Recognition: unknown
Byzantine-Robust Distributed SGD: A Unified Analysis and Tight Error Bounds
Pith reviewed 2026-05-10 16:21 UTC · model grok-4.3
The pith
Byzantine-robust distributed SGD achieves tight convergence rates for nonconvex smooth and PL objectives under general data heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish the convergence rates for nonconvex smooth objectives and those satisfying the Polyak-Lojasiewicz condition under a general data heterogeneity assumption. Our analysis reveals that while stochasticity and data heterogeneity introduce unavoidable error floors, local momentum provably reduces the error component induced by stochasticity. Furthermore, we derive matching lower bounds to demonstrate that the upper bounds obtained in our analysis are tight and characterize the fundamental limits of Byzantine resilience under stochasticity and data heterogeneity.
What carries the argument
Unified convergence analysis framework that accommodates general data heterogeneity and applies to variants with and without local momentum using properties of robust aggregation rules.
If this is right
- Nonconvex smooth objectives converge to a neighborhood whose radius depends on the level of heterogeneity and gradient variance.
- Objectives satisfying the Polyak-Lojasiewicz condition converge linearly to an error floor whose size is characterized by the same factors.
- Adding local momentum reduces the error floor component caused by stochastic gradients but does not eliminate the heterogeneity-induced floor.
- The matching upper and lower bounds show that no Byzantine-robust SGD method can achieve faster rates without stronger assumptions on heterogeneity or stochasticity.
Where Pith is reading between the lines
- Aggregation rules should be chosen or designed to keep the heterogeneity-induced error as small as possible, since it forms an irreducible floor.
- The same analysis template may apply to other first-order methods such as distributed Adam if their update rules can be cast in similar recursive form.
- In federated learning deployments that already use momentum for faster training, the extra robustness benefit against Byzantine workers comes at no additional cost to the convergence theory.
Load-bearing premise
The chosen robust aggregation rules bound the effect of Byzantine workers and the general data heterogeneity assumption holds along with standard smoothness or PL conditions.
What would settle it
A controlled experiment on a distributed SGD setup with known Byzantine fraction, measurable data heterogeneity, and stochastic gradients, checking whether the observed convergence error floor matches the paper's predicted lower bound.
Figures

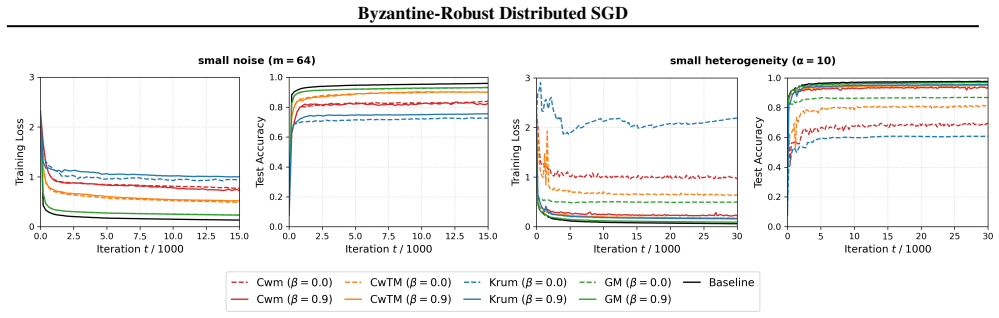
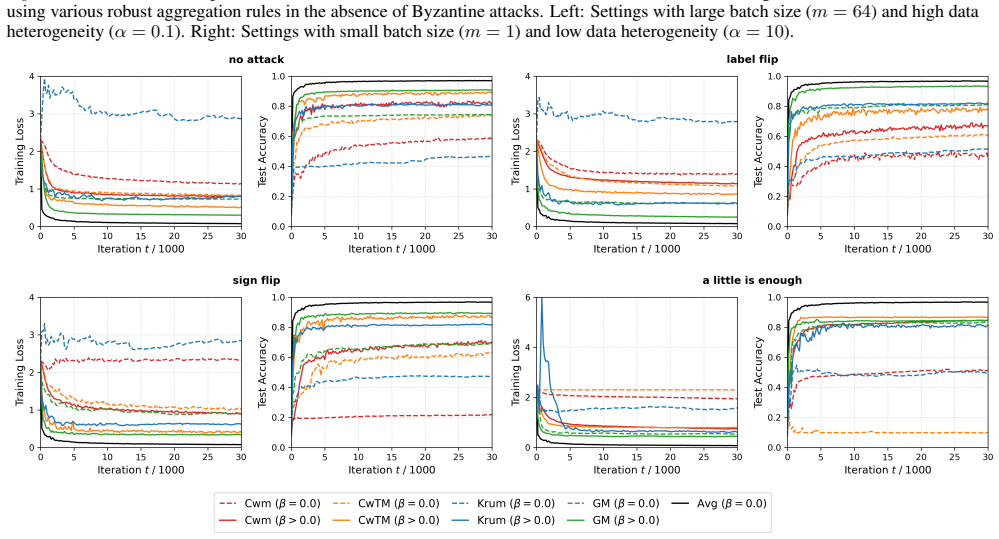
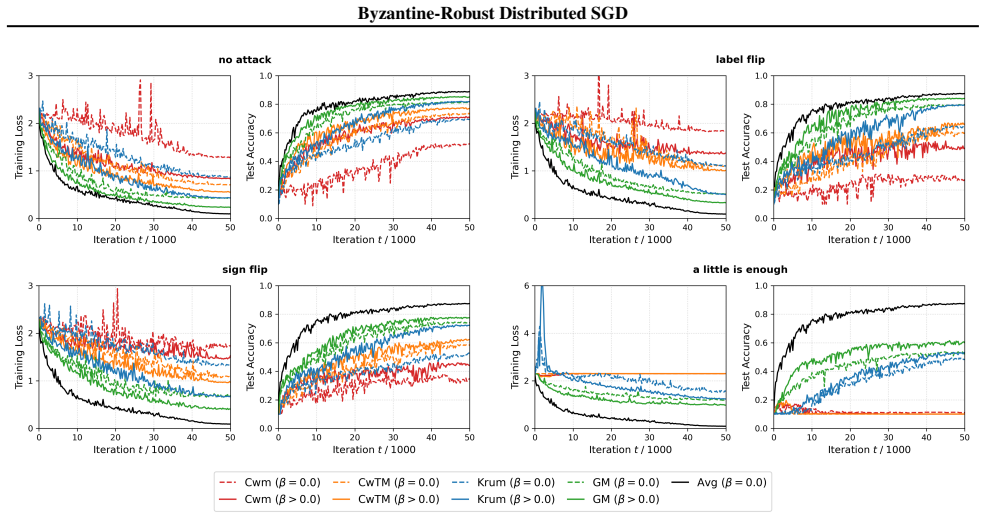
