Recognition: 2 theorem links
· Lean TheoremScalable Generative Sampling and Multilevel Estimation for Lattice Field Theories Near Criticality
Pith reviewed 2026-05-10 15:57 UTC · model grok-4.3
The pith
A multiscale generative sampler models the Boltzmann distribution of lattice field theories near criticality through a coarse-to-fine hierarchy of conditional distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a hierarchy of conditional distributions across length scales, with each refinement level employing a conditional Gaussian mixture for dominant local dependence and a masked continuous normalizing flow for residual structure, generates unbiased samples from the critical Boltzmann distribution, yields integrated autocorrelation times orders of magnitude below those of Hybrid Monte Carlo on large volumes, and furnishes exact restriction maps for unbiased Multilevel Monte Carlo at negligible additional cost.
What carries the argument
The coarse-to-fine generative hierarchy that exactly preserves sampled coarse fields at each refinement level, thereby providing exact restriction maps for multilevel Monte Carlo without extra computation.
If this is right
- Integrated autocorrelation times become orders of magnitude smaller than Hybrid Monte Carlo on large volumes near criticality.
- Exact restriction maps are obtained at no additional computational cost, enabling direct unbiased Multilevel Monte Carlo variance reduction.
- Importance-sampling efficiency remains high relative to other generative baselines.
- Physical observables are reproduced without bias and agree statistically with long Hybrid Monte Carlo simulations.
- The multiscale construction scales sampling efficiency with lattice volume by isolating long-wavelength modes at coarse levels.
Where Pith is reading between the lines
- The same coarse-to-fine architecture with exact restriction maps could be tested on three-dimensional scalar theories or gauge theories where critical slowing down is more severe.
- The method's preservation of coarse fields suggests straightforward combination with other variance-reduction techniques such as multilevel importance sampling.
- Because the conditional models are learned independently at each scale, the approach may extend to dynamical simulations that require consistent multiscale updates.
- Direct measurement of how the learned conditional distributions deviate from the true ones on small test lattices would quantify the approximation error before scaling to production volumes.
Load-bearing premise
The learned conditional Gaussian mixture plus masked continuous normalizing flow at every refinement level must accurately represent the true conditional distribution of the fine field given the coarse field.
What would settle it
A statistically significant discrepancy in any unbiased observable, such as susceptibility or correlation length, between the generative samples and independent long Hybrid Monte Carlo runs on the same large critical lattices would falsify the claim of unbiased sampling.
Figures






read the original abstract
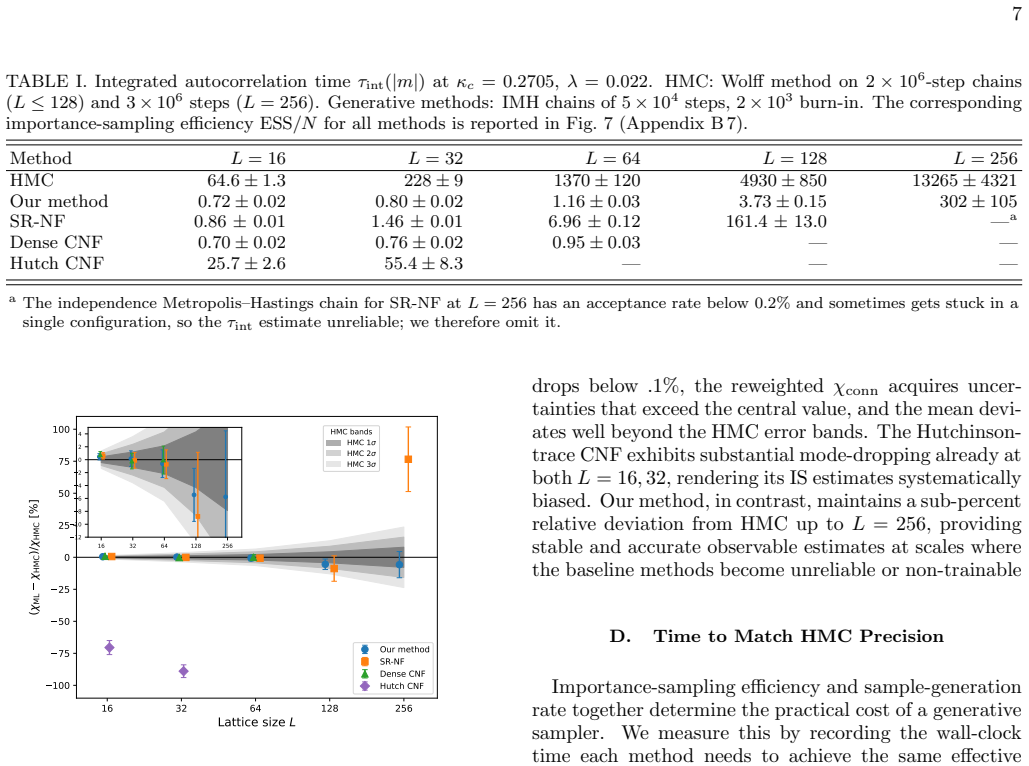
