Recognition: unknown
Mask-Free Privacy Extraction and Rewriting: A Domain-Aware Approach via Prototype Learning
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
DAMPER learns domain prototypes via contrastive learning to localize and rewrite private text spans without masks or prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
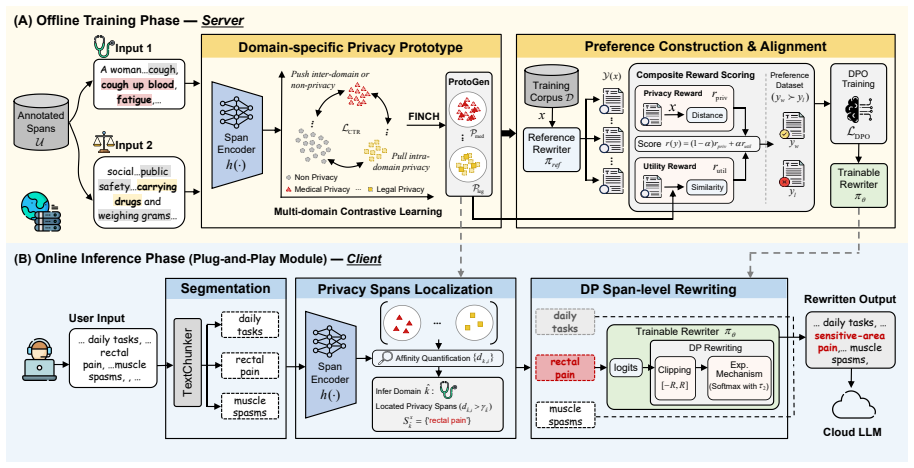
DAMPER operationalizes latent privacy semantics into compact Domain Privacy Prototypes via contrastive learning, enabling precise, autonomous span localization. Furthermore, Prototype-Guided Preference Alignment leverages the learned prototypes as semantic anchors to construct preference pairs, optimizing a domain-compliant rewriting policy without human annotations. At inference time, DAMPER integrates a sampling-based Exponential Mechanism to provide rigorous span-level Differential Privacy guarantees.
What carries the argument
Domain Privacy Prototypes, compact vectors learned via contrastive learning on domain data that anchor both span localization and the construction of preference pairs for rewriting policy optimization.
If this is right
- Private span localization becomes fully autonomous and does not rely on unstable LLM instruction following or static dictionaries.
- A rewriting policy can be optimized directly from prototype-derived preference pairs without any human-labeled data.
- Span-level differential privacy is enforced at inference through the exponential mechanism sampling process.
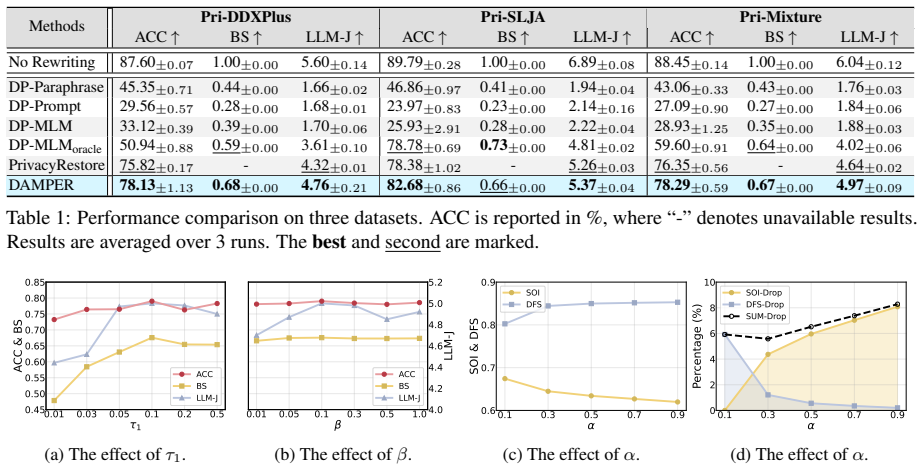
- The overall pipeline delivers a measurable improvement in the privacy-utility trade-off over full-text, mask-based, and prompt-based baselines on domain-specific tasks.
