Recognition: unknown
Inductive Reasoning for Temporal Knowledge Graphs with Emerging Entities
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
TransFIR transfers interaction patterns from similar known entities to support reasoning on emerging entities in temporal knowledge graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
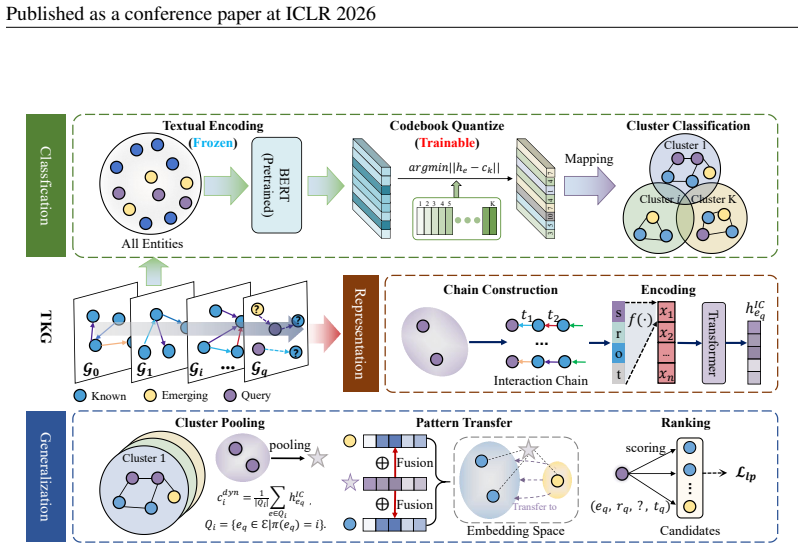
The paper claims that a codebook-based classifier can assign emerging entities to latent semantic clusters, allowing them to inherit historical interaction sequences and reasoning patterns from semantically similar known entities, thereby enabling effective inductive reasoning on temporal knowledge graphs that contain entities absent from the training set.
What carries the argument
A codebook-based classifier that assigns emerging entities to latent semantic clusters so they can adopt temporal reasoning patterns from known entities with matching histories.
Where Pith is reading between the lines
- The same clustering step could be applied to other dynamic graph tasks where new nodes arrive without history.
- Periodic recomputation of the codebook might let the method adapt as more entities appear over longer time spans.
- If the semantic-to-temporal-pattern link holds in additional domains, models could avoid full retraining each time a graph grows.
Load-bearing premise
Semantic similarity between entities reliably predicts similarity in their temporal interaction histories, so that cluster assignment transfers useful patterns to entities with no prior data.
What would settle it
Run the codebook classifier on a dataset where entities grouped by semantic similarity show markedly different temporal interaction sequences and check whether mean reciprocal rank for emerging-entity predictions remains higher than baselines.
Figures








read the original abstract
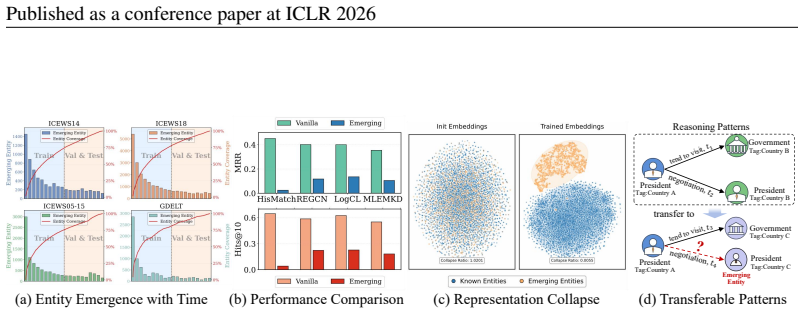
Reasoning on Temporal Knowledge Graphs (TKGs) is essential for predicting future events and time-aware facts. While existing methods are effective at capturing relational dynamics, their performance is limited by a closed-world assumption, which fails to account for emerging entities not present in the training. Notably, these entities continuously join the network without historical interactions. Empirical study reveals that emerging entities are widespread in TKGs, comprising roughly 25\% of all entities. The absence of historical interactions of these entities leads to significant performance degradation in reasoning tasks. Whereas, we observe that entities with semantic similarities often exhibit comparable interaction histories, suggesting the presence of transferable temporal patterns. Inspired by this insight, we propose TransFIR (Transferable Inductive Reasoning), a novel framework that leverages historical interaction sequences from semantically similar known entities to support inductive reasoning. Specifically, we propose a codebook-based classifier that categorizes emerging entities into latent semantic clusters, allowing them to adopt reasoning patterns from similar entities. Experimental results demonstrate that TransFIR outperforms all baselines in reasoning on emerging entities, achieving an average improvement of 28.6% in Mean Reciprocal Rank (MRR) across multiple