Sampling lattice field theories near criticality is severely hindered by critical slowing down, which makes standard Markov chain methods increasingly inefficient at large lattice volumes. We introduce a multiscale generative sampler, inspired by renormalization-group ideas, that models the Boltzmann distribution through a coarse-to-fine hierarchy across length scales. At each level, a conditional Gaussian mixture model captures the main local dependence of newly introduced variables on the already-sampled coarse field, while a masked continuous normalizing flow refines the remaining conditional structure. Coarse levels encode the dominant long-wavelength modes, and finer levels progressively add short-distance fluctuations. In addition, because the architecture preserves coarse fields exactly during refinement, it provides exact restriction maps at no additional computational cost and directly enables unbiased Multilevel Monte Carlo (MLMC) variance reduction. For the two-dimensional scalar $\phi^4$ theory at criticality, the method achieves integrated autocorrelation times orders of magnitude smaller than Hybrid Monte Carlo (HMC) on large volumes, maintains high importance-sampling efficiency relative to other generative baselines, and reproduces unbiased physical observables in statistical agreement with long HMC simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multiscale generative sampler for lattice field theories near criticality, modeling the Boltzmann distribution via a coarse-to-fine hierarchy. At each level, a conditional Gaussian mixture captures local dependence on the coarse field, refined by a masked continuous normalizing flow. The architecture preserves coarse fields exactly, enabling unbiased Multilevel Monte Carlo (MLMC) variance reduction. For the 2D scalar φ⁴ theory at criticality, it claims integrated autocorrelation times orders of magnitude smaller than HMC on large volumes, high importance-sampling efficiency relative to other generative baselines, and reproduction of unbiased physical observables in statistical agreement with long HMC runs.
Significance. If the unbiasedness and efficiency claims hold, this represents a meaningful advance in mitigating critical slowing down for lattice simulations. The exact restriction maps and direct enablement of MLMC are technical strengths that could reduce computational costs for large-volume studies, with potential applicability beyond φ⁴ to other critical theories. The approach combines generative modeling with multilevel estimation in a way that, if validated, offers a scalable alternative to standard MCMC methods.
major comments (1)
- [Multilevel estimation and generative hierarchy] The unbiasedness claim for physical observables (Abstract) depends on the learned conditional distributions at each level inducing marginals that are consistent with the coarse-level model after exact restriction. Independent training of the conditional Gaussian mixture + masked CNF at each refinement level does not automatically enforce this cross-level consistency; any approximation error or mode mismatch would bias the telescoping MLMC estimator even before importance weights. The manuscript must provide explicit verification (e.g., moment or distribution comparisons between restricted fine-level samples and independently generated coarse samples) to support the central unbiasedness assertion.
minor comments (2)
- The abstract reports statistical agreement with HMC and large autocorrelation reduction but omits quantitative details on training convergence, effective sample size, specific autocorrelation time ratios, or importance-sampling efficiency metrics; these should be added with supporting tables or figures.
