Recognition: unknown
ExpertEdit: Learning Skill-Aware Motion Editing from Expert Videos
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
ExpertEdit edits novice motions toward higher skill by learning an expert motion prior from unpaired expert videos alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
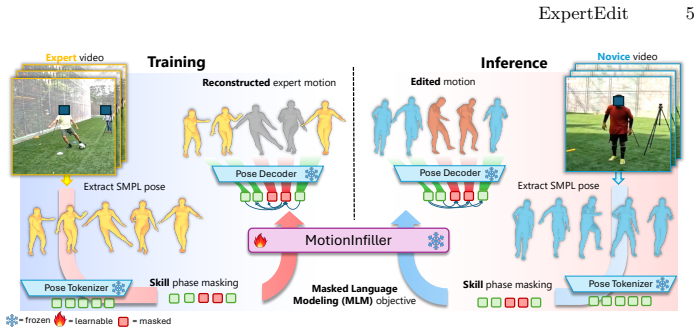
ExpertEdit trains an expert motion prior on unpaired expert videos by masking random spans and training the model to infill them with expert refinements. At inference, novice motion is masked at skill-critical moments and the masked segments are projected into this prior, yielding localized skill improvements without paired supervision or explicit guidance.
What carries the argument
The masked language modeling objective that infills masked motion spans with expert-level refinements to form the learned expert motion prior.
If this is right
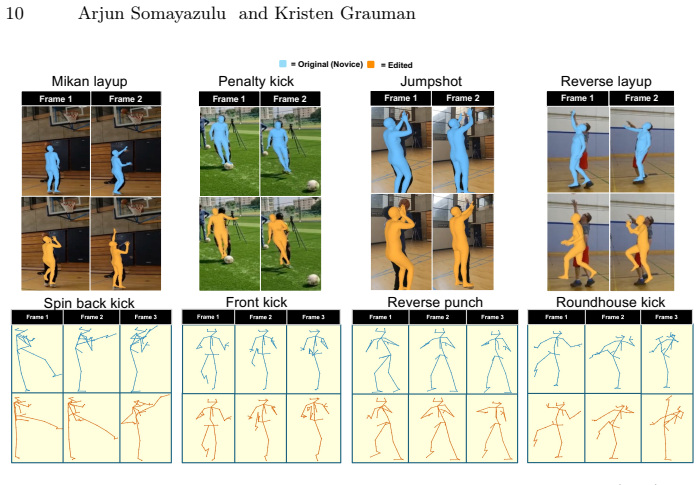
- The method outperforms supervised motion editing baselines on multiple metrics of realism and expert quality across eight diverse techniques and three sports.
- Skill improvements occur locally at masked critical moments rather than globally across the entire sequence.
- Training requires only unpaired expert videos, removing the need to collect or align novice-expert pairs.
- Inference needs no manual edit guidance or paired examples, enabling fully automatic application to new videos.
Where Pith is reading between the lines
- The same masking-and-projection strategy could be tested on other sequential data such as dance sequences or rehabilitation exercises where expert demonstrations exist but paired data do not.
- Real-time versions of the pipeline might support immediate visual feedback loops in training apps if the masking step can be made fast enough.
- Performance across different body proportions or camera viewpoints would be a natural next test to determine how far the expert manifold generalizes beyond the training distributions.
Load-bearing premise
Masking novice motion at skill-critical moments and projecting it into the learned expert manifold produces localized meaningful skill improvements without paired supervision or explicit edit guidance.
What would settle it
Quantitative evaluation on the eight techniques from Ego-Exo4D and Karate Kyokushin showing no gains in motion realism or expert quality metrics over state-of-the-art supervised motion editing methods would falsify the central claim.
Figures


read the original abstract
Visual feedback is critical for motor skill acquisition in sports and rehabilitation, and psychological studies show that observing near-perfect versions of one's own performance accelerates learning more effectively than watching expert demonstrations alone. We propose to enable such personalized feedback by automatically editing a person's motion to reflect higher skill. Existing motion editing approaches are poorly suited for this setting because they assume paired input-output data -- rare and expensive to curate for skill-driven tasks -- and explicit edit guidance at inference. We introduce ExpertEdit, a framework for skill-driven motion editing trained exclusively on unpaired expert video demonstrations. ExpertEdit learns an expert motion prior with a masked language modeling objective that infills masked motion spans with expert-level refinements. At inference, novice motion is masked at skill-critical moments and projected into the learned expert manifold, producing localized skill improvements without paired supervision or manual edit guidance. Across eight diverse techniques and three sports from Ego-Exo4D and Karate Kyokushin, ExpertEdit outperforms state-of-the-art supervised motion editing methods on multiple metrics of motion realism and expert quality. Project page: https://vision.cs.utexas.edu/projects/expert_edit/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ExpertEdit, a framework for skill-driven motion editing trained solely on unpaired expert videos. It learns an expert motion prior via masked language modeling that infills masked spans with expert refinements. At inference, novice motions are masked at skill-critical moments and projected into the learned expert manifold to produce localized improvements. The method is evaluated on eight techniques across three sports from Ego-Exo4D and Karate Kyokushin, claiming to outperform state-of-the-art supervised motion editing baselines on metrics of motion realism and expert quality without requiring paired data or explicit edit guidance.
