Recognition: unknown
LASQ: A Low-resource Aspect-based Sentiment Quadruple Extraction Dataset
Pith reviewed 2026-05-10 16:29 UTC · model grok-4.3
The pith
A new dataset and syntax-enhanced model support quadruple sentiment extraction in Uzbek and Uyghur.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
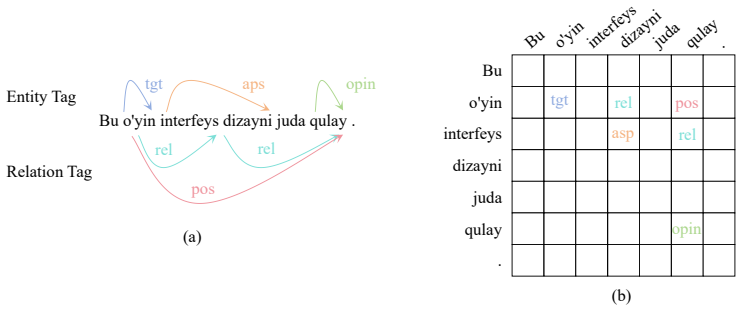
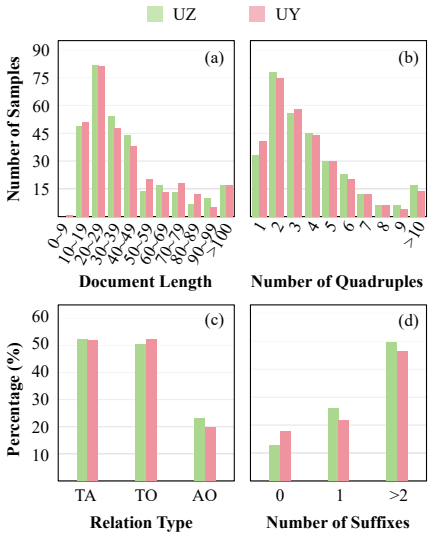
We construct LASQ, the first Low-resource Aspect-based Sentiment Quadruple dataset for Uzbek and Uyghur, and introduce a grid-tagging model with a Syntax Knowledge Embedding Module that incorporates part-of-speech and dependency knowledge. This design alleviates lexical sparsity in agglutinative languages. Experiments on LASQ demonstrate consistent gains over competitive baselines, validating the dataset's utility and the modeling approach.
What carries the argument
The Syntax Knowledge Embedding Module that integrates part-of-speech and dependency knowledge into a grid-tagging model for target-aspect-opinion-sentiment extraction.
If this is right
- The LASQ dataset supplies the first public benchmark for quadruple extraction in Uzbek and Uyghur.
- Syntactic embeddings help models manage data scarcity and morphological complexity in low-resource settings.
- Quadruple extraction yields more detailed sentiment information than prior pair or triplet tasks.
- The dataset construction and evaluation process can guide similar efforts for other low-resource languages.
Where Pith is reading between the lines
- The same syntactic module could transfer to other agglutinative low-resource languages to reduce annotation needs.
- LASQ may expose language-specific sentiment patterns that differ from high-resource language benchmarks.
- Pairing the model with cross-lingual transfer from related languages could further lift performance without new labels.
Load-bearing premise
That adding part-of-speech and dependency knowledge will specifically alleviate lexical sparsity in these agglutinative languages.
What would settle it
Training the grid-tagging model without the Syntax Knowledge Embedding Module and finding equal or better performance on the LASQ test set.