datasets. The implementations are available at https://github.com/zhaodazhuang2333/TransFIR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TransFIR, a framework for inductive reasoning on temporal knowledge graphs (TKGs) that handles emerging entities lacking historical interactions. It observes that semantically similar entities tend to share comparable interaction histories and introduces a codebook-based classifier to assign emerging entities to latent semantic clusters, thereby transferring temporal patterns from known entities for future event prediction. The work reports an average 28.6% improvement in Mean Reciprocal Rank (MRR) over baselines across multiple datasets and releases the implementation publicly.
Significance. If the reported gains prove robust, the approach would meaningfully extend TKG reasoning beyond the closed-world assumption, addressing the practical issue that emerging entities comprise roughly 25% of entities in real TKGs. The public code release is a clear strength for reproducibility and further research in inductive graph reasoning.
major comments (2)
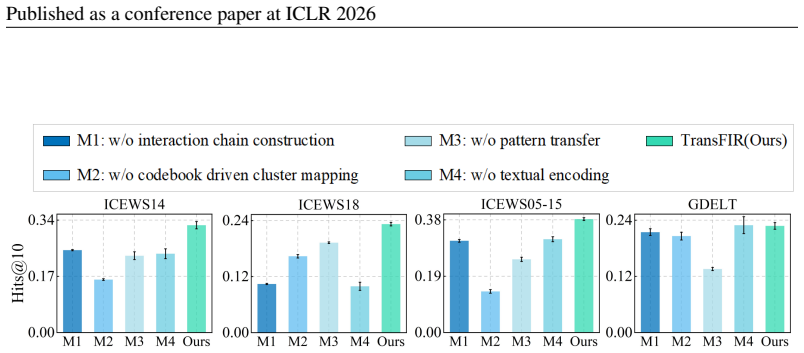
- [Method (codebook-based classifier and cluster assignment)] The central inductive step depends on the unvalidated assumption that semantic similarity (via the codebook classifier) reliably identifies clusters whose historical sequences contain transferable temporal patterns. No quantitative check—such as intra- versus inter-cluster interaction-sequence similarity or an ablation that disables the transfer step—is described, making it impossible to attribute the 28.6% MRR gain specifically to pattern transfer rather than auxiliary modeling choices. This is load-bearing for all zero-history predictions.
- [Experiments] The experimental section provides no details on baseline re-implementations, dataset splits for emerging entities, number of random seeds, or statistical significance tests. Without these, the claimed average 28.6% MRR improvement cannot be assessed for robustness or reproducibility.
minor comments (2)
- [Abstract] The abstract states that an 'empirical study reveals' emerging entities comprise roughly 25% of all entities; the full paper should specify the exact datasets, time windows, and definition of 'emerging' used for this statistic.
- [Method] Notation for the codebook classifier, cluster assignment, and how historical sequences are encoded should be introduced with explicit equations or pseudocode to improve clarity for readers unfamiliar with the specific TKG formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of validation and reproducibility that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Method (codebook-based classifier and cluster assignment)] The central inductive step depends on the unvalidated assumption that semantic similarity (via the codebook classifier) reliably identifies clusters whose historical sequences contain transferable temporal patterns. No quantitative check—such as intra- versus inter-cluster interaction-sequence similarity or an ablation that disables the transfer step—is described, making it impossible to attribute the 28.6% MRR gain specifically to pattern transfer rather than auxiliary modeling choices. This is load-bearing for all zero-history predictions.
