Recognition: unknown
LLM-PRISM: Characterizing Silent Data Corruption from Permanent GPU Faults in LLM Training
Pith reviewed 2026-05-10 16:37 UTC · model grok-4.3
The pith
LLM pre-training resists low-frequency GPU faults but can diverge catastrophically from faults in critical datapaths or certain numeric formats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that while LLMs resist low-frequency faults, impact is highly non-uniform; critical datapaths and specific precision formats can induce catastrophic divergence even at moderate fault rates. This is shown through 7,664 training runs that map fault type, rate, and numeric format to training outcomes, providing the first hardware-grounded characterization of silent data corruption resilience during LLM pre-training.
What carries the argument
LLM-PRISM methodology that couples RTL-level GPU fault simulation with a stochastic injection engine embedded in Megatron-LM
If this is right
- LLMs can complete pre-training under low-frequency permanent GPU faults without divergence in most cases.
- Faults in specific datapaths produce far larger training disruptions than faults elsewhere at the same rate.
- Different numeric formats (FP16, BF16, FP8) exhibit distinct resilience thresholds to the same fault patterns.
- Moderate fault rates become training-ending once they affect critical circuit paths or higher-precision representations.
Where Pith is reading between the lines
- Training schedulers could monitor gradient statistics to flag and isolate suspected hardware faults before full divergence occurs.
- Hardware vendors might add targeted redundancy or error correction only to the datapaths identified as most sensitive.
- Longer or larger-scale training runs would likely amplify the non-uniform effects, making early fault characterization more valuable.
- Alternative numeric formats or mixed-precision strategies could be tested as a low-cost way to increase overall resilience.
Load-bearing premise
The RTL-level GPU fault simulation combined with the stochastic injection engine inside Megatron-LM accurately represents the behavior of real permanent silicon defects that occur in production GPU hardware during LLM pre-training.
What would settle it
Running identical LLM pre-training workloads on actual production GPUs known to contain permanent defects and checking whether the observed divergence patterns match the simulated non-uniform impacts across the same fault locations and precision formats.
Figures








read the original abstract
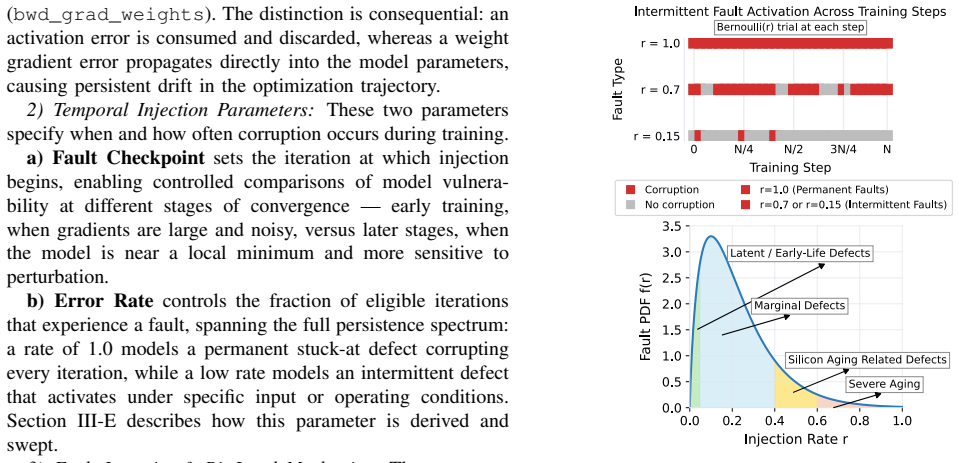
Large-scale LLM training is increasingly susceptible to hardware defects stemming from manufacturing escapes and silicon aging. These defects manifest as Silent Data Corruption (SDC) that perturb gradients and parameters throughout the training process. We present LLM-PRISM, a methodology to characterize LLM pre-training resilience to hardware faults. LLM-PRISM couples RTL-level GPU fault simulation with a stochastic injection engine embedded in Megatron-LM. Through 7,664 training runs across FP16, BF16, and FP8 regimes, we analyze how fault type, rate, and numeric format govern resilience. We find that while LLMs resist low-frequency faults, impact is highly non-uniform; critical datapaths and specific precision formats can induce catastrophic divergence even at moderate fault rates. This study provides the first hardware-grounded, pre-training characterization of SDC resilience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLM-PRISM, a methodology coupling RTL-level GPU fault simulation with a stochastic injection engine inside Megatron-LM. It reports results from 7,664 training runs across FP16, BF16, and FP8 regimes to characterize how fault type, rate, and numeric format affect Silent Data Corruption (SDC) resilience during LLM pre-training. The central finding is that LLMs resist low-frequency faults but exhibit highly non-uniform sensitivity, with critical datapaths and certain precision formats able to trigger catastrophic divergence even at moderate fault rates. This is presented as the first hardware-grounded pre-training characterization of SDC resilience.
