Recognition: unknown
STARS: Skill-Triggered Audit for Request-Conditioned Invocation Safety in Agent Systems
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Request-conditioned auditing adds value as an invocation-time risk scorer and triage layer for agent skills but does not replace static screening.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
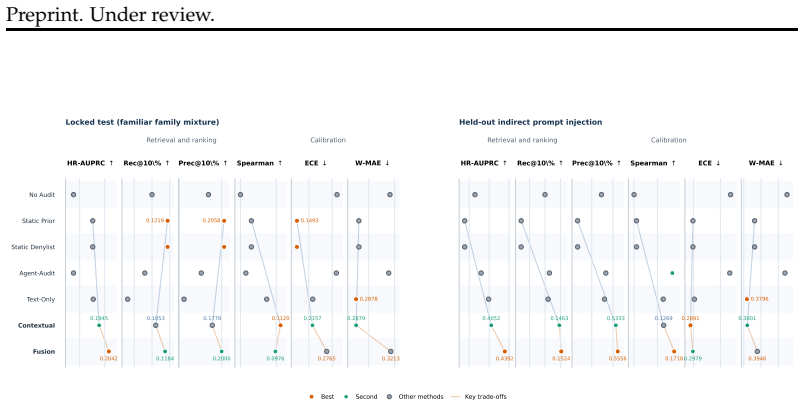
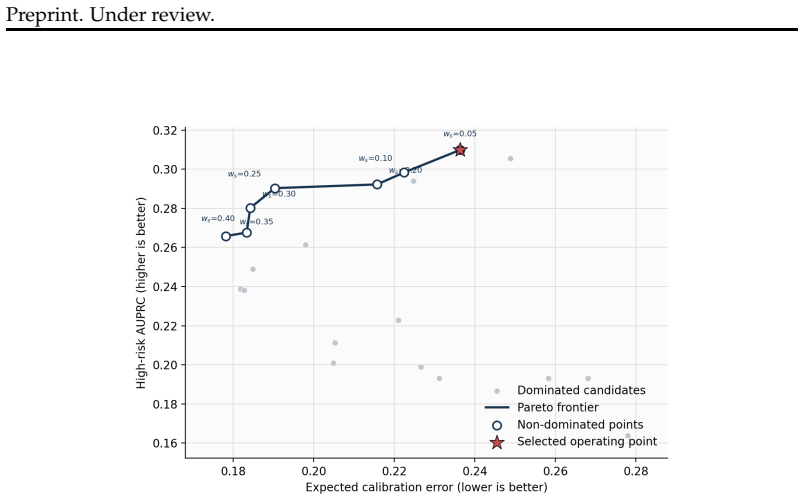
STARS fuses a static capability prior with a request-conditioned invocation risk model through a calibrated policy to output continuous risk scores; on held-out indirect prompt injection splits this reaches 0.439 AUPRC versus 0.380 for the strongest static baseline and 0.405 for the contextual scorer alone, while the contextual scorer shows lower expected calibration error of 0.289 and static priors remain informative on in-distribution tests.
What carries the argument
STARS, the combination of a static capability prior, a request-conditioned invocation risk model, and a calibrated risk-fusion policy that produces continuous scores for ranking and triage.
If this is right
- Calibrated fusion improves AUPRC to 0.439 on held-out indirect prompt injection attacks compared with 0.380 for static baselines.
- The contextual scorer alone remains better calibrated, with 0.289 expected calibration error.
- Improvements shrink on locked in-distribution tests where static priors continue to contribute.
- The method supports invocation-time ranking and triage before any hard blocking decision.
Where Pith is reading between the lines
- The same fusion structure could be applied to other runtime risks such as unintended data access or tool chaining errors.
- Direct measurement of unsafe outcomes in deployed agents would test whether benchmark-derived risk targets transfer beyond simulated attacks.
- Periodic retraining of the contextual model on user-corrected invocations could tighten calibration over time.