Figures





read the original abstract
In recent years, aspect-based sentiment analysis (ABSA) has made rapid progress and shown strong practical value. However, existing research and benchmarks are largely concentrated on high-resource languages, leaving fine-grained sentiment extraction in low-resource languages under-explored. To address this gap, we constructed the first Low-resource languages Aspect-based Sentiment Quadruple dataset, named LASQ, which includes two low-resource languages: Uzbek and Uyghur. Secondly, it includes a fine-grained target-aspect-opinion-sentiment quadruple extraction task. To facilitate future research, we designed a grid-tagging model that integrates syntactic knowledge. This model incorporates part-of-speech (POS) and dependency knowledge into the model through our designed Syntax Knowledge Embedding Module (SKEM), thereby alleviating the lexical sparsity problem caused by agglutinative languages. Experiments on LASQ demonstrate consistent gains over competitive baselines, validating both the dataset's utility and the effectiveness of the proposed modeling approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LASQ, the first dataset for fine-grained aspect-based sentiment quadruple extraction (target-aspect-opinion-sentiment) covering the low-resource agglutinative languages Uzbek and Uyghur. It also proposes a grid-tagging architecture augmented by a Syntax Knowledge Embedding Module (SKEM) that injects POS tags and dependency relations to mitigate lexical sparsity. The central claim is that experiments on LASQ yield consistent gains over competitive baselines, thereby validating both the utility of the new dataset and the effectiveness of the SKEM-augmented modeling approach.
Significance. If the dataset is of sufficient scale and quality and the reported gains are reproducible, the work would meaningfully extend ABSA research beyond high-resource languages. The quadruple extraction formulation and the explicit incorporation of syntactic knowledge for agglutinative morphology address a documented gap. The empirical comparison to external baselines constitutes a concrete strength; however, the absence of internal controls limits the strength of the causal claim about SKEM.
major comments (2)
- [Experiments] Experiments section: the manuscript reports consistent gains over competitive baselines but provides no ablation that isolates SKEM (i.e., full model versus identical grid-tagging architecture with SKEM removed). Without this internal comparison, observed improvements cannot be attributed to the syntactic embeddings rather than other modeling choices, undermining the claim that the proposed approach is validated.
- [Model] Model section (SKEM description): the assertion that POS and dependency knowledge 'alleviate the lexical sparsity problem caused by agglutinative languages' is presented without supporting evidence such as error analysis, morphological breakdown, or quantitative comparison of sparsity metrics before and after SKEM injection.
minor comments (2)
- [Abstract] Abstract and introduction: quantitative dataset statistics (number of sentences, quadruples, train/dev/test splits) and key experimental metrics (F1 scores, exact numbers of baselines) are not summarized, making it difficult for readers to assess scale and effect size at a glance.
- [Dataset] Dataset construction: the description of the annotation protocol, inter-annotator agreement, and quality-control steps for the quadruple labels should be expanded with concrete figures if not already present.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical support in our work. We address the major comments point by point below and commit to revisions that enhance the manuscript's rigor without misrepresenting our current results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the manuscript reports consistent gains over competitive baselines but provides no ablation that isolates SKEM (i.e., full model versus identical grid-tagging architecture with SKEM removed). Without this internal comparison, observed improvements cannot be attributed to the syntactic embeddings rather than other modeling choices, undermining the claim that the proposed approach is validated.
Authors: We agree that the absence of an internal ablation study limits the strength of the causal attribution to SKEM. The current experiments focus on comparisons with external competitive baselines, but do not include a direct head-to-head evaluation against the grid-tagging architecture with SKEM removed. In the revised manuscript, we will add this ablation, reporting performance metrics for both the full model and the SKEM-ablated variant on the LASQ dataset for Uzbek and Uyghur. This will allow readers to isolate the contribution of the Syntax Knowledge Embedding Module. revision: yes
-
Referee: [Model] Model section (SKEM description): the assertion that POS and dependency knowledge 'alleviate the lexical sparsity problem caused by agglutinative languages' is presented without supporting evidence such as error analysis, morphological breakdown, or quantitative comparison of sparsity metrics before and after SKEM injection.
