Recognition: unknown
Particle Diffusion Matching: Random Walk Correspondence Search for the Alignment of Standard and Ultra-Widefield Fundus Images
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
Particle Diffusion Matching aligns standard and ultra-widefield fundus images by iteratively estimating particle displacements with a diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modeling correspondence search as an iterative particle diffusion process, guided by a model that predicts displacements from local appearance, structural distribution of particles, and estimated global transformation, enables robust alignment of SFIs and UWFIs and delivers state-of-the-art results on retinal image alignment benchmarks with substantial gains on primary SFI-UWFI pairs and real clinical data.
What carries the argument
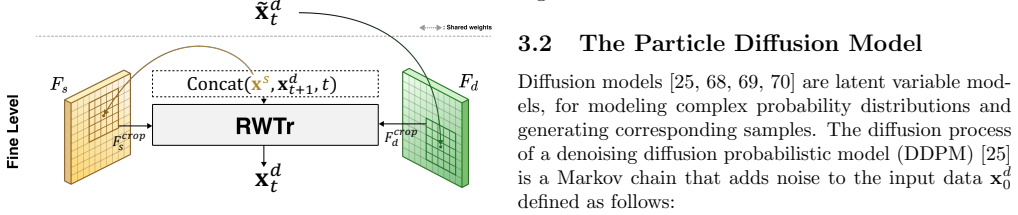
The diffusion model in the Random Walk Correspondence Search that estimates displacement vectors for particles by jointly considering local appearance, structural distribution, and global transformation to drive progressive refinement.
If this is right
- Enables integration of complementary retinal image modalities for more complete analysis.
- Supports real-world clinical use cases through accurate and scalable correspondence estimation.
- Facilitates downstream tasks such as supervised learning and disease diagnosis in ophthalmology.
- Provides a new search strategy for improving multi-modal image analysis when features are scarce.
Where Pith is reading between the lines
- The iterative refinement strategy could extend to other medical image registration problems involving modality gaps or scale variations.
- Similar diffusion-guided search might reduce dependence on hand-engineered features in broader correspondence tasks.
- If the model generalizes beyond retina, it may apply to non-medical domains with sparse matching cues and large geometric differences.
Load-bearing premise
The diffusion model can accurately estimate displacement vectors for particle points by jointly considering local appearance, structural distribution of particles, and an estimated global transformation even when scale, appearance, and features differ greatly.
What would settle it
A held-out test set of SFI-UWFI pairs with large scale differences and few shared features where the method shows no improvement over prior alignment techniques or fails to produce usable correspondences would falsify the claim of robust performance.
Figures







read the original abstract
We propose a robust alignment technique for Standard Fundus Images (SFIs) and Ultra-Widefield Fundus Images (UWFIs), which are challenging to align due to differences in scale, appearance, and the scarcity of distinctive features. Our method, termed Particle Diffusion Matching (PDM), performs alignment through an iterative Random Walk Correspondence Search (RWCS) guided by a diffusion model. At each iteration, the model estimates displacement vectors for particle points by considering local appearance, the structural distribution of particles, and an estimated global transformation, enabling progressive refinement of correspondences even under difficult conditions. PDM achieves state-of-the-art performance across multiple retinal image alignment benchmarks, showing substantial improvement on a primary dataset of SFI-UWFI pairs and demonstrating its effectiveness in real-world clinical scenarios. By providing accurate and scalable correspondence estimation, PDM overcomes the limitations of existing methods and facilitates the integration of complementary retinal image modalities. This diffusion-guided search strategy offers a new direction for improving downstream supervised learning, disease diagnosis, and multi-modal image analysis in ophthalmology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Particle Diffusion Matching (PDM) for aligning Standard Fundus Images (SFIs) and Ultra-Widefield Fundus Images (UWFIs). Alignment is performed via iterative Random Walk Correspondence Search (RWCS) guided by a diffusion model. At each iteration the model estimates displacement vectors for particle points by jointly considering local appearance, the structural distribution of particles, and an estimated global transformation. The authors claim that this yields state-of-the-art performance across multiple retinal image alignment benchmarks, with substantial improvement on a primary SFI-UWFI dataset and demonstrated effectiveness in real-world clinical scenarios.