Where Pith is reading between the lines
- The prototype approach could be extended to other alignment objectives, such as reducing toxicity or bias, by swapping the contrastive objective for the target attribute.
- Separate prototype sets could be trained per subdomain and combined at inference to handle mixed-domain inputs.
- If domain data is limited, the contrastive pre-training step might be replaced by few-shot or synthetic data augmentation while preserving the same downstream alignment logic.
- One could test cross-domain transfer by training prototypes on medical notes and evaluating rewriting quality on legal documents to quantify generalization limits.
Load-bearing premise
Contrastive learning on domain data will produce prototypes that reliably separate private from non-private spans without excessive false positives or leakage, and the resulting preference pairs will yield a rewriting policy that generalizes beyond the training distribution.
What would settle it
Apply the learned prototypes to a held-out dataset containing manually annotated private spans and measure whether localization precision falls below the level needed to match or exceed baseline privacy-utility scores while satisfying the differential privacy guarantee.
Figures



















read the original abstract
Client-side privacy rewriting is crucial for deploying LLMs in privacy-sensitive domains. However, existing approaches struggle to balance privacy and utility. Full-text methods often distort context, while span-level approaches rely on impractical manual masks or brittle static dictionaries. Attempts to automate localization via prompt-based LLMs prove unreliable, as they suffer from unstable instruction following that leads to privacy leakage and excessive context scrubbing. To address these limitations, we propose DAMPER (Domain-Aware Mask-free Privacy Extraction and Rewriting). DAMPER operationalizes latent privacy semantics into compact Domain Privacy Prototypes via contrastive learning, enabling precise, autonomous span localization. Furthermore, we introduce a Prototype-Guided Preference Alignment, which leverages learned prototypes as semantic anchors to construct preference pairs, optimizing a domain-compliant rewriting policy without human annotations. At inference time, DAMPER integrates a sampling-based Exponential Mechanism to provide rigorous span-level Differential Privacy (DP) guarantees. Extensive experiments demonstrate that DAMPER significantly outperforms existing baselines, achieving a superior privacy-utility trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAMPER, a domain-aware mask-free method for privacy extraction and rewriting in LLMs. It learns compact Domain Privacy Prototypes via contrastive learning to autonomously localize private spans, then uses Prototype-Guided Preference Alignment to construct preference pairs and optimize a domain-compliant rewriting policy without human annotations. At inference, it applies a sampling-based Exponential Mechanism for span-level differential privacy guarantees. The central claim is that DAMPER significantly outperforms existing baselines and achieves a superior privacy-utility trade-off.
Significance. If the empirical claims hold with rigorous quantitative support, the work could enable more practical client-side privacy preservation for LLMs in sensitive domains by removing reliance on manual masks, static dictionaries, or unstable prompt-based localization, while providing formal DP guarantees.
major comments (2)
- Abstract: the claim that DAMPER 'significantly outperforms existing baselines' and achieves a 'superior privacy-utility trade-off' is presented without any quantitative metrics, baseline names, dataset descriptions, or ablation results; the supporting evidence is described only as 'extensive experiments' and 'qualitative experiment summaries.' This is load-bearing for the central claim and prevents verification of the asserted superiority.
- The separation assumption underlying Domain Privacy Prototypes (learned via contrastive learning) is load-bearing: the manuscript provides no equations, sampling details, or hard-negative construction strategy for the contrastive stage. If the learned embeddings fail to tightly cluster private semantics separately from non-private ones, both span localization and the downstream Prototype-Guided Preference Alignment will operate on noisy pairs, directly undermining the claimed privacy-utility improvement.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below, outlining specific revisions to address the concerns while preserving the core contributions of DAMPER.
