Recognition: unknown
STRONG-VLA: Decoupled Robustness Learning for Vision-Language-Action Models under Multimodal Perturbations
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
A two-stage decoupled fine-tuning process builds robustness to visual and language noise in VLA models before restoring task alignment on clean data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
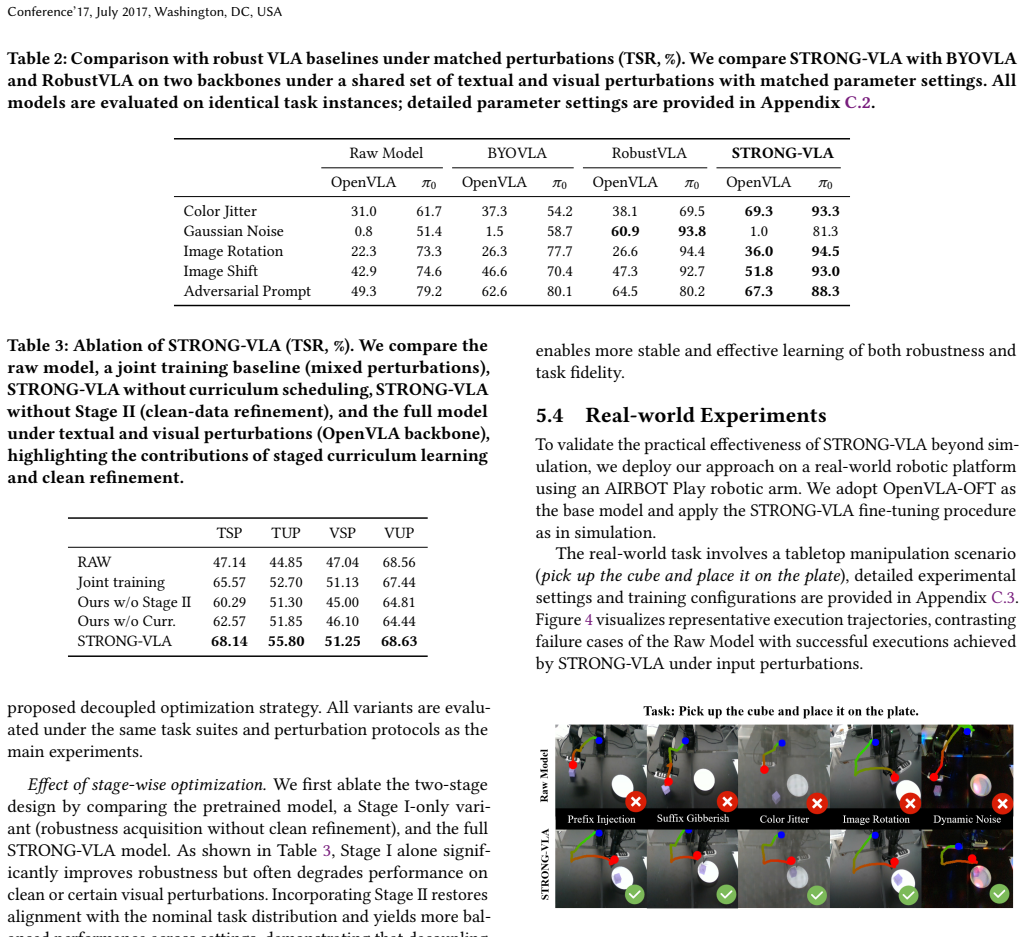
STRONG-VLA decouples robustness acquisition from task refinement by first exposing the model to a curriculum of multimodal perturbations with increasing difficulty to enable progressive robustness learning under controlled distribution shifts, then realigning the model with clean task distributions to recover execution fidelity while preserving robustness. This yields gains of up to 12.60 percent under seen perturbations and 7.77 percent under unseen perturbations on OpenVLA, with comparable or larger improvements on OpenVLA-OFT and pi0, plus real-world validation on an AIRBOT platform.
