Recognition: unknown
Mosaic: Cross-Modal Clustering for Efficient Video Understanding
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Mosaic organizes VLM KVCache into cross-modal clusters to speed streaming long-video understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
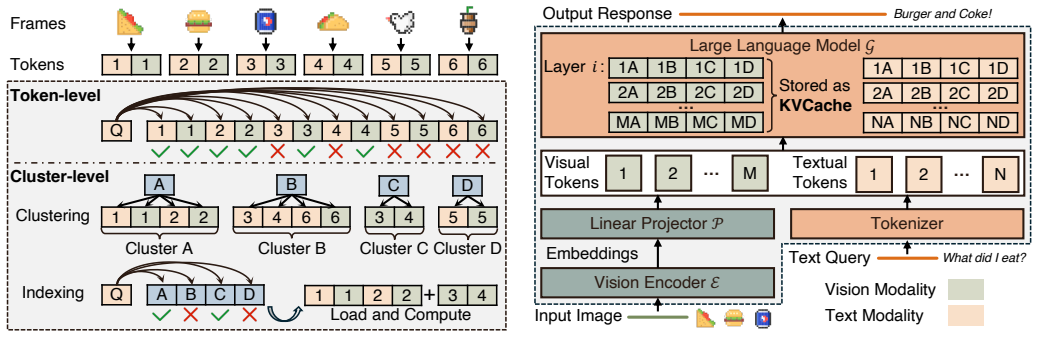
We present Mosaic, the first cluster-driven VLM inference system for streaming long-video understanding. Our key insight is that VLM KVCache exhibits an implicit cross-modal clustering structure: retrieved KV states form groups jointly shaped by visual coherence and semantic relevance. Based on this observation, Mosaic uses cross-modal clusters as the basic unit of KVCache organization, maintenance, and retrieval.
What carries the argument
Cross-modal clusters, which serve as the basic unit for KVCache organization, maintenance, and retrieval, where each cluster groups KV states by visual coherence and semantic relevance.
If this is right
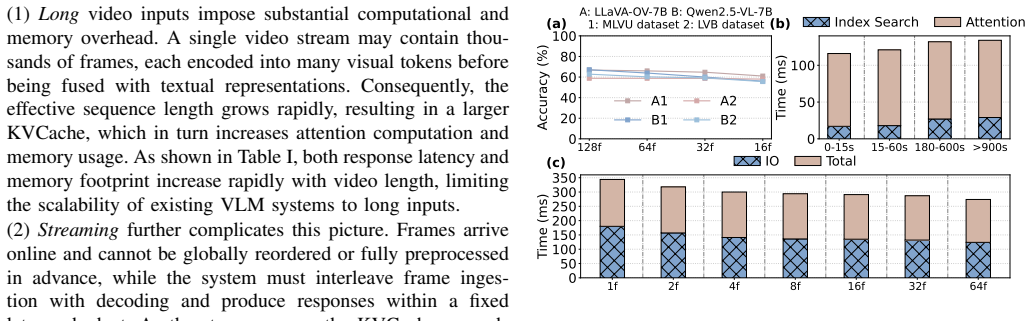
- Enables efficient handling of expanding KVCache as video streams lengthen without proportional increases in computation or memory traffic.
- Replaces token-level attention sparsity methods with cluster-level operations to cut data movement fragmentation.
- Supports offloading of inactive clusters from GPU to CPU while preserving retrieval accuracy for long-term context.
- Delivers measured speedups of up to 1.38 times relative to existing retrieval baselines under streaming latency constraints.
Where Pith is reading between the lines
- The same clustering principle could be tested on non-video tasks that also accumulate large KV caches, such as long-document reasoning.
- Hardware schedulers might gain from explicit support for moving entire clusters rather than individual tokens.
- Dynamic re-clustering triggered by scene changes in video could further reduce stale data retention.