Significance. If the central claims hold after clarification, the work would be significant for computer vision applications in personalized feedback for sports and rehabilitation. Learning skill-aware priors from unpaired experts via masked modeling avoids the data collection burden of paired supervision and could enable scalable motion editing; the reported outperformance on diverse techniques provides a concrete benchmark for future unpaired methods.
major comments (2)
- [§4] §4 (Inference procedure): The mechanism for automatically identifying 'skill-critical moments' in novice input is unspecified. The abstract claims masking occurs 'at skill-critical moments' and produces improvements 'without ... manual edit guidance,' but if detection relies on heuristics, a separate model, or any form of selection, this constitutes explicit guidance. This is load-bearing for the no-supervision claim and for fair comparison to supervised baselines that receive explicit paired signals.
- [§5] §5 (Experiments and results): The outperformance claims on realism and expert quality metrics across eight techniques lack reported statistical significance tests, details on baseline re-implementations or hyperparameter matching, and confirmation that metric choices were not post-hoc. Without these, the superiority over supervised methods cannot be verified as robust, directly affecting the central empirical claim.
minor comments (2)
- [Abstract] Abstract: The reference to 'psychological studies' on observing near-perfect versions of one's performance should include specific citations for traceability.
- [Method] Method section: Notation for motion representations (e.g., how spans are masked and projected) could be introduced with a clear equation or diagram earlier to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the inference procedure and experimental reporting. We address each major comment below and outline revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Inference procedure): The mechanism for automatically identifying 'skill-critical moments' in novice input is unspecified. The abstract claims masking occurs 'at skill-critical moments' and produces improvements 'without ... manual edit guidance,' but if detection relies on heuristics, a separate model, or any form of selection, this constitutes explicit guidance. This is load-bearing for the no-supervision claim and for fair comparison to supervised baselines that receive explicit paired signals.
Authors: We appreciate the referee's emphasis on this point, as it directly relates to our central claim of operating without manual edit guidance. Section 4 of the manuscript specifies that masking at inference is performed automatically on the novice input motion alone, using only information derived from the input sequence itself and without any user-provided masks, paired supervision, or external signals. This is distinct from the explicit edit guidance supplied to the supervised baselines. We acknowledge that the current description could be more explicit about the precise automatic identification process. In the revised version, we will expand §4 with additional algorithmic details and pseudocode to demonstrate that the procedure requires no manual intervention or paired data, thereby reinforcing rather than weakening the no-supervision claim. revision: partial
-
Referee: [§5] §5 (Experiments and results): The outperformance claims on realism and expert quality metrics across eight techniques lack reported statistical significance tests, details on baseline re-implementations or hyperparameter matching, and confirmation that metric choices were not post-hoc. Without these, the superiority over supervised methods cannot be verified as robust, directly affecting the central empirical claim.
Authors: We agree that these elements are essential for verifying the robustness of the empirical results. In the revised manuscript, we will add statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) for all metric comparisons across the eight techniques. We will also include an expanded methods or appendix section providing full details on baseline re-implementations, including hyperparameter choices and how they were aligned with the original publications. Finally, we will add an explicit statement confirming that the evaluation metrics were selected a priori based on prior motion editing literature and not chosen post-hoc. These changes will be incorporated without altering the reported numerical results. revision: yes
Circularity Check
No circularity; derivation uses standard masked modeling on unpaired data with independent external evaluation
full rationale
The paper's core pipeline—masked language modeling on unpaired expert videos to learn a motion prior, followed by inference-time masking of novice inputs and projection into the prior—is described without any equations or steps that reduce by construction to fitted parameters, self-citations, or renamed inputs. Training objective and inference procedure are distinct, and performance claims rest on comparisons to supervised baselines on external datasets (Ego-Exo4D, Karate Kyokushin), which are not forced by the training process itself. No load-bearing self-citation chains or ansatzes are invoked in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert motions form a manifold that masked language modeling on unpaired videos can capture as a prior for infilling refinements.
- domain assumption Skill-critical moments in novice motion can be masked and projected into the expert manifold to yield localized improvements.
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics39(4) (Aug 2020)
Aberman, K., Weng, Y., Lischinski, D., Cohen-Or, D., Chen, B.: Unpaired motion style transfer from video to animation. ACM Transactions on Graphics39(4) (Aug 2020). https://doi.org/10.1145/3386569.3392469 , http://dx.doi.org/ 10.1145/3386569.33924694
-
[2]
006724, 9, 11
Ashutosh, K., Nagarajan, T., Pavlakos, G., Kitani, K., Grauman, K.: Expertaf: Expert actionable feedback from video (2025), https://arxiv.org/abs/2408. 006724, 9, 11
2025
- [3]
- [4]
-
[5]
In: Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology
Cheng, L., Xie, X., Peng, Y., Feng, M., He, Y., Cao, A., Wu, Y., Zhang, H., Wu, Y.: Vismimic: Integrating motion chain in feedback video generation for motor coaching. In: Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. UIST ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/...
