Recognition: unknown
Comparative Analysis of Large Language Models in Healthcare
Pith reviewed 2026-05-10 15:28 UTC · model grok-4.3
The pith
Domain-specific models like ChatDoctor produce more medically accurate text than general-purpose LLMs, which score higher on structured question-answering tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
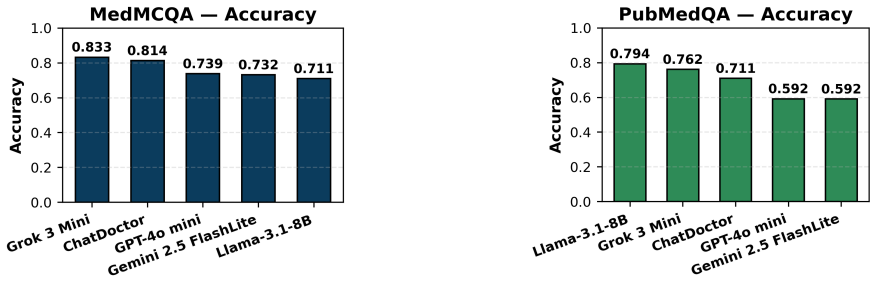
The paper establishes that domain-specific models such as ChatDoctor excel in contextual reliability, producing medically accurate and semantically aligned text, whereas general-purpose models like Grok and LLaMA perform better in structured question-answering tasks, demonstrating higher quantitative accuracy. This pattern holds across the tested datasets and highlights complementary strengths that depend on whether the medical task emphasizes narrative coherence or precise factual retrieval.
What carries the argument
Comparative evaluation of five LLMs on patient note summarization and medical question answering, scored with a mix of linguistic metrics and task-specific accuracy measures across the MedMCQA, PubMedQA, and Asclepius datasets.
If this is right
- Task-specific selection of LLMs becomes necessary for different healthcare applications.
- Human oversight remains essential to maintain contextual accuracy and ethical standards.
- Complementary deployment of domain-specific and general-purpose models can optimize support for clinicians.
- Standardized benchmarking across tasks is required before wider integration into clinical workflows.
Where Pith is reading between the lines
- Extending the tests to real electronic health record data could expose performance gaps the current benchmarks miss.
- Regulatory guidelines might need to require separate validation for each clinical task rather than blanket approvals.
- Future work could examine whether combining a domain-specific model with a general one reduces the observed trade-offs.
- Similar comparative studies on other high-stakes domains such as law or finance might show the same pattern of specialization benefits.
Load-bearing premise
The selected linguistic and task-specific metrics together with the three datasets adequately reflect real-world clinical accuracy, reliability, and patient safety.
What would settle it
A follow-up test in which practicing physicians rate the models' outputs on anonymized real patient cases for factual correctness and clinical safety, then find no reliable performance gap between domain-specific and general models.
Figures








read the original abstract
Background: Large Language Models (LLMs) are transforming artificial intelligence applications in healthcare due to their ability to understand, generate, and summarize complex medical text. They offer valuable support to clinicians, researchers, and patients, yet their deployment in high-stakes clinical environments raises critical concerns regarding accuracy, reliability, and patient safety. Despite substantial attention in recent years, standardized benchmarking of LLMs for medical applications has been limited. Objective: This study addresses the need for a standardized comparative evaluation of LLMs in medical settings. Method: We evaluate multiple models, including ChatGPT, LLaMA, Grok, Gemini, and ChatDoctor, on core medical tasks such as patient note summarization and medical question answering, using the open-access datasets, MedMCQA, PubMedQA, and Asclepius, and assess performance through a combination of linguistic and task-specific metrics. Results: The results indicate that domain-specific models, such as ChatDoctor, excel in contextual reliability, producing medically accurate and semantically aligned text, whereas general-purpose models like Grok and LLaMA perform better in structured question-answering tasks, demonstrating higher quantitative accuracy. This highlights the complementary strengths of domain-specific and general-purpose LLMs depending on the medical task. Conclusion: Our findings suggest that LLMs can meaningfully support medical professionals and enhance clinical decision-making; however, their safe and effective deployment requires adherence to ethical standards, contextual accuracy, and human oversight in relevant cases. These results underscore the importance of task-specific evaluation and cautious integration of LLMs into healthcare workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a comparative evaluation of LLMs including ChatGPT, LLaMA, Grok, Gemini, and ChatDoctor on healthcare tasks such as patient note summarization and medical question answering. It uses the MedMCQA, PubMedQA, and Asclepius datasets together with linguistic and task-specific metrics to claim that domain-specific models like ChatDoctor excel in contextual reliability and medical accuracy while general-purpose models perform better on structured QA tasks with higher quantitative accuracy, highlighting complementary strengths and the need for human oversight.