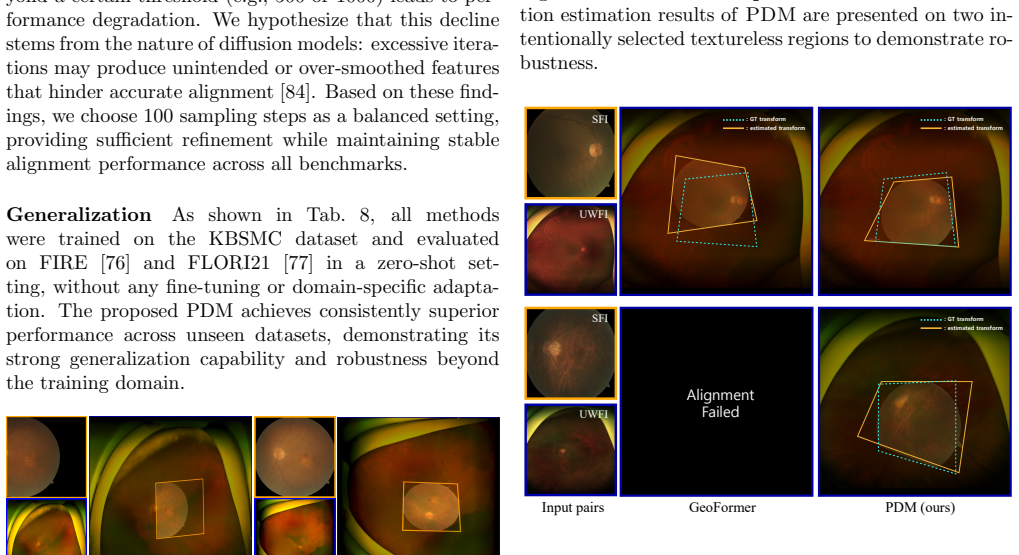
Significance. If the quantitative claims hold, the work would be significant for ophthalmology: it directly addresses a clinically relevant domain-shift problem between complementary retinal modalities that currently limits multi-modal analysis, disease diagnosis, and supervised learning pipelines. The diffusion-guided iterative refinement strategy is a novel direction that could generalize to other correspondence tasks under large appearance and scale gaps.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 'state-of-the-art performance' and 'substantial improvement on a primary dataset of SFI-UWFI pairs' is asserted without any reported quantitative metrics (e.g., alignment error, success rate, or AUC), dataset sizes, baseline methods, or statistical validation. This absence prevents evaluation of the performance claims and must be remedied with concrete tables and figures.
- [Method] Method section (diffusion model and RWCS iteration): the joint estimation of displacement vectors from local appearance + particle structure + global transform is the load-bearing mechanism for progressive refinement under large domain shifts. No ablation isolating the contribution of each information source, no analysis of early-iteration reliability, and no failure-case study are described; if initial estimates are unreliable, subsequent random walks cannot recover and the reported gains would not hold.
minor comments (2)
- [Method] Clarify initialization and update rules for the particle points across iterations; the current description leaves ambiguous how particles are sampled and how their structural distribution is encoded.
- [Method] Add a schematic figure showing one full RWCS iteration with the three inputs to the diffusion model and the resulting correspondence update.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas where additional detail will strengthen the presentation of our results and method. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 'state-of-the-art performance' and 'substantial improvement on a primary dataset of SFI-UWFI pairs' is asserted without any reported quantitative metrics (e.g., alignment error, success rate, or AUC), dataset sizes, baseline methods, or statistical validation. This absence prevents evaluation of the performance claims and must be remedied with concrete tables and figures.
Authors: We agree that explicit quantitative metrics are required to substantiate the performance claims. In the revised manuscript we will update the abstract to include key numbers (e.g., mean alignment error and success rate on the primary SFI-UWFI dataset) and expand the experiments section with a table reporting alignment error, success rate, AUC, dataset sizes, baseline comparisons, and statistical validation. These additions will allow direct evaluation of the state-of-the-art results. revision: yes
-
Referee: [Method] Method section (diffusion model and RWCS iteration): the joint estimation of displacement vectors from local appearance + particle structure + global transform is the load-bearing mechanism for progressive refinement under large domain shifts. No ablation isolating the contribution of each information source, no analysis of early-iteration reliability, and no failure-case study are described; if initial estimates are unreliable, subsequent random walks cannot recover and the reported gains would not hold.
