Recognition: unknown
Attention-Guided Dual-Stream Learning for Group Engagement Recognition: Fusing Transformer-Encoded Motion Dynamics with Scene Context via Adaptive Gating
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
The pith
Dual-stream model fuses transformer motion tracking with 3D scene context via gating to reach 96 percent accuracy on group engagement
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
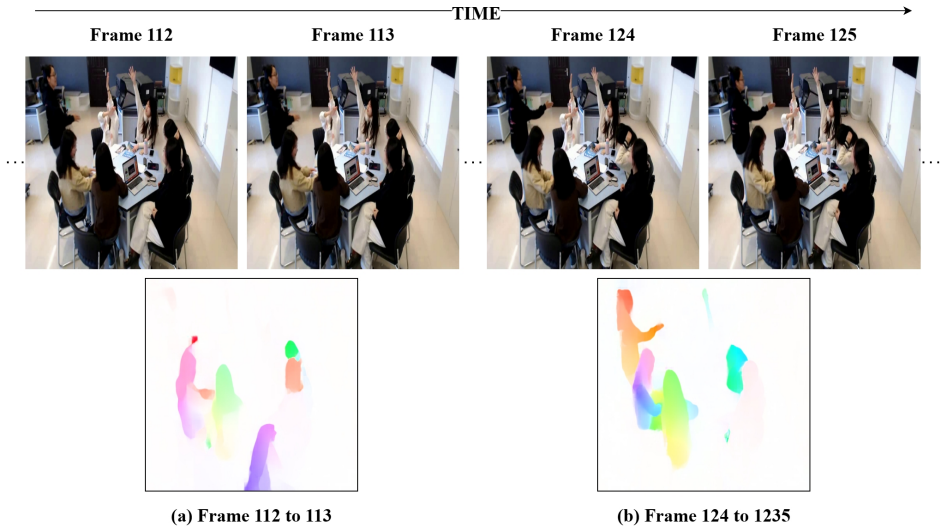
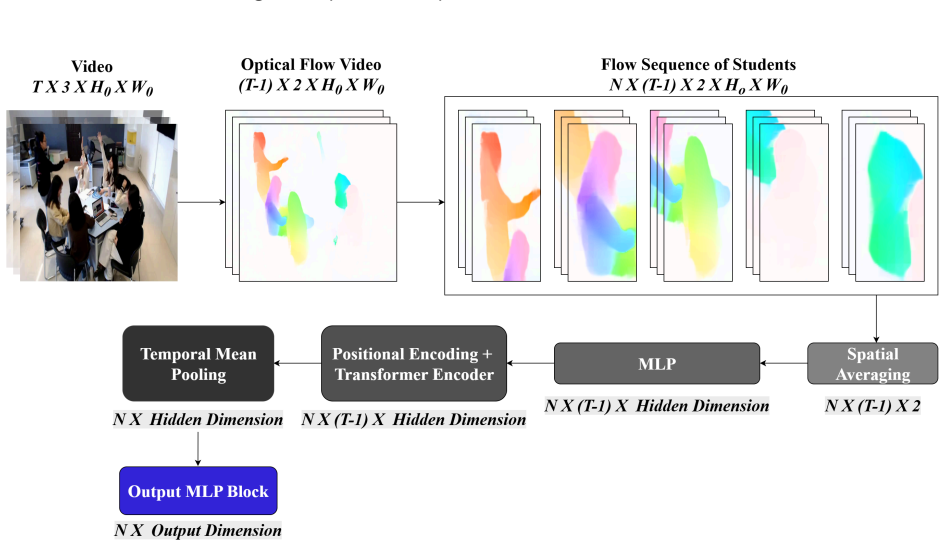
DualEngage models engagement as a joint function of both individual and group-level behaviors by encoding person-level motion dynamics through student detection, tracking, dense optical flow with the Recurrent All-Pairs Field Transforms network, transformer temporal encoding, and attention pooling into a unified representation, then combining this with scene-level spatiotemporal features from a pretrained three-dimensional Residual Network via softmax-gated fusion that dynamically weights each stream based on joint context.
What carries the argument
The softmax-gated fusion mechanism that dynamically weights the contribution of the transformer-encoded and attention-pooled motion stream against the 3D ResNet scene stream according to their joint feature context.
