, Cheng Chien, Wei-Chen Chiu, and Wen-Hsiao Peng. Transtic: Transferring transformer-based image compression from hu- man perception to machine perception. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 23297–23307, 2023. 1, 2, 6, 5
2023
-
[9]
Vision transformer adapter for dense predictions
Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions. InThe Eleventh International Conference on Learning Representations, 2023. 2
2023
-
[10]
Learned image compression with discretized gaussian mixture likelihoods and attention modules
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto. Learned image compression with discretized gaussian mixture likelihoods and attention modules. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7939–7948, 2020. 5, 2, 8, 9, 13
2020
-
[11]
Hyomin Choi and Ivan V . Baji ´c. Scalable image coding for humans and machines.IEEE Transactions on Image Pro- cessing, 31:2739–2754, 2022. 1, 2
2022
-
[12]
C. A. Christopoulos, T. Ebrahimi, and A. N. Skodras. Jpeg2000: the new still picture compression standard. In Proceedings of the 2000 ACM Workshops on Multimedia, page 45–49, 2000. 2
2000
-
[13]
Learned image compression for machine percep- tion.arXiv preprint arXiv:2111.02249, 2021
Felipe Codevilla, Jean Gabriel Simard, Ross Goroshin, and Chris Pal. Learned image compression for machine percep- tion.arXiv preprint arXiv:2111.02249, 2021. 1, 2
-
[14]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 6
2009
-
[15]
Semantically structured image compression via ir- regular group-based decoupling
Ruoyu Feng, Yixin Gao, Xin Jin, Runsen Feng, and Zhibo Chen. Semantically structured image compression via ir- regular group-based decoupling. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17237–17247, 2023. 1
2023
-
[16]
Prompt-icm: A unified framework to- wards image coding for machines with task-driven prompts
Ruoyu Feng, Jinming Liu, Xin Jin, Xiaohan Pan, Heming Sun, and Zhibo Chen. Prompt-icm: A unified framework to- wards image coding for machines with task-driven prompts. arXiv preprint arXiv:2305.02578, 2023. 1
-
[17]
Boosting neural image compression for machines using latent space masking.IEEE Transactions on Circuits and Systems for Video Technology, 35(4):3719–3731, 2025
Kristian Fischer, Fabian Brand, and Andr ´e Kaup. Boosting neural image compression for machines using latent space masking.IEEE Transactions on Circuits and Systems for Video Technology, 35(4):3719–3731, 2025. 1
2025
-
[18]
Weconvene: Learned image compression with wavelet-domain convolution and entropy model
Haisheng Fu, Jie Liang, Zhenman Fang, Jingning Han, Feng Liang, and Guohe Zhang. Weconvene: Learned image compression with wavelet-domain convolution and entropy model. InEuropean Conference on Computer Vision, pages 37–53. Springer, 2024. 2
2024
-
[19]
A unified image compression method for human perception and multiple vision tasks
Sha Guo, Lin Sui, Chenlin Zhang, Zhuo Chen, Wenhan Yang, and Lingyu Duan. A unified image compression method for human perception and multiple vision tasks. In European Conference on Computer Vision, pages 342–359. Springer, 2024. 1, 2
2024
-
[20]
Causal context adjustment loss for learned image compression
Minghao Han, Shiyin Jiang, Shengxi Li, Xin Deng, Mai Xu, Ce Zhu, and Shuhang Gu. Causal context adjustment loss for learned image compression. InAdvances in Neural Informa- tion Processing Systems, pages 133231–133253, 2024. 2
2024
-
[21]
Elic: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding
Dailan He, Ziming Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang. Elic: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5718–5727, 2022. 6, 8, 9, 13
2022
-
[22]
Towards a unified view of parameter-efficient transfer learning
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg- Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. InInternational Con- ference on Learning Representations, 2022. 1
2022
-
[23]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition (CVPR), pages 770–778, 2016. 1, 5
2016
-
[24]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2961–2969,
-
[25]
Squeeze-and-excitation net- works
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7132–7141,
-
[26]
Learned image compression with channel-wise autore- gressive entropy and context modelling
Sofia Iliopoulou, Dimitris Ampeliotis, and Athanassios Sko- dras. Learned image compression with channel-wise autore- gressive entropy and context modelling. In2025 25th In- ternational Conference on Digital Signal Processing (DSP), pages 1–5, 2025. 1, 2
2025
-
[27]
Deep learning image compression method based on 9 efficient channel-time attention module.Scientific Reports, 15(1):15678, 2025
Xiu Ji, Xiao Yang, Zheyu Yue, Hongliu Yang, and Boyang Zheng. Deep learning image compression method based on 9 efficient channel-time attention module.Scientific Reports, 15(1):15678, 2025. 2
2025
-