- Clarify implementation specifics of the masked continuous normalizing flow and the exact form of the conditional Gaussian mixture (e.g., number of components, masking strategy) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying this key technical point on cross-level consistency in the hierarchical generative model. We address the concern directly below and will revise the manuscript to include the requested verification.
read point-by-point responses
-
Referee: The unbiasedness claim for physical observables (Abstract) depends on the learned conditional distributions at each level inducing marginals that are consistent with the coarse-level model after exact restriction. Independent training of the conditional Gaussian mixture + masked CNF at each refinement level does not automatically enforce this cross-level consistency; any approximation error or mode mismatch would bias the telescoping MLMC estimator even before importance weights. The manuscript must provide explicit verification (e.g., moment or distribution comparisons between restricted fine-level samples and independently generated coarse samples) to support the central unbiasedness assertion.
Authors: We agree that independent per-level training does not automatically guarantee marginal consistency and that explicit checks are necessary to rigorously support the unbiasedness of the MLMC estimator. The architecture does ensure that coarse fields are preserved exactly under refinement, providing an exact restriction map at no extra cost. However, to confirm that the learned conditionals induce consistent marginals, we will add in the revised manuscript direct comparisons at each hierarchy level: (i) low-order moments (mean, variance, and two-point functions) and (ii) where computationally feasible, binned distribution comparisons or estimated KL divergences between (a) coarse fields obtained by exact restriction of fine-level samples and (b) independent samples generated at the coarse level. These verifications will be presented alongside the existing observable comparisons with HMC, which already indicate that any residual mismatch is statistically negligible for the observables of interest. We believe this addition will fully address the referee's concern while preserving the central claim that the exact restriction enables unbiased MLMC. revision: yes
Circularity Check
No significant circularity; claims rest on empirical validation against external HMC baselines
full rationale
The paper's core construction uses exact restriction maps (coarse field preserved by design) to enable MLMC, with each level's conditional Gaussian mixture + masked CNF trained independently on the target action. The reported performance gains (autocorrelation times, efficiency) and unbiased observables are demonstrated via direct numerical comparison to independent long HMC runs and other generative baselines, not by re-deriving quantities from the model's own fitted parameters. No equation reduces a claimed result to an input by construction, no self-citation chain bears the central claim, and the unbiasedness statement is qualified by statistical agreement with external reference simulations rather than asserted as automatic from architecture alone. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The target distribution is the Boltzmann distribution exp(-S[φ]) for the lattice action S.