If this is right
- The dual-stream architecture improves classification accuracy and macro F1 over single-stream baselines as demonstrated by the ablation experiments.
- Individual motion dynamics captured by optical flow and transformer encoding supply information complementary to full-scene spatiotemporal features.
- Attention pooling successfully converts per-student motion encodings into a single group-level representation.
- Modeling engagement as the combination of person-level and scene-level signals enables accurate recognition from in-classroom video without relying on online-only or individual-only assumptions.
Where Pith is reading between the lines
- Automated tools built on this architecture could supply teachers with real-time indicators of how well group activities are sustaining collective attention.
- The same motion-plus-scene fusion pattern could be tested on video from other group settings such as team meetings or laboratory collaborations.
- Adding audio or speech features to the existing visual streams would constitute a direct next step for richer joint representations.
- Cross-dataset experiments on classrooms varying in age, culture, or room layout would reveal the extent to which the learned gating and motion features transfer.
Load-bearing premise
The Classroom Group Engagement Dataset supplies representative and accurately labeled examples of group engagement levels that generalize beyond the specific classrooms and students recorded.
What would settle it
Retraining DualEngage on the Ocean University dataset and evaluating it on an independent collection of classroom videos from a different school or country; a large drop below 90 percent accuracy would indicate the performance is tied to dataset-specific patterns rather than general group engagement cues.
Figures



read the original abstract
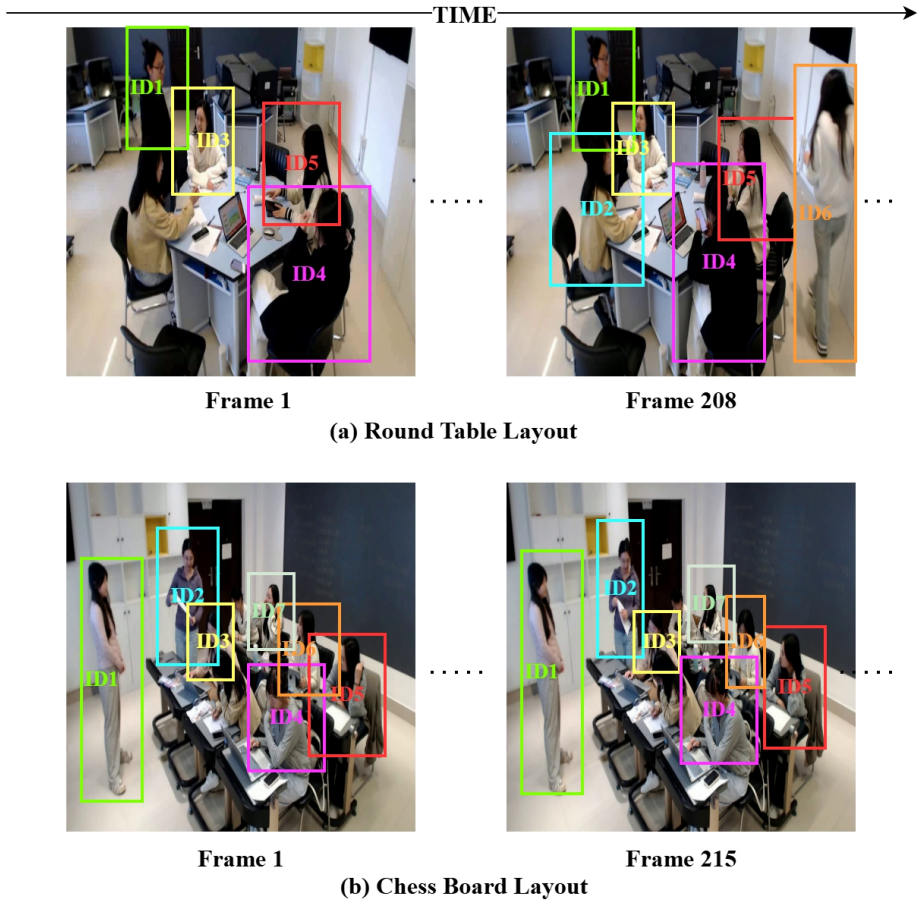
Student engagement is crucial for improving learning outcomes in group activities. Highly engaged students perform better both individually and contribute to overall group success. However, most existing automated engagement recognition methods are designed for online classrooms or estimate engagement at the individual level. Addressing this gap, we propose DualEngage, a novel two-stream framework for group-level engagement recognition from in-classroom videos. It models engagement as a joint function of both individual and group-level behaviors. The primary stream models person-level motion dynamics by detecting and tracking students, extracting dense optical flow with the Recurrent All-Pairs Field Transforms network, encoding temporal motion patterns using a transformer encoder, and finally aggregating per-student representations through attention pooling into a unified representation. The secondary stream captures scene-level spatiotemporal information from the full video clip, leveraging a pretrained three-dimensional Residual Network. The two-stream representations are combined via softmax-gated fusion, which dynamically weights each stream's contribution based on the joint context of both features. DualEngage learns a joint representation of individual actions with overarching group dynamics. We evaluate the proposed approach using fivefold cross-validation on the Classroom Group Engagement Dataset developed by Ocean University of China, achieving an average classification accuracy of 0.9621+/-0.0161 with a macro-averaged F1 of 0.9530+/-0.0204. To understand the contribution of each branch, we further conduct an ablation study comparing single-stream variants against the two-stream model. This work is among the first in classroom engagement recognition to adopt a dual-stream design that explicitly leverages motion cues as an estimator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DualEngage, a dual-stream architecture for group-level student