Recognition: unknown
Long-Horizon Streaming Video Generation via Hybrid Attention with Decoupled Distillation
Pith reviewed 2026-05-10 16:06 UTC · model grok-4.3
The pith
Hybrid attention with a compact linear state and block-sparse windows enables real-time unbounded streaming video generation from distilled diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hybrid Forcing uses a hybrid attention design that jointly retains temporal information and improves efficiency: lightweight linear temporal attention maintains a compact key-value state to incrementally absorb evicted tokens beyond the sliding window, block-sparse attention reallocates computation within the local window by skipping redundant dependencies, and a decoupled distillation strategy first performs dense-attention pre-training then activates the linear and sparse components for streaming modeling.
What carries the argument
Hybrid attention consisting of lightweight linear temporal attention that maintains a compact key-value state for long-range context plus block-sparse attention inside the sliding window, trained via a decoupled distillation schedule from a dense bidirectional teacher.
If this is right
- Streaming video models can produce videos of unbounded length without progressive loss of distant history.
- Real-time inference at 29.5 FPS for 832x480 video becomes practical on a single high-end GPU without quantization or compression.
- Distillation pipelines for autoregressive video generators become more stable by separating dense pre-training from hybrid-component training.
- Computational budget can be shifted from redundant local calculations to critical long-term temporal dependencies.
Where Pith is reading between the lines
- The same linear-state plus sparse-window pattern could transfer to other autoregressive modalities such as long audio or 3D scene generation.
- Continuous real-time video synthesis applications, such as interactive content creation, become feasible if the compact state truly scales without bound.
- Empirical tests on multi-minute or hour-long videos would reveal whether the fixed-size KV state eventually saturates or requires periodic resetting.
Load-bearing premise
The lightweight linear temporal attention and block-sparse attention can be stably distilled from the dense bidirectional teacher model while preserving generation quality over arbitrarily long horizons.
What would settle it
Measuring a clear drop in perceptual quality or temporal coherence when generating videos thousands of frames longer than the training horizon, or failing to sustain 29.5 FPS at 832x480 resolution on a single H100 GPU.
Figures












read the original abstract
Streaming video generation (SVG) distills a pretrained bidirectional video diffusion model into an autoregressive model equipped with sliding window attention (SWA). However, SWA inevitably loses distant history during long video generation, and its computational overhead remains a critical challenge to real-time deployment. In this work, we propose Hybrid Forcing, which jointly optimizes temporal information retention and computational efficiency through a hybrid attention design. First, we introduce lightweight linear temporal attention to preserve long-range dependencies beyond the sliding window. In particular, we maintain a compact key-value state to incrementally absorb evicted tokens, retaining temporal context with negligible memory and computational overhead. Second, we incorporate block-sparse attention into the local sliding window to reduce redundant computation within short-range modeling, reallocating computational capacity toward more critical dependencies. Finally, we introduce a decoupled distillation strategy tailored to the hybrid attention design. A few-step initial distillation is performed under dense attention, then the distillation of our proposed linear temporal and block-sparse attention is activated for streaming modeling, ensuring stable optimization. Extensive experiments on both short- and long-form video generation benchmarks demonstrate that Hybrid Forcing consistently achieves state-of-the-art performance. Notably, our model achieves real-time, unbounded 832x480 video generation at 29.5 FPS on a single NVIDIA H100 GPU without quantization or model compression. The source code and trained models are available at https://github.com/leeruibin/hybrid-forcing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hybrid Forcing for streaming video generation, distilling a bidirectional video diffusion model into an autoregressive model with a hybrid attention design: lightweight linear temporal attention (maintaining a compact KV state to absorb evicted tokens for long-range context) combined with block-sparse attention in the local sliding window, trained via a two-stage decoupled distillation procedure. It reports SOTA results on short- and long-form benchmarks and claims real-time unbounded 832x480 video generation at 29.5 FPS on a single H100 GPU without quantization.
Significance. If the empirical results and stability claims hold under scrutiny, the work would advance practical long-horizon video generation by addressing both temporal context retention and computational overhead in a single framework, with the open release of code and models aiding reproducibility. The hybrid design and distillation strategy offer a concrete path toward efficient streaming models.
major comments (2)
- [Experimental results and long-horizon evaluation sections] The central claim of unbounded real-time generation at constant memory depends on the compact linear temporal attention (plus block-sparse local attention) retaining necessary temporal context without capacity limits or drift over arbitrary horizons. However, the manuscript provides no analysis of the KV state's effective capacity (e.g., rank or compression loss) nor quantitative results for perceptual metrics (FVD, CLIP-T, temporal consistency) as a function of horizon length beyond the reported benchmarks.