What carries the argument
The two-stage decoupled fine-tuning framework that separates curriculum-based robustness acquisition under multimodal perturbations from subsequent clean-data realignment.
Load-bearing premise
Robustness acquired during the perturbation curriculum stage is preserved after realignment on clean data without significant forgetting or interference.
What would settle it
Measuring task success rates after Stage II that show no improvement or a drop relative to joint-training baselines on the 28-perturbation benchmark would indicate the separation fails to hold.
Figures







read the original abstract
Despite their strong performance in embodied tasks, recent Vision-Language-Action (VLA) models remain highly fragile under multimodal perturbations, where visual corruption and linguistic noise jointly induce distribution shifts that degrade task-level execution. Existing robustness approaches typically rely on joint training with perturbed data, treating robustness as a static objective, which leads to conflicting optimization between robustness and task fidelity. In this work, we propose STRONG-VLA, a decoupled fine-tuning framework that explicitly separates robustness acquisition from task-aligned refinement. In Stage I, the model is exposed to a curriculum of multimodal perturbations with increasing difficulty, enabling progressive robustness learning under controlled distribution shifts. In Stage II, the model is re-aligned with clean task distributions to recover execution fidelity while preserving robustness. We further establish a comprehensive benchmark with 28 perturbation types spanning both textual and visual modalities, grounded in realistic sources of sensor noise, occlusion, and instruction corruption. Extensive experiments on the LIBERO benchmark show that STRONG-VLA consistently improves task success rates across multiple VLA architectures. On OpenVLA, our method achieves gains of up to 12.60% under seen perturbations and 7.77% under unseen perturbations. Notably, similar or larger improvements are observed on OpenVLA-OFT (+14.48% / +13.81%) and pi0 (+16.49% / +5.58%), demonstrating strong cross-architecture generalization. Real-world experiments on an AIRBOT robotic platform further validate its practical effectiveness. These results highlight the importance of decoupled optimization for multimodal robustness and establish STRONG-VLA as a simple yet principled framework for robust embodied control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STRONG-VLA, a decoupled two-stage fine-tuning framework for Vision-Language-Action (VLA) models to improve robustness to multimodal (visual and linguistic) perturbations. Stage I applies a curriculum of increasing-difficulty perturbations to acquire robustness; Stage II realigns the model on clean task data to recover execution fidelity while aiming to preserve the learned robustness. A 28-type perturbation benchmark is introduced, and experiments on the LIBERO benchmark report consistent task-success gains across OpenVLA (+12.60% seen / +7.77% unseen), OpenVLA-OFT, and pi0, with additional real-robot validation on an AIRBOT platform.
Significance. If the central claim holds, the work provides evidence that explicitly separating robustness acquisition from task realignment can reduce optimization conflicts that arise in joint training, yielding more reliable VLA performance under realistic sensor and instruction noise. The cross-architecture consistency, introduction of a grounded multimodal benchmark, and real-world hardware results would strengthen the case for decoupled robustness methods in embodied AI.
major comments (2)
- [§3 (Method) and §4 (Experiments)] The central claim that robustness acquired in Stage I survives Stage II realignment on clean data is not directly supported by evidence. No before/after robustness metrics on perturbed inputs, no ablation removing Stage I, and no retention mechanisms (e.g., regularization or replay) are reported; the published gains are measured only on the final model. This assumption is load-bearing for the decoupled-training thesis.
- [§4 (Experiments)] The experimental section lacks statistical details (standard deviations, number of runs, significance tests) and explicit data-split descriptions for the seen/unseen perturbation partitions. Without these, the reported gains (e.g., +12.60% / +7.77% on OpenVLA) cannot be fully verified as robust rather than incidental.
minor comments (2)
- [Abstract and §3] The abstract and method description would benefit from a concise statement of the exact loss functions or objectives used in each stage to clarify how the two objectives are decoupled.