[28]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements.arXiv preprint arXiv:2410.17725, 2024. 8
work page internal anchor Pith review arXiv 2024
-
[29]
Context-adaptive entropy model for end-to-end optimized image compression
Jooyoung Lee, Seunghyun Cho, and Seung-Kwon Beack. Context-adaptive entropy model for end-to-end optimized image compression. InInternational Conference on Learn- ing Representations, 2019. 2
2019
-
[30]
Frequency-aware transformer for learned image compression
Han Li, Shaohui Li, Wenrui Dai, Chenglin Li, Junni Zou, and Hongkai Xiong. Frequency-aware transformer for learned image compression. InThe Twelfth International Conference on Learning Representations, 2024. 2
2024
-
[31]
Image compression for machine and human vision with spatial- frequency adaptation
Han Li, Shaohui Li, Shuangrui Ding, Wenrui Dai, Maida Cao, Chenglin Li, Junni Zou, and Hongkai Xiong. Image compression for machine and human vision with spatial- frequency adaptation. InEuropean Conference on Computer Vision, pages 382–399. Springer, 2024. 1, 2, 3, 6, 7, 5, 8
2024
-
[32]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 5
2014
-
[33]
Improving mul- tiple machine vision tasks in the compressed domain
Jinming Liu, Heming Sun, and Jiro Katto. Improving mul- tiple machine vision tasks in the compressed domain. In 2022 26th International Conference on Pattern Recognition (ICPR), pages 331–337, 2022. 1, 6
2022
-
[34]
Composable image coding for machine via task- oriented internal adaptor and external prior
Jinming Liu, Xin Jin, Ruoyu Feng, Zhibo Chen, and Wen- jun Zeng. Composable image coding for machine via task- oriented internal adaptor and external prior. In2023 IEEE In- ternational Conference on Visual Communications and Im- age Processing (VCIP), pages 1–5, 2023. 1, 2
2023
-
[35]
Learned image compression with mixed transformer-cnn architectures
Jinming Liu, Heming Sun, and Jiro Katto. Learned image compression with mixed transformer-cnn architectures. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 14388–14397,
-
[36]
Semantics-to-signal scalable image compression with learned revertible representations.International Journal of Computer Vision, 129(9):2605–2621, 2021
Kang Liu, Dong Liu, Li Li, Ning Yan, and Houqiang Li. Semantics-to-signal scalable image compression with learned revertible representations.International Journal of Computer Vision, 129(9):2605–2621, 2021. 2
2021
-
[37]
Icmh- net: Neural image compression towards both machine vision and human vision
Lei Liu, Zhihao Hu, Zhenghao Chen, and Dong Xu. Icmh- net: Neural image compression towards both machine vision and human vision. InProceedings of the 31st ACM Interna- tional Conference on Multimedia, page 8047–8056, 2023. 1, 6
2023
-
[38]
Region-adaptive transform with segmentation prior for image compression
Yuxi Liu, Wenhan Yang, Huihui Bai, Yunchao Wei, and Yao Zhao. Region-adaptive transform with segmentation prior for image compression. InEuropean conference on com- puter vision, pages 181–197. Springer, 2024. 1, 2
2024
-
[39]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10012–10022, 2021. 1
2021
-
[40]
Learned image compression with dictionary- based entropy model
Jingbo Lu, Leheng Zhang, Xingyu Zhou, Mu Li, Wen Li, and Shuhang Gu. Learned image compression with dictionary- based entropy model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12850–12859, 2025. 8, 9, 13
2025
-
[41]
Transformer-based image compression.arXiv preprint arXiv:2111.06707, 2021
Ming Lu, Peiyao Guo, Huiqing Shi, Chuntong Cao, and Zhan Ma. Transformer-based image compression.arXiv preprint arXiv:2111.06707, 2021. 3, 5, 8, 9
-
[42]
Channel-wise autoregres- sive entropy models for learned image compression
David Minnen and Saurabh Singh. Channel-wise autoregres- sive entropy models for learned image compression. In2020 IEEE International Conference on Image Processing (ICIP), pages 3339–3343, 2020. 1, 2
2020
-
[43]
Joint autoregressive and hierarchical priors for learned image compression
David Minnen, Johannes Ball ´e, and George D Toderici. Joint autoregressive and hierarchical priors for learned image compression. InAdvances in Neural Information Processing Systems, pages 10794–10803, 2018. 2
2018
-
[44]
Lmm-driven se- mantic image-text coding for ultra low-bitrate learned image compression
Shimon Murai, Heming Sun, and Jiro Katto. Lmm-driven se- mantic image-text coding for ultra low-bitrate learned image compression. In2024 IEEE International Conference on Vi- sual Communications and Image Processing (VCIP), pages 1–5, 2024. 2
2024
-
[45]
Test-time fine-tuning of im- age compression models for multi-task adaptability
Unki Park, Seongmoon Jeong, Youngchan Jang, Gyeong- Moon Park, and Jong Hwan Ko. Test-time fine-tuning of im- age compression models for multi-task adaptability. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4430–4440, 2025. 2, 6
2025
-