Authors: We appreciate this point. The manuscript presents an empirical study showing that semantically similar entities tend to share comparable interaction histories, which motivates the codebook approach. However, we acknowledge that direct quantitative validation of intra- versus inter-cluster sequence similarity and an ablation isolating the transfer step are not included. In the revised manuscript, we will add these analyses: computation of interaction-sequence similarities (e.g., via temporal embedding distances or relation overlap) within and across clusters, plus an ablation that disables the codebook assignment and transfer (replacing it with random or no transfer) to quantify its specific contribution to the reported MRR gains. These additions will strengthen attribution of the inductive benefits. revision: yes
-
Referee: [Experiments] The experimental section provides no details on baseline re-implementations, dataset splits for emerging entities, number of random seeds, or statistical significance tests. Without these, the claimed average 28.6% MRR improvement cannot be assessed for robustness or reproducibility.
Authors: We agree that these details are essential for evaluating robustness. The original manuscript omitted some implementation specifics to focus on the core results. In the revision, we will expand the experimental section to include: descriptions of baseline re-implementations (including any modifications for the inductive setting), the exact procedure and criteria for identifying emerging entities and constructing the dataset splits, the number of random seeds used (we will report means and standard deviations over 5 seeds), and statistical significance tests (e.g., paired t-tests with p-values against baselines). We will also ensure the released code includes the exact splits and seeds for full reproducibility. revision: yes
Circularity Check
No circularity: empirical framework validated by external experiments
full rationale
The paper presents TransFIR as an ML architecture that assigns emerging entities to semantic clusters via a codebook classifier and transfers temporal patterns from known entities. All central claims are supported by experimental MRR gains on held-out datasets rather than any derivation that reduces outputs to inputs by construction. No equations equate predictions to fitted parameters, no self-citations supply uniqueness theorems, and the core assumption (semantic similarity implies transferable histories) is treated as an empirical observation checked via performance metrics, not presupposed. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entities with semantic similarities often exhibit comparable interaction histories
Forward citations
Cited by 1 Pith paper
-
AdaTKG: Adaptive Memory for Temporal Knowledge Graph Reasoning
AdaTKG equips temporal knowledge graph entities with per-entity memories updated via a single shared learnable exponential moving average, allowing online adaptation and better reasoning on evolving facts.
Reference graph
Works this paper leans on
-
[1]
Borui Cai, Yong Xiang, Longxiang Gao, He Zhang, Yunfeng Li, and Jianxin Li
URLhttps://doi.org/10.7910/DVN/ 28075. Borui Cai, Yong Xiang, Longxiang Gao, He Zhang, Yunfeng Li, and Jianxin Li. Temporal knowl- edge graph completion: a survey. InProceedings of the Thirty-Second International Joint Con- ference on Artificial Intelligence, pp. 6545–6553,
-
[2]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[3]
zr- llm: Zero-shot relational learning on temporal knowledge graphs with large language models
Zifeng Ding, Heling Cai, Jingpei Wu, Yunpu Ma, Ruotong Liao, Bo Xiong, and V olker Tresp. zr- llm: Zero-shot relational learning on temporal knowledge graphs with large language models. In Proceedings of the 2024 conference of the North American chapter of the association for com- putational linguistics: Human language technologies (Volume 1: Long papers)...
2024
-
[4]
Towards foundation models for knowledge graph reasoning
11 Published as a conference paper at ICLR 2026 Mikhail Galkin, Xinyu Yuan, Hesham Mostafa, Jian Tang, and Zhaocheng Zhu. Towards foundation models for knowledge graph reasoning. InThe Twelfth International Conference on Learning Representations,
2026
-
[5]
Learning sequence encoders for temporal knowledge graph completion
Alberto Garcia-Duran, Sebastijan Duman ˇci´c, and Mathias Niepert. Learning sequence encoders for temporal knowledge graph completion. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 4816–4821,
2018
-
[6]
arXiv preprint arXiv:1904.05530 , year=
Woojeong Jin, Meng Qu, Xisen Jin, and Xiang Ren. Recurrent event network: Autoregressive structure inference over temporal knowledge graphs.arXiv preprint arXiv:1904.05530,
-
[7]
Understanding dimensional collapse in contrastive self-supervised learning
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. Understanding dimensional collapse in contrastive self-supervised learning. In10th International Conference on Learning Representa- tions, ICLR 2022,
2022
-
[8]
Dong-Ho Lee, Kian Ahrabian, Woojeong Jin, Fred Morstatter, and Jay Pujara. Temporal knowledge graph forecasting without knowledge using in-context learning.arXiv preprint arXiv:2305.10613, 2023a. Jaejun Lee, Chanyoung Chung, and Joyce Jiyoung Whang. Ingram: Inductive knowledge graph embedding via relation graphs. InInternational conference on machine lear...
