Recognition: unknown
EviCare: Enhancing Diagnosis Prediction with Deep Model-Guided Evidence for In-Context Reasoning
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
EviCare integrates deep model outputs into LLM prompts to better capture novel diagnoses from electronic health records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
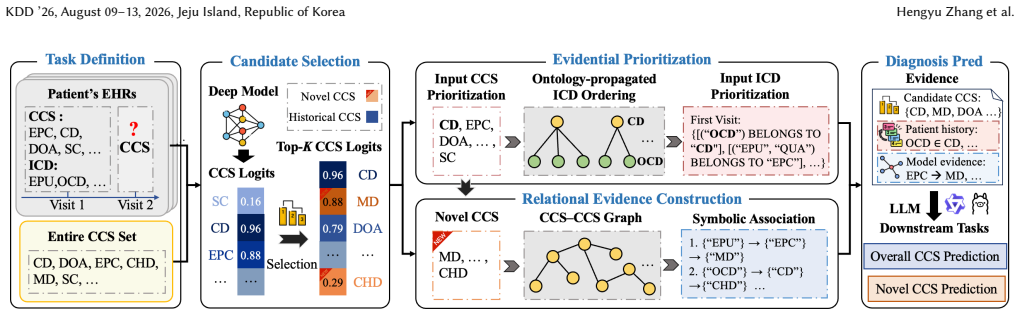
EviCare performs deep model inference for candidate selection, evidential prioritization for set-based EHRs, and relational evidence construction for novel diagnosis prediction, then composes these signals into an adaptive in-context prompt that guides LLM reasoning more accurately than direct prompting with raw inputs.
What carries the argument
The EviCare three-stage pipeline of deep model candidate selection, evidential prioritization, and relational evidence construction that feeds into adaptive LLM prompts.
If this is right
- Diagnosis prediction on EHR benchmarks shows higher precision and accuracy than either LLM-only or deep model-only baselines.
- Gains are largest for novel diagnoses that do not appear in historical training patterns.
- The evidence-based prompts make the LLM outputs more interpretable by exposing the relational links used in reasoning.
- The hybrid approach works on both MIMIC-III and MIMIC-IV datasets without task-specific retraining of the language model.
Where Pith is reading between the lines
- The same candidate-selection and evidence-construction steps could be tested on non-diagnosis tasks such as medication recommendation or risk stratification.
- Hospitals could run the deep model on their local data first to adapt the evidence pipeline before feeding prompts to any public LLM.
- If the deep model component is replaced by a simpler rule-based selector, performance on novel cases would likely drop, providing a direct test of the hybrid design.
Load-bearing premise
Deep model inference can reliably select candidate diagnoses and build relational evidence that captures clinically novel conditions without selection bias or loss of critical patient details.
What would settle it
Replace the deep model candidate selector with random selection on the MIMIC-IV benchmark and check whether the reported gains in novel diagnosis prediction disappear.
Figures


read the original abstract
Recent advances in large language models (LLMs) have enabled promising progress in diagnosis prediction from electronic health records (EHRs). However, existing LLM-based approaches tend to overfit to historically observed diagnoses, often overlooking novel yet clinically important conditions that are critical for early intervention. To address this, we propose EviCare, an in-context reasoning framework that integrates deep model guidance into LLM-based diagnosis prediction. Rather than prompting LLMs directly with raw EHR inputs, EviCare performs (1) deep model inference for candidate selection, (2) evidential prioritization for set-based EHRs, and (3) relational evidence construction for novel diagnosis prediction. These signals are then composed into an adaptive in-context prompt to guide LLM reasoning in an accurate and interpretable manner. Extensive experiments on two real-world EHR benchmarks (MIMIC-III and MIMIC-IV) demonstrate that EviCare achieves significant performance gains, which consistently outperforms both LLM-only and deep model-only baselines by an average of 20.65\% across precision and accuracy metrics. The improvements are particularly notable in challenging novel diagnosis prediction, yielding average improvements of 30.97\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EviCare, an in-context reasoning framework for diagnosis prediction from EHRs that integrates deep model guidance via three steps: (1) deep model inference for candidate selection, (2) evidential prioritization for set-based EHRs, and (3) relational evidence construction for novel diagnosis prediction. These are composed into adaptive prompts for LLMs. Experiments on MIMIC-III and MIMIC-IV report average gains of 20.65% over LLM-only and deep model-only baselines across precision and accuracy, with 30.97% average improvement in novel diagnosis prediction.