Significance. A rigorous comparative study of this kind could help clarify task-dependent strengths of domain-adapted versus general LLMs in medicine. However, the absence of quantitative scores, statistical tests, reproducibility details, and validation of metrics against clinical factuality or safety judgments substantially limits the ability to assess whether the reported distinctions are reliable or clinically meaningful.
major comments (4)
- [Abstract/Results] Abstract and Results: The abstract and results state only directional claims (domain-specific models excel in contextual reliability; general models show higher quantitative accuracy) without reporting any numerical scores, confidence intervals, or statistical significance tests for the model comparisons on each dataset and task.
- [Methods] Methods: No details are supplied on prompt templates, model versions, temperature or sampling settings, or the precise definitions and implementations of the 'linguistic and task-specific metrics,' all of which are required to evaluate reproducibility and rule out confounds.
- [Methods/Evaluation] Evaluation design: The chosen metrics (accuracy, ROUGE/BLEU-style overlap, semantic similarity) are not shown to have been validated against clinician judgments or medical error taxonomies; automated overlap scores can be high for fluent but factually unsafe outputs (e.g., hallucinated contraindications), directly undermining claims about 'medically accurate' text and 'patient safety.'
- [Datasets] Datasets and generalizability: MedMCQA, PubMedQA, and Asclepius consist of multiple-choice exam questions and abstracts rather than real-world patient notes or ambiguous clinical cases; this choice weakens support for conclusions about 'contextual reliability' and downstream clinical utility.
minor comments (2)
- [Results] The manuscript would benefit from a summary table reporting per-model, per-task scores for all metrics to allow direct comparison of the claimed performance differences.
- [Conclusion] The conclusion invokes 'ethical standards' and 'human oversight' without specifying concrete recommendations or referencing relevant guidelines (e.g., FDA or WHO AI in healthcare documents).
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. The comments highlight important areas for improving the rigor, reproducibility, and clinical relevance of our comparative analysis. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract/Results] Abstract and results state only directional claims without reporting any numerical scores, confidence intervals, or statistical significance tests for the model comparisons on each dataset and task.
Authors: We agree that the abstract and results would benefit from greater quantitative specificity. In the revised manuscript we will update the abstract to reference key performance metrics and expand the results section to report numerical scores, confidence intervals, and statistical significance tests for each model-dataset-task combination. revision: yes
-
Referee: [Methods] No details on prompt templates, model versions, temperature or sampling settings, or precise definitions and implementations of the linguistic and task-specific metrics.
Authors: We acknowledge this omission. The revised methods section will include the full prompt templates, exact model versions and checkpoints, temperature and sampling parameters, and detailed definitions plus implementation code references for every metric used. revision: yes
-
Referee: [Methods/Evaluation] Chosen metrics are not validated against clinician judgments or medical error taxonomies; automated scores can be high for factually unsafe outputs, undermining claims about medical accuracy and patient safety.
Authors: We recognize that standard automated metrics have well-known limitations in detecting clinical factuality and safety risks. We will revise the discussion to explicitly state that these metrics were not validated against clinician judgments in the present study, qualify our accuracy claims accordingly, and reinforce the necessity of human oversight already noted in the conclusions. revision: partial
-
Referee: [Datasets] MedMCQA, PubMedQA, and Asclepius consist of multiple-choice questions and abstracts rather than real-world patient notes or ambiguous cases, weakening support for conclusions about contextual reliability and clinical utility.
Authors: These datasets were chosen as established, reproducible benchmarks. We agree they do not capture the full complexity of real-world clinical encounters. The revised discussion will expand the limitations section to address generalizability and note the value of future evaluations on more diverse, real-world patient data. revision: partial
Circularity Check
Direct empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper reports performance of LLMs (ChatGPT, LLaMA, Grok, Gemini, ChatDoctor) on MedMCQA, PubMedQA, and Asclepius using standard linguistic and task-specific metrics. No equations, fitted parameters, or predictions appear; results are direct measurements of accuracy, semantic alignment, and related scores. No self-citations are invoked to justify uniqueness or to close a derivation chain. The central claim (domain-specific models excel at contextual reliability while general models excel at structured QA) follows from the tabulated metric values rather than reducing to any input quantity by construction. This is a standard empirical comparison whose validity can be assessed against external clinician judgment or additional datasets.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
AgenticVM: Agentic AI for Adaptive Software Vulnerability Management
AgenticVM reduces vulnerability scanner alerts by up to 98% and predicts missing CVSS attributes with 89.3% accuracy using a multi-agent LLM framework integrated with security tools and public databases.