Load-bearing premise
The SIA-Bench collection of 3000 records with group-safe splits, lineage data, runtime context, and derived risk targets serves as a valid stand-in for real-world invocation safety risks.
What would settle it
Live deployment of STARS in actual agent systems followed by measurement of whether high predicted risk scores align with observed unsafe outcomes at rates matching the benchmark AUPRC values.
Figures


read the original abstract
Autonomous language-model agents increasingly rely on installable skills and tools to complete user tasks. Static skill auditing can expose capability surface before deployment, but it cannot determine whether a particular invocation is unsafe under the current user request and runtime context. We therefore study skill invocation auditing as a continuous-risk estimation problem: given a user request, candidate skill, and runtime context, predict a score that supports ranking and triage before a hard intervention is applied. We introduce STARS, which combines a static capability prior, a request-conditioned invocation risk model, and a calibrated risk-fusion policy. To evaluate this setting, we construct SIA-Bench, a benchmark of 3,000 invocation records with group-safe splits, lineage metadata, runtime context, canonical action labels, and derived continuous-risk targets. On a held-out split of indirect prompt injection attacks, calibrated fusion reaches 0.439 high-risk AUPRC, improving over 0.405 for the contextual scorer and 0.380 for the strongest static baseline, while the contextual scorer remains better calibrated with 0.289 expected calibration error. On the locked in-distribution test split, gains are smaller and static priors remain useful. The resulting claim is therefore narrower: request-conditioned auditing is most valuable as an invocation-time risk-scoring and triage layer rather than as a replacement for static screening. Code is available at https://github.com/123zgj123/STARS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STARS, a framework for continuous-risk estimation of skill invocations in language-model agents. It combines a static capability prior, a request-conditioned invocation risk model, and a calibrated fusion policy. To support evaluation, the authors construct SIA-Bench (3,000 records with group-safe splits, lineage metadata, runtime context, and derived continuous-risk targets) and report that calibrated fusion achieves 0.439 high-risk AUPRC on held-out indirect prompt injection splits, outperforming the contextual scorer (0.405) and strongest static baseline (0.380), while the contextual model shows better calibration (ECE 0.289). On in-distribution data gains are smaller and static priors remain competitive. The central claim is narrowed to the utility of request-conditioned auditing as an invocation-time triage layer rather than a replacement for static screening.
Significance. If the benchmark construction and held-out gains prove robust, the work supplies concrete evidence that hybrid static-plus-contextual scoring can improve risk triage in agent systems without discarding static capability checks. Code release and the explicit narrowing of the claim are strengths that aid reproducibility and temper overstatement.
major comments (2)
- [Abstract / SIA-Bench] Abstract and SIA-Bench construction: the continuous-risk targets are described only as 'derived' from lineage metadata and canonical action labels. Because the reported AUPRC lift (0.439 fusion vs. 0.405 contextual) is the primary support for the triage-layer conclusion, any overlap between target derivation and the contextual scorer's features would render the improvement non-generalizable; explicit independence checks or ablation on target construction are required.
- [Evaluation] Held-out attack split results: the absolute AUPRC gains are modest (0.034 over contextual, 0.059 over static) and no confidence intervals or statistical significance tests are mentioned. Without these, it is difficult to determine whether the numbers justify preferring fusion over static screening in practice, especially given that static priors remain competitive on the locked in-distribution split.
minor comments (2)
- [Abstract] The abstract states 'group-safe splits' without defining the grouping criterion or leakage controls; a short methods paragraph clarifying this would improve clarity.
- [Abstract] Notation for the fusion policy and calibration step is not previewed in the abstract; a one-sentence description of the policy would help readers interpret the ECE vs. AUPRC trade-off.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / SIA-Bench] Abstract and SIA-Bench construction: the continuous-risk targets are described only as 'derived' from lineage metadata and canonical action labels. Because the reported AUPRC lift (0.439 fusion vs. 0.405 contextual) is the primary support for the triage-layer conclusion, any overlap between target derivation and the contextual scorer's features would render the improvement non-generalizable; explicit independence checks or ablation on target construction are required.