read the original abstract
Byzantine-robust distributed optimization relies on robust aggregation rules to mitigate the influence of malicious Byzantine workers. Despite the proliferation of such rules, a unified convergence analysis framework that accommodates general data heterogeneity is lacking. In this work, we provide a thorough convergence theory of Byzantine-robust distributed stochastic gradient descent (SGD), analyzing variants both with and without local momentum. We establish the convergence rates for nonconvex smooth objectives and those satisfying the Polyak-Lojasiewicz condition under a general data heterogeneity assumption. Our analysis reveals that while stochasticity and data heterogeneity introduce unavoidable error floors, local momentum provably reduces the error component induced by stochasticity. Furthermore, we derive matching lower bounds to demonstrate that the upper bounds obtained in our analysis are tight and characterize the fundamental limits of Byzantine resilience under stochasticity and data heterogeneity. Empirical results support our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a unified convergence analysis for Byzantine-robust distributed SGD, both with and without local momentum. It establishes rates for nonconvex smooth objectives and those satisfying the Polyak-Łojasiewicz condition under a general data heterogeneity assumption. The analysis identifies unavoidable error floors due to stochasticity and heterogeneity, shows that local momentum reduces the stochastic error component, and derives matching lower bounds to prove the upper bounds are tight and to characterize fundamental limits of Byzantine resilience.
Significance. If the derivations hold, the work is significant for providing tight, matching upper and lower bounds that quantify the precise impact of stochastic gradients and data heterogeneity on Byzantine-robust optimization. The explicit demonstration that local momentum mitigates only the stochastic floor (while heterogeneity remains unavoidable) offers actionable insight for algorithm design. The matching lower-bound constructions, which saturate the same heterogeneity and variance terms used in the upper bounds, constitute a clear strength by establishing optimality rather than merely upper bounds.
minor comments (3)
- [Abstract] Abstract: the statement that local momentum 'provably reduces the error component induced by stochasticity' is correct but would be clearer if it briefly indicated the precise improvement in the rate (e.g., removal of a 1/√T term or similar).
- [Section 2 (Assumptions)] The general data heterogeneity assumption is used throughout the upper- and lower-bound arguments; a short paragraph comparing its strength to the more common bounded-gradient-dissimilarity condition would help readers assess generality.