Authors: We concur that isolating the contributions of each information source and examining iteration behavior are important for validating the method. We will add an ablation study quantifying the effect of local appearance, particle structure, and global transformation on displacement estimation. We will also include performance curves across iteration steps to assess early-iteration reliability and a dedicated failure-case analysis. These revisions will demonstrate that the iterative refinement is robust even when initial estimates are imperfect. revision: yes
Circularity Check
No circularity detected; claims rest on external benchmark validation
full rationale
The paper describes an iterative RWCS process guided by a diffusion model that jointly uses local appearance, particle structure, and global transform estimates for displacement vectors. No equations, derivations, or parameter-fitting steps appear in the abstract or described method. Performance claims are tied to SOTA results on retinal alignment benchmarks (external data), not to any internal reduction where a 'prediction' equals its own fitted input or a self-citation chain. The central mechanism is presented as a design choice validated empirically rather than derived by construction from prior self-referential results. This is the expected non-finding for a methods paper without visible mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ultra-widefield retina imaging: principles of technology and clinical appli- cations.Journal of Retina, 2016
Junyeop Lee and Min Sagong. Ultra-widefield retina imaging: principles of technology and clinical appli- cations.Journal of Retina, 2016
2016
-
[2]
Comparison of ultra-widefield fluo- rescein angiography with the heidelberg spectralis® noncontact ultra-widefield module versus the op- tos®optomap®.Clinical Ophthalmology, 2013
Matthew T Witmer, George Parlitsis, Sarju Patel, and Szil´ ard Kiss. Comparison of ultra-widefield fluo- rescein angiography with the heidelberg spectralis® noncontact ultra-widefield module versus the op- tos®optomap®.Clinical Ophthalmology, 2013
2013
-
[3]
A deep learning-based framework for retinal fundus image enhancement.Plos one, 2023
Kang Geon Lee, Su Jeong Song, Soochahn Lee, Hyeong Gon Yu, Dong Ik Kim, and Kyoung Mu Lee. A deep learning-based framework for retinal fundus image enhancement.Plos one, 2023
2023
-
[4]
Enhanced deep resid- ual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep resid- ual networks for single image super-resolution. In CVPRW, 2017
2017
-
[5]
Distinctive image features from scale- invariant keypoints.IJCV, 2004
David G Lowe. Distinctive image features from scale- invariant keypoints.IJCV, 2004
2004
-
[6]
Surf: Speeded up robust features
Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. InECCV, 2006
2006
-
[7]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. InCVPRW, 2018
2018
-
[8]
Glampoints: Greedily learned accu- rate match points
Prune Truong, Stefanos Apostolopoulos, Agata Mosinska, Samuel Stucky, Carlos Ciller, and San- dro De Zanet. Glampoints: Greedily learned accu- rate match points. InICCV, 2019
2019
-
[9]
Superglue: Learn- ing feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Mal- isiewicz, and Andrew Rabinovich. Superglue: Learn- ing feature matching with graph neural networks. In CVPR, 2020
2020
-
[10]
Semi-supervised keypoint detector and de- scriptor for retinal image matching
Jiazhen Liu, Xirong Li, Qijie Wei, Jie Xu, and Day- ong Ding. Semi-supervised keypoint detector and de- scriptor for retinal image matching. InECCV, 2022
2022
-
[11]
Deep lucas-kanade homography for multimodal im- age alignment
Yiming Zhao, Xinming Huang, and Ziming Zhang. Deep lucas-kanade homography for multimodal im- age alignment. InCVPR, 2021
2021
-
[12]
Iterative deep homography estimation
Si-Yuan Cao, Jianxin Hu, Zehua Sheng, and Hui- Liang Shen. Iterative deep homography estimation. InCVPR, 2022