Authors: We acknowledge that the manuscript states this benefit of SKEM without direct supporting analysis. To address the concern, the revised version will include a dedicated error analysis subsection. This will provide qualitative examples illustrating how POS tags and dependency relations help resolve ambiguities in agglutinative structures, along with any feasible quantitative metrics (such as error rates on morphologically complex tokens). If the analysis does not fully substantiate the claim, we will qualify the language accordingly. revision: yes
Circularity Check
No circularity: empirical claims rest on new dataset construction and baseline comparisons
full rationale
The paper introduces the LASQ dataset for Uzbek and Uyghur and proposes a grid-tagging model incorporating SKEM for syntactic knowledge. Central claims of dataset utility and modeling effectiveness are supported solely by experimental results showing gains over external baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The assertion that SKEM alleviates lexical sparsity is presented as a design motivation rather than a proven reduction; validation remains external to any self-referential loop. This is a standard data-and-model empirical paper with self-contained content against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the AAAI Conference on Artificial Intelligence, vol
Yang, J., Yang, R., Wang, C., Xie, J.: Multi-entity aspect-based sentiment analysis with context, entity and aspect memory. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32 (2018)
2018
-
[2]
In: Proceedings of the AAAI Conference on 22 Artificial Intelligence, vol
Li, X., Bing, L., Li, P., Lam, W.: A unified model for opinion target extraction and target sentiment prediction. In: Proceedings of the AAAI Conference on 22 Artificial Intelligence, vol. 33, pp. 6714–6721 (2019)
2019
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence, vol
Peng, H., Xu, L., Bing, L., Huang, F., Lu, W., Si, L.: Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 8600–8607 (2020)
2020
-
[4]
Jiang, Q., Chen, L., Xu, R., Ao, X., Yang, M.: A challenge dataset and effective models for aspect-based sentiment analysis. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 6280– 6285 (2019)
2019
-
[5]
Cai, H., Xia, R., Yu, J.: Aspect-category-opinion-sentiment quadruple extraction with implicit aspects and opinions. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 340–350 (2021)
2021
-
[6]
In: Findings of the Association for Computational Linguistics: ACL 2023, pp
Li, B., Fei, H., Li, F., Wu, Y., Zhang, J., Wu, S., Li, J., Liu, Y., Liao, L., Chua, T.-S.,et al.: Diaasq: A benchmark of conversational aspect-based sentiment quadruple analysis. In: Findings of the Association for Computational Linguistics: ACL 2023, pp. 13449–13467 (2023)
2023
-
[7]
In: Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages@ LREC- COLING 2024, pp
Matlatipov, S.G., Rajabov, J., Kuriyozov, E., Aripov, M.: Uzabsa: Aspect-based sentiment analysis for the uzbek language. In: Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages@ LREC- COLING 2024, pp. 394–403 (2024)
2024
-
[8]
Van Thin, D., Hao, D.N., Nguyen, N.L.-T.: A systematic literature review on vietnamese aspect-based sentiment analysis. ACM Trans. Asian Low-Resour. Lang. Inf. Process.22(8) (2023) https://doi.org/10.1145/3610226
-
[9]
In: Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., Piperidis, S
Regatte, Y.R., Gangula, R.R.R., Mamidi, R.: Dataset creation and evaluation of aspect based sentiment analysis in Telugu, a low resource language. In: Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., Piperidis, S. (eds.) Proceedings of the Twelf...