read point-by-point responses
-
Referee: Abstract: the claim that DAMPER 'significantly outperforms existing baselines' and achieves a 'superior privacy-utility trade-off' is presented without any quantitative metrics, baseline names, dataset descriptions, or ablation results; the supporting evidence is described only as 'extensive experiments' and 'qualitative experiment summaries.' This is load-bearing for the central claim and prevents verification of the asserted superiority.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the central claims. In the revised manuscript, we will add specific metrics from our experiments (e.g., relative improvements in privacy leakage reduction and utility preservation on named datasets such as medical and legal corpora, compared to baselines including prompt-based localization and static dictionary methods). This will allow immediate verification of the privacy-utility trade-off without requiring readers to consult the full experimental section. revision: yes
-
Referee: The separation assumption underlying Domain Privacy Prototypes (learned via contrastive learning) is load-bearing: the manuscript provides no equations, sampling details, or hard-negative construction strategy for the contrastive stage. If the learned embeddings fail to tightly cluster private semantics separately from non-private ones, both span localization and the downstream Prototype-Guided Preference Alignment will operate on noisy pairs, directly undermining the claimed privacy-utility improvement.
Authors: We acknowledge that the contrastive learning stage for Domain Privacy Prototypes requires fuller technical detail to substantiate the separation assumption. In the revision, we will include the complete contrastive loss formulation, the positive/negative pair sampling procedure (including domain-specific batch construction), and the hard-negative mining strategy based on embedding similarity thresholds. These additions will clarify how private semantics are isolated from non-private ones, directly supporting the reliability of span localization and preference alignment. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces DAMPER as a new pipeline combining contrastive learning for Domain Privacy Prototypes with prototype-guided preference alignment and sampling-based DP at inference. No equations, derivations, or self-citations are shown that reduce the claimed privacy-utility superiority to fitted inputs by construction, self-definitional loops, or renamed known results. Performance claims rest on external experimental benchmarks against baselines rather than internal reductions; the contrastive and preference objectives are standard losses applied to domain data without the target metric being presupposed in the fitting process. The derivation chain remains self-contained and falsifiable via held-out evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Domain Privacy Prototypes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint
Scaling instruction-finetuned language models. arXiv preprint. DeepSeek-AI. 2025. Deepseek-v3.2: Pushing the fron- tier of open large language models. Arthur P Dempster, Nan M Laird, and Donald B Rubin
2025
-
[2]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Maximum likelihood from incomplete data via the em algorithm.Journal of the Royal Statistical Society: Series B (Methodological), 39(1):1–22. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understand- ing. InProceedings of the 2019 conference of the North American ...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Saquib Sarfraz, Vivek Sharma, and Rainer Stiefelhagen
Direct preference optimization: Your language model is secretly a reward model.arXiv preprint. Saquib Sarfraz, Vivek Sharma, and Rainer Stiefelhagen
-
[4]
Efficient parameter-free clustering using first neighbor relations. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 8934–8943. Weiyan Shi, Ryan Shea, Si Chen, Chiyuan Zhang, Ruoxi Jia, and Zhou Yu. 2022. Just fine-tune twice: Selec- tive differential privacy for large language models. InProceedings of the 2022 ...
-
[5]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma
-
[6]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Appendices A Notations 12 B Related Work 12 B.1 Token-level LDP Substitution . . . 12 B.2 Seque...
-
[7]
Early mechanisms perturb each word independently and sample substitutes under metric-LDP constraints
has been widely used to privatize text at the token level. Early mechanisms perturb each word independently and sample substitutes under metric-LDP constraints. SanText (Yue et al., 2021) selects replacements according to embedding dis- tance to provide provable token-level guarantees, while CusText (Chen et al., 2023a) restricts the can- didate neighborh...
2021
-
[8]
Recent work explores strategies that combine multiple granularities
proposes the 1-Diffractor mechanism to gen- erate multiple DP-compliant candidates and select high-quality realizations. Recent work explores strategies that combine multiple granularities. DP- GTR (Li et al., 2025), for example, generates mul- tiple DP paraphrases and identifies consensus key- words that consistently survive privatization for iterative s...