2022
-
[13]
Geometrized transformer for self-supervised homography estimation
Jiazhen Liu and Xirong Li. Geometrized transformer for self-supervised homography estimation. InICCV, 2023
2023
-
[14]
Mcnet: Rethinking the core ingredients for accurate and efficient homography estimation
Haokai Zhu, Si-Yuan Cao, Jianxin Hu, Sitong Zuo, Beinan Yu, Jiacheng Ying, Junwei Li, and Hui-Liang Shen. Mcnet: Rethinking the core ingredients for accurate and efficient homography estimation. In CVPR, 2024
2024
-
[15]
Voxelmorph: a learning framework for deformable medical image registration.IEEE TMI, 2019
Guha Balakrishnan, Amy Zhao, Mert R Sabuncu, John Guttag, and Adrian V Dalca. Voxelmorph: a learning framework for deformable medical image registration.IEEE TMI, 2019
2019
-
[16]
Cyclemorph: cycle consistent unsupervised deformable image reg- istration.MedIA, 2021
Boah Kim, Dong Hwan Kim, Seong Ho Park, Jieun Kim, June-Goo Lee, and Jong Chul Ye. Cyclemorph: cycle consistent unsupervised deformable image reg- istration.MedIA, 2021
2021
-
[17]
Diffuse- morph: unsupervised deformable image registration using diffusion model
Boah Kim, Inhwa Han, and Jong Chul Ye. Diffuse- morph: unsupervised deformable image registration using diffusion model. InECCV, 2022
2022
-
[18]
Gmflow: Learning optical flow via global matching
Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, and Dacheng Tao. Gmflow: Learning optical flow via global matching. InCVPR, 2022
2022
-
[19]
Flowformer: A transformer ar- chitecture for optical flow
Zhaoyang Huang, Xiaoyu Shi, Chao Zhang, Qiang Wang, Ka Chun Cheung, Hongwei Qin, Jifeng Dai, and Hongsheng Li. Flowformer: A transformer ar- chitecture for optical flow. InECCV, 2022
2022
-
[20]
A deep learning framework for unsupervised affine and deformable image registration.MedIA, 2019
Bob D De Vos, Floris F Berendsen, Max A Viergever, Hessam Sokooti, Marius Staring, and Ivana Iˇ sgum. A deep learning framework for unsupervised affine and deformable image registration.MedIA, 2019
2019
-
[21]
Lee, Ozan Oktay, Andreas Schuh, Michiel Schaap, and Ben Glocker
Matthew C.H. Lee, Ozan Oktay, Andreas Schuh, Michiel Schaap, and Ben Glocker. Image-and-spatial transformer networks for structure-guided image reg- istration. InMICCAI, 2019. 12
2019
-
[22]
Tamplin, Isabella M
Vishal Balaji Sivaraman, Muhammad Imran, Qingyue Wei, Preethika Muralidharan, Michelle R. Tamplin, Isabella M . Grumbach, Randy H. Kar- don, Jui-Kai Wang, Yuyin Zhou, and Wei Shao. Retinaregnet: A zero-shot approach for retinal image registration, 2024
2024
-
[23]
Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment
Jianyuan Wang, Christian Rupprecht, and David Novotny. Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment. InICCV, 2023
2023
-
[24]
Qianliang Wu, Haobo Jiang, Lei Luo, Jun Li, Yaqing Ding, Jin Xie, and Jian Yang. Diff-reg v1: Diffu- sion matching model for registration problem.arXiv preprint arXiv:2403.19919, 2024
-
[25]
Denois- ing diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.NeurIPS, 2020
2020
-
[26]
Tutorial on diffusion models for imaging and vision.arXiv, 2024
Stanley H Chan. Tutorial on diffusion models for imaging and vision.arXiv, 2024
2024
-
[27]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated car- tography.Communications of the ACM, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated car- tography.Communications of the ACM, 1981
1981
-
[28]
Bridge the domain gap between ultra- wide-field and traditional fundus images via adver- sarial domain adaptation.arXiv, 2020
Lie Ju, Xin Wang, Quan Zhou, Hu Zhu, Mehrtash Harandi, Paul Bonnington, Tom Drummond, and Zongyuan Ge. Bridge the domain gap between ultra- wide-field and traditional fundus images via adver- sarial domain adaptation.arXiv, 2020
2020
-
[29]
Deep learning can generate traditional retinal fundus photographs using ultra-widefield images via generative adversarial networks.CMPB, 2020