Significance. If the results hold after addressing the attribution of gains to the proposed components, the work could meaningfully advance hybrid deep model-LLM systems for clinical prediction by targeting the overfitting issue in LLMs and improving detection of novel conditions. The structured evidence construction for in-context reasoning is a clear strength if empirically validated.
major comments (2)
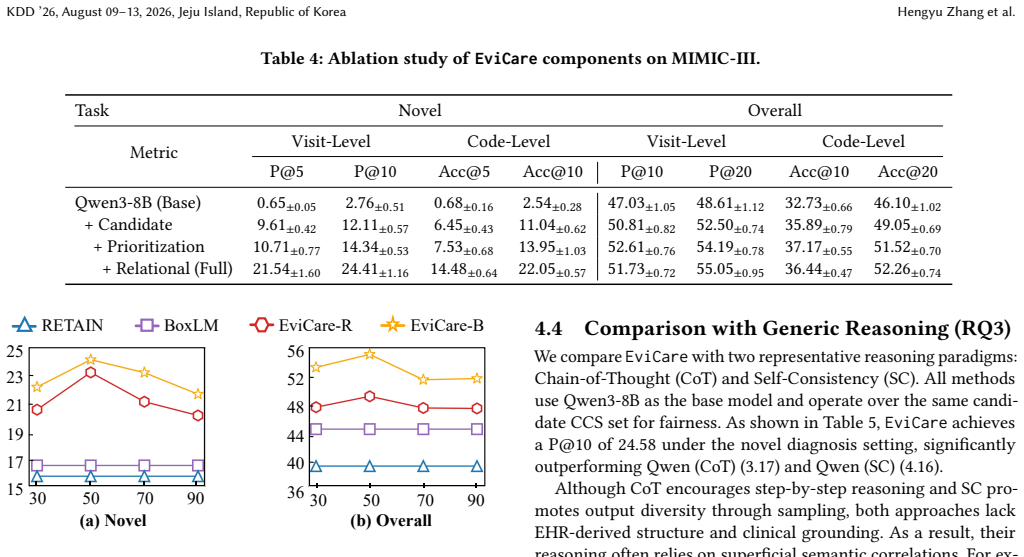
- [Methods (candidate selection step)] The pipeline description of deep model inference for candidate selection does not include any mechanism, ablation, or analysis demonstrating that the candidate set reliably surfaces novel (unseen in training) diagnoses. This is load-bearing for the 30.97% novel-prediction gain, as any such lift could otherwise be explained by prompt formatting or LLM capability alone rather than the deep-model guidance.
- [Results and Experiments] Results section and abstract report aggregate percentage gains without specifying the exact baselines (e.g., which LLMs or deep models), metric definitions, statistical significance tests, data splits, or how 'novel' diagnoses are operationalized. This prevents assessment of whether the central empirical claims are supported.
minor comments (2)
- Clarify the precise composition of the adaptive in-context prompt (e.g., how prioritization scores and relational evidence are formatted) to improve reproducibility.
- The abstract would benefit from naming the specific metrics (precision@K, accuracy, etc.) underlying the 20.65% figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving the clarity and empirical rigor of the manuscript. We address each major comment below and will revise the paper accordingly to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: [Methods (candidate selection step)] The pipeline description of deep model inference for candidate selection does not include any mechanism, ablation, or analysis demonstrating that the candidate set reliably surfaces novel (unseen in training) diagnoses. This is load-bearing for the 30.97% novel-prediction gain, as any such lift could otherwise be explained by prompt formatting or LLM capability alone rather than the deep-model guidance.