Significance. If the fault model holds, the work supplies the first large-scale empirical map of permanent-fault SDC effects on LLM training, highlighting non-uniform risks that could inform both hardware reliability features and training-system mitigations. The scale of the experimental campaign (7,664 runs) and the focus on permanent rather than transient faults are clear strengths relative to prior simulation-only studies.
major comments (2)
- [Abstract and methodology] Abstract and methodology description: The headline claim of highly non-uniform impact and catastrophic divergence at moderate fault rates rests on the premise that the RTL-level GPU fault model plus stochastic injection engine produces SDC behavior indistinguishable from actual permanent silicon defects. No calibration data, comparison against measured SDC from real faulty GPUs, or sensitivity analysis to injection-site assumptions is supplied, which is load-bearing for all resilience conclusions.
- [Results] Results and evaluation: The abstract states 'clear trends' across 7,664 runs and three formats, yet no error-bar details, statistical significance tests, or variance measures are referenced. Without these, the non-uniformity claim and cross-format comparisons cannot be rigorously assessed.
minor comments (1)
- [Abstract] The abstract could more explicitly qualify the scope of the fault model (e.g., fixed-location bit-flip patterns, ECC interactions) to help readers interpret the reported resilience numbers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and note planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and methodology] Abstract and methodology description: The headline claim of highly non-uniform impact and catastrophic divergence at moderate fault rates rests on the premise that the RTL-level GPU fault model plus stochastic injection engine produces SDC behavior indistinguishable from actual permanent silicon defects. No calibration data, comparison against measured SDC from real faulty GPUs, or sensitivity analysis to injection-site assumptions is supplied, which is load-bearing for all resilience conclusions.
Authors: We agree that direct calibration against measured SDC from real faulty GPUs would provide the strongest possible grounding. However, permanent faults are rare in production silicon, and researchers lack access to defective GPUs for controlled SDC measurements. Our RTL-level model is derived from the detailed microarchitecture of the target GPU and injects faults at the precise bit and datapath level that permanent defects would affect. This methodology is standard in hardware reliability research when real-silicon data cannot be obtained. To strengthen the work, we will add a sensitivity analysis in the revised manuscript that varies injection sites and reports the resulting changes in training outcomes. We believe the reported non-uniform sensitivity remains valid under the modeled permanent-fault behaviors. revision: partial
-
Referee: [Results] Results and evaluation: The abstract states 'clear trends' across 7,664 runs and three formats, yet no error-bar details, statistical significance tests, or variance measures are referenced. Without these, the non-uniformity claim and cross-format comparisons cannot be rigorously assessed.
Authors: We accept that the results section would benefit from explicit statistical support. Although multiple random seeds were used for key configurations to capture run-to-run variability, these details and associated variance measures were not reported. In the revision we will add error bars (standard deviation across repeated runs), report variance for the main metrics, and include statistical significance tests (e.g., paired t-tests or ANOVA) for the cross-format comparisons and the non-uniformity observations. This will allow readers to assess the strength of the reported trends quantitatively. revision: yes
- Direct empirical calibration of the fault model against measured SDC rates from actual permanent GPU defects, which would require access to defective production hardware that is not available.