Reference graph
Works this paper leans on
-
[1]
Scalar: Self- calibrating adaptive latent attention representation learning
Farwa Abbas, Hussain Ahmad, and Claudia Szabo. Scalar: Self- calibrating adaptive latent attention representation learning. In2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI), pages 762–769. IEEE, 2025
2025
-
[2]
Australian bushfire intelligence with ai-driven environmental analytics,
Tanvi Jois, Hussain Ahmad, Fatima Noor, and Faheem Ullah. Australian bushfire intelligence with ai-driven environmental analytics.arXiv preprint arXiv:2601.06105, 2026
-
[3]
Robust partial least squares using low rank and sparse decomposition,
Farwa Abbas and Hussain Ahmad. Robust partial least squares using low rank and sparse decomposition.arXiv preprint arXiv:2407.06936, 2024
-
[4]
Regimefolio: A regime aware ml system for sectoral portfolio optimiza- tion in dynamic markets.IEEE Access, 2025
Yiyao Zhang, Diksha Goel, Hussain Ahmad, and Claudia Szabo. Regimefolio: A regime aware ml system for sectoral portfolio optimiza- tion in dynamic markets.IEEE Access, 2025
2025
-
[5]
The future of ai: Exploring the potential of large concept models,
Hussain Ahmad and Diksha Goel. The future of ai: Exploring the potential of large concept models.arXiv preprint arXiv:2501.05487, 2025
-
[6]
Diksha Goel, Hussain Ahmad, Kristen Moore, and Mingyu Guo. Co-evolutionary defence of active directory attack graphs via gnn- approximated dynamic programming.arXiv preprint arXiv:2505.11710, 2025
-
[7]
Machine learning driven smishing detection framework for mobile security,
Diksha Goel, Hussain Ahmad, Ankit Kumar Jain, and Nikhil Kumar Goel. Machine learning driven smishing detection framework for mobile security.arXiv preprint arXiv:2412.09641, 2024
-
[8]
Microservice vulnerability analysis: A literature review with empirical insights.IEEE Access, 12:155168– 155204, 2024
Raveen Kanishka Jayalath, Hussain Ahmad, Diksha Goel, Muham- mad Shuja Syed, and Faheem Ullah. Microservice vulnerability analysis: A literature review with empirical insights.IEEE Access, 12:155168– 155204, 2024
2024
-
[9]
A survey on immersive cyber situational awareness systems.Journal of Cybersecurity and Privacy, 5(2):33, 2025
Hussain Ahmad, Faheem Ullah, and Rehan Jafri. A survey on immersive cyber situational awareness systems.Journal of Cybersecurity and Privacy, 5(2):33, 2025
2025
-
[10]
Towards resource-efficient reactive and proactive auto-scaling for mi- croservice architectures.Journal of Systems and Software, 225:112390, 2025
Hussain Ahmad, Christoph Treude, Markus Wagner, and Claudia Szabo. Towards resource-efficient reactive and proactive auto-scaling for mi- croservice architectures.Journal of Systems and Software, 225:112390, 2025
2025
-
[11]
Smart hpa: A resource-efficient horizontal pod auto-scaler for microservice architectures
Hussain Ahmad, Christoph Treude, Markus Wagner, and Claudia Sz- abo. Smart hpa: A resource-efficient horizontal pod auto-scaler for microservice architectures. In2024 IEEE 21st International Conference on Software Architecture (ICSA), pages 46–57. IEEE, 2024
2024
-
[12]
Resilient auto-scaling of microservice architectures with efficient resource management,
Hussain Ahmad, Christoph Treude, Markus Wagner, and Claudia Sz- abo. Resilient auto-scaling of microservice architectures with efficient resource management.arXiv preprint arXiv:2506.05693, 2025
-
[13]
A review on c3i systems’ security: Vulnerabilities, attacks, and countermeasures.ACM Computing Surveys, 55(9):1–38, 2023
Hussain Ahmad, Isuru Dharmadasa, Faheem Ullah, and Muhammad Ali Babar. A review on c3i systems’ security: Vulnerabilities, attacks, and countermeasures.ACM Computing Surveys, 55(9):1–38, 2023
2023
-
[14]
Towards deep learning enabled cybersecurity risk assessment for mi- croservice architectures.Cluster Computing, 28(6):350, 2025
Majid Abdulsatar, Hussain Ahmad, Diksha Goel, and Faheem Ullah. Towards deep learning enabled cybersecurity risk assessment for mi- croservice architectures.Cluster Computing, 28(6):350, 2025
2025
-
[15]
What skills do cybersecurity professionals need? Information & Computer Security, pages 1–19, 2026