Authors: We agree that an explicit analysis of the candidate selection step's ability to surface novel diagnoses is necessary to attribute the reported gains specifically to the deep-model guidance rather than other factors. The current manuscript describes the deep model as selecting candidates from its predictions but does not include supporting ablations or statistics on novel diagnosis coverage. In the revised version, we will add: (i) an analysis of the proportion of novel (unseen in training) diagnoses included in the candidate sets, (ii) an ablation isolating the candidate selection component's impact on novel diagnosis performance, and (iii) discussion of how this step addresses LLM overfitting. These additions will directly address the load-bearing concern for the 30.97% figure. revision: yes
-
Referee: [Results and Experiments] Results section and abstract report aggregate percentage gains without specifying the exact baselines (e.g., which LLMs or deep models), metric definitions, statistical significance tests, data splits, or how 'novel' diagnoses are operationalized. This prevents assessment of whether the central empirical claims are supported.
Authors: We acknowledge these omissions in the current draft, which limit the ability to fully evaluate the claims. The revised manuscript will explicitly detail: the exact baselines (LLM-only with GPT-4 and Llama-2-70B; deep model-only with fine-tuned BERT and clinical BERT variants), metric definitions (e.g., precision@5, accuracy, and F1), statistical significance testing (paired t-tests with p-values reported), data splits (temporal 70/15/15 splits on MIMIC-III and MIMIC-IV to prevent leakage), and the operationalization of 'novel' diagnoses (conditions absent from the patient's training history and the overall training corpus). We will also incorporate these specifics into the abstract and results section for completeness. revision: yes
Circularity Check
Empirical framework with no derivation chain or self-referential elements
full rationale
The paper proposes an empirical in-context reasoning framework (deep model candidate selection, evidential prioritization, relational evidence construction) that feeds into LLM prompts and reports performance on public MIMIC-III/IV benchmarks. No equations, fitted parameters presented as predictions, or mathematical derivations appear in the described pipeline. Claims rest on experimental comparisons to LLM-only and deep-model baselines rather than any self-citation chain or definitional reduction. The 30.97% novel-diagnosis improvement is an observed empirical outcome, not a quantity forced by construction from the method's inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tanisha Aggarwal et al. 2025. Harnessing AI Algorithms for Accurate Medical Diagnosis from Electronic Health Record. In2025 IEEE International Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation (IATMSI), Vol. 3. IEEE, 1–5
2025
-
[2]
Emmi Antikainen, Joonas Linnosmaa, Adil Umer, Niku Oksala, Markku Eskola, Mark van Gils, Jussi Hernesniemi, and Moncef Gabbouj. 2023. Transformers for cardiac patient mortality risk prediction from heterogeneous electronic health records.Scientific Reports13, 1 (2023), 3517
2023
-
[3]
Jiayuan Chen, Changchang Yin, Yuanlong Wang, and Ping Zhang. 2024. Predictive modeling with temporal graphical representation on electronic health records. InIJCAI: proceedings of the conference, Vol. 2024. 5763
2024
-
[4]
Xuanzhong Chen, Xiaohao Mao, Qihan Guo, Lun Wang, Shuyang Zhang, and Ting Chen. 2024. RareBench: Can LLMs Serve as Rare Diseases Specialists?. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4850–4861
2024
-
[5]