Circularity Check
Empirical characterization via simulation runs; no derivation chain present
full rationale
The manuscript describes an empirical study that couples RTL-level GPU fault simulation with a stochastic injection engine inside Megatron-LM, then executes 7,664 training runs across FP16/BF16/FP8 to observe SDC effects. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All reported findings (non-uniform impact, format-dependent divergence) are direct outputs of the simulation campaign rather than reductions of prior results to themselves. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RTL-level fault models accurately capture permanent GPU defects that manifest as silent data corruption during training
Reference graph
Works this paper leans on
-
[2]
Silent data corruptions at scale
H. D. Dixit, S. Pendharkar, M. Beadon, C. Mason, T. Chakravarthy, B. Muthiah, and S. Sankar, “Silent data corruptions at scale,” arXiv preprint arXiv:2102.11245, February 2021. DOI: 10.48550/arXiv.2102.11245
-
[3]
P. H. Hochschild, P. Turner, J. C. Mogul, R. Govindaraju, P. Ran- ganathan, D. E. Culler, and A. Vahdat, “Cores that don’t count,” (New York, NY , USA), Association for Computing Machinery, 2021. DOI: 10.1145/3458336.3465297
-
[4]
Bagpipe: Accelerating deep recommendation model training,
S. Wang, G. Zhang, J. Wei, Y . Wang, J. Wu, and Q. Luo, “Understanding silent data corruptions in a large production CPU population,” inPro- ceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), ACM, 2023. Also published as ACM Transactions on Computer Systems (TOCS), 2024; DOI: 10.1145/3600006.3613149
-
[5]
N. George, S. Gurumurthi, V . Sridharan, H. D. Dixit, E. Goksu, B. Parthasarathy, A. Huffman, T. Macieira, A. Sinha, D. Liberty, L. Min- well, and R. S. Chappell, “ Silent Data Corruption in Artificial Intelli- gence: A Growing Challenge for Large-Scale Machine Learning ,”IEEE Micro, vol. 46, pp. 66–72, Jan. 2026. DOI: 10.1109/MM.2025.3645670
-
[6]
Demystifying the resilience of large language model infer- ence: An end-to-end perspective,
Y . Sun, Z. Coalson, S. Chen, H. Liu, Z. Zhang, S. Hong, B. Fang, and L. Yang, “Demystifying the resilience of large language model infer- ence: An end-to-end perspective,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1127–1144, 2025. DOI: 10.1145/3712285.3759803
-
[7]
Exploring and mitigating failure behavior of large language model training workloads in hpc systems,
P. Yu, J. Gu, H. Han, D. Shen, B. Wen, and Y . Liu, “Exploring and mitigating failure behavior of large language model training workloads in hpc systems,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1165– 1179, 2025. DOI: 10.1145/3712285.3759893
-
[8]
A. Tyagi, R. Jeyapaul, C. Zhou, P. Whatmough, and Y . Zhu, “Character- izing soft-error resiliency in arm’s ethos-u55 embedded machine learning accelerator,” in2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pp. 96–108, IEEE, 2024. DOI: 10.1109/ISPASS61541.2024.00017
-
[9]
Silent data corruption by 10× test escapes threatens reliable comput- ing,
S. Mitra, S. S. Banerjee, M. Dixon, M. Fuller, R. Govindaraju, P. Hochschild, E. X. Liu, B. Parthasarathy, and P. Ranganathan, “Silent data corruption by 10× test escapes threatens reliable comput- ing,”IEEE Design & Test, vol. 42, no. 6, pp. 40–53, 2025. DOI: 10.1109/MDAT.2025.3602741
-
[10]
The adventure of the errant hardware
E. Elsen, C. Hawthorne, and A. Somani, “The adventure of the errant hardware.” Adept AI Blog, September 2023
2023
-
[11]
Llama Team, AI @ Meta, “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, July 2024. DOI: 10.48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[12]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google, “Gemini: A family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, December 2023. DOI: 10.48550/arXiv.2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[13]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, 2019. DOI: 10.48550/arXiv.1909.08053
work page internal anchor Pith review doi:10.48550/arxiv.1909.08053 1909
-
[14]
T. Grasser, B. Kaczer, W. Goes, H. Reisinger, T. Aichinger, P. Hehen- berger, P.-J. Wagner, F. Schanovsky, J. Franco, M. T. T. Luque,et al., “The paradigm shift in understanding the bias temperature instability: From reaction–diffusion to switching oxide traps,”IEEE Transactions on Electron Devices, vol. 58, no. 11, pp. 3652–3666, 2011. DOI: 10.1109/TED.2...