- [Method and distillation procedure sections] The decoupled distillation strategy is described as performing initial dense-attention distillation followed by activation of linear temporal and block-sparse components, but no ablation or stability analysis is given for how this two-stage process prevents optimization issues specific to the hybrid design during streaming.
minor comments (2)
- [Abstract] The abstract states 'consistently achieves state-of-the-art performance' without listing the specific quantitative margins or baseline comparisons; adding a brief table reference or key metric deltas would improve clarity.
- [Hybrid attention design] Notation for the linear temporal attention state size and block-sparsity ratio is introduced but not explicitly tied to the free parameters listed in the design; a short equation or pseudocode reference would aid readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment in detail below, providing clarifications and committing to revisions that strengthen the presentation of our results and method without altering the core contributions.
read point-by-point responses
-
Referee: [Experimental results and long-horizon evaluation sections] The central claim of unbounded real-time generation at constant memory depends on the compact linear temporal attention (plus block-sparse local attention) retaining necessary temporal context without capacity limits or drift over arbitrary horizons. However, the manuscript provides no analysis of the KV state's effective capacity (e.g., rank or compression loss) nor quantitative results for perceptual metrics (FVD, CLIP-T, temporal consistency) as a function of horizon length beyond the reported benchmarks.
Authors: We appreciate the referee's emphasis on rigorously validating the long-horizon claims. Our long-form benchmarks already include extended sequences that exceed typical short-clip evaluations, and the compact KV state is designed to incrementally absorb evicted tokens with fixed memory footprint. However, we acknowledge that explicit analysis of the state's effective capacity (e.g., via rank or reconstruction metrics) and metric trends versus horizon length would provide stronger quantitative support. In the revised manuscript, we will add plots of FVD, CLIP-T, and temporal consistency as functions of increasing horizon length on long-form data, along with a brief discussion of the linear attention state's compression properties derived from its incremental update rule. These additions will directly address the concern while preserving the existing SOTA results. revision: yes
-
Referee: [Method and distillation procedure sections] The decoupled distillation strategy is described as performing initial dense-attention distillation followed by activation of linear temporal and block-sparse components, but no ablation or stability analysis is given for how this two-stage process prevents optimization issues specific to the hybrid design during streaming.
Authors: We agree that additional analysis of the distillation procedure would enhance clarity. The two-stage decoupled approach first stabilizes the model under dense attention to establish reliable gradients before activating the hybrid linear and block-sparse components, thereby avoiding the instability that can arise from jointly optimizing sparse patterns and incremental KV updates from the start. In the revision, we will include an ablation comparing the two-stage procedure against a single-stage joint optimization, reporting training loss curves, gradient norms, and final generation quality to demonstrate improved stability. This will substantiate how the decoupling mitigates hybrid-specific optimization challenges without requiring changes to the core method. revision: yes
Circularity Check
No circularity: empirical architecture proposal with external benchmarks
full rationale
The paper introduces Hybrid Forcing as a practical distillation procedure combining linear temporal attention, block-sparse attention, and a two-stage decoupled training schedule. All claims rest on measured performance (FPS, FVD, CLIP scores) against standard video generation benchmarks rather than any closed-form derivation or self-referential prediction. No equations are presented that equate a fitted quantity to its own input, and no uniqueness theorem or ansatz is imported via self-citation to force the design. The method is self-contained against external evaluation protocols.
Axiom & Free-Parameter Ledger
free parameters (2)
- linear temporal attention state size
- block-sparsity ratio
axioms (1)
- domain assumption A pretrained bidirectional video diffusion model can be effectively distilled into an autoregressive streaming model without catastrophic quality loss
Forward citations
Cited by 1 Pith paper
-
SWIFT: Prompt-Adaptive Memory for Efficient Interactive Long Video Generation
SWIFT introduces a semantic injection cache with head-wise updates and an adaptive dynamic window plus segment anchors to achieve efficient multi-prompt long video generation at 22.6 FPS while preserving quality in ca...
