Recognition: unknown
Counting finite O-sequences: sub-Fibonacci behaviour and growth estimates
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
The sequence counting finite O-sequences whose last nonzero term exceeds 1 is sub-Fibonacci, with exact values to multiplicity 1100 refining asymptotic growth bounds and disproving a 1992 question.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
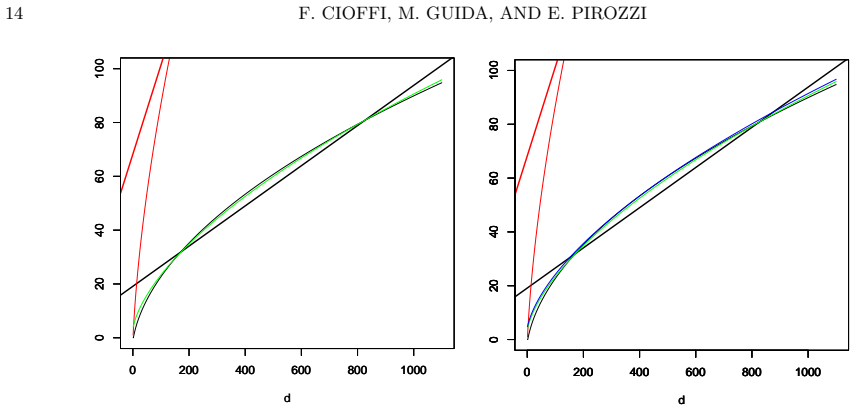
Exploiting an iterative formula already introduced in a previous manuscript to count the number O_d of finite O-sequences of multiplicity d, we prove that the sequence (A_{d+2})_{d≥1} is sub-Fibonacci. We develop an algorithm that computes O_d up to d=1100 and use the data to obtain an empirical calibration of the Stanley-Zanello asymptotic upper bound for log(O_d) that better fits the observed values. An analogous calibration of the lower bound is carried out, some consequent prediction estimates are proposed, and we show that a question posed by L. G. Roberts in 1992 has a negative answer.
What carries the argument
The iterative formula that enumerates every finite O-sequence of multiplicity d exactly once, which both establishes the sub-Fibonacci property for the shifted count A_d and powers the algorithm for exact computation up to d=1100.
If this is right
- The sequence (A_{d+2})_{d≥1} satisfies A_{d+2} ≤ A_{d+1} + A_d.
- The calibrated Stanley-Zanello upper bound for log(O_d) matches the computed values more closely than the original bound throughout 1 ≤ d ≤ 1100.
- An analogous empirical improvement holds for the lower bound on log(O_d).
- The calibrated constants yield explicit prediction estimates for O_d at multiplicities larger than 1100.
- The computations supply a concrete negative answer to Roberts' 1992 question.
Where Pith is reading between the lines
- If the sub-Fibonacci inequality continues to hold for d > 1100, then A_d grows no faster than a constant multiple of the Fibonacci numbers.
- Running the same algorithm for a few values of d just above 1100 would test whether the calibrated bounds remain accurate.
- The exact counts up to 1100 could serve as a benchmark for any future closed-form formula or generating-function approach to O_d.
Load-bearing premise
The iterative formula correctly generates every finite O-sequence of a given multiplicity exactly once with no omissions or duplicates.
What would settle it
A direct enumeration for some d ≤ 1100 that produces a different value of O_d or A_d than the algorithm, or a computed A_{d+2} > A_{d+1} + A_d for any d.
Figures





read the original abstract
Exploiting an iterative formula already introduced in a previous manuscript to count the number $O_d$ of finite $O$-sequences of multiplicity $d$, we obtain some new information about $O_d$. Letting $A_d$ be the number of the finite $O$-sequences of multiplicity $d$ whose last non-zero element is strictly larger than $1$, first we prove that the sequence $(A_{d+2})_{d\geq 1}$ is sub-Fibonacci, as was already proved for $(O_d)_d$. Then, we develop an algorithm that allows the computation of $O_d$ up to $d=1100$ and use the computed data to obtain an empirical calibration in the interval $1\leq d \leq 1100$ of the Stanley-Zanello asymptotic upper bound for $\log(O_d)$ that better fits the observed values of $\log(O_d)$ in the given interval. An analogous study of the Stanley-Zanello asymptotic lower bound for $\log(O_d)$ is also carried out. Some consequent prediction estimates are proposed. We also show that a question posed by L. G. Roberts in 1992 has a negative answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. Exploiting an iterative formula from a prior manuscript, the paper proves that the sequence (A_{d+2})_{d≥1} is sub-Fibonacci (extending a similar result for O_d), develops an algorithm to compute the number O_d of finite O-sequences up to multiplicity d=1100, uses the resulting data to empirically calibrate the Stanley-Zanello asymptotic upper and lower bounds on log(O_d) in the range 1≤d≤1100, proposes consequent prediction estimates, and exhibits a counterexample showing that a 1992 question of L. G. Roberts has a negative answer.