engagement recognition in classroom videos. The primary stream detects and tracks individuals, computes dense optical flow via RAFT, encodes temporal dynamics with a transformer, and aggregates via attention pooling. The secondary stream extracts spatiotemporal scene features with a pretrained 3D ResNet. Representations are fused by softmax-gated adaptive weighting. On the Classroom Group Engagement Dataset from Ocean University of China, five-fold cross-validation yields 0.9621±0.0161 accuracy and 0.9530±0.0204 macro F1; ablations confirm the dual-stream benefit over single-stream variants.
Significance. If the performance holds under proper validation, the work is significant as one of the first explicit dual-stream treatments of group engagement that jointly models individual motion dynamics and scene context. The transformer-based motion encoding and learned gating mechanism constitute a clear technical contribution, and the internal ablation study supplies direct evidence that both streams are necessary. The approach addresses a genuine gap between individual/online engagement estimators and in-classroom group analysis.
major comments (2)
- [Experiments] Experiments section: the manuscript reports 0.9621 accuracy and 0.9530 F1 on the Classroom Group Engagement Dataset but supplies no information on dataset size, number of clips, class balance, labeling protocol, inter-rater agreement, or student demographics. Without these details the central performance claim cannot be assessed for reliability or generalization beyond the single institutional source.
- [Experimental results] Experimental results: while ablation tables compare single-stream variants to the full model, no quantitative comparison is provided against prior group or individual engagement methods. This omission makes it impossible to determine whether the reported numbers represent an advance over existing baselines.
minor comments (2)
- [Abstract and Methods] The abstract and introduction refer to 'fivefold cross-validation' without stating whether folds are stratified by class or by video to avoid leakage; this should be clarified in the methods.
- [Method] Notation for the gated fusion (softmax over the two stream features) is introduced without an explicit equation; adding a numbered equation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our contributions or results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports 0.9621 accuracy and 0.9530 F1 on the Classroom Group Engagement Dataset but supplies no information on dataset size, number of clips, class balance, labeling protocol, inter-rater agreement, or student demographics. Without these details the central performance claim cannot be assessed for reliability or generalization beyond the single institutional source.
Authors: We agree that these dataset details are essential for evaluating reliability and generalization. The Classroom Group Engagement Dataset was developed at Ocean University of China, and we have the underlying statistics available. In the revised manuscript we will add a dedicated subsection in Experiments describing: total number of clips and students, class balance across engagement levels, the labeling protocol (including number of annotators and how consensus was reached), student demographics, and any inter-rater agreement statistics that were computed. If formal inter-rater agreement was not recorded during dataset creation, we will explicitly note this as a limitation and discuss its implications. revision: yes
-
Referee: [Experimental results] Experimental results: while ablation tables compare single-stream variants to the full model, no quantitative comparison is provided against prior group or individual engagement methods. This omission makes it impossible to determine whether the reported numbers represent an advance over existing baselines.