Load-bearing premise
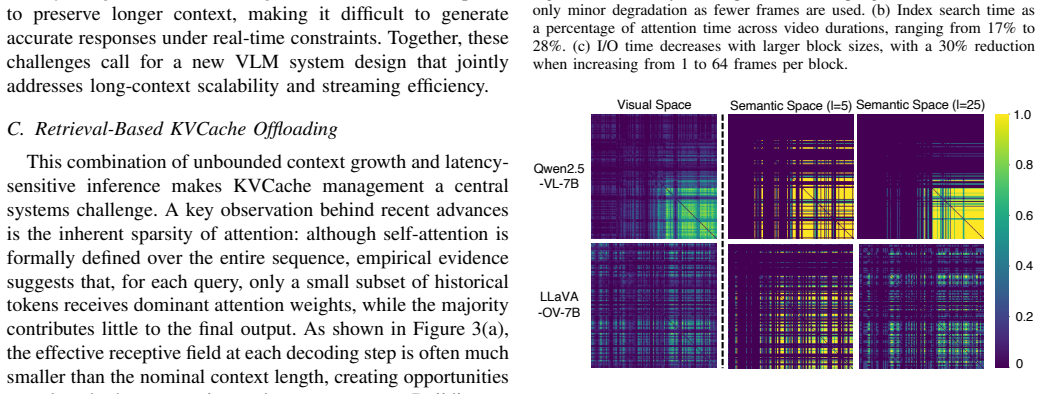
VLM KVCache naturally forms groups of retrieved states that are jointly shaped by visual coherence and semantic relevance.
What would settle it
A direct measurement showing that KV states retrieved for video queries do not form coherent clusters by visual and semantic features, or that switching to cluster-based units produces no reduction in management overhead or latency.
Figures








read the original abstract
Large vision-language models (VLMs) are enabling interactive video reasoning, giving rise to streaming long-video understanding. In this setting, frames arrive continuously, while the system preserves long-term context and generates responses under strict latency constraints. A central challenge is KVCache management: as video streams grow, KVCache expands rapidly, increasing computation and memory overhead. Existing retrieval-based approaches exploit attention sparsity and offload inactive KVCache from GPU to CPU memory, but their token-level design causes high management overhead and fragmented data movement. We present Mosaic, the first cluster-driven VLM inference system for streaming long-video understanding. Our key insight is that VLM KVCache exhibits an implicit cross-modal clustering structure: retrieved KV states form groups jointly shaped by visual coherence and semantic relevance. Based on this observation, Mosaic uses cross-modal clusters as the basic unit of KVCache organization, maintenance, and retrieval. Evaluations show that Mosaic outperforms state-of-the-art baselines, achieving up to 1.38x speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mosaic, the first cluster-driven VLM inference system for streaming long-video understanding. It claims that VLM KVCache exhibits an implicit cross-modal clustering structure in which retrieved KV states form groups jointly shaped by visual coherence and semantic relevance. Mosaic therefore organizes, maintains, and retrieves KVCache at the level of these cross-modal clusters rather than at the token level, with the goal of reducing management overhead and fragmented data movement. Evaluations are reported to show up to 1.38x speedup over state-of-the-art baselines.
Significance. If the empirical results hold and the speedup can be attributed to the cross-modal clustering mechanism, the work addresses a practically important bottleneck in long-context VLM inference under latency constraints. The insight that KVCache naturally forms cross-modal groups could influence future KVCache designs and improve scalability for interactive video reasoning. The reported 1.38x speedup is a concrete performance gain that would be of interest to the systems community if supported by reproducible experiments.
major comments (2)
- Abstract: The central claim that 'VLM KVCache exhibits an implicit cross-modal clustering structure' is stated without any supporting derivation, preliminary measurement, or reference to a specific section or figure that demonstrates this structure; this makes the load-bearing assumption difficult to evaluate from the given text.
- Evaluations section (implied by the abstract's performance claim): No ablation studies, implementation details, or quantitative breakdowns are provided to isolate the contribution of cross-modal clustering from other factors such as offloading strategy or hardware-specific optimizations; without these, the 1.38x speedup cannot be confidently attributed to the proposed method.
minor comments (1)
- Abstract: The acronym 'VLM' and 'KVCache' are used without initial expansion, which reduces clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the supporting material already present in the manuscript while committing to revisions that improve clarity and attribution of results.
read point-by-point responses
-
Referee: Abstract: The central claim that 'VLM KVCache exhibits an implicit cross-modal clustering structure' is stated without any supporting derivation, preliminary measurement, or reference to a specific section or figure that demonstrates this structure; this makes the load-bearing assumption difficult to evaluate from the given text.
Authors: We agree that the abstract would benefit from an explicit pointer. Section 3.1 of the manuscript contains the supporting analysis: it reports preliminary measurements of attention scores across visual and textual tokens, shows that retrieved KV states form coherent groups via t-SNE visualizations of embedding similarity, and quantifies cluster purity using both visual coherence (frame-level feature similarity) and semantic relevance (caption alignment). We will revise the abstract to include a direct reference to Section 3.1 and Figure 2. revision: yes
-
Referee: Evaluations section (implied by the abstract's performance claim): No ablation studies, implementation details, or quantitative breakdowns are provided to isolate the contribution of cross-modal clustering from other factors such as offloading strategy or hardware-specific optimizations; without these, the 1.38x speedup cannot be confidently attributed to the proposed method.