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Forty-first International Conference on Machine Learning (2024)
Bruce, J., Dennis, M.D., Edwards, A., Parker-Holder, J., Shi, Y., Hughes, E., Lai, M., Mavalankar, A., Steigerwald, R., Apps, C., et al.: Genie: Generative interactive environments. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[3]
Advances in Neural Information Processing Systems37, 24081–24125 (2024)
Chen, B., Martí Monsó, D., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems37, 24081–24125 (2024)
2024
-
[4]
SkyReels-V2: Infinite-length Film Generative Model
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al.: Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074 (2025)
work page internal anchor Pith review arXiv 2025
-
[5]
Sana-video: Efficient video generation with block linear diffusion transformer, 2025 b
Chen, J., Zhao, Y., Yu, J., Chu, R., Chen, J., Yang, S., Wang, X., Pan, Y., Zhou, D.,Ling,H.,etal.:Sana-video:Efficientvideogenerationwithblocklineardiffusion transformer. arXiv preprint arXiv:2509.24695 (2025)
-
[6]
arXiv preprint arXiv:2510.02283 (2025)
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
-
[7]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Dalal, K., Koceja, D., Xu, J., Zhao, Y., Han, S., Cheung, K.C., Kautz, J., Choi, Y., Sun, Y., Wang, X.: One-minute video generation with test-time training. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 17702– 17711 (2025)
2025
-
[8]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[9]
Autoregressive Video Gen- eration Without Vector Quantization
Deng, H., Pan, T., Diao, H., Luo, Z., Cui, Y., Lu, H., Shan, S., Qi, Y., Wang, X.: Autoregressive video generation without vector quantization. arXiv preprint arXiv:2412.14169 (2024)
-
[10]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Dong, J., Feng, B., Guessous, D., Liang, Y., He, H.: Flex attention: A programming model for generating optimized attention kernels. arXiv preprint arXiv:2412.05496 2(3), 4 (2024)
-
[11]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
work page internal anchor Pith review arXiv 2025
-
[12]
googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf
Google: Veo: a text-to-video generation system (2025),https : / / storage . googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf
2025
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and ex- tendable long video generation from text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2568–2577 (2025)
2025
-
[14]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
Hong, Y., Mei, Y., Ge, C., Xu, Y., Zhou, Y., Bi, S., Hold-Geoffroy, Y., Roberts, M., Fisher, M., Shechtman, E., et al.: Relic: Interactive video world model with long-horizon memory. arXiv preprint arXiv:2512.04040 (2025)
-
[15]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review arXiv 2025
-
[16]
arXiv preprint arXiv:2512.14699 (2025) Head Forcing 17
Ji, S., Chen, X., Yang, S., Tao, X., Wan, P., Zhao, H.: Memflow: Flowing adap- tive memory for consistent and efficient long video narratives. arXiv preprint arXiv:2512.14699 (2025) 16 R. Li et al
-
[17]
Jin, Y., Sun, Z., Li, N., Xu, K., Jiang, H., Zhuang, N., Huang, Q., Song, Y., Mu, Y., Lin, Z.: Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954 (2024)
-
[18]
Advances in neural information processing systems35, 26565–26577 (2022)
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. Advances in neural information processing systems35, 26565–26577 (2022)
2022
-
[19]
Kling: Kling ai: Next-generation ai creative studio.https://klingai.com/cn/ (2026)
2026
-
[20]
Streamdit: Real-time streaming text-to-video generation
Kodaira, A., Hou, T., Hou, J., Georgopoulos, M., Juefei-Xu, F., Tomizuka, M., Zhao, Y.: Streamdit: Real-time streaming text-to-video generation. arXiv preprint arXiv:2507.03745 (2025)
-
[21]
ArXiv (2024)
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., Wu, K., Lin, Q., Wang, A., Wang, A., Li, C., Huang, D., Yang, F., Tan, H., Wang, H., Song, J., Bai, J., Wu, J., Xue, J., Wang, J., Yuan, J., Wang, K., Liu, M., Li, P., Li, S., Wang, W., Yu, W., Deng, X., Li, Y., Long, Y., Chen, Y., Cui, Y., Peng, Y., Yu, Z., H...