Significance. If the iterative formula is correct and the enumeration accurate, the work supplies a new sub-Fibonacci result, a substantial computational dataset enabling refined empirical calibration of known asymptotic bounds, and a resolution of an open question. The scale of the computation (up to d=1100) is a concrete strength that grounds the calibration exercise.
major comments (3)
- [Abstract and proof of sub-Fibonacci behaviour] The proof that (A_{d+2})_{d≥1} is sub-Fibonacci and the counterexample to Roberts' 1992 question both rest on the iterative formula introduced in the previous manuscript. No re-derivation of the formula, no explicit small-d cross-checks against independent enumerations, and no verification that the algorithm produces neither omissions nor duplicates appear in the present text; these omissions are load-bearing for both the sub-Fibonacci claim and the claimed counterexample.
- [Calibration of Stanley-Zanello bounds and prediction estimates] The empirical calibration of the Stanley-Zanello upper and lower bounds for log(O_d) is performed by post-hoc fitting to the computed values up to d=1100; the prediction estimates for d>1100 are obtained by extrapolating the same fitted parameters. This procedure renders the forecasts dependent on the observed data rather than independent, and the manuscript supplies neither error analysis nor cross-validation of the fitting procedure.
- [Algorithm and computational results] The algorithm that enumerates all finite O-sequences up to d=1100 is derived directly from the prior iterative formula. Without reported independent verification for small d (e.g., matching known values of O_d for d≤20) or a complexity/termination argument, it is impossible to assess whether the tabulated counts are complete and duplication-free, which directly affects the reliability of the calibrated bounds and the counterexample.
minor comments (2)
- [Introduction and references] The previous manuscript containing the iterative formula is referenced only generically; a full bibliographic citation with title, authors, and arXiv identifier (if applicable) should be supplied in the introduction and references section.
- [Abstract] The precise definition of the sequence A_d (finite O-sequences whose last non-zero element is strictly larger than 1) is used throughout but is not restated in the abstract; a one-sentence reminder would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation of major revision. The comments highlight important points regarding the reliance on prior work, the need for verification, and the empirical nature of the calibration. We address each major comment below and propose targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and proof of sub-Fibonacci behaviour] The proof that (A_{d+2})_{d≥1} is sub-Fibonacci and the counterexample to Roberts' 1992 question both rest on the iterative formula introduced in the previous manuscript. No re-derivation of the formula, no explicit small-d cross-checks against independent enumerations, and no verification that the algorithm produces neither omissions nor duplicates appear in the present text; these omissions are load-bearing for both the sub-Fibonacci claim and the claimed counterexample.
Authors: The iterative formula was rigorously derived and proven in our prior manuscript. In the revised version, we will include a self-contained statement of the formula together with a brief outline of its key properties. We will also add explicit small-d verifications (d ≤ 20) by comparing our computed O_d and A_d values against any independently known enumerations or direct manual counts for small multiplicities. For the algorithm, we will insert a dedicated subsection arguing correctness, termination (via the finite support of O-sequences), and absence of omissions/duplicates based on the recursive structure. These additions will make the sub-Fibonacci proof and the counterexample to Roberts' question more self-contained while still referencing the prior derivation for full details. revision: partial
-
Referee: [Calibration of Stanley-Zanello bounds and prediction estimates] The empirical calibration of the Stanley-Zanello upper and lower bounds for log(O_d) is performed by post-hoc fitting to the computed values up to d=1100; the prediction estimates for d>1100 are obtained by extrapolating the same fitted parameters. This procedure renders the forecasts dependent on the observed data rather than independent, and the manuscript supplies neither error analysis nor cross-validation of the fitting procedure.
Authors: We agree that the calibration is inherently empirical and post-hoc. In the revision we will expand the relevant section to describe the fitting procedure in detail, report residual errors and goodness-of-fit statistics for the interval 1 ≤ d ≤ 1100, and include a cross-validation exercise (fitting on d ≤ 500 and validating on 501 ≤ d ≤ 1100). We will also explicitly discuss the limitations of extrapolation and qualify the prediction estimates accordingly, making clear that they are data-dependent forecasts rather than independent predictions. revision: yes
-
Referee: [Algorithm and computational results] The algorithm that enumerates all finite O-sequences up to d=1100 is derived directly from the prior iterative formula. Without reported independent verification for small d (e.g., matching known values of O_d for d≤20) or a complexity/termination argument, it is impossible to assess whether the tabulated counts are complete and duplication-free, which directly affects the reliability of the calibrated bounds and the counterexample.