- [Section 6 (Experiments)] Empirical section: the reported experiments support the theory, but the description of the Byzantine attack models and the choice of robust aggregation rules (e.g., Krum, median) should be expanded with explicit parameter settings to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and positive assessment of our manuscript, including the accurate summary of our unified convergence analysis, the role of local momentum in reducing stochastic error floors, and the matching lower bounds under general heterogeneity. The recommendation for minor revision is appreciated. No specific major comments were provided in the report.
Circularity Check
No significant circularity; upper and lower bounds derived independently
full rationale
The paper's convergence analysis proceeds from standard assumptions (smoothness or PL condition plus a general heterogeneity model) to upper bounds via properties of robust aggregation rules, without any self-definitional reduction or fitted parameter renamed as prediction. Matching lower bounds are obtained by explicit construction of adversarial data distributions and Byzantine behaviors that saturate the same variance and heterogeneity terms appearing in the upper bounds; these constructions are independent of the upper-bound derivation and do not rely on self-citation chains or imported uniqueness results. The overall argument is self-contained against external benchmarks and follows conventional optimization-theory patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Objectives are nonconvex and smooth or satisfy the Polyak-Lojasiewicz condition
- domain assumption General data heterogeneity assumption holds across workers
Reference graph
Works this paper leans on
-
[1]
Byzantine machine learning: A primer.ACM Computing Surveys, 56(7): 1–39, 2024a
Guerraoui, R., Gupta, N., and Pinot, R. Byzantine machine learning: A primer.ACM Computing Surveys, 56(7): 1–39, 2024a. Guerraoui, R., Gupta, N., and Pinot, R.Robust Machine Learning: Distributed Methods for Safe AI. Springer, 2024b. Gupta, D., Honsell, A., Xu, C., Gupta, N., and Neglia, G. Reconciling communication compression and Byzantine- robustness i...
-
[2]
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Koneˇcn`y, J., McMahan, H. B., Ramage, D., and Richt´arik, P. Federated optimization: Distributed machine learning for on-device intelligence.arXiv preprint arXiv:1610.02527,
-
[3]
11 Byzantine-Robust Distributed SGD Wang, J., Charles, Z., Xu, Z., Joshi, G., McMahan, H. B., Al-Shedivat, M., Andrew, G., Avestimehr, S., Daly, K., Data, D., et al. A field guide to federated optimization. arXiv preprint arXiv:2107.06917,
-
[4]
Generalized Byzantine- tolerant SGD.arXiv preprint arXiv:1802.10116,
Xie, C., Koyejo, O., and Gupta, I. Generalized Byzantine- tolerant SGD.arXiv preprint arXiv:1802.10116,
-
[5]
Federated learning with non-iid data,
Zhao, Y ., Li, M., Lai, L., Suda, N., Civin, D., and Chandra, V . Federated learning with non-IID data.arXiv preprint arXiv:1806.00582,
-
[6]
This verifies the tightness of the lower bound. C.2. Lower Bound for Randomness Before proving the lower boundO σ2 1−κB2 , we first introduce the following convergence results for SGD from the work of Nguyen et al. (2019) and Gorbunov et al. (2020). Lemma C.1((Nguyen et al., 2019), Theorems 9, 11).Consider the following stochastic optimization problem: mi...
2019
-
[7]
We report the best performance (i.e., the smallest error) over all configurations
The initial stepsize γ0 is selected from 0.5,0.2,0.1,0.05,0.01,0.005,0.001 , and the total number of iterations T is chosen from 10,20,50,100,200,1000,2000 . We report the best performance (i.e., the smallest error) over all configurations. D.2. Detailed Experimental Setups for MNIST and CIFAR-10 Experiments Models.For experiments on the MNIST dataset, we...
2000
-
[8]
Specifically, the stepsize at iteration t is given by γt = 1+cos(tπ/50000) 2 γ0, where γ0 is selected from γ0 ∈ {0.2,0.1,0.05,0.025,0.01}
In the CIFAR-10 task, each algorithm is run for 50000 iterations with a cosine annealing learning rate schedule (Loshchilov & Hutter, 2017). Specifically, the stepsize at iteration t is given by γt = 1+cos(tπ/50000) 2 γ0, where γ0 is selected from γ0 ∈ {0.2,0.1,0.05,0.025,0.01} . For R-DSGD-M, the momentum parameter is tuned over β∈ {0.5,0.6,0.7,0.8,0.9} ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.