2024
-
[22]
In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference
Li, R., Yang, T., Guo, S., Zhang, L.: Rorem: Training a robust object remover with human-in-the-loop. In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference. pp. 14024–14035 (2025)
2025
-
[23]
arXiv preprint arXiv:2506.01758 (2025)
Li, R., Yang, T., Shi, Y., Zhang, Y., Dong, Q., Cheng, H., Feng, W., Wen, S., Peng, B., Zhang, L.: Many-for-many: Unify the training of multiple video and image generation and manipulation tasks. arXiv preprint arXiv:2506.01758 (2025)
-
[24]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Liu, K., Hu, W., Xu, J., Shan, Y., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025)
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[28]
ltx2: ltx2.https://ltx.io/model/ltx-2(2026)
2026
-
[29]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Lu, C., Song, Y.: Simplifying, stabilizing and scaling continuous-time consistency models. arXiv preprint arXiv:2410.11081 (2024)
work page internal anchor Pith review arXiv 2024
-
[30]
Advances in Neural Information Processing Systems37, 131434–131455 (2024)
Lu, Y., Liang, Y., Zhu, L., Yang, Y.: Freelong: Training-free long video generation with spectralblend temporal attention. Advances in Neural Information Processing Systems37, 131434–131455 (2024)
2024
-
[31]
Lu, Y., Zeng, Y., Li, H., Ouyang, H., Wang, Q., Cheng, K.L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., et al.: Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678 (2025)
-
[32]
com/sora
OpenAI: Video generation models as world simulators (2024),https://openai. com/sora
2024
-
[33]
Open-sora 2.0: Training a commercial-level video generation model in $200 k
Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., Wang, Y., Ye, A., Ren, G., Ma, Q., Liang, W., Lian, X., Wu, X., Zhong, Y., Li, Z., Gong, C., Lei, G., Cheng, L., Zhang, L., Li, M., Zhang, R., Fast Stream Video Generation with Hybrid Attention 17 Hu, S., Huang, S., Wang, X., Zhao, Y., Wang, Y., Wei, Z., You, ...
-
[34]
org / blog / triton - kernel - compilation - stages(2026)
Pytorch: Triton.https : / / pytorch . org / blog / triton - kernel - compilation - stages(2026)
2026
-
[35]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al.: Gated attention for large language models: Non- linearity, sparsity, and attention-sink-free. arXiv preprint arXiv:2505.06708 (2025)
work page internal anchor Pith review arXiv 2025
-
[36]
RunwayML: Gen-3 by runway (2023),https://research.runwayml.com/gen3
2023
-
[37]
Sand-AI: Autoregressive video generation at scale (2025)
2025
-
[38]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[40]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[41]
Kimi Linear: An Expressive, Efficient Attention Architecture
Team, K., Zhang, Y., Lin, Z., Yao, X., Hu, J., Meng, F., Liu, C., Men, X., Yang, S., Li, Z., et al.: Kimi linear: An expressive, efficient attention architecture. arXiv preprint arXiv:2510.26692 (2025)
work page internal anchor Pith review arXiv 2025
-
[42]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Advances in Neural Information Processing Systems37, 65618–65642 (2024)
Wang, W., Yang, Y.: Vidprom: A million-scale real prompt-gallery dataset for text- to-video diffusion models. Advances in Neural Information Processing Systems37, 65618–65642 (2024)
2024
-
[44]
International Journal of Computer Vision133(5), 3059–3078 (2025)
Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffu- sion models. International Journal of Computer Vision133(5), 3059–3078 (2025)
2025
-
[45]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[46]
Wu, T., Li, R., Zhang, L., Ma, K.: Diversity-preserved distribution matching dis- tillation for fast visual synthesis. arXiv preprint arXiv:2602.03139 (2026)
-
[47]
Xi, H., Yang, S., Zhao, Y., Xu, C., Li, M., Li, X., Lin, Y., Cai, H., Zhang, J., Li, D., et al.: Sparse videogen: Accelerating video diffusion transformers with spatial- temporal sparsity. arXiv preprint arXiv:2502.01776 (2025)
-
[48]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xia, Y., Ling, S., Fu, F., Wang, Y., Li, H., Xiao, X., Cui, B.: Training-free and adaptive sparse attention for efficient long video generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15982–15993 (2025)
2025
-
[49]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453 (2023)
work page internal anchor Pith review arXiv 2023
-
[50]