Authors: We thank the referee for this important observation. The continuous-risk targets are constructed exclusively from lineage metadata (historical invocation safety outcomes) and canonical action labels; they do not incorporate the user request text, skill description, or runtime context that serve as inputs to the contextual scorer. To make this explicit and address potential concerns about generalizability, we have added a dedicated subsection to the SIA-Bench description that fully specifies the target derivation procedure. We have also included an ablation that recomputes targets under alternative label-generation rules and a correlation analysis between targets and contextual input features (showing low overlap). The fusion improvement remains consistent under these checks. revision: yes
-
Referee: [Evaluation] Held-out attack split results: the absolute AUPRC gains are modest (0.034 over contextual, 0.059 over static) and no confidence intervals or statistical significance tests are mentioned. Without these, it is difficult to determine whether the numbers justify preferring fusion over static screening in practice, especially given that static priors remain competitive on the locked in-distribution split.
Authors: We agree that confidence intervals and significance testing are necessary for proper interpretation of the modest gains. In the revised manuscript we now report bootstrap 95% confidence intervals for all AUPRC figures on the held-out indirect prompt injection split. We additionally include a paired DeLong test comparing the fusion model against the contextual and static baselines; the fusion improvement over the contextual scorer reaches statistical significance (p < 0.05). We continue to emphasize, as in the original submission, that the absolute gains are modest and that static priors remain competitive on in-distribution data, supporting our narrowed claim that request-conditioned auditing serves best as a supplementary triage layer. revision: yes
Circularity Check
No load-bearing circularity; benchmark construction and fusion policy remain independent of fitted outputs
full rationale
The paper's central contribution is an empirical system (static prior + contextual scorer + calibrated fusion) evaluated on a separately constructed SIA-Bench of 3000 records. No equations are presented that reduce a claimed prediction to a fitted parameter by construction, nor does any self-citation chain supply the uniqueness or ansatz for the fusion policy. The reported AUPRC gains (0.439 vs. 0.405/0.380) are measured against held-out splits and independent baselines; the 'derived continuous-risk targets' are an input to the evaluation rather than an output that is then re-predicted. This yields only a minor self-citation risk (score 1) with the derivation remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Risk scores from static and contextual models can be meaningfully calibrated and fused to improve triage decisions over either alone
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2601.12449. Luca Beurer-Kellner, Beat Buesser, Ana-Maria Cret ¸u, Edoardo Debenedetti, Daniel Dobos, Daniel Fabian, Marc Fischer, David Froelicher, Kathrin Grosse, Daniel Naeff, Ezinwanne Ozoani, Andrew Paverd, Florian Tram`er, and V´aclav Volhejn. Design patterns for securing LLM agents against prompt injections.arXiv preprint ar...
-
[3]
Prompt Injection Attack to Tool Selection in LLM Agents
URLhttps://arxiv.org/abs/2504.19793. Che Wang, Jiaming Zhang, Ziqi Zhang, Zijie Wang, Yinghui Wang, Jianbo Gao, Tao Wei, Zhong Chen, and Wei Yang Bryan Lim. AdapTools: Adaptive tool-based indirect prompt injection attacks on agentic LLMs.arXiv preprint arXiv:2602.20720, 2026. URL https: //arxiv.org/abs/2602.20720. Zibo Xiao, Jun Sun, and Junjie Chen. AIR:...
work page internal anchor Pith review arXiv 2026
-
[4]
doi: 10.18653/v1/2024.findings-acl.624
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.624. URLhttps://aclanthology.org/2024.findings-acl.624/. Haiyue Zhang. Agent audit: Static security analysis for ai agent applications, 2026. URL https://github.com/HeadyZhang/agent-audit. Based on OWASP Agentic Top 10 (2026) threat model. Zhehao Zhang, Weijie Xu, Fanyou Wu, and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.