- domain assumption Conditional distributions at each scale can be modeled by Gaussian mixtures followed by continuous normalizing flows.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a multiscale generative sampler, inspired by renormalization-group ideas, that models the Boltzmann distribution through a coarse-to-fine hierarchy... conditional Gaussian mixture model... masked continuous normalizing flow... exact restriction maps... unbiased Multilevel Monte Carlo (MLMC)
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Kadanoff-inspired multilevel partition... ϕ≡ϕ(ℓmax)→{ϕ(0),ϕ(1),…,ϕ(ℓmax)}... p(ϕ)=p(ϕ(0))∏p(ϕ(ℓ)|ϕ(≤ℓ−1))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. G. Wilson and J. Kogut, Phys. Rep.12, 75 (1974)
1974
-
[2]
Creutz,Quarks, gluons and lattices(Cambridge Uni- versity Press, 1983)
M. Creutz,Quarks, gluons and lattices(Cambridge Uni- versity Press, 1983)
1983
-
[3]
Creutz, L
M. Creutz, L. Jacobs, and C. Rebbi, Physics Reports95, 201 (1983)
1983
-
[4]
Aoki et al., FLAG review 2024, Phys
Y. Aokiet al.(Flavour Lattice Averaging Group (FLAG)), Phys. Rev. D113, 014508 (2026), arXiv:2411.04268 [hep-lat]
-
[5]
T. Aoyamaet al., Phys. Rept.887, 1 (2020), arXiv:2006.04822 [hep-ph]
-
[6]
R. Alibertiet al., Phys. Rept.1143, 1 (2025), arXiv:2505.21476 [hep-ph]
-
[7]
Wolff, Nuclear Physics B17, 93 (1990)
U. Wolff, Nuclear Physics B17, 93 (1990)
1990
-
[8]
Wolff, Comp
U. Wolff, Comp. Phys. Comm.156, 143 (2004)
2004
-
[9]
S. Schaefer, R. Sommer, and F. Virotta (ALPHA), Nucl. Phys. B845, 93 (2011), arXiv:1009.5228 [hep-lat]
-
[10]
E. G. Tabak and E. Vanden-Eijnden, Communications in Mathematical Sciences8, 217 (2010)
2010
-
[11]
E. G. Tabak and C. V. Turner, Communications on Pure and Applied Mathematics66, 145 (2013)
2013
-
[12]
Rezende and S
D. Rezende and S. Mohamed, inProceedings of the 32nd International Conference on Machine Learning, Vol. 37 (2015) pp. 1530–1538
2015
- [13]
-
[14]
M. S. Albergo, G. Kanwar, and P. E. Shanahan, Phys. Rev. D100, 034515 (2019)
2019
- [15]
- [16]
-
[17]
K. A. Nicoli, S. Nakajima, N. Strodthoff, W. Samek, et al., Phys. Rev. E101, 023304 (2020)
2020
-
[18]
K. A. Nicoli, C. J. Anders, L. Funcke, T. Hartung,et al., Phys. Rev. Lett.126, 032001 (2021)
2021
-
[19]
Singha, D
A. Singha, D. Chakrabarti, and V. Arora, Phys. Rev. D 107, 014512 (2023)
2023
-
[20]
Singha, D
A. Singha, D. Chakrabarti, and V. Arora, Phys. Rev. D 108, 074518 (2023)
2023
- [21]
-
[22]
P. Tuo, Z. Zeng, J. Chen, and B. Cheng, Journal of Chem- ical Theory and Computation21, 11427 (2025)
2025
- [23]
-
[24]
Improvement of Heatbath Algorithm in LFT using Generative models
A. Faraz, A. Singha, D. Chakrabarti, S. Nakajima, and V. Arora, PoSLATTICE2024, 036 (2025), arXiv:2308.08615 [physics.comp-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Finkenrath, PoSLATTICE2023, 022 (2024)
J. Finkenrath, PoSLATTICE2023, 022 (2024)
2024
- [26]
- [27]
-
[28]
Kanaujia, M
V. Kanaujia, M. S. Scheurer, and V. Arora, SciPost Phys. 16, 132 (2024)
2024
-
[29]
S. Bacchio, P. Kessel, S. Schaefer, and L. Vaitl, Phys. Rev. D107, L051504 (2023), arXiv:2212.08469 [hep-lat]
-
[30]
Gerdes, P
M. Gerdes, P. de Haan, C. Rainone, R. Bondesan,et al., SciPost Physics15, 238 (2023)
2023
-
[31]
M. Caselle, E. Cellini, and A. Nada, JHEP02, 048, arXiv:2307.01107 [hep-lat]
- [32]
-
[33]
M. Caselle, E. Cellini, A. Nada, and M. Panero, JHEP 07, 015, arXiv:2201.08862 [hep-lat]
-
[34]
M. Caselle, E. Cellini, and A. Nada, JHEP02, 090, arXiv:2409.15937 [hep-lat]
-
[35]
A. Bulgarelli, E. Cellini, K. Jansen, S. K¨ uhn, A. Nada, S. Nakajima, K. A. Nicoli, and M. Panero, Phys. Rev. Lett.134, 151601 (2025), arXiv:2410.14466 [quant-ph]
-
[36]
A. Bulgarelli, E. Cellini, and A. Nada, Phys. Rev. D111, 074517 (2025), arXiv:2412.00200 [hep-lat]