-
[9]
Hismatch: Historical structure matching based temporal knowl- edge graph reasoning
Zixuan Li, Zhongni Hou, Saiping Guan, Xiaolong Jin, Weihua Peng, Long Bai, Yajuan Lyu, Wei Li, Jiafeng Guo, and Xueqi Cheng. Hismatch: Historical structure matching based temporal knowl- edge graph reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2022, pp. 7328–7338,
2022
-
[10]
Gentkg: Generative forecasting on temporal knowledge graph with large language models
Ruotong Liao, Xu Jia, Yangzhe Li, Yunpu Ma, and V olker Tresp. Gentkg: Generative forecasting on temporal knowledge graph with large language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pp. 4303–4317,
2024
-
[11]
Indigo: Gnn-based inductive knowl- edge graph completion using pair-wise encoding.Advances in Neural Information Processing Systems, 34:2034–2045,
Shuwen Liu, Bernardo Grau, Ian Horrocks, and Egor Kostylev. Indigo: Gnn-based inductive knowl- edge graph completion using pair-wise encoding.Advances in Neural Information Processing Systems, 34:2034–2045,
2034
-
[12]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[13]
Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs
12 Published as a conference paper at ICLR 2026 Yushan Liu, Yunpu Ma, Marcel Hildebrandt, Mitchell Joblin, and V olker Tresp. Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs. InProceedings of the AAAI conference on artificial intelligence, volume 36, pp. 4120–4127,
2026
-
[14]
An adaptive logical rule embedding model for inductive reasoning over temporal knowledge graphs
Xin Mei, Libin Yang, Xiaoyan Cai, and Zuowei Jiang. An adaptive logical rule embedding model for inductive reasoning over temporal knowledge graphs. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 7304–7316, Abu Dhabi, United Arab Emirates, December
2022
-
[15]
Association for Computational Linguistics. doi: 10.18653/v1/2022. emnlp-main.493. Shi Mingcong, Chunjiang Zhu, Detian Zhang, Shiting Wen, and Li Qing. Multi-granularity history and entity similarity learning for temporal knowledge graph reasoning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5232–5243,
-
[16]
Towards foundation model on temporal knowledge graph reasoning
Jiaxin Pan, Mojtaba Nayyeri, Osama Mohammed, Daniel Hernandez, Rongchuan Zhang, Cheng Cheng, and Steffen Staab. Towards foundation model on temporal knowledge graph reasoning. arXiv preprint arXiv:2506.06367,
-
[17]
37th Conference on Artificial Intelligence (AAAI) , year =
Jianling Wang, Haokai Lu, James Caverlee, Ed H Chi, and Minmin Chen. Large language models as data augmenters for cold-start item recommendation. InCompanion Proceedings of the ACM Web Conference 2024, pp. 726–729, 2024a. Jiapu Wang, Sun Kai, Linhao Luo, Wei Wei, Yongli Hu, Alan Wee-Chung Liew, Shirui Pan, and Baocai Yin. Large language models-guided dyna...