2020
-
[10]
Aziz, K., Yusufu, A., Zhou, J., Ji, D., Iqbal, M.S., Wang, S., Hadi, H.J., Yuan, Z.: Urduaspectnet: Fusing transformers and dual gcn for urdu aspect-based sentiment detection. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (2024) https://doi.org/10.1145/3663367 . Just Accepted
-
[11]
In: 23 Proceedings of the ACM on Web Conference 2024, pp
Zhou, C., Wu, Z., Song, D., Hu, L., Tian, Y., Xu, J.: Span-pair interaction and tagging for dialogue-level aspect-based sentiment quadruple analysis. In: 23 Proceedings of the ACM on Web Conference 2024, pp. 3995–4005 (2024)
2024
-
[12]
Xu, L., Chia, Y.K., Bing, L.: Learning span-level interactions for aspect sentiment triplet extraction. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 4755–4766 (2021)
2021
-
[13]
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp
Zhang, W., Deng, Y., Li, X., Yuan, Y., Bing, L., Lam, W.: Aspect sentiment quad prediction as paraphrase generation. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 9209–9219 (2021)
2021
-
[14]
In: Ku, L.-W., Martins, A., Srikumar, V
Ma, T., Wang, Z., Zhou, G.: Transition-based opinion generation for aspect-based sentiment analysis. In: Ku, L.-W., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics: ACL 2024, pp. 3078–3087. Association for Computational Linguistics, Bangkok, Thailand (2024). https://doi.org/10. 18653/v1/2024.findings-acl.182 .htt...
2024
-
[15]
In: Ku, L.-W., Martins, A., Srikumar, V
Kim, J., Heo, R., Seo, Y., Kang, S., Yeo, J., Lee, D.: Self-consistent reasoning-based aspect-sentiment quad prediction with extract-then-assign strategy. In: Ku, L.-W., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics: ACL 2024, pp. 7295–7303. Association for Computational Linguistics, Bangkok, Thailand (2024). h...
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence, vol
Li, B., Fei, H., Liao, L., Zhao, Y., Su, F., Li, F., Ji, D.: Harnessing holistic discourse features and triadic interaction for sentiment quadruple extraction in dialogues. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 18462–18470 (2024)
2024
-
[17]
In: Beermann, D., Besacier, L., Sakti, S., Soria, C
Abulimiti, A., Schultz, T.: Building language models for morphological rich low- resource languages using data from related donor languages: the case of Uyghur. In: Beermann, D., Besacier, L., Sakti, S., Soria, C. (eds.) Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-resourced Lan- guages (SLTU) and Collaboration and Compu...
2020
-
[18]
In: Krauwer, S., Moortgat, M., Tombe, L
Oflazer, K.: Two-level description of Turkish morphology. In: Krauwer, S., Moortgat, M., Tombe, L. (eds.) Sixth Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Utrecht, The Netherlands (1993).https://aclanthology.org/E93-1066/
1993
-
[19]
(eds.) Proceedings of the 31st International 24 Conference on Computational Linguistics, pp
Arnett, C., Bergen, B.: Why do language models perform worse for morphologi- cally complex languages? In: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S. (eds.) Proceedings of the 31st International 24 Conference on Computational Linguistics, pp. 6607–6623. Association for Compu- tational Linguistics, Abu Dhabi, UAE (...
2025
-
[20]
Cambridge university press, ??? (2020)
Liu, B.: Sentiment Analysis: Mining Opinions, Sentiments, and Emotions. Cambridge university press, ??? (2020)
2020
-
[21]
Artificial Intelligence Review53(6), 4335–4385 (2020)
Yadav, A., Vishwakarma, D.K.: Sentiment analysis using deep learning architec- tures: a review. Artificial Intelligence Review53(6), 4335–4385 (2020)
2020
-
[22]
Pearce, K., Alghowinem, S., Breazeal, C.: Build-a-bot: teaching conversational ai using a transformer-based intent recognition and question answering architecture. In: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Ed...