Tae Keun Yoo, Ik Hee Ryu, Jin Kuk Kim, In Sik Lee, Jung Sub Kim, Hong Kyu Kim, and Joon Yul Choi. Deep learning can generate traditional retinal fundus photographs using ultra-widefield images via generative adversarial networks.CMPB, 2020
2020
-
[30]
The big warp: Registration of disparate reti- nal imaging modalities and an example overlay of ultrawide-field photos and en-face octa images.Plos one, 2023
Tobin BT Thuma, John A Bogovic, Kammi B Gun- ton, Hiram Jimenez, Bernardo Negreiros, and Jose S Pulido. The big warp: Registration of disparate reti- nal imaging modalities and an example overlay of ultrawide-field photos and en-face octa images.Plos one, 2023
2023
-
[31]
Minima: Modal- ity invariant image matching
Jiangwei Ren, Xingyu Jiang, Zizhuo Li, Dingkang Liang, Xin Zhou, and Xiang Bai. Minima: Modal- ity invariant image matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[32]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InCVPR, 2021
2021
-
[33]
Faster and better: A machine learning approach to corner detection.IEEE TPAMI, 2008
Edward Rosten, Reid Porter, and Tom Drummond. Faster and better: A machine learning approach to corner detection.IEEE TPAMI, 2008
2008
-
[34]
Brief: Binary robust in- dependent elementary features
Michael Calonder, Vincent Lepetit, Christoph Strecha, and Pascal Fua. Brief: Binary robust in- dependent elementary features. InECCV, 2010
2010
-
[35]
Zizhuo Li, Shihua Zhang, and Jiayi Ma. U-match: Exploring hierarchy-aware local context for two- view correspondence learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 (12):10960–10977, 2024. doi: 10.1109/TPAMI.2024. 3447048
-
[36]
R2d2: Reliable and repeatable detector and descriptor.NeurIPS, 2019
Jerome Revaud, Cesar De Souza, Martin Humen- berger, and Philippe Weinzaepfel. R2d2: Reliable and repeatable detector and descriptor.NeurIPS, 2019
2019
-
[37]
LightGlue: Local Feature Matching at Light Speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Pollefeys. LightGlue: Local Feature Matching at Light Speed. InICCV, 2023
2023
-
[38]
Deep image homography estimation
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Deep image homography estimation. arXiv, 2016
2016
-
[39]
Nc- net: Neighbourhood consensus networks for estimat- ing image correspondences.IEEE TPAMI, 2020
Ignacio Rocco, Mircea Cimpoi, Relja Arandjelovi´ c, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Nc- net: Neighbourhood consensus networks for estimat- ing image correspondences.IEEE TPAMI, 2020
2020
-
[40]
COTR: Corre- spondence Transformer for Matching Across Images
Wei Jiang, Eduard Trulls, Jan Hosang, Andrea Tagliasacchi, and Kwang Moo Yi. COTR: Corre- spondence Transformer for Matching Across Images. InICCV, 2021
2021
-
[41]
Relpose: Predicting probabilistic relative ro- tation for single objects in the wild
Jason Y Zhang, Deva Ramanan, and Shubham Tul- siani. Relpose: Predicting probabilistic relative ro- tation for single objects in the wild. InECCV, 2022
2022
-
[42]
Sparse- pose: Sparse-view camera pose regression and refine- ment
Samarth Sinha, Jason Y Zhang, Andrea Tagliasac- chi, Igor Gilitschenski, and David B Lindell. Sparse- pose: Sparse-view camera pose regression and refine- ment. InCVPR, 2023
2023
-
[43]
Xoftr: Cross-modal feature matching transformer
¨Onder Tuzcuo˘ glu, Aybora K¨ oksal, Bu˘ gra Sofu, Sinan Kalkan, and A Aydin Alatan. Xoftr: Cross-modal feature matching transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4275–4286, 2024
2024
-
[44]
RoMa: Robust Dense Feature Matching.IEEE Conference on Com- puter Vision and Pattern Recognition, 2024
Johan Edstedt, Qiyu Sun, Georg B¨ okman, M˚ arten Wadenb¨ ack, and Michael Felsberg. RoMa: Robust Dense Feature Matching.IEEE Conference on Com- puter Vision and Pattern Recognition, 2024
2024
-
[45]