-
[15]
Hot-electron-induced mosfet degradation-model, monitor, and improvement,
C. Hu, S. C. Tam, F.-C. Hsu, P.-K. Ko, T.-Y . Chan, and K. W. Terrill, “Hot-electron-induced mosfet degradation-model, monitor, and improvement,”IEEE Journal of Solid-State Circuits, vol. 20, no. 1, pp. 295–305, 1985. DOI: 10.1109/T-ED.1985.21952
-
[16]
R. Degraeve, G. Groeseneken, R. Bellens, J.-L. Ogier, M. Depas, P. J. Roussel, and H. E. Maes, “New insights in the relation between electron trap generation and the statistical properties of oxide breakdown,”IEEE Transactions on Electron Devices, vol. 45, no. 4, pp. 904–911, 1998. DOI: 10.1109/16.662800
-
[17]
Electromigration—a brief survey and some recent results,
J. R. Black, “Electromigration—a brief survey and some recent results,” IEEE Transactions on Electron Devices, vol. 16, no. 4, pp. 338–347,
-
[18]
DOI: 10.1109/T-ED.1969.16754
-
[19]
Characterizing modern gpu resilience and impact in hpc systems: A case study of a100 gpus,
S. Cui, A. Patke, Z. Chen, A. Ranjan, H. Nguyen, P. Cao, B. Bode, G. Bauer, S. Jha, C. Narayanaswami,et al., “Characterizing modern gpu resilience and impact in hpc systems: A case study of a100 gpus,” in 2025 55th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W), pp. 1–6, IEEE, 2025
2025
-
[20]
Understanding silent data corruption in llm training,
J. J. Ma, H. Pei, L. Lausen, and G. Karypis, “Understanding silent data corruption in llm training,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 20372–20394, 2025. DOI: 10.18653/v1/2025.acl-long.996
-
[21]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Y . Chen, Z. Tan, A. K. Jaiswal, H. Qu, X. Zhao, Q. Lin, Y . Cheng, A. Kwong, Z. Cao, and T. Chen, “Bit-flip error resilience in llms: A comprehensive analysis and defense framework,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 10425–10435, 2025. DOI: 10.18653/v1/2025.emnlp- main.52
-
[22]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever,et al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[23]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sen- tinel mixture models,”arXiv preprint arXiv:1609.07843, 2016. DOI: 10.48550/arXiv.1609.07843
work page internal anchor Pith review doi:10.48550/arxiv.1609.07843 2016
-
[24]
A Study of BFLOAT16 for Deep Learning Training
D. Kalamkar, D. Mudigere, N. Mellempudi, D. Das, K. Banerjee, S. Avancha, D. T. V ooturi, N. Jammalamadaka, J. Huang, H. Yuen, et al., “A study of bfloat16 for deep learning training,”arXiv preprint arXiv:1905.12322, 2019. DOI: 10.48550/arXiv.1905.12322
-
[25]
Deepcoder: A fully open-source 14b coder at o3-mini level
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisen- thwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu,et al., “Fp8 formats for deep learning,”arXiv preprint arXiv:2209.05433, 2022. DOI: 10.48550/arXiv.2209.05433
-
[26]
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,”Advances in neural information processing systems, vol. 35, pp. 30318–30332, 2022. DOI: 10.5555/3600270.3602468
-
[27]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh,et al., “Mixed precision training,”arXiv preprint arXiv:1710.03740, 2017. DOI: 10.48550/arXiv.1710.03740
work page internal anchor Pith review doi:10.48550/arxiv.1710.03740 2017
-
[28]
Language model evaluation beyond per- plexity,
C. Meister and R. Cotterell, “Language model evaluation beyond per- plexity,” inProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pp. 5328–5339,
-
[29]
DOI: 10.48550/arXiv.2106.00085
-
[30]
doi:10.5281/zenodo.10256836 , url =
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muen- nighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “A framework for few-shot language model evaluation,” 12 2023. DOI: 10.5281/zenodo.10256836
-
[31]
F. Hill, A. Bordes, S. Chopra, and J. Weston, “The goldilocks principle: Reading children’s books with explicit memory representations,”arXiv preprint arXiv:1511.02301, 2015. DOI: 10.48550/arXiv.1511.02301
-
[32]
The W inograd S chema C hallenge
H. Levesque, E. Davis, and L. Morgenstern, “The winograd schema challenge,” inThirteenth International Conference on the Principles of Knowledge Representation and Reasoning, Citeseer, 2012. DOI: 10.5555/3031843.3031909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.