Authors: The manuscript already contains the requested elements. Section 5.3 presents ablation studies that disable cross-modal clustering while retaining the same offloading and retrieval mechanisms, isolating a 1.12–1.25x contribution from clustering alone. Implementation details, including the clustering algorithm, eviction policy, and hardware configuration (A100 GPUs with PCIe offloading), appear in Section 4 and Appendix A. To strengthen attribution, we will add an explicit breakdown table in Section 5 that decomposes the overall speedup into clustering, offloading, and baseline retrieval components. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents Mosaic as an engineering system motivated by the empirical observation that VLM KVCache exhibits cross-modal clustering. This insight is stated directly as a premise for organizing KVCache into clusters rather than derived via equations, fitted parameters, or theorems. No predictions are claimed from self-referential fits, no uniqueness theorems are invoked via self-citation, and no ansatz or renaming of known results is used to support the core architecture. Performance gains (e.g., 1.38x speedup) are reported as evaluation outcomes, not forced by construction from inputs. The derivation chain is therefore self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2601.03267
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267 2025
-
[2]
Gemini 3 pro model card,
Google DeepMind, “Gemini 3 pro model card,” Google DeepMind, Tech. Rep., Nov. 2025, accessed: December
2025
-
[3]
Available: https://storage.googleapis.com/deepmind- media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
[Online]. Available: https://storage.googleapis.com/deepmind- media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2010.11929
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2021
-
[5]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8186–8193, 2024. [Online]. Available: https://doi.org/10.1109/LRA.2024.3440097
-
[6]
T-VSL: text-guided visual sound source localization in mixtures
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 120–15 130. [Online]. Available: https://doi.org/10.1109/CVPR52733.2024.01432
-
[7]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huanget al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2303.03378
work page internal anchor Pith review doi:10.48550/arxiv.2303.03378 2023
-
[8]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
[Online]. Available: https://doi.org/10.48550/arXiv.2406.09246
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246
-
[10]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 34 892–34 916, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2304.08485
work page internal anchor Pith review doi:10.48550/arxiv.2304.08485 2023
-
[11]
Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704, 2023
H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S.-F. Chang, and Y . Yang, “Ferret: Refer and ground anything anywhere at any granularity,”arXiv preprint arXiv:2310.07704, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.07704
-
[12]
Video-llava: Learning united visual representation by alignment before projection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 5971–5984. [Online]. Available: https://aclanthology.org/2024.emnlp-main.342
2024
-
[13]
Videochat: Chat-centric video understanding,
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat-centric video understanding,”Science China Information Sciences, vol. 68, no. 10, p. 200102, 2025. [Online]. Available: https://doi.org/10.1007/s11432-024-4321-9
-
[14]
arXiv preprint arXiv:2503.00540 , year=
S. Di, Z. Yu, G. Zhang, H. Li, T. Zhong, H. Cheng, B. Li, W. He, F. Shu, and H. Jiang, “Streaming video question-answering with in-context video kv-cache retrieval,”arXiv preprint arXiv:2503.00540,
-
[15]
arXiv preprint arXiv:2503.00540 , year=
[Online]. Available: https://doi.org/10.48550/arXiv.2503.00540
-
[16]
LiveVLM: Efficient Online Video Understanding via Streaming-Oriented KV Cache and Retrieval
Z. Ning, G. Liu, Q. Jin, W. Ding, M. Guo, and J. Zhao, “Livevlm: Efficient online video understanding via streaming-oriented kv cache and retrieval,”arXiv preprint arXiv:2505.15269, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.15269
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.15269 2025
-
[17]
Y . Yang, Z. Zhao, S. N. Shukla, A. Singh, S. K. Mishra, L. Zhang, and M. Ren, “Streammem: Query-agnostic kv cache memory for streaming video understanding,”arXiv preprint arXiv:2508.15717, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.15717