LongLive: Real-time Interactive Long Video Generation
Yang, S., Huang, W., Chu, R., Xiao, Y., Zhao, Y., Wang, X., Li, M., Xie, E., Chen, Y., Lu, Y., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
work page internal anchor Pith review arXiv 2025
-
[51]
Yesiltepe, H., Meral, T.H.S., Akan, A.K., Oktay, K., Yanardag, P.: Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout. arXiv preprint arXiv:2511.20649 (2025)
-
[52]
Li et al
Yin, S., Wu, C., Yang, H., Wang, J., Wang, X., Ni, M., Yang, Z., Li, L., Liu, S., Yang, F., et al.: Nuwa-xl: Diffusion over diffusion for extremely long video 18 R. Li et al. generation. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1309–1320 (2023)
2023
-
[53]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yin, T., Gharbi, M., Zhang, R., Shechtman, E., Durand, F., Freeman, W.T., Park, T.: One-step diffusion with distribution matching distillation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6613– 6623 (2024)
2024
-
[54]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 22963– 22974 (2025)
2025
-
[55]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y., Wang, L., Xiao, Z., et al.: Native sparse attention: Hardware-aligned and natively trainable sparse attention. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 23078–23097 (2025)
2025
-
[56]
Gonzalez, Jun Zhu, and Jianfei Chen
Zhang, J., Wang, H., Jiang, K., Yang, S., Zheng, K., Xi, H., Wang, Z., Zhu, H., Zhao, M., Stoica, I., et al.: Sla: Beyond sparsity in diffusion transformers via fine- tunable sparse-linear attention. arXiv preprint arXiv:2509.24006 (2025)
-
[57]
Arxiv (2025)
Zhang, L., Agrawala, M.: Packing input frame contexts in next-frame prediction models for video generation. Arxiv (2025)
2025
-
[58]
VSA: Faster Video Diffusion with Trainable Sparse Attention, October 2025
Zhang, P., Chen, Y., Huang, H., Lin, W., Liu, Z., Stoica, I., Xing, E., Zhang, H.: Vsa: Faster video diffusion with trainable sparse attention. arXiv preprint arXiv:2505.13389 (2025)
-
[59]
Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
Zhang, P., Chen, Y., Su, R., Ding, H., Stoica, I., Liu, Z., Zhang, H.: Fast video generation with sliding tile attention. arXiv preprint arXiv:2502.04507 (2025)
-
[60]
Waver: Wave your way to lifelike video generation,
Zhang, Y., Yang, H., Zhang, Y., Hu, Y., Zhu, F., Lin, C., Mei, X., Jiang, Y., Yuan, Z., Peng, B.: Waver: Wave your way to lifelike video generation. arXiv preprint arXiv:2508.15761 (2025)
-
[61]
Advances in Neural Information Processing Systems36, 49842–49869 (2023)
Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. Advances in Neural Information Processing Systems36, 49842–49869 (2023)
2023
-
[62]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Zheng, K., Wang, Y., Ma, Q., Chen, H., Zhang, J., Balaji, Y., Chen, J., Liu, M.Y., Zhu, J., Zhang, Q.: Large scale diffusion distillation via score-regularized continuous-time consistency. arXiv preprint arXiv:2510.08431 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Zhu, H., Zhao, M., He, G., Su, H., Li, C., Zhu, J.: Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video genera- tion. arXiv preprint arXiv:2602.02214 (2026) Fast Stream Video Generation with Hybrid Attention 19 In this supplementary file, we provide the following materials: –A complete description ...
-
[64]
For overly concise user inputs , r e a s o n a b l y infer and add details
-
[65]
Enhance the main features in user d e s c r i p t i o n s
-
[66]
Output the entire prompt in English
-
[67]
Prompts should match the user ’ s intent
-
[68]
E mp has iz e motion i n f o r m a t i o n
-
[69]
Your output should have natural motion a t t r i b u t e s
-
[70]
The revised prompt should be around 80 -100 words long . 20 R. Li et al. Revised prompt examples :
-
[71]
Japanese - style fresh film photography ,
-
[72]
Anime thick - coated illustration ,
-
[73]
CG game concept digital art ,
-
[74]
I will now provide the prompt for you to rewrite
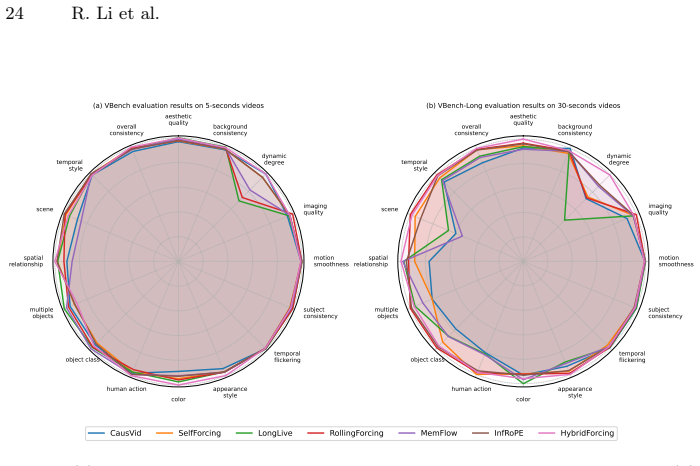
American TV series poster style , ... I will now provide the prompt for you to rewrite ... C Detailed evaluation results on the short VBench benchmark and VBench-Long Benchmark InFig.6,wepresentthedetailedevaluationresultsonVBenchandVBench-Long for representative few-step autoregressive models across all 16 VBench metrics. Overall, our hybrid forcing meth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.