Authors: We acknowledge that external baselines are needed to contextualize the reported performance. While the primary contribution is the dual-stream architecture and the ablation evidence for both streams, we will add quantitative comparisons in the revised Experiments section. We will implement and evaluate representative prior individual-engagement methods (e.g., CNN- or LSTM-based student behavior models from the literature) on our group-level dataset, reporting accuracy and macro F1. We will also include any directly applicable group-engagement baselines if they exist. We will clearly discuss differences in task formulation (individual vs. group) and dataset characteristics so readers can interpret the gains fairly. revision: yes
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper proposes a dual-stream neural architecture (transformer on optical flow + 3D ResNet + gated fusion) and reports its classification performance via five-fold cross-validation on a newly introduced dataset. No equations, first-principles derivations, or uniqueness theorems are claimed; the central result is an empirical accuracy number obtained by training and testing on held-out folds of the same data distribution. This is standard supervised learning practice and does not reduce the reported metric to a fitted parameter by construction or to a self-citation chain. No load-bearing self-citations or ansatzes are invoked in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned gating parameters
axioms (2)
- domain assumption Video labels accurately reflect true group engagement levels
- domain assumption Optical flow and 3D ResNet features capture behaviorally relevant information
invented entities (1)
-
DualEngage dual-stream framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1812.10328
A multi-stream convolutional neural network framework for group activity recognition. arXiv preprint arXiv:1812.10328 . Baltrušaitis, T., Robinson, P., Morency, L.P.,
-
[2]
Openface: an open source facial behavior analysis toolkit, in: 2016 IEEE winter conference on applications of computer vision (WACV), IEEE. pp. 1–10. Bewley, A., Ge, Z., Ott, L., Ramos, F., Upcroft, B.,
2016
-
[3]
European Conference on Computer Vision (ECCV), Springer
A naturalistic open source movie for optical flow evaluation, in: Proc. European Conference on Computer Vision (ECCV), Springer. pp. 611–625. URL:https://is.mpg.de/ps/publications/butler-eccv-2012, doi:10.1007/978-3-642-33783-3_44. Carreira, J., Zisserman, A., 2017a. Quo vadis, action recognition? a new model and the kinetics dataset, in: IEEE Conference ...
-
[4]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Patterns of motivating teaching behaviour and student engagement: A microanalytic approach. European Journal of Psychology of Education 37, 227–255. Chen,C.F.R.,Panda,R.,Ramakrishnan,K.,Feris,R.,Cohn,J.,Oliva,A.,Fan,Q.,2021. Deepanalysisofcnn-basedspatio-temporalrepresentations for action recognition, in: Proceedings of the IEEE/CVF conference on computer...
work page Pith review arXiv 2021
-
[5]
What are they doing?: Collective activity classification using spatio-temporal relationship among people, in:2009IEEE12thInternationalConferenceonComputerVisionWorkshops(ICCVWorkshops),IEEE.pp.1282–1289. doi:10.1109/ICCVW. 2009.5457633. Christenson, S.L., Reschly, A.L., Wylie, C. (Eds.),
-
[6]
IEEE International Conference on Computer Vision (ICCV), pp
Flownet: Learning optical flow with convolutional networks, in: Proc. IEEE International Conference on Computer Vision (ICCV), pp. 2758–2766. URL:https: //openaccess.thecvf.com/content_iccv_2015/html/Dosovitskiy_FlowNet_Learning_Optical_ICCV_2015_paper.html. Dosovitskiy,A.,etal.,2021. Animageisworth16x16words:Transformersforimagerecognitionatscale,in:Inte...