-
[23]
Computers in Human Behavior129, 107122 (2022)
Benke, I., Gnewuch, U., Maedche, A.: Understanding the impact of control levels over emotion-aware chatbots. Computers in Human Behavior129, 107122 (2022)
2022
-
[24]
Electronic commerce research23(1), 279–314 (2023)
Karn, A.L., Karna, R.K., Kondamudi, B.R., Bagale, G., Pustokhin, D.A., Pustokhina, I.V., Sengan, S.: Retracted article: Customer centric hybrid recom- mendation system for e-commerce applications by integrating hybrid sentiment analysis. Electronic commerce research23(1), 279–314 (2023)
2023
-
[25]
Expert Systems with Applications 140, 112871 (2020)
Da’u, A., Salim, N., Rabiu, I., Osman, A.: Weighted aspect-based opinion mining using deep learning for recommender system. Expert Systems with Applications 140, 112871 (2020)
2020
-
[26]
In: Findings of the Association for Computational Linguistics: EMNLP 2021, pp
Yu, G., Li, J., Luo, L., Meng, Y., Ao, X., He, Q.: Self question-answering: Aspect- based sentiment analysis by role flipped machine reading comprehension. In: Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 1331–1342 (2021)
2021
-
[27]
Frontiers of Computer Science 18(5), 185321 (2024)
Sun, R., Tao, H., Chen, Y., Liu, Q.: Hacan: a hierarchical answer-aware and context-aware network for question generation. Frontiers of Computer Science 18(5), 185321 (2024)
2024
-
[28]
In: Matsumoto, Y., Prasad, R
Tang, D., Qin, B., Feng, X., Liu, T.: Effective LSTMs for target-dependent sentiment classification. In: Matsumoto, Y., Prasad, R. (eds.) Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pp. 3298–3307. The COLING 2016 Organizing Committee, Osaka, Japan (2016).https://aclanthology.org/C16-1311
2016
-
[29]
Computer Science Review49, 25 100576 (2023)
Chauhan, G.S., Nahta, R., Meena, Y.K., Gopalani, D.: Aspect based sentiment analysis using deep learning approaches: A survey. Computer Science Review49, 25 100576 (2023)
2023
-
[30]
PeerJ Computer Science8, 1044 (2022)
Zhu, L., Xu, M., Bao, Y., Xu, Y., Kong, X.: Deep learning for aspect-based sentiment analysis: a review. PeerJ Computer Science8, 1044 (2022)
2022
-
[31]
European Journal of Operational Research265(3), 993–1004 (2018)
Ghaddar, B., Naoum-Sawaya, J.: High dimensional data classification and fea- ture selection using support vector machines. European Journal of Operational Research265(3), 993–1004 (2018)
2018
-
[32]
In: Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, pp
Riloff, E., Wiebe, J.: Learning extraction patterns for subjective expressions. In: Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, pp. 105–112 (2003)
2003
-
[33]
In: Proceed- ings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pp
Alvarez-López, T., Juncal-Martínez, J., Fernández-Gavilanes, M., Costa- Montenegro, E., González-Castano, F.J.: Gti at semeval-2016 task 5: Svm and crf for aspect detection and unsupervised aspect-based sentiment analysis. In: Proceed- ings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pp. 306–311 (2016)
2016
-
[34]
In: 2018 5th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), pp
Mulyo, B.M., Widyantoro, D.H.: Aspect-based sentiment analysis approach with cnn. In: 2018 5th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), pp. 142–147 (2018). IEEE
2018
-
[35]
arXiv preprint arXiv:1905.07719 (2019)
Xing, B., Liao, L., Song, D., Wang, J., Zhang, F., Wang, Z., Huang, H.: Earlier attention? aspect-aware lstm for aspect-based sentiment analysis. arXiv preprint arXiv:1905.07719 (2019)
-
[36]
In: Computational Linguistics and Intelligent Text Processing: 16th International Conference, CICLing 2015, Cairo, Egypt, April 14-20, 2015, Proceedings, Part II 16, pp
Nguyen, T.H., Shirai, K.: Aspect-based sentiment analysis using tree kernel based relation extraction. In: Computational Linguistics and Intelligent Text Processing: 16th International Conference, CICLing 2015, Cairo, Egypt, April 14-20, 2015, Proceedings, Part II 16, pp. 114–125 (2015). Springer
2015
-
[37]