Chih-Chou Chiu, Chung-Min Wu, Te-Nien Chien, Ling-Jing Kao, Chengcheng Li, and Chuan-Mei Chu. 2023. Integrating structured and unstructured EHR data for predicting mortality by machine learning and latent Dirichlet allocation method.International journal of environmental research and public health20, 5 (2023), 4340
2023
-
[6]
Edward Choi, Mohammad Taha Bahadori, Le Song, Walter F Stewart, and Jimeng Sun. 2017. GRAM: graph-based attention model for healthcare representation learning. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 787–795
2017
-
[7]
Edward Choi, Mohammad Taha Bahadori, Jimeng Sun, Joshua Kulas, Andy Schuetz, and Walter Stewart. 2016. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism.Advances in neural information processing systems29 (2016)
2016
-
[8]
Sirui Ding, Jiancheng Ye, Xia Hu, and Na Zou. 2024. Distilling the knowledge from large-language model for health event prediction.Scientific Reports14, 1 (2024), 30675
2024
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[10]
Junyi Gao, Cao Xiao, Yasha Wang, Wen Tang, Lucas M Glass, and Jimeng Sun. 2020. Stagenet: Stage-aware neural networks for health risk prediction. InProceedings of the web conference 2020. 530–540
2020
- [11]
-
[12]
Janneke MT Hendriksen, Geert-Jan Geersing, Karel GM Moons, and Joris AH de Groot. 2013. Diagnostic and prognostic prediction models.Journal of Thrombosis and Haemostasis11 (2013), 129–141
2013
- [13]
- [14]
- [15]
-
[16]
Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2024. GeneGPT: augmenting large language models with domain tools for improved access to biomedical information.Bioinformatics40, 2 (2024), btae075
2024
-
[17]
Li Jiu, Junfeng Wang, Francisco Javier Somolinos-Simón, Jose Tapia-Galisteo, Gema García-Sáez, Mariaelena Hernando, Xinyu Li, Rick A Vreman, Aukje K Mantel-Teeuwisse, and Wim G Goettsch. 2024. A literature review of quality assessment and applicability to HTA of risk prediction models of coronary heart disease in patients with diabetes.Diabetes research a...
2024
-
[18]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database.Scientific data3, 1 (2016), 1–9
2016
-
[19]
Alistair EW Johnson, David J Stone, Leo A Celi, and Tom J Pollard. 2018. The MIMIC Code Repository: enabling reproducibility in critical care research.Journal of the American Medical Informatics Association25, 1 (2018), 32–39
2018
- [20]
-
[21]
Taeyoon Kwon, Kai Tzu-iunn Ong, Dongjin Kang, Seungjun Moon, Jeong Ryong Lee, Dosik Hwang, Beomseok Sohn, Yongsik Sim, Dongha Lee, and Jinyoung Yeo. 2024. Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales. InProceedings of the AAAI Conference on Artificial Intelligence
2024
-
[22]
Qing Li, Zehao Li, Jingjing Song, Jianshuo Bao, Jin Yang, and Zhuhong You
-
[23]
InKrat: Interpretable diagnosis prediction models based on cross-modal knowledge graph semantic retrieval fusion.Information Fusion(2025), 103546
2025
-
[24]
Chang Lu, Chandan K Reddy, Prithwish Chakraborty, Samantha Kleinberg, and Yue Ning. 2021. Collaborative Graph Learning with Auxiliary Text for Temporal Event Prediction in Healthcare. InInternational Joint Conference on Artificial Intelligence
2021
-
[25]
Junyu Luo, Muchao Ye, Cao Xiao, and Fenglong Ma. 2020. Hitanet: Hierarchical time-aware attention networks for risk prediction on electronic health records. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 647–656
2020
-
[26]
Hang Lv, Zehai Chen, Yacong Yang, Guofang Ma, Tan Yanchao, and Carl Yang
-
[27]
InCompanion Proceedings of the ACM Web Conference 2024
BoxCare: a box embedding model for disease representation and diag- nosis prediction in healthcare data. InCompanion Proceedings of the ACM Web Conference 2024. 1130–1133
2024
-
[28]
Fenglong Ma, Radha Chitta, Jing Zhou, Quanzeng You, Tong Sun, and Jing Gao
-
[29]
InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining
Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 1903–1911
1903
-
[30]