-
[18]
Least Squares Quantization in PCM,
S. Lloyd, “Least squares quantization in pcm,”IEEE transactions on information theory, vol. 28, no. 2, pp. 129–137, 1982. [Online]. Available: https://doi.org/10.1109/TIT.1982.1056489
-
[19]
Deep residual learning for image recognition
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. [Online]. Available: https://doi.org/10.1109/CVPR.2016.90
-
[20]
Llava-onevision: Easy visual task transfer,
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, and C. Li, “Llava-onevision: Easy visual task transfer,”
-
[21]
LLaVA-OneVision: Easy Visual Task Transfer
[Online]. Available: https://doi.org/10.48550/arXiv.2408.03326
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03326
-
[22]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[23]
MLVU: Benchmarking Multi-task Long Video Understanding
J. Zhou, Y . Shu, B. Zhao, B. Wu, Z. Liang, S. Xiao, M. Qin, X. Yang, Y . Xiong, B. Zhang, T. Huang, and Z. Liu, “Mlvu: Benchmarking multi-task long video understanding,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2406.04264
work page internal anchor Pith review doi:10.48550/arxiv.2406.04264 2025
-
[24]
Longvideobench: A benchmark for long-context inter- leaved video-language understanding
H. Wu, D. Li, B. Chen, and J. Li, “Longvideobench: A benchmark for long-context interleaved video-language understanding,” 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2407.15754
-
[25]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhang, P. Chen, Y . Li, S. Lin, S. Zhao, K. Li, T. Xu, X. Zheng, E. Chen, C. Shan, R. He, and X. Sun, “Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2405.21075
work page internal anchor Pith review doi:10.48550/arxiv.2405.21075 2025
-
[26]
arXiv preprint arXiv:2506.23825 , year=
H. Zhang, Y . Wang, Y . Tang, Y . Liu, J. Feng, J. Dai, and X. Jin, “Flash-vstream: Memory-based real-time understanding for long video streams,” 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2506.23825
-
[27]
Kuaishou,
Kuaishou Technology, “Kuaishou,” https://www.kuaishou.com/en, 2026, accessed: 2026-04-08
2026
-
[28]
Y . Zhang, Z. Zhao, Z. Chen, Z. Ding, X. Yang, and Y . Sun, “Beyond training: Dynamic token merging for zero-shot video understanding,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 22 046–22 055. [Online]. Available: https://doi.org/10.48550/arXiv.2411.14401
-
[29]
X. Tang, J. Qiu, L. Xie, Y . Tian, J. Jiao, and Q. Ye, “Adaptive keyframe sampling for long video understanding,” arXiv preprint arXiv:2502.21271, 2025. [Online]. Available: https://doi.org/10.1109/CVPR52734.2025.02711
-
[30]
Adaretake: Adaptive redundancy reduction to perceive longer for video-language understanding,
X. Wang, Q. Si, J. Wu, S. Zhu, L. Cao, and L. Nie, “Adaretake: Adaptive redundancy reduction to perceive longer for video-language understanding,”arXiv preprint arXiv:2503.12559, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.12559
-
[31]
X. Shen, Y . Xiong, C. Zhao, L. Wu, J. Chen, C. Zhu, Z. Liu, F. Xiao, B. Varadarajan, F. Bordes, Z. Liu, H. Xu, H. J. Kim, B. Soran, R. Krishnamoorthi, M. Elhoseiny, and V . Chandra, “Longvu: Spatiotemporal adaptive compression for long video-language understanding,”arXiv preprint arXiv:2410.17434, 2024. [Online]. Available: https://doi.org/10.48550/arXiv...
-
[32]
T-VSL: text-guided visual sound source localization in mixtures
E. Song, W. Chai, G. Wang, Y . Zhang, H. Zhou, F. Wu, X. Guo, T. Ye, Y . Lu, J.-N. Hwanget al., “Moviechat: From dense token to sparse memory for long video understanding,” arXiv preprint arXiv:2307.16449, 2023. [Online]. Available: https://doi.org/10.1109/CVPR52733.2024.01725
-
[33]
Video-in-the-loop: Span-grounded long video qa with interleaved reasoning,
C. Wang, D. Bai, Y . Yang, X. Jin, A. Zhang, R. Wang, S. Jiang, Y . Yang, H. Wu, Q. Dai, C. Luo, T. Cao, L. Qiu, and S. Banerjee, “Video-in-the-loop: Span-grounded long video qa with interleaved reasoning,”arXiv preprint arXiv:2510.04022, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.04022
-
[34]
T-VSL: text-guided visual sound source localization in mixtures
J. Chen, Z. Lv, S. Wu, K. Q. Lin, C. Song, D. Gao, J.-W. Liu, Z. Gao, D. Mao, and M. Z. Shou, “Videollm-online: Online video large language model for streaming video,” inCVPR, 2024. [Online]. Available: https://doi.org/10.1109/CVPR52733.2024.01742
-
[35]
Streamingvlm: Real-time understanding for infinite video streams,