Sun, K., Zhang, R., Mensah, S., Mao, Y., Liu, X.: Aspect-level sentiment analysis via convolution over dependency tree. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 5679–5688 (2019)
2019
-
[38]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[40]
In: Proceedings of 26 the AAAI Conference on Artificial Intelligence, vol
Sun, Y., Wang, S., Li, Y., Feng, S., Tian, H., Wu, H., Wang, H.: Ernie 2.0: A continual pre-training framework for language understanding. In: Proceedings of 26 the AAAI Conference on Artificial Intelligence, vol. 34, pp. 8968–8975 (2020)
2020
-
[41]
Song, Y., Wang, J., Jiang, T., Liu, Z., Rao, Y.: Attentional encoder network for targeted sentiment classification. arxiv 2019. arXiv preprint arXiv:1902.09314 (2019)
-
[42]
arXiv preprint arXiv:1709.00893 (2017)
Ma, D., Li, S., Zhang, X., Wang, H.: Interactive attention networks for aspect-level sentiment classification. arXiv preprint arXiv:1709.00893 (2017)
-
[43]
Applied Intelligence 51, 3522–3533 (2021)
Liao, W., Zeng, B., Yin, X., Wei, P.: An improved aspect-category sentiment analysis model for text sentiment analysis based on roberta. Applied Intelligence 51, 3522–3533 (2021)
2021
-
[44]
Neural Networks166, 225–235 (2023)
Xiang, Y., Zhang, J., Guo, J.: Block-level dependency syntax based model for end-to-end aspect-based sentiment analysis. Neural Networks166, 225–235 (2023)
2023
-
[45]
Neurocomputing586, 127642 (2024)
Nie, Y., Fu, J., Zhang, Y., Li, C.: Modeling implicit variable and latent structure for aspect-based sentiment quadruple extraction. Neurocomputing586, 127642 (2024)
2024
-
[46]
Wu, C., Kang, H.: Harnessing syntax gcn and multi-view interaction for conversational aspect-based quadruple sentiment analysis13, 73332–73341 (2025)
2025
-
[47]
Zhang, W., Li, X., Deng, Y., Bing, L., Lam, W.: Towards generative aspect-based sentiment analysis. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pp. 504–510 (2021)
2021
-
[48]
In: 2024 IEEE International Conference on Consumer Electronics (ICCE), pp
Lee, C., Lee, H., Kim, K., Kim, S., Lee, J.: An efficient fine-tuning of generative language model for aspect-based sentiment analysis. In: 2024 IEEE International Conference on Consumer Electronics (ICCE), pp. 1–4 (2024). IEEE
2024
-
[49]
arXiv preprint arXiv:2310.18025 (2023)
Simmering, P.F., Huoviala, P.: Large language models for aspect-based sentiment analysis. arXiv preprint arXiv:2310.18025 (2023)
-
[50]
arXiv preprint arXiv:2412.02279 (2024)
Zhou, C., et al.: A comprehensive evaluation of large language models on aspect- based sentiment analysis. arXiv preprint arXiv:2412.02279 (2024)
-
[51]
In: International Journal of Advanced Information Technology, vol
Alanazi, S., Liu, X.: Leveraging large language models for aspect-based sentiment classification using gpt-4. In: International Journal of Advanced Information Technology, vol. 14 (2024)
2024
-
[52]
arXiv preprint arXiv:2505.24701 (2025)
Pandit, T., et al.: Multi-domain absa conversation dataset generation via llms for real-world evaluation and model comparison. arXiv preprint arXiv:2505.24701 (2025)
-
[53]
arXiv preprint arXiv:2503.20715 (2025)
Neveditsin, N., Lingras, P., Mago, V.: From annotation to adaptation: Metrics, synthetic data, and aspect extraction for aspect-based sentiment analysis with 27 large language models. arXiv preprint arXiv:2503.20715 (2025)
-
[54]
Azhar, A.N., Khodra, M.L.: Fine-tuning pretrained multilingual bert model for indonesian aspect-based sentiment analysis. In: 2020 7th International Conference on Advance Informatics: Concepts, Theory and Applications (ICAICTA), pp. 1–6 (2020). https://doi.org/10.1109/ICAICTA49861.2020.9428882
-
[55]
In: Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., Piperidis, S
Nivre, J., Marneffe, M.-C., Ginter, F., Hajič, J., Manning, C.D., Pyysalo, S., Schuster, S., Tyers, F., Zeman, D.: Universal Dependencies v2: An ever- growing multilingual treebank collection. In: Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J.,...