2021
-
[7]
Introducing transfer learning to 3d resnet-18 for alzheimer’s disease detection on mri images, in: 2020 35th international conference on image and vision computing New Zealand (IVCNZ), IEEE. pp. 1–6. Farnebäck, G.,
2020
-
[8]
arXiv preprint arXiv:1608.08711
Engagement detection in meetings. arXiv preprint arXiv:1608.08711 . Fredricks, J.A., Blumenfeld, P.C., Paris, A.H.,
-
[9]
Review of Educational Research 74, 59–109
School engagement: Potential of the concept, state of the evidence. Review of Educational Research 74, 59–109. Gortazar,L.,Hupkau,C.,Roldán-Monés,A.,2024. Onlinetutoringworks:Experimentalevidencefromaprogramwithvulnerablechildren. Journal of Public Economics 232, 105082. Gupta, A., D’Mello, S., Stephen, J., et al.,
2024
-
[10]
arXiv preprint arXiv:1609.01885 (2016)
Daisee: Towards user engagement recognition in the wild. arXiv:1609.01885. Hager,K.D.,2012. Self-monitoringasastrategytoincreasestudentteachers’useofeffectiveteachingpractices. RuralSpecialEducationQuarterly 31, 9–17. Hara, K., Kataoka, H., Satoh, Y.,
-
[11]
Hasnine,M.N.,Bui,H.T.,Tran,T.T.T.,Nguyen,H.T.,Akçapınar,G.,Ueda,H.,2021
Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?, in: CVPR. Hasnine,M.N.,Bui,H.T.,Tran,T.T.T.,Nguyen,H.T.,Akçapınar,G.,Ueda,H.,2021. Students’emotionextractionandvisualizationforengagement detection in online learning. Procedia Computer Science 192, 3423–3431. He, K., Zhang, X., Ren, S., Sun, J.,
2021
-
[12]
1971–1980
A hierarchical deep temporal model for group activity recognition, in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1971–1980. Ilse,M.,Tomczak,J.,Welling,M.,2018. Attention-baseddeepmultipleinstancelearning,in:Internationalconferenceonmachinelearning,PMLR. pp. 2127–2136. Jiang,X.,Qing,L.,Huang,J.,Guo,L.,Peng,Y.,2024. Unveilinggro...
1971
-
[13]
The Kinetics Human Action Video Dataset
Pathways to engagement: A longitudinal study of the first-year student experience in the educational interface. Higher Education 79, 657–673. Kay,W.,Carreira,J.,Simonyan,K.,Zhang,B.,Hillier,C.,Vijayanarasimhan,S.,Viola,F.,Green,T.,Back,T.,Natsev,P.,etal.,2017. Thekinetics human action video dataset. arXiv preprint arXiv:1705.06950 . Kingma, D.P., Ba, J.,
work page internal anchor Pith review arXiv 2017
-
[14]
introduces the HD1K optical flow benchmark
URL:https://www.researchgate.net/publication/311755798_The_HCI_Benchmark_Suite_Stereo_and_Flow_Ground_ Truth_with_Uncertainties_for_Urban_Autonomous_Driving, doi:10.1109/CVPRW.2016.10. introduces the HD1K optical flow benchmark. Koonce, B.,
-
[15]
Deep learning-based student engagement detection using cnn, mobile net, resnet50, vgg16, in: 2025 International Conference on Innovations in Intelligent Systems: Advancements in Computing, Communication, and Cybersecurity (ISAC3), IEEE. pp. 1–5. Leiker,A.M.,Miller,M.,Brewer,L.,Nelson,M.,Siow,M.,Lohse,K.,2016. Therelationshipbetweenengagementandneurophysio...
2025
-
[16]
Electronic Journal of E-Learning 20, 1–18
The shift to online classes during the covid-19 pandemic: Benefits, challenges, and required improvements from the students’ perspective. Electronic Journal of E-Learning 20, 1–18. Lin,F.C.,Ngo,H.H.,Dow,C.R.,Lam,K.H.,Le,H.L.,2021. Studentbehaviorrecognitionsystemfortheclassroomenvironmentbasedonskeleton pose estimation and person detection. Sensors 21,
2021
-
[17]
doi:10.1038/s41597-025-04987-w. dataset descriptor. Matz-Costa, C., Cosner Berzin, S., Pitt-Catsouphes, M., Halvorsen, C.J.,
-
[18]
Perceptions of the meaningfulness of work among older social purpose workers: an ecological momentary assessment study. Journal of Applied Gerontology 38, 1121–1146. Mayer,N.,Ilg,E.,Häusser,P.,Fischer,P.,Cremers,D.,Dosovitskiy,A.,Brox,T.,2016. Alargedatasettotrainconvolutionalnetworksfordisparity, opticalflow,andsceneflowestimation,in:Proc.IEEEConferenceo...
