Recognition: unknown
CodeComp: Structural KV Cache Compression for Agentic Coding
Pith reviewed 2026-05-10 15:34 UTC · model grok-4.3
The pith
Incorporating code structure into KV cache compression outperforms attention-only baselines in agentic coding tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A training-free framework for compressing the key-value cache during LLM inference on code augments attention-based token importance with priors from code property graphs produced by static analysis. On bug localization and code generation benchmarks, this approach beats pure attention compression at the same memory budget, retains most of the accuracy of full un-compressed context, and produces patches of equivalent quality to the full-context version.
What carries the argument
The hybrid importance scoring mechanism that ranks tokens for retention using both attention weights and structural significance extracted from code property graphs.
Load-bearing premise
That the tokens marked as structurally critical by static code analysis are reliably more important for task success than those selected purely by attention scores.
What would settle it
If attention-only compression, when forced to retain the same number of tokens, achieves equal or better accuracy on the bug localization and patch generation tasks than the structural hybrid method.
Figures


read the original abstract
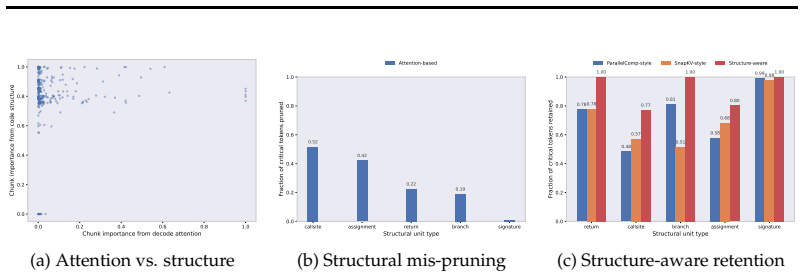
Agentic code tasks such as fault localization and patch generation require processing long codebases under tight memory constraints, where the Key-Value (KV) cache becomes the primary inference bottleneck. Existing compression methods rely exclusively on attention signals to estimate token importance, systematically discarding structurally critical tokens such as call sites, branch conditions, and assignments that are essential for code understanding. We present CodeComp, a training-free KV cache compression framework that incorporates static program analysis into LLM inference via Code Property Graph priors extracted by Joern. Across bug localization and code generation benchmarks, CodeComp consistently outperforms attention-only compression baselines under equal memory budgets, recovering the majority of full-context accuracy under aggressive KV cache compression, while matching the patch generation quality of uncompressed full-context inference and integrating seamlessly into SGLang-based agentic coding pipelines without model modification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodeComp, a training-free KV cache compression framework for agentic coding tasks. It incorporates static program analysis through Code Property Graph (CPG) priors extracted by Joern to retain structurally critical tokens (call sites, branch conditions, assignments) during inference, rather than relying solely on attention signals. The central empirical claim is that this approach outperforms attention-only compression baselines on bug localization and code generation benchmarks under equal memory budgets, recovers most full-context accuracy under aggressive compression, matches uncompressed patch generation quality, and integrates directly into SGLang pipelines without model modification.
Significance. If the results hold under rigorous controls, the work offers a practical, training-free method to mitigate KV cache bottlenecks in long-context code agent scenarios. The use of external static analysis priors and seamless SGLang integration are concrete strengths that could translate to deployment benefits in resource-constrained environments. The approach is falsifiable via standard benchmark comparisons and avoids parameter fitting, which strengthens its potential impact on efficient LLM inference for code.
minor comments (4)
- Abstract: replace qualitative claims such as 'consistently outperforms' and 'recovering the majority of full-context accuracy' with specific quantitative metrics (e.g., exact accuracy deltas, token budgets, and recovery percentages) to allow immediate assessment of the central claim.
- §3 (Method): provide a clear algorithmic description or pseudocode showing exactly how CPG node types are mapped to token retention priorities and combined with attention scores under a fixed budget.
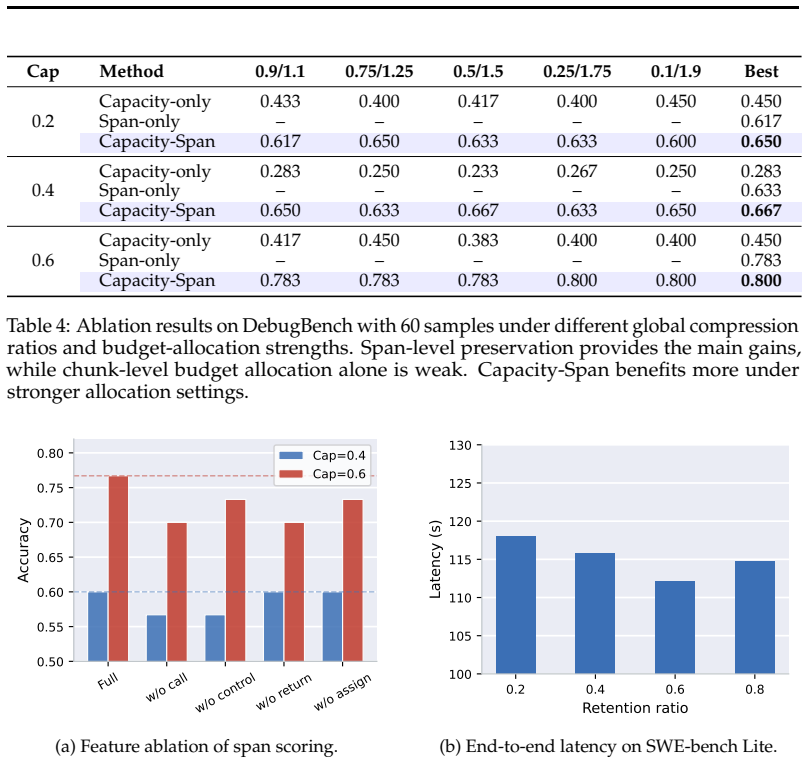
- §4 (Experiments): include an ablation comparing CPG-based selection against random selection of the same number of tokens to isolate the contribution of the structural priors; also report error bars and the precise memory budgets used for all baselines.