R. Xu, G. Xiao, Y . Chen, L. He, K. Peng, Y . Lu, and S. Han, “Streamingvlm: Real-time understanding for infinite video streams,”
-
[36]
arXiv preprint arXiv:2510.09608 , year=
[Online]. Available: https://doi.org/10.48550/arXiv.2510.09608
-
[37]
QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design
B. Schneider, D. Jiang, C. Du, T. Pang, and W. Chen, “Quickvideo: Real-time long video understanding with system algorithm co- design,”arXiv preprint arXiv:2505.16175, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.16175
-
[38]
Streaming long video understanding with large language models,
R. Qian, X. Dong, P. Zhang, Y . Zang, S. Ding, D. Lin, and J. Wang, “Streaming long video understanding with large language models,”https://arxiv.org/abs/2405.16009, 2024. [Online]. Available: https://doi.org/10.52202/079017-3792
-
[39]
Timechat- online: 80% visual tokens are naturally redundant in streaming videos,
L. Yao, Y . Li, Y . Wei, L. Li, S. Ren, Y . Liu, K. Ouyang, L. Wang, S. Li, S. Li, L. Kong, Q. Liu, Y . Zhang, and X. Sun, “Timechat- online: 80% visual tokens are naturally redundant in streaming videos,”https://arxiv.org/abs/2504.17343, 2025. [Online]. Available: https://doi.org/10.1145/3746027.3754839
-
[40]
T. Wang, K. Li, Z. Hao, D. Bai, J. Ren, Y . Zhang, T. Cao, and M. Yang, “Long exposure: Accelerating parameter-efficient fine- tuning for llms under shadowy sparsity,” inSC24: International 11 Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–18. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00081
-
[41]
{JENGA}: Enhancing{LLM}{Long-Context}fine-tuning with contextual token sparsity,
T. Wang, X. Chen, K. Li, T. Cao, J. Ren, and Y . Zhang, “{JENGA}: Enhancing{LLM}{Long-Context}fine-tuning with contextual token sparsity,” in2025 USENIX Annual Technical Conference (USENIX ATC 25), 2025, pp. 123–141. [Online]. Available: https://doi.org/10.48550/arXiv.2501.09767
-
[42]
Neuralink: Fast on-device llm inference with neuron co-activation linking,
T. Wang, R. Fan, M. Huang, Z. Hao, K. Li, T. Cao, Y . Lu, Y . Zhang, and J. Ren, “Neuralink: Fast on-device llm inference with neuron co-activation linking,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2025, pp. 147–162. [Online]. Available: https://doi.org/10.1...
-
[43]
Dynakv: Enabling accurate and efficient long-sequence llm decoding on smartphones,
T. Wang, M. Huang, F. Li, L. Chen, J. Zhang, and J. Ren, “Dynakv: Enabling accurate and efficient long-sequence llm decoding on smartphones,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2511.07427
-
[44]
Swarm: Co-activation aware kvcache offloading across multiple ssds,
T. Wang, L. Chu, R. Fan, and J. Ren, “Swarm: Co-activation aware kvcache offloading across multiple ssds,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.17803
-
[45]
C. Xiao, P. Zhang, X. Han, G. Xiao, Y . Lin, Z. Zhang, Z. Liu, and M. Sun, “Infllm: Training-free long-context extrapolation for llms with an efficient context memory,”https://arxiv.org/abs/2402.04617, 2024. [Online]. Available: https://doi.org/10.52202/079017-3801
-
[46]
Y . Li and M. Gao, “Hydrogen: Contention-aware hybrid memory for heterogeneous cpu-gpu architectures,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis, 2024. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00017
-
[47]
A. Cho, A. Saxena, M. Qureshi, and A. Daglis, “Coaxial: A cxl-centric memory system for scalable servers,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, 2024. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00101
-
[48]
Z. Zhang, D. Yang, X. Zhou, and D. Cheng, “Mcfuser: High- performance and rapid fusion of memory-bound compute-intensive operators,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, 2024. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00040
-
[49]
B. Butler, S. Yu, A. Mazaheri, and A. Jannesari, “Pipeinfer: Accelerating llm inference using asynchronous pipelined speculation,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis, 2024. [Online]. Available: https://doi.org/10.1109/SC41406.2024.00046
-
[50]
Mlp- offload: Multi-level, multi-path offloading for llm pre-training to break the gpu memory wall,
A. K. Maurya, M. M. Rafique, F. Cappello, and B. Nicolae, “Mlp- offload: Multi-level, multi-path offloading for llm pre-training to break the gpu memory wall,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis,
-
[51]
Available: https://doi.org/10.1145/3712285.3759864 12
[Online]. Available: https://doi.org/10.1145/3712285.3759864 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.