Faheem Ullah, Xiaohan Ye, Uswa Fatima, Yuxi Wu, Zahid Akhtar, and Hussain Ahmad. What skills do cybersecurity professionals need? Information & Computer Security, pages 1–19, 2026
2026
-
[16]
Explainable Autonomous Cyber Defense using Adversarial Multi-Agent Reinforcement Learning
Yiyao Zhang, Diksha Goel, and Hussain Ahmad. Explainable au- tonomous cyber defense using adversarial multi-agent reinforcement learning.arXiv preprint arXiv:2604.04442, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
” i think this is the most disruptive technology
Mubin Ul Haque, Isuru Dharmadasa, Zarrin Tasnim Sworna, Roshan Na- mal Rajapakse, and Hussain Ahmad. ” i think this is the most disruptive technology”: Exploring sentiments of chatgpt early adopters using twitter data.arXiv preprint arXiv:2212.05856, 2022
-
[18]
Chatnvd: Advancing cybersecurity vulnerability assessment with large language models.IEEE Access, 2026
Shivansh Chopra, Hussain Ahmad, Diksha Goel, and Claudia Szabo. Chatnvd: Advancing cybersecurity vulnerability assessment with large language models.IEEE Access, 2026
2026
-
[19]
Kefan Chen, Hussain Ahmad, Diksha Goel, and Claudia Szabo. 3s- trader: A multi-llm framework for adaptive stock scoring, strategy, and selection in portfolio optimization.arXiv preprint arXiv:2510.17393, 2025
-
[20]
Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models.PLOS Digital Health, 2(2):e0000198, 2023
Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepano, Maria Madriaga, Rianna Aggabao, Giezel Diaz-Candido, James Maningo, et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models.PLOS Digital Health, 2(2):e0000198, 2023
2023
-
[21]
Capabilities of gpt-4 on medical challenge problems,
Harsha Nori et al. Capabilities of gpt-4 on medical challenge problems,
-
[22]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[23]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge.Cureus, 15(6), 2023
Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge.Cureus, 15(6), 2023
2023
-
[25]
Zhengliang Liu, Yiwei Li, Peng Shu, Aoxiao Zhong, Longtao Yang, Chao Ju, Zihao Wu, Chong Ma, Jie Luo, Cheng Chen, et al. Radiology- llama2: Best-in-class large language model for radiology.arXiv preprint arXiv:2309.06419, 2023
-
[26]
Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum.JAMA internal medicine, 183(6):589–596, 2023
John W Ayers, Adam Poliak, Mark Dredze, Eric C Leas, Zechariah Zhu, Jessica B Kelley, Dennis J Faix, Aaron M Goodman, Christopher A Longhurst, Michael Hogarth, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum.JAMA internal medicine, 183(6):589–596, 2023
2023
-
[27]
Analysis of large-language model versus human performance for genetics questions.European Journal of Human Genetics, 32(4):466–468, 2024
Diana Duong and Benjamin D Solomon. Analysis of large-language model versus human performance for genetics questions.European Journal of Human Genetics, 32(4):466–468, 2024
2024
-
[28]
A framework for human evaluation of large language models in healthcare.npj Digital Medicine, 7:258, 2024
T Y C Tam et al. A framework for human evaluation of large language models in healthcare.npj Digital Medicine, 7:258, 2024
2024
-
[29]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[30]
Rouge: A package for automatic evaluation of sum- maries.Text summarization branches out, pages 74–81, 2004
Chin-Yew Lin. Rouge: A package for automatic evaluation of sum- maries.Text summarization branches out, pages 74–81, 2004
2004
-
[31]
Llms-healthcare.Artifi- cial Intelligence in Health, 1(2):16–28, 2024
Umar Mumtaz, Ali Ahmed, and Sara Mumtaz. Llms-healthcare.Artifi- cial Intelligence in Health, 1(2):16–28, 2024
2024
-
[32]
Large language models in health care.Health Care Science, 2(4):255–263, 2023
Rui Yang et al. Large language models in health care.Health Care Science, 2(4):255–263, 2023
2023
-
[33]
Applications and concerns of chatgpt in health care
Lei Wang et al. Applications and concerns of chatgpt in health care. Journal of Medical Internet Research, 26:e22769, 2024
2024
-
[34]
Current applications and challenges in large language models for patient care.Communications Medicine, 5(1):26, 2025
Florian Busch et al. Current applications and challenges in large language models for patient care.Communications Medicine, 5(1):26, 2025
2025
-
[35]