Authors: We will augment the algorithm description with explicit comparisons of our O_d values for d ≤ 20 against any previously published or independently computed counts. In addition, we will supply a complexity analysis (showing that the recursion depth and branching are bounded by the multiplicity) and a termination argument grounded in the finite length of O-sequences. These changes will directly address concerns about completeness and duplication. revision: yes
Circularity Check
Predictions extrapolate from parameters fitted to data up to d=1100; sub-Fibonacci proof and counts depend on un-rederived iterative formula from prior manuscript
specific steps
-
self citation load bearing
[Abstract]
"Exploiting an iterative formula already introduced in a previous manuscript to count the number $O_d$ of finite $O$-sequences of multiplicity $d$, we obtain some new information about $O_d$. ... first we prove that the sequence $(A_{d+2})_{d≥1}$ is sub-Fibonacci... Then, we develop an algorithm that allows the computation of $O_d$ up to $d=1100$"
The sub-Fibonacci proof and the enumeration algorithm that supplies both the data for the Roberts counterexample and the calibration set are justified solely by citation to the prior manuscript; no independent derivation or verification is supplied here, so the central claims are load-bearing on that self-citation.
-
fitted input called prediction
[Abstract]
"use the computed data to obtain an empirical calibration in the interval 1≤d≤1100 of the Stanley-Zanello asymptotic upper bound for log(O_d) that better fits the observed values of log(O_d) in the given interval. ... Some consequent prediction estimates are proposed."
Parameters of the asymptotic bound are fitted to the O_d values computed up to d=1100; the subsequent 'prediction estimates' are therefore direct extrapolations from that fit and reduce to the input data by construction.
full rationale
The paper's core contributions—the sub-Fibonacci proof for (A_{d+2}), the O_d counts up to 1100, the negative answer to Roberts' question, and the proposed predictions—all rest on an iterative formula introduced only in a previous manuscript. The algorithm is built directly from that formula to generate the data, which is then used both to prove the inequality and to empirically calibrate the Stanley-Zanello bounds. Because the calibration step fits parameters to exactly those computed values and then extrapolates, the 'prediction estimates' are statistically forced by the fit rather than independent. No re-derivation of the formula, no small-d cross-check against independent enumerations, and no external validation appear in the present text, so the load-bearing steps reduce to acceptance of the prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration constants in Stanley-Zanello bounds =
determined from computed data
axioms (1)
- domain assumption The iterative formula from the previous manuscript correctly generates all finite O-sequences of multiplicity d
Reference graph
Works this paper leans on
-
[1]
Abbott, A
J. Abbott, A. M. Bigatti, and L. Robbiano, CoCoA : a system for doing C omputations in C ommutative A lgebra , Available at http://cocoa.dima.unige.it
-
[2]
Ceria, Bar code for monomial ideals, J
M. Ceria, Bar code for monomial ideals, J. Symbolic Comput. 91 (2019), 30--56
2019
-
[3]
Counting finite $O$-sequences of a given multiplicity
F. Cioffi, M. Guida, Counting finite O -sequences of a given multiplicity, (2025), available at https://arxiv.org/pdf/2507.23438
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Enkosky and B
T. Enkosky and B. Stone, A sequence defined by M -sequences , Discrete Math. 333 (2014), 35--38
2014
-
[5]
P. C. Fishburn and F. S. Roberts, Elementary sequences, sub- F ibonacci sequences , Discrete Appl. Math. 44 (1993), no. 1-3, 261--281
1993
-
[6]
G. H. Hardy and S. Ramanujan, Asymptotic Formulae in Combinatory Analysis, Proceedings of London Math. Soc., 2, XVII, 1918, 75--115
1918
-
[7]
Hartshorne, Connectedness of the H ilbert scheme , Inst
R. Hartshorne, Connectedness of the H ilbert scheme , Inst. Hautes \'Etudes Sci. Publ. Math. (1966), no. 29, 5--48
1966
-
[8]
Linusson, The number of M -sequences and f -vectors , Combinatorica 19 (1999), no
S. Linusson, The number of M -sequences and f -vectors , Combinatorica 19 (1999), no. 2, 255--266
1999
-
[9]
F. S. Macaulay, Some properties of enumeration in the theory of modular systems, Proc. London Math. Soc. (1926), no. 26, 531--555
1926
-
[10]
L. G. Roberts, Open problems, problem (6), Zero-dimensional schemes ( R avello, 1992), de Gruyter, Berlin, 1994, p. 330
1992
-
[11]
R. P. Stanley and F. Zanello, A note on the asymptotics of the number of O -sequences of given length , Discrete Math. 342 (2019), no. 7, 2033--2034
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.