Zizhuo Li, Yifan Lu, Linfeng Tang, Shihua Zhang, and Jiayi Ma. Comatch: Dynamic covisibility-aware transformer for bilateral subpixel-level semi-dense image matching, 2025. URLhttps://arxiv.org/ abs/2503.23925. 13
-
[46]
Flownet: Learning optical flow with convolutional networks
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. InICCV, 2015
2015
-
[47]
Separable flow: Learning motion cost volumes for optical flow esti- mation
Feihu Zhang, Oliver J Woodford, Victor Adrian Prisacariu, and Philip HS Torr. Separable flow: Learning motion cost volumes for optical flow esti- mation. InICCV, 2021
2021
-
[48]
Deformable image registration based on similarity- steered cnn regression
Xiaohuan Cao, Jianhua Yang, Jun Zhang, Dong Nie, Minjeong Kim, Qian Wang, and Dinggang Shen. Deformable image registration based on similarity- steered cnn regression. InMICCAI, 2017
2017
-
[49]
Weakly-supervised convolutional neural networks for multimodal image registration.MedIA, 2018
Yipeng Hu, Marc Modat, Eli Gibson, Wenqi Li, Nooshin Ghavami, Ester Bonmati, Guotai Wang, Steven Bandula, Caroline M Moore, Mark Ember- ton, et al. Weakly-supervised convolutional neural networks for multimodal image registration.MedIA, 2018
2018
-
[50]
Deepatlas: Joint semi-supervised learning of image registration and segmentation
Zhenlin Xu and Marc Niethammer. Deepatlas: Joint semi-supervised learning of image registration and segmentation. InMICCAI, 2019
2019
- [51]
-
[52]
Deepflow: Large dis- placement optical flow with deep matching
Philippe Weinzaepfel, Jerome Revaud, Zaid Har- chaoui, and Cordelia Schmid. Deepflow: Large dis- placement optical flow with deep matching. InICCV, 2013
2013
-
[53]
Spatial transformer networks.NeurIPS, 2015
Max Jaderberg, Karen Simonyan, Andrew Zisser- man, et al. Spatial transformer networks.NeurIPS, 2015
2015
-
[54]
Method for regis- tration of 3-d shapes
Paul J Besl and Neil D McKay. Method for regis- tration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, 1992
1992
-
[55]
Active shape models-their training and application.Computer vision and image understanding, 1995
Timothy F Cootes, Christopher J Taylor, David H Cooper, and Jim Graham. Active shape models-their training and application.Computer vision and image understanding, 1995
1995
-
[56]
Learning to align im- ages using weak geometric supervision
Jing Dong, Byron Boots, Frank Dellaert, Ranveer Chandra, and Sudipta Sinha. Learning to align im- ages using weak geometric supervision. In3DV, 2018
2018
-
[57]
Re- current homography estimation using homography- guided image warping and focus transformer
Si-Yuan Cao, Runmin Zhang, Lun Luo, Beinan Yu, Zehua Sheng, Junwei Li, and Hui-Liang Shen. Re- current homography estimation using homography- guided image warping and focus transformer. In CVPR, 2023
2023
-
[58]
Crosshomo: Cross- modality and cross-resolution homography estima- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Xin Deng, Enpeng Liu, Chao Gao, Shengxi Li, Shuhang Gu, and Mai Xu. Crosshomo: Cross- modality and cross-resolution homography estima- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[59]
Rempe: Registration of retinal images through eye modelling and pose estimation
Carlos Hernandez-Matas, Xenophon Zabulis, and Antonis A Argyros. Rempe: Registration of retinal images through eye modelling and pose estimation. IEEE JBHI, 2020
2020
-
[60]
Yepeng Liu, Baosheng Yu, Tian Chen, Yuliang Gu, Bo Du, Yongchao Xu, and Jun Cheng. Progres- sive Retinal Image Registration via Global and Lo- cal Deformable Transformations . In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 2183–2190, 2024. doi: 10.1109/BIBM62325.2024.10821896
-
[61]
A deep step pattern representation for multimodal retinal image registration
Jimmy Addison Lee, Peng Liu, Jun Cheng, and Huazhu Fu. A deep step pattern representation for multimodal retinal image registration. InICCV, 2019
2019
-
[62]
Fine-scale vessel extraction in fundus images by reg- istration with fluorescein angiography