2020
-
[56]
Unifiedqa: Crossing format boundaries with a single QA system.CoRR, abs/2005.00700, 2020a
Qi, P., Zhang, Y., Zhang, Y., Bolton, J., Manning, C.D.: Stanza: A python natural language processing toolkit for many human languages. In: Celikyilmaz, A., Wen, T.-H. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 101–108. Association for Computational Linguistics, Online (2020)....
-
[57]
In: Merlo, P., Tiedemann, J., Tsarfaty, R
Bai, J., Wang, Y., Chen, Y., Yang, Y., Bai, J., Yu, J., Tong, Y.: Syntax-BERT: Improving pre-trained transformers with syntax trees. In: Merlo, P., Tiedemann, J., Tsarfaty, R. (eds.) Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 3011–3020. Association for Computational Linguis...
2021
-
[58]
In: Inui, K., Jiang, J., Ng, V., Wan, X
Zhang, C., Li, Q., Song, D.: Aspect-based sentiment classification with aspect- specific graph convolutional networks. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4568–4578...
-
[59]
In: Palmer, M., Hwa, R., Riedel, S
Marcheggiani, D., Titov, I.: Encoding sentences with graph convolutional networks for semantic role labeling. In: Palmer, M., Hwa, R., Riedel, S. (eds.) Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 1506–1515. Association for Computational Linguistics, Copenhagen, Denmark (2017). https://doi.org/10.18653/v1/D1...
-
[60]
Wu, Z., Ying, C., Zhao, F., Fan, Z., Dai, X., Xia, R.: Grid tagging scheme for aspect-oriented fine-grained opinion extraction. In: Cohn, T., He, Y., Liu, Y. (eds.) 28 Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 2576–2585. Association for Computational Linguistics, Online (2020). https://doi. org/10.18653/v1/2020.findings-em...
-
[61]
In: Muresan, S., Nakov, P., Villavicencio, A
Yuan, Z., Tan, C., Huang, S., Huang, F.: Fusing heterogeneous factors with tri- affine mechanism for nested named entity recognition. In: Muresan, S., Nakov, P., Villavicencio, A. (eds.) Findings of the Association for Computational Linguistics: ACL 2022, pp. 3174–3186. Association for Computational Linguis- tics, Dublin, Ireland (2022). https://doi.org/1...
-
[62]
In: International Conference on Learning Representations, pp
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: International Conference on Learning Representations, pp. 1–14 (2016)
2016
-
[63]
In: International Conference on Learning Representations (2022)
Dozat, T., Manning, C.D.: Deep biaffine attention for neural dependency parsing. In: International Conference on Learning Representations (2022)
2022
-
[64]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp
Zhang, Y., Li, Z., Zhang, M.: Efficient second-order treecrf for neural dependency parsing. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 3295–3305 (2020)
2020
-
[65]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
https://openai.com/index/ introducing-gpt-5/
OpenAI: Introducing GPT-5 (2025). https://openai.com/index/ introducing-gpt-5/
2025
-
[67]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, É., Ott, M., Zettlemoyer, L., Stoyanov, V.: Unsupervised cross-lingual representation learning at scale. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8440–8451 (2020)
2020
-
[68]
mt5: A massively multilingual pre-trained text-to-text transformer
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A., Raffel, C.: mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934 (2020)
-
[69]
In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (2020) 29
Qi, P., Zhang, Y., Zhang, Y., Bolton, J., Manning, C.D.: Stanza: A Python natural language processing toolkit for many human languages. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (2020) 29
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.