[46]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. InAdvances in Neural Information Pro- cessing Systems, pages 91–99, 2015. 6, 5
2015
-
[47]
https://doi.org/10.48550/ARXIV.2509.25164
Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, and Manoj Karkee. Yolo26: key architectural enhancements and performance benchmarking for real-time object detection. arXiv preprint arXiv:2509.25164, 2025. 8
-
[48]
Dec-adapter: Exploring efficient decoder-side adapter for bridging screen content and natural image compression
Sheng Shen, Huanjing Yue, and Jingyu Yang. Dec-adapter: Exploring efficient decoder-side adapter for bridging screen content and natural image compression. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12887–12896, 2023. 1, 2
2023
-
[49]
Juan Song, Lijie Yang, and Mingtao Feng. Extremely low-bitrate image compression semantically disentangled by lmms from a human perception perspective.arXiv preprint arXiv:2503.00399, 2025. 2
-
[50]
Uni- versal deep image compression via content-adaptive opti- mization with adapters
Koki Tsubota, Hiroaki Akutsu, and Kiyoharu Aizawa. Uni- versal deep image compression via content-adaptive opti- mization with adapters. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2529–2538, 2023. 2
2023
-
[51]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, pages 5998–6008, 2017. 1
2017
-
[52]
The jpeg still picture compression stan- dard.Communications of the ACM, 34(4):30–44, 1991
Gregory K Wallace. The jpeg still picture compression stan- dard.Communications of the ACM, 34(4):30–44, 1991. 2
1991
-
[53]
End-to- end compression towards machine vision: Network architec- ture design and optimization.IEEE Open Journal of Circuits and Systems, 2:675–685, 2021
Shurun Wang, Zhao Wang, Shiqi Wang, and Yan Ye. End-to- end compression towards machine vision: Network architec- ture design and optimization.IEEE Open Journal of Circuits and Systems, 2:675–685, 2021. 1, 3 10
2021
-
[54]
Enhanced invertible encoding for learned image compression
Yueqi Xie, Ka Leong Cheng, and Qifeng Chen. Enhanced invertible encoding for learned image compression. InPro- ceedings of the 29th ACM International Conference on Mul- timedia, page 162–170, 2021. 3
2021
-
[55]
Yuan Xue, Qi Zhang, Chuanmin Jia, and Shiqi Wang. Ll-icm: Image compression for low-level machine vi- sion via large vision-language model.arXiv preprint arXiv:2412.03841, 2024. 1, 2
-
[56]
Towards coding for human and machine vision: Scalable face image coding.IEEE Transactions on Multime- dia, 23:2957–2971, 2021
Shuai Yang, Yueyu Hu, Wenhan Yang, Ling-Yu Duan, and Jiaying Liu. Towards coding for human and machine vision: Scalable face image coding.IEEE Transactions on Multime- dia, 23:2957–2971, 2021. 1
2021
-
[57]
Unified coding for both human per- ception and generalized machine analytics with clip super- vision
Kangsheng Yin, Quan Liu, Xuelin Shen, Yulin He, Wenhan Yang, and Shiqi Wang. Unified coding for both human per- ception and generalized machine analytics with clip super- vision. InProceedings of the AAAI Conference on Artificial Intelligence, pages 9517–9525, 2025. 1, 2
2025
-
[58]
Mambaic: State space models for high- performance learned image compression
Fanhu Zeng, Hao Tang, Yihua Shao, Siyu Chen, Ling Shao, and Yan Wang. Mambaic: State space models for high- performance learned image compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18041–18050, 2025. 2
2025
-
[59]
All-in-one image coding for joint human-machine vision with multi- path aggregation
Xu Zhang, Peiyao Guo, Ming Lu, and Zhan Ma. All-in-one image coding for joint human-machine vision with multi- path aggregation. InAdvances in Neural Information Pro- cessing Systems, pages 71465–71503, 2024. 1, 2
2024
-
[60]
Jiancheng Zhao, Xiang Ji, and Yinqiang Zheng. All-in-one transferring image compression from human perception to multi-machine perception.arXiv preprint arXiv:2504.12997,
-
[61]
Transformer- based transform coding
Yinhao Zhu, Yang Yang, and Taco Cohen. Transformer- based transform coding. InInternational Conference on Learning Representations, 2022. 3
2022
-
[62]
Renjie Zou, Chunfeng Song, and Zhaoxiang Zhang. The devil is in the details: Window-based attention for image compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17492–17501, 2022. 2 11 What and Where to Adapt: Structure–Semantics Co-Tuning for Machine Vision Compression via Synergistic Adapters S...
-
[63]
Channel Excitation and Bottleneck Projection
-
[64]
Spatial-Frequency Dual-Branch Modulation
-
[65]
"" 4Semantic Context Adapter (SCA). 5
Soft Fusion. 8""" 9 10def __init__(self, in_dim: int = 128, middle_dim: int = 64, r: int = 16, se_factor: float = 1.0, adapt_factor: float = 1.0): 11super().__init__() 12self.adapt_factor = adapt_factor 13 14# Channel 15self.c_squeeze = nn.AdaptiveAvgPool2d(1) 16self.c_excite = nn.Sequential( 17nn.Conv2d(in_dim, in_dim // r, 1, bias=False), 18nn.ReLU(), 1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.