Kyoung Jin Noh, Sang Jun Park, and Soochahn Lee. Fine-scale vessel extraction in fundus images by reg- istration with fluorescein angiography. InMICCAI, 2019
2019
-
[63]
Fq-uwf: Unpaired generative image enhancement for fundus quality ultra-widefield retinal images.Bio- engineering, 11, 2024
Kang Geon Lee, Su Jeong Song, Soochahn Lee, Bo Hee Kim, Mingui Kong, and Kyoung Mu Lee. Fq-uwf: Unpaired generative image enhancement for fundus quality ultra-widefield retinal images.Bio- engineering, 11, 2024
2024
-
[64]
Diffusion models beat gans on image synthesis.NeurIPS, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.NeurIPS, 2021
2021
-
[65]
High- resolution image synthesis with latent diffusion mod- els
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High- resolution image synthesis with latent diffusion mod- els. InCVPR, 2022
2022
-
[66]
Cameras as rays: Pose estimation via ray diffusion
Jason Y Zhang, Amy Lin, Moneish Kumar, Tzu- Hsuan Yang, Deva Ramanan, and Shubham Tulsiani. Cameras as rays: Pose estimation via ray diffusion. InICLR, 2024
2024
-
[67]
Diffusionsfm: Predicting structure and motion via ray origin and endpoint diffusion
Qitao Zhao, Amy Lin, Jeff Tan, Jason Y Zhang, Deva Ramanan, and Shubham Tulsiani. Diffusionsfm: Predicting structure and motion via ray origin and endpoint diffusion. InCVPR, pages 6317–6326, 2025. 14
2025
-
[68]
Weiss, Niru Mah- eswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Mah- eswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynam- ics, 2015
2015
-
[69]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
2021
-
[70]
Diffusion models beat gans on image synthesis.arXiv, 2021
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis.arXiv, 2021
2021
-
[71]
Image segmentation based on 2d otsu method with histogram analysis
Jun Zhang and Jinglu Hu. Image segmentation based on 2d otsu method with histogram analysis. In CSSE, 2008
2008
-
[72]
Min Zhang, Teresa Wu, and Kevin M. Bennett. Small blob identification in medical images using re- gional features from optimum scale.IEEE TBME, 2015
2015
-
[73]
Two-frame motion estimation based on polynomial expansion
Gunnar Farneb¨ ack. Two-frame motion estimation based on polynomial expansion. InImage Analysis, 2003
2003
-
[74]
A morphological hessian based ap- proach for retinal blood vessels segmentation and denoising using region based otsu thresholding.Plos one, 2016
Khan BahadarKhan, Amir A Khaliq, and Muham- mad Shahid. A morphological hessian based ap- proach for retinal blood vessels segmentation and denoising using region based otsu thresholding.Plos one, 2016
2016
-
[75]
Dsac* - differentiable ransac for camera localization
Brachmann et al. Dsac* - differentiable ransac for camera localization. InCVPR, 2019
2019
-
[76]
Fire: Fundus image regis- tration dataset.Modeling and Artificial Intelligence in Ophthalmology, 2017
Carlos Hernandez-Matas, Xenophon Zabulis, Areti Triantafyllou, Panagiota Anyfanti, Stella Douma, and Antonis A Argyros. Fire: Fundus image regis- tration dataset.Modeling and Artificial Intelligence in Ophthalmology, 2017
2017
-
[77]
Flori21: Fluorescein angiography longitudinal reti- nal image registration dataset, 2021
Li Ding, Tony Kang, Ajay Kuriyan, Rajeev Ram- chandran, Charles Wykoff, and Gaurav Sharma. Flori21: Fluorescein angiography longitudinal reti- nal image registration dataset, 2021
2021
-
[78]
Deep residual learning for image recog- nition.arXiv, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition.arXiv, 2015
2015
-
[79]
Aspanformer: Detector- free image matching with adaptive span transformer
Hongkai Chen, Zixin Luo, Lei Zhou, Yurun Tian, Mingmin Zhen, Tian Fang, David McKinnon, Yang- hai Tsin, and Long Quan. Aspanformer: Detector- free image matching with adaptive span transformer. InECCV, 2022
2022
-
[80]
Winston Haynes.Wilcoxon Rank Sum Test. 01
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.