-
[19]
Student engagement detection based on head pose estimation and facial expressions using transfer learning, in: The Proceedings of the International Conference on Smart City Applications, Springer. pp. 246–255. Qi,M.,Wang,Y.,Qin,J.,Li,A.,Luo,J.,VanGool,L.,2019. Stagnet:Anattentivesemanticrnnforgroupactivityandindividualactionrecognition. IEEE Transactions ...
2019
-
[20]
arXiv preprint arXiv:2302.01921
Transformers in action recognition: A review on temporal modeling. arXiv preprint arXiv:2302.01921 . Sharma, P., Joshi, S., Gautam, S., Maharjan, S., Khanal, S.R., Reis, M.C., Barroso, J., de Jesus Filipe, V.M.,
-
[21]
Fostering learning with facial insights: Geometrical approach to real-time learner engagement detection, in: 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), IEEE. pp. 1–6. Simonyan, K., Zisserman, A.,
2024
-
[22]
Sinatra,G.M.,Heddy,B.C.,Lombardi,D.,2015
Two-stream convolutional networks for action recognition in videos, in: Advances in Neural Information Processing Systems (NeurIPS). Sinatra,G.M.,Heddy,B.C.,Lombardi,D.,2015. Thechallengesofdefiningandmeasuringstudentengagementinscience. EducationalPsychologist 50, 1–13. S. K. Chowdhury et al.:Preprint submitted to ElsevierPage 15 of 16 Sinha, D., El-Shar...
2015
-
[23]
Thin mobilenet: An enhanced mobilenet architecture, in: 2019 IEEE 10th annual ubiquitous computing, electronics & mobile communication conference (UEMCON), IEEE. pp. 0280–0285. Stephens,K.,Bors,A.G.,2016.Humangroupactivityrecognitionbasedonmodellingmovingregionsinterdependencies,in:201623rdInternational Conference on Pattern Recognition (ICPR), IEEE. pp. ...
2019
-
[24]
Long range arena: A benchmark for efficient transformers,
Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume, in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8934–8943. Tay,Y.,Dehghani,M.,Abnar,S.,Shen,Y.,Bahri,D.,Pham,P.,Rao,J.,Yang,L.,Ruder,S.,Metzler,D.,2020. Longrangearena:Abenchmarkfor efficient transformers. arXiv preprint arXiv:2011.04006 . Teed, Z., Deng, J.,
-
[25]
Predicting student engagement in classrooms using facial behavioral cues, in: Proceedings of the 1st ACM SIGCHI international workshop on multimodal interaction for education, pp. 33–40. Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser,Ł.,Polosukhin,I.,2017. Attentionisallyouneed,in:Advances in neural information processing systems,...
2017
-
[26]
Computers and Education: Artificial Intelligence 5, 100187
Designing an artificial intelligence tool to understand student engagement based on teacher’s behaviours and movements in video conferencing. Computers and Education: Artificial Intelligence 5, 100187. Wang,D.,Zhu,X.,Liu,J.,Zhang,Z.,Zhou,Y.,2025. Multi-dimensionalconvolutiontransformerforgroupactivityrecognition. MultimediaTools and Applications 84, 27071...
2025
-
[27]
arXiv preprint arXiv:2001.08317 , year=
Simple online and realtime tracking with a deep association metric, in: ICIP, pp. 3645–3649. Wu,N.,Green,B.,Ben,X.,O’Banion,S.,2020. Deeptransformermodelsfortimeseriesforecasting:Theinfluenzaprevalencecase. arXivpreprint arXiv:2001.08317 . Xie, J., Wang, L., Webster, P., Yao, Y., Sun, J., Wang, S., Zhou, H.,
-
[28]
arXiv preprint arXiv:1911.11393
A two-stream end-to-end deep learning network for recognizing atypical visual attention in autism spectrum disorder. arXiv preprint arXiv:1911.11393 . Yan, S., Xiong, Y., Lin, D., 2018a. Spatial temporal graph convolutional networks for skeleton-based action recognition, in: Proceedings of the AAAI conference on artificial intelligence. Yan, X., Ricci, E....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.