-
[18]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Jinchuan Zhang, Ming Sun, Chong Mu, Jinhao Zhang, Quanjiang Guo, and Ling Tian. Historically relevant event structuring for temporal knowledge graph reasoning. In2025 IEEE 41st Interna- tional Conference on Data Engineering (ICDE), pp. 3179–3192. IEEE, 2025a. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
All LLM-generated content was thoroughly reviewed and validated by the authors to ensure the accuracy of the pre- sented information
14 Published as a conference paper at ICLR 2026 A LLM USAGEDISCLOSURE In this work, we used GPT-4o to assist with grammar checking and polishing. All LLM-generated content was thoroughly reviewed and validated by the authors to ensure the accuracy of the pre- sented information. Additionally, the items representing ”President” and ”Government” in Fig. 1 a...
2026
-
[20]
visited Country A att 1
enables cross-dataset knowledge transfer through si- nusoidal positional encoding. Despite these advances, they overlook the fact that emerging entities in temporal knowledge graphs often arrive without any historical interactions, a common scenario in real-world applications. The absence of relational context makes it particularly challenging to derive m...
2026
-
[21]
Pattern transfer (generalization).Forming cluster prototypes requiresO(n td+Kd)
(attention and feed-forward), and memoryO(n tkd)for activations. Pattern transfer (generalization).Forming cluster prototypes requiresO(n td+Kd). Broad- casting drift via the MLP costsO(Emd)with spaceO(Ed)for (temporary) updated embeddings. In practice we apply drift only to non-query entities att. 17 Published as a conference paper at ICLR 2026 Algorithm...
2026
-
[22]
+O(EKd) +O(Emd) Sincek,L,K, andmare small constants (e.g.,k≤32), TRANSFIR scaleslinearlywith the number of queries and entities, and its controllable chain length avoids dependence on the full neighborhood size. E ADDITIONALEXPERIMENTALSETTINGS E.1 DETAILEDDATASETINFORMATION Table E.1 presents comprehensive statistics for all datasets, encompassing entity...
2026
-
[23]
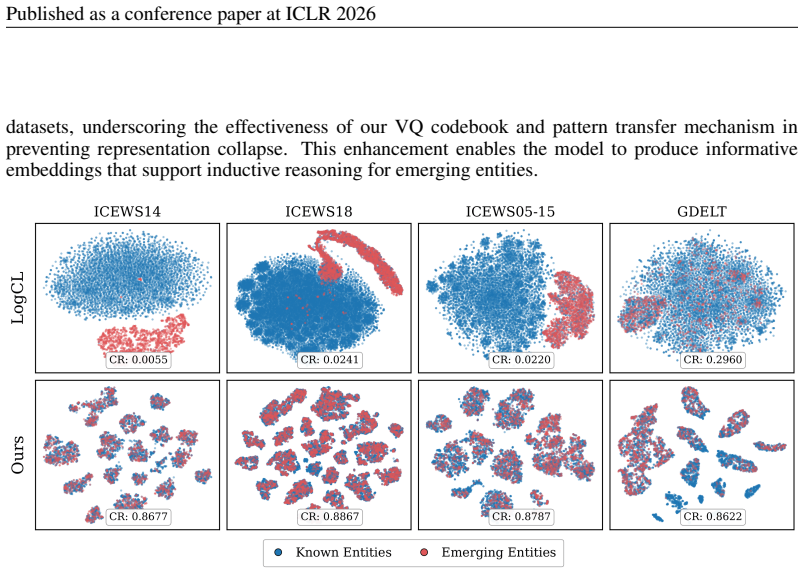
Note that GenTKG generates 10 samples to compute Hits, so MRR values are not available for this method. F EXTENDEDEXPERIMENTALRESULTS F.1 REPRESENTATION ANDLEARNINGANALYSIS(RQ2) Representation quality and collapse.We further evaluate TRANSFIR’s ability to represent emerging entities through t-SNE visualizations across multiple datasets. As illustrated in ...
2026
-
[24]
21 Published as a conference paper at ICLR 2026 Figure 9: Ablation results on four benchmarks underMRR(top row) andHits@3(bottom row)
which enforcest q =t e(e)(zero history), the Unknown setting allows the model toobserve local pre-query history within the test window, defined as Hte tq = [ i∈Tte, i<tq Fi, while future facts (≥t q) remain hidden. 21 Published as a conference paper at ICLR 2026 Figure 9: Ablation results on four benchmarks underMRR(top row) andHits@3(bottom row). The ran...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.