- [§4.1 (Benchmark)] Perturbation generation details (e.g., specific visual corruption parameters and linguistic noise models) should be expanded in the benchmark section to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications based on the manuscript and committing to revisions that strengthen the evidence for our claims without misrepresenting the current results.
read point-by-point responses
-
Referee: [§3 (Method) and §4 (Experiments)] The central claim that robustness acquired in Stage I survives Stage II realignment on clean data is not directly supported by evidence. No before/after robustness metrics on perturbed inputs, no ablation removing Stage I, and no retention mechanisms (e.g., regularization or replay) are reported; the published gains are measured only on the final model. This assumption is load-bearing for the decoupled-training thesis.
Authors: We acknowledge that the manuscript primarily reports final-model performance on perturbed inputs rather than explicit before/after Stage II comparisons. The observed gains on both seen and unseen perturbations (including cross-architecture results) provide indirect support that robustness is retained, as Stage II uses only clean data yet the model still outperforms baselines under perturbation. However, we agree this is insufficient to fully substantiate the decoupling thesis. In the revised manuscript we will add: (i) direct robustness metrics on perturbed inputs before and after Stage II, (ii) an ablation that removes Stage I entirely (training only on clean data), and (iii) explicit discussion of how the two-stage separation itself functions as the retention mechanism by avoiding the optimization conflicts of joint training. These additions will be placed in §3 and §4. revision: yes
-
Referee: [§4 (Experiments)] The experimental section lacks statistical details (standard deviations, number of runs, significance tests) and explicit data-split descriptions for the seen/unseen perturbation partitions. Without these, the reported gains (e.g., +12.60% / +7.77% on OpenVLA) cannot be fully verified as robust rather than incidental.
Authors: We agree that the current experimental reporting is incomplete on these dimensions. The manuscript states the gains but does not include variance estimates or split details. In the revision we will expand §4 to report: standard deviations over multiple random seeds (we will run and report at least 3–5 independent trials per setting), results of statistical significance tests (e.g., paired t-tests against baselines), and a precise description of the seen/unseen perturbation partitions, including how the 28-type benchmark was partitioned to guarantee that unseen perturbations are genuinely novel and not merely held-out instances of seen types. revision: yes
Circularity Check
No significant circularity; purely empirical claims with no derivation chain
full rationale
The paper presents an empirical two-stage fine-tuning procedure (Stage I curriculum on multimodal perturbations, Stage II clean-data realignment) and reports measured success rates on held-out perturbations and hardware. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All performance numbers (e.g., +12.60% seen / +7.77% unseen on OpenVLA) are obtained from external benchmarks and are therefore falsifiable rather than tautological by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
OA-WAM: Object-Addressable World Action Model for Robust Robot Manipulation
OA-WAM uses persistent address vectors and dynamic content vectors in object slots to enable addressable world-action prediction, improving robustness on manipulation benchmarks under scene changes.
Reference graph
Works this paper leans on
-
[1]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
𝜋0: A Vision-Language-Action Flow Model for General Robot Control. arXiv:2410.24164 [cs.LG] https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, ...