-
[37]
Scaling flow-based approaches for topology sampling in $\mathrm{SU}(3)$ gauge theory
C. Bonanno, A. Bulgarelli, E. Cellini, A. Nada, D. Pan- falone, D. Vadacchino, and L. Verzichelli, JHEP04, 051, arXiv:2510.25704 [hep-lat]. 10
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
D. Wu, L. Wang, and P. Zhang, Phys. Rev. Lett.122, 080602 (2019)
2019
-
[39]
Singha, E
A. Singha, E. Cellini, K. A. Nicoli, K. Jansen, S. K¨ uhn, and S. Nakajima, inThe Thirteenth International Conference on Learning Representations (ICLR 2025) (2025)
2025
-
[40]
Bia las, P
P. Bia las, P. Korcyl, and T. Stebel, Computer Physics Communications281, 108502 (2022)
2022
- [41]
- [42]
- [43]
-
[44]
G. Kanwar and O. Vega, in42th International Sympo- sium on Lattice Field Theory(2025) arXiv:2512.19877 [hep-lat]
- [45]
-
[46]
V. Kanaujia and V. Arora, arXiv (2025), arXiv:2510.21330 [cs.LG]
-
[47]
H. Alharazin, J. Y. Panteleeva, and B. D. Sun, arXiv (2026), arXiv:2602.09045 [hep-lat]
-
[48]
J. M. Pawlowski and J. M. Urban, Machine Learning: Science and Technology1, 045011 (2020)
2020
-
[49]
J. Singh, M. Scheurer, and V. Arora, SciPost Physics11, 10.21468/scipostphys.11.2.043 (2021)
-
[50]
Singha, D
A. Singha, D. Chakrabarti, and V. Arora, SciPost Phys. Core5, 052 (2022)
2022
-
[51]
L. Del Debbio, J. M. Rossney, and M. Wilson, Phys. Rev. D104, 094507 (2021), arXiv:2105.12481 [hep-lat]
-
[52]
R. Abbottet al., Eur. Phys. J. A59, 257 (2023), arXiv:2211.07541 [hep-lat]
-
[53]
G. Catumba and A. Ramos, Eur. Phys. J. C85, 1037 (2025), arXiv:2502.15570 [hep-lat]
-
[54]
Goodman and A
J. Goodman and A. D. Sokal, Phys. Rev. Lett.56, 1015 (1986)
1986
-
[55]
Goodman and A
J. Goodman and A. D. Sokal, Phys. Rev. D40, 2035 (1989)
2035
-
[56]
W. Janke and T. Sauer, Phys. Rev. E49, 3475 (1994), arXiv:hep-lat/9305016
-
[57]
K. E. Schmidt, Phys. Rev. Lett.51, 2175 (1983)
1983
-
[58]
Faas and H
M. Faas and H. Hilhorst, Physica A: Statistical Mechan- ics and its Applications135, 571 (1986)
1986
- [59]
- [60]
-
[61]
Grabenstein and B
M. Grabenstein and B. Mikeska, Phys. Rev. D47, R3103 (1993)
1993
-
[62]
P. Bia las, P. Czarnota, P. Korcyl, and T. Stebel, Phys. Rev. E107, 054127 (2023), arXiv:2212.04955 [cond- mat.stat-mech]
- [63]
-
[64]
Bauer, R
M. Bauer, R. Kapust, J. M. Pawlowski, and F. L. Tem- men, SciPost Physics19, 077 (2025)
2025
- [65]
-
[66]
M. B. Giles, Acta Numerica24, 259 (2015)
2015
-
[67]
Duane, A
S. Duane, A. Kennedy, B. J. Pendleton, and D. Roweth, Physics Letters B195, 216 (1987)
1987
-
[68]
Madras and A
N. Madras and A. D. Sokal, J. Stat. Phys.50, 109 (1988)
1988
-
[70]
L. P. Kadanoff, Physics Physique Fizika2, 263 (1966)
1966
-
[71]
Binder, Z
K. Binder, Z. Phys. B43, 119 (1981)
1981
-
[72]
M. F. Hutchinson, Commun. Stat. Simul.19, 433 (1990)
1990
-
[73]
U. Wolff (ALPHA), Comput. Phys. Commun.156, 143 (2004), [Erratum: Comput.Phys.Commun. 176, 383 (2007)], arXiv:hep-lat/0306017
-
[74]
D. P. Kingma and J. Ba, Adam: A method for stochastic optimization (2017), arXiv:1412.6980 [cs.LG]. Appendix A: HMC Simulation: Critical Slowing Down and Scaling
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[75]
All simulations are performed at κc = 0.2705,λ= 0.022
Simulation Details ForL∈ {8,16,32,64,128}we run HMC chains with molecular-dynamics trajectory lengthτ MD = 1 and nleap = 10 leapfrog steps (step sizeϵ= 0.1), fixed across all lattice sizes. All simulations are performed at κc = 0.2705,λ= 0.022. The acceptance rate decreases withLsince the step size is not re-tuned per volume (Table II). TABLE II. HMC acce...