Sidra Nasir, Rizwan Ahmed Khan, and Samita Bai. 2024. Ethical framework for harnessing the power of AI in healthcare and beyond.IEEE Access12 (2024), 31014–31035
2024
- [31]
-
[32]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[33]
Thomas Savage, Ashwin Nayak, Robert Gallo, Ekanath Rangan, and Jonathan H Chen. 2024. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine.NPJ Digital Medicine7, 1 (2024), 20
2024
-
[34]
Yanchao Tan, Hang Lv, Yunfei Zhan, Guofang Ma, Bo Xiong, and Carl Yang. 2025. BoxLM: Unifying Structures and Semantics of Medical Concepts for Diagnosis Prediction in Healthcare. InForty-second International Conference on Machine Learning
2025
-
[35]
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. 2024. MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning. InACL Findings
2024
-
[36]
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, et al. 2025. Towards conversational diagnostic artificial intelligence.Nature642, 8067 (2025), 442–450
2025
- [37]
-
[38]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[40]
Hao Wu, Yinghao Zhu, Zixiang Wang, Xiaochen Zheng, Ling Wang, Wen Tang, Yasha Wang, Chengwei Pan, Ewen M Harrison, Junyi Gao, et al. 2024. Ehrflow: A large language model-driven iterative multi-agent electronic health record data analysis workflow. InArtificial Intelligence and Data Science for Healthcare: Bridging Data-Centric AI and People-Centric Healthcare
2024
-
[41]
Yongxin Xu, Xu Chu, Kai Yang, Zhiyuan Wang, Peinie Zou, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. 2023. Seqcare: Sequential training with external medical knowledge graph for diagnosis prediction in healthcare data. In Proceedings of the ACM Web Conference 2023. 2819–2830
2023
-
[42]
Yongxin Xu, Xinke Jiang, Xu Chu, Rihong Qiu, Yujie Feng, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. 2025. DearLLM: Enhancing Personalized Health- care via Large Language Models-Deduced Feature Correlations. InProceedings of the AAAI Conference on Artificial Intelligence
2025
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Cyril Zakka, Rohan Shad, Akash Chaurasia, Alex R Dalal, Jennifer L Kim, Michael Moor, Robyn Fong, Curran Phillips, Kevin Alexander, Euan Ashley, et al. 2024. Almanac—retrieval-augmented language models for clinical medicine.Nejm ai1, 2 (2024), AIoa2300068
2024
-
[45]
Other primary cardiomy- opathies
Sunyi Zheng, Nannan Zhao, Jing Wang, Tao Yu, Dongsheng Yue, Wenjia Zhang, Shuxuan Fan, Xiaolei Wang, Guilin Tang, Yuxuan Sun, et al. 2025. Comparison of a specialized large language model with GPT-4o for CT and MRI radiology report summarization.Radiology316, 2 (2025), e243774. EviCare: Enhancing Diagnosis Prediction with Deep Model-Guided Evidence for In...
2025
-
[46]
Other primary cardiomyopathies
The patient has "Other primary cardiomyopathies" and "Cardiac dysrhythmias", both of which are pre- cursors or components of nonhypertensive heart fail- ure. Although not explicitly stated, the progression is clinically plausible
-
[47]
Other primary car- diomyopathies
The patient’s history includes "Other primary car- diomyopathies" (ICD) and "Cardiac dysrhythmias" (CCS), which are strong indicators of heart failure. Cardiomyopathies can progress to heart failure, and dysrhythmias like paroxysmal ventricular tachycar- dia are common in heart failure
-
[48]
Fitting and adjustment of automatic implantable cardiac defibrillator
(No relevant prediction) EviCare (Ours) This is supported by the patient’s history of cardiac dysrhythmias, other primary cardiomyopathies, and AICD adjustment. These conditions are often associ- ated with heart failure, especially in the context of chronic disease and device management. Relational Evidence "Fitting and adjustment of automatic implantable...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.