work page internal anchor Pith review arXiv 2023
-
[4]
Hao Cheng, Erjia Xiao, Yichi Wang, Chengyuan Yu, Mengshu Sun, Qiang Zhang, Jiahang Cao, Yijie Guo, Ning Liu, Kaidi Xu, Jize Zhang, Chao Shen, Philip Torr, Jindong Gu, and Renjing Xu. 2025. Manipulation Facing Threats: Eval- uating Physical Vulnerabilities in End-to-End Vision Language Action Models. arXiv:2409.13174 [cs.CV] https://arxiv.org/abs/2409.13174
-
[5]
Jianing Guo, Zhenhong Wu, Chang Tu, Yiyao Ma, Xiangqi Kong, Zhiqian Liu, Jiaming Ji, Shuning Zhang, Yuanpei Chen, Kai Chen, Qi Dou, Yaodong Yang, Xianglong Liu, Huijie Zhao, Weifeng Lv, and Simin Li. 2026. On Ro- bustness of Vision-Language-Action Model against Multi-Modal Perturbations. arXiv:2510.00037 [cs.CV] https://arxiv.org/abs/2510.00037
-
[6]
Asher J Hancock, Allen Z Ren, and Anirudha Majumdar. 2025. Run-time obser- vation interventions make vision-language-action models more visually robust. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 9499–9506
2025
-
[7]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-Tuning Vision-Language- Action Models: Optimizing Speed and Success. arXiv:2502.19645 [cs.RO] https: //arxiv.org/abs/2502.19645
work page internal anchor Pith review arXiv 2025
-
[8]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. OpenVLA: An Open-Source Vision- Language-Action Model. arXiv:2406.09246 [cs.RO] h...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. arXiv:2306.03310 [cs.AI] https://arxiv.org/abs/2306.03310
work page internal anchor Pith review arXiv 2023
-
[11]
Hanqing Liu, Shouwei Ruan, Jiahuan Long, Junqi Wu, Jiacheng Hou, Huili Tang, Tingsong Jiang, Weien Zhou, and Wen Yao. 2026. Eva-VLA: Evaluating Vision- Language-Action Models’ Robustness Under Real-World Physical Variations. arXiv:2509.18953 [cs.RO] https://arxiv.org/abs/2509.18953
-
[12]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2019. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv:1706.06083 [stat.ML] https://arxiv.org/abs/1706.06083
work page internal anchor Pith review arXiv 2019
-
[13]
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. 2024. Octo: An Open-Source Generalist Robot Policy. arXiv:2405.12213 [cs.RO] https:/...
work page internal anchor Pith review arXiv 2024
-
[14]
Taowen Wang, Cheng Han, James Liang, Wenhao Yang, Dongfang Liu, Luna Xinyu Zhang, Qifan Wang, Jiebo Luo, and Ruixiang Tang. 2025. Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 6948–6958
2025
-
[15]
Zhijie Wang, Zhehua Zhou, Jiayang Song, Yuheng Huang, Zhan Shu, and Lei Ma. 2025. VLATest: Testing and Evaluating Vision-Language-Action Models for Robotic Manipulation.Proceedings of the ACM on Software Engineering2, FSE (2025), 1615–1638. https://api.semanticscholar.org/CorpusID:272753667
2025
- [16]
- [17]
- [18]
-
[19]
Hongyin Zhang, Pengxiang Ding, Shangke Lyu, Ying Peng, and Donglin Wang
-
[20]
arXiv:2502.09268 [cs.RO] https://arxiv.org/abs/2502.09268
GEVRM: Goal-Expressive Video Generation Model For Robust Visual Manipulation. arXiv:2502.09268 [cs.RO] https://arxiv.org/abs/2502.09268
-
[21]
Hongyin Zhang, Shuo Zhang, Junxi Jin, Qixin Zeng, Runze Li, and Donglin Wang
-
[22]
RobustVLA: Robustness-Aware Reinforcement Post-Training for Vision- Language-Action Models. arXiv:2511.01331 [cs.RO] https://arxiv.org/abs/2511. 01331
-
[23]
Sanketi, Grecia Salazar, Michael S
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Van- houcke, Huong Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Ser- manet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michale...
-
[24]
InProceedings of The 7th Conference on Robot Learning (Proceedings of Ma- chine Learning Research, Vol
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. InProceedings of The 7th Conference on Robot Learning (Proceedings of Ma- chine Learning Research, Vol. 229), Jie Tan, Marc Toussaint, and Kourosh Darvish (Eds.). PMLR, 2165–2183. https://proceedings.mlr.press/v229/zitkovich23a.html Conference’17, July 2017, Washington, DC, USA...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.