2025
-
[9]
or FINCH (Sarfraz et al., 2019)) to serve as structured, discrete summaries of the underlying data distribution. C.4 Direct Preference Optimization Preference alignment aims to steer language mod- els toward desired behaviors using relative feed- back rather than absolute rewards (Christiano et al., 2017; Ouyang et al., 2022; Bai et al., 2022). Direct Pre...
2019
-
[10]
optimizes a policy πθ directly from a dataset of preference pairs (x, yw, yl), where yw is pre- ferred over yl. Unlike Reinforcement Learning from Human Feedback (RLHF) (Ouyang et al., 2022), which requires training a separate reward model, DPO derives a closed-form objective by im- plicitly defining the reward via the ratio of the pol- icy likelihood to ...
2022
-
[11]
taking the victim by force
based on the rewritten queries, and then leverage DeepSeek-V3 (DeepSeek-AI, 2025) as an evaluator to assign a quality score on a scale of 1 to 10. The prompt templates used for this evaluation are provided in Appendix I.4. Semantic Obfuscation Index (SOI ↑) and Do- main Fidelity Score (DFS ↑).These dual metrics quantify the effectiveness of the rewriting ...
2025
-
[12]
the symptoms of burning sensation in throat
-
[13]
symptoms worse after eating
-
[14]
pain Detected Privacy Spans (Ours)
-
[15]
burning sensation in throat b. cough
-
[16]
The woman presents throat discomfort[3], general unease[4], cough, worsening after meals[5]
pain Detected Privacy Spans (Prompt-based) Rewritten (Ours) A woman has a history of a prior condition[1], weight-related issues[2]. The woman presents throat discomfort[3], general unease[4], cough, worsening after meals[5]. Rewritten (Prompt-based) A woman has a history of pregnancy[1], obesity[2]. The woman presents throat issues[3], aches[4], breathin...
-
[17]
involuntary eye movement
-
[19]
shortness of breath Detected Privacy Spans (Ours)
-
[20]
muscle spasms
involuntary eye movement b. muscle spasms
-
[21]
muscle spasms in neck
-
[22]
shortness of breath Detected Privacy Spans (Prompt-based) Gold Label Acute dystonic reactions
-
[23]
antipsychotic medication usage
-
[24]
The male presents visual irregularities[3], facial discomfort[4], neck tension[5], drooping eyelids[6], breathing difficulty[7]
ptosis Rewritten (Ours) A male has a history of prior medication exposure[1], stomach discomfort[a], substance exposure[2]. The male presents visual irregularities[3], facial discomfort[4], neck tension[5], drooping eyelids[6], breathing difficulty[7]. Rewritten (Prompt-based) A male has a history of antipsychotic medication usage[1], nausea, stimulant dr...
-
[25]
intention and negligence Detected Privacy Spans (Ours)
selling fake drugs a. intention and negligence Detected Privacy Spans (Ours)
-
[26]
physical health rights and life safety b. state's drug management system Detected Privacy Spans (Prompt-based) Rewritten (Ours) Rewritten (Prompt-based) Inference (Ours) Inference (Prompt-based) Gold Label Production and sale of counterfeit drugs Original Text & Ground-truth Spans The social relationships protected by criminal law and infringed upon by cr...
-
[27]
physical health rights and life safety
-
[28]
criminal acts is public safety interests[1] state's drug
to seek illegal benefits an intentional The social ... criminal acts is public safety interests[1] state's drug ... a crime contains distributing questionable products [2], improper gains[3] [a, selling Qufeng ... Consisted of mixed intent ] the ... its results is personal gain motives[4]. The social ... criminal acts is public well-being[1] and regulator...
-
[29]
the victim was injured
-
[30]
constituting a joint crime
-
[31]
taking the victim by force
-
[32]
beating the victim Detected Privacy Spans (Ours)
-
[33]
span1","span2
personal rights 2. constituting a joint crime and a person with full capacity for conduct Detected Privacy Spans (Prompt-based) Rewritten (Ours) Rewritten (Prompt-based) Inference (Ours) Inference (Prompt-based) Gold Label Illegal Detention Original Text & Ground-truth Spans The social relationships protected by criminal law and infringed upon by criminal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.