-
[76]
Power-Law Fit and Extrapolation Table III collects the measuredτ int(|m|) values. The dynamical critical exponentz dyn is extracted by fitting the power-law ansatzτ int =A L zdyn in log-log space us- ing an unweighted least-squares fit to the five measured pointsL∈ {8,16,32,64,128}: zdyn = 1.99±0.10, A= 0.30,(A1) where the uncertainty is a bootstrap stand...
-
[77]
Overall structure.Our method is a hierarchical coarse-to-fine sampler
Our Multilevel Method a. Overall structure.Our method is a hierarchical coarse-to-fine sampler. It starts from a coarse 8×8 lat- tice and appliesK= log 2(L/8) successive upsampling steps, each doubling the linear lattice size. The full model therefore consists of a standalone coarse-level CNF fol- lowed byKupsampling modules. b. Coarse-level CNF.The coars...
-
[78]
At each upsampling step, the coarse field is naively repeated on a 2×2 block, Gaussian block noise is injected, and a full-lattice (unmasked) CNF refines all L2 ℓ+1 sites jointly
SR-NF SR-NF follows the coarse-to-fine upsampling architec- ture of [64], replacing the HMC-based coarsest sampler with the same dense CNF used in our method (RK4, 40 steps). At each upsampling step, the coarse field is naively repeated on a 2×2 block, Gaussian block noise is injected, and a full-lattice (unmasked) CNF refines all L2 ℓ+1 sites jointly. We...
-
[79]
The vector field is adensesingle-layer FFT-based parameterisation in which each spatial mode 12 interacts with all others, withO(L 4) parameters
Dense CNF Dense CNF [30] is a single-scale baseline: one CNF acts directly on the fullL×Llattice, starting from an isotropic Gaussian prior. The vector field is adensesingle-layer FFT-based parameterisation in which each spatial mode 12 interacts with all others, withO(L 4) parameters. It is integrated with RK4 forn steps = 50 evaluations. A richer Fourie...
-
[80]
Its vector field is a 3-layer convolutional network with 32 hidden channels, 7×7 kernels, and GELU activations
Hutch CNF Hutch CNF is also a single-scale baseline acting di- rectly on the full lattice. Its vector field is a 3-layer convolutional network with 32 hidden channels, 7×7 kernels, and GELU activations. The divergence is esti- mated with the Hutchinson stochastic trace. The ODE is solved with a fixed-step RK4 integrator atn steps = 40, and gradient checkp...
-
[81]
Our method and SR-NF use initial learning rate 10−2; Dense CNF uses 5×10 −3 as in Ref
Training All methods are trained end-to-end with the reverse- KL objective using the Adam optimizer [74] (β 1 = 0.8, β2 = 0.9). Our method and SR-NF use initial learning rate 10−2; Dense CNF uses 5×10 −3 as in Ref. [30]. All methods apply an exponential learning-rate decay with γ= 0.9994 and minimum 10 −4. Gradient norms are clipped at 0.5 for our method,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.