Opportunities and challenges for llms in primary health care.Journal of Primary Care and Community Health, 16:215, 2025
Hao Qin and Yan Tong. Opportunities and challenges for llms in primary health care.Journal of Primary Care and Community Health, 16:215, 2025
2025
-
[36]
Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios.Journal of medical systems, 47(1):33, 2023
Marco Cascella, Jonathan Montomoli, Valentina Bellini, and Elena Bignami. Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios.Journal of medical systems, 47(1):33, 2023
2023
-
[37]
Large language models encode clinical knowledge
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Nature, 620(7972):172–180, 2023
2023
-
[38]
Capabil- ities of GPT-4 on Medical Challenge Problems
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of GPT-4 on medical challenge problems. arXiv preprint arXiv:2303.13375, 2023
-
[39]
Can large language models reason about medical knowledge?Patterns, 5(3):100943, 2024
Valentin Li ´evin, Christoffer Egeberg Hother, Andreas Geert Motzfeldt, and Ole Winther. Can large language models reason about medical knowledge?Patterns, 5(3):100943, 2024
2024
-
[40]
Clinical text summarization: Adapting large language models can outperform human experts.Research Square, 2023
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, et al. Clinical text summarization: Adapting large language models can outperform human experts.Research Square, 2023
2023
-
[41]
Qiao Jin, Bhuwan Dhingra, Zhiyong Liu, William W Cohen, and Xinghua Lu. PubMedQA: A dataset for biomedical research question answering.arXiv preprint arXiv:1909.06146, 2019
-
[42]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[43]
Revolu- tionizing medicine: the role of ai in healthcare.Edu-Tech Enterprise, 3:1–25, 2025
V PremaLatha, Dinesh Kumar Anguraj, and Nikhat Parveen. Revolu- tionizing medicine: the role of ai in healthcare.Edu-Tech Enterprise, 3:1–25, 2025
2025
-
[44]
Pubmed: the bibliographic database.The NCBI handbook, 2(1):2013, 2013
Kathi Canese and Sarah Weis. Pubmed: the bibliographic database.The NCBI handbook, 2(1):2013, 2013
2013
-
[45]
Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database.Scientific data, 3(1):1–9, 2016
2016
-
[46]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[47]
Comparative evaluation of large language models for medical education: Performance analysis in urinary system histology
Anik ´o Szab ´o and Ghasem Dolatkhah Laein. Comparative evaluation of large language models for medical education: Performance analysis in urinary system histology. 2025
2025
-
[48]
A study of generative large language models for medical research.npj Digital Medicine, 6:210, 2023
Cheng Peng et al. A study of generative large language models for medical research.npj Digital Medicine, 6:210, 2023
2023
-
[49]
Large language models in healthcare, 2025
Mohammed Al-Garadi et al. Large language models in healthcare, 2025. Preprint
2025
-
[50]
Medmcqa, 2022
A Agrawal et al. Medmcqa, 2022. Dataset
2022
-
[51]
Pubmedqa
Qiao Jin et al. Pubmedqa. InProceedings of EMNLP-IJCNLP, pages 2567–2577, 2019
2019
-
[52]
Publicly shareable clinical large language model built on synthetic clinical notes
Sunjun Kweon, Junu Kim, Jiyoun Kim, Sujeong Im, Eunbyeol Cho, Seongsu Bae, Jungwoo Oh, Gyubok Lee, Jong Hak Moon, Seng Chan You, et al. Publicly shareable clinical large language model built on synthetic clinical notes. InFindings of the Association for Computational Linguistics: ACL 2024, pages 5148–5168, 2024
2024
-
[53]
On the impact of fine-tuning on chain-of-thought reasoning
Elita Lobo, Chirag Agarwal, and Himabindu Lakkaraju. On the impact of fine-tuning on chain-of-thought reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 11679–11698, 2025
2025
-
[54]
A systematic analysis of per- formance measures for classification tasks.Information processing & management, 45(4):427–437, 2009
Marina Sokolova and Guy Lapalme. A systematic analysis of per- formance measures for classification tasks.Information processing & management, 45(4):427–437, 2009
2009
-
[55]
Bertscore: Evaluating text generation with bert
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. InInternational Conference on Learning Representations, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.