- §4.2 (Benchmarks): specify the language coverage of the evaluated codebases and any failure cases where Joern extraction was incomplete or inaccurate.
Simulated Author's Rebuttal
We thank the referee for the positive review and for recommending minor revision. The assessment correctly identifies the core contribution of incorporating Code Property Graph priors from static analysis into training-free KV cache compression, along with the practical advantages of SGLang integration and the falsifiability of the benchmark claims.
Circularity Check
No significant circularity detected
full rationale
The paper presents a training-free method that extracts Code Property Graph priors via the external static analyzer Joern and uses them to guide KV cache retention decisions. No equations or claims reduce by construction to fitted parameters, self-defined quantities, or load-bearing self-citations; the central empirical claim rests on direct comparisons against attention-only baselines under fixed memory budgets. The derivation chain is therefore self-contained against external benchmarks and does not match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Code Property Graphs extracted by Joern accurately capture tokens essential for code understanding (call sites, branches, assignments).
Reference graph
Works this paper leans on
-
[1]
Long code arena: a set of benchmarks for long-context code models
Egor Bogomolov, Aleksandra Eliseeva, Timur Galimzyanov, Evgeniy Glukhov, Anton Shapkin, Maria Tigina, Yaroslav Golubev, Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, and Timofey Bryksin. Long code arena: a set of benchmarks for long-context code models.arXiv preprint arXiv:2406.11612,
-
[2]
Alessio Devoto, Maximilian Jeblick, and Simon J ´egou
URL https: //arxiv.org/abs/2512.07666. Alessio Devoto, Maximilian Jeblick, and Simon J ´egou. Expected attention: Kv cache compression by estimating attention from future queries distribution,
-
[3]
URL https://arxiv.org/abs/2510.00636. Aaron Grattafiori et al. The llama 3 herd of models,
-
[4]
URL https://arxiv.org/abs/ 2407.21783. Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
URLhttps://arxiv.org/abs/2310.06770. Joern Developers. Joern: Code analysis platform,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
StarCoder: may the source be with you!
URL https://arxiv.org/ abs/2305.06161. Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970,
work page internal anchor Pith review arXiv
-
[7]
Chunkkv: Semantic-preserving KV cache compression for efficient long-context LLM inference
Xiang Liu, Zhenheng Tang, Peijie Dong, Zeyu Li, Yue Liu, Bo Li, Xuming Hu, and Xiaowen Chu. Chunkkv: Semantic-preserving kv cache compression for efficient long-context llm inference.arXiv preprint arXiv:2502.00299,
-
[8]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750,
work page internal anchor Pith review arXiv
-
[9]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
URLhttps://arxiv.org/abs/2203.13474. Stefano Rando, Luca Romani, Alessio Sampieri, Luca Franco, John Yang, Yuta Kyuragi, Fabio Galasso, and Tatsunori Hashimoto. Longcodebench: Evaluating coding llms at 1m context windows,
work page internal anchor Pith review arXiv
-
[10]
URLhttps://arxiv.org/abs/2505.07897. Baptiste Rozi`ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, J´er´emy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre D ´efossez, Jade Copet, Fais...
-
[11]
Code Llama: Open Foundation Models for Code
URLhttps://arxiv.org/abs/2308.12950. Qwen Team. Qwen3 technical report,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://arxiv.org/abs/2505.09388. 11 Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Debugbench: Evaluating debugging capability of large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URL https://arxiv.org/abs/2407. 01489. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient stream- ing language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review arXiv
-
[14]
Fabian Yamaguchi, Nico Golde, Daniel Arp, and Konrad Rieck
URL https://arxiv.org/abs/ 2502.14317. Fabian Yamaguchi, Nico Golde, Daniel Arp, and Konrad Rieck. Modeling and discovering vulnerabilities with code property graphs. InProceedings of the 2014 IEEE Symposium on Security and Privacy, pp. 590–604,
-
[15]
https://doi.org/10.1109/SP.2014.44
URLhttps://doi.org/10.1109/SP.2014.44. Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. ∞Bench: Extending long context evaluation beyond 100K tokens. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Proceedings of the 62nd Annual Meeting of the Association for Com...
-
[16]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark Barrett, et al
URLhttps://aclanthology.org/2024.acl-long.814. Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710,
2024
-
[17]
SGLang: Efficient Execution of Structured Language Model Programs
URL https://arxiv.org/abs/2312.07104. A Appendix A.1 Experimental Setup Models and benchmarks.We evaluate two 8B-scale code language models, Llama-3- 8B-Instruct (Grattafiori et al.,
work page internal anchor Pith review arXiv
-
[18]
For bug localization, we use InfiniteBench-CodeDebug (Zhang et al., 2024), DebugBench (Tian et al., 2024), and LongCodeQA (Rando et al., 2025)
and Qwen3-8B (Team, 2025), across five benchmarks spanning two task types. For bug localization, we use InfiniteBench-CodeDebug (Zhang et al., 2024), DebugBench (Tian et al., 2024), and LongCodeQA (Rando et al., 2025). For code generation, we use SWE-bench Lite (Jimenez et al.,
2025
-
[19]
All experiments are conducted using SGLang (Zheng et al.,
and the LCA library-based code generation benchmark (Bogomolov et al., 2024). All experiments are conducted using SGLang (Zheng et al.,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.