- [6]
-
[7]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Ding, Y., Zhang, S., Shenglan, L., Zhang, J., Chen, W., Haifei, D., dong, b., Sun, T.: 2m-af: A strong multi-modality framework for human action quality assessment with self-supervised representation learning. In: Proceedings of the 32nd ACM International Conference on Multimedia. p. 1564–1572. MM ’24, Association for Computing Machinery, New York, NY, US...
-
[8]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Dittakavi, B., Bavikadi, D., Desai, S.V., Chakraborty, S., Reddy, N., Balasub- ramanian, V.N., Callepalli, B., Sharma, A.: Pose tutor: An explainable system for pose correction in the wild. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 3539–3548 (2022). https://doi.org/10.1109/CVPRW56347.2022.003984
- [9]
-
[10]
In: Proceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games
Du, H., Herrmann, E., Sprenger, J., Fischer, K., Slusallek, P.: Stylistic locomotion modeling and synthesis using variational generative models. In: Proceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games. MIG ’19, Association for Computing Machinery, New York, NY, USA (2019).https://doi. org/10.1145/3359566.3360083,https://doi.or...
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Fieraru, M., Zanfir, M., Pirlea, S.C., Olaru, V., Sminchisescu, C.: Aifit: Automatic 3d human-interpretable feedback models for fitness training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9919–9928 (June 2021) 4
2021
-
[12]
Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models
Goel, P., Wang, K.C., Liu, C.K., Fatahalian, K.: Iterative motion editing with natural language. In: Special Interest Group on Computer Graphics and Inter- active Techniques Conference Conference Papers. p. 1–9. SIGGRAPH ’24, ACM (Jul 2024). https://doi.org/10.1145/3641519.3657447, http://dx.doi.org/10. 1145/3641519.36574474 16 Arjun Somayazulu and Kriste...
-
[13]
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., Byrne, E., Chavis, Z., Chen, J., Cheng, F., Chu, F.J., Crane, S., Dasgupta, A., Dong, J., Escobar, M., Forigua, C., Gebreselasie, A., Haresh, S., Huang, J., Islam, M.M., Jain, S., Khirodkar, R., Kukreja, D., Liang, K.J., Liu, J.W....
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating diverse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5152–5161 (June 2022) 12
2022
- [15]
-
[16]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium (2018), https://arxiv.org/abs/1706.0850011
work page Pith review arXiv 2018
-
[17]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models (2020),https: //arxiv.org/abs/2006.1123911
work page internal anchor Pith review arXiv 2020
-
[18]
SIGGRAPH Asia 2015 Technical Briefs , year =
Holden, D., Saito, J., Komura, T., Joyce, T.: Learning motion manifolds with convolutional autoencoders. In: SIGGRAPH Asia 2015 Technical Briefs. SA ’15, Association for Computing Machinery, New York, NY, USA (2015).https://doi. org/10.1145/2820903.2820918,https://doi.org/10.1145/2820903.28209184
- [19]
- [20]
- [21]
-
[22]
Jang, D.K., Park, S., Lee, S.H.: Motion puzzle: Arbitrary motion style transfer by body part. ACM Transactions on Graphics41(3), 1–16 (Jun 2022).https: //doi.org/10.1145/3516429,http://dx.doi.org/10.1145/35164294
- [23]
-
[24]
207242, 4
Jiang, N., Li, H., Yuan, Z., He, Z., Chen, Y., Liu, T., Zhu, Y., Huang, S.: Dynamic motion blending for versatile motion editing (2025),https://arxiv.org/abs/2503. 207242, 4
2025
-
[25]
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for improved quality, stability, and variation (2018),https://arxiv.org/abs/1710.1019611 ExpertEdit 17
work page internal anchor Pith review arXiv 2018
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kim, B., Kim, J., Chang, H.J., Choi, J.Y.: Most: Motion style transformer between diverse action contents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1705–1714 (June 2024) 4
2024
- [27]
- [28]
- [29]
-
[30]
IEEE Transactions on Visualization and Computer Graphics30(7), 3180–3195 (Jul 2024)
Liu, J., Saquib, N., Zhutian, C., Kazi, R.H., Wei, L.Y., Fu, H., Tai, C.L.: Posecoach: A customizable analysis and visualization system for video-based running coaching. IEEE Transactions on Visualization and Computer Graphics30(7), 3180–3195 (Jul 2024). https://doi.org/10.1109/tvcg.2022.3230855 , http://dx.doi.org/10. 1109/TVCG.2022.32308554
- [31]
- [32]
-
[33]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia)34(6), 248:1–248:16 (Oct 2015) 5, 12
2015
-
[34]
105424, 7, 11, 12, 22
Lucas, T., Baradel, F., Weinzaepfel, P., Rogez, G.: Posegpt: Quantization-based 3d human motion generation and forecasting (2022),https://arxiv.org/abs/2210. 105424, 7, 11, 12, 22
2022
- [35]
-
[36]
In: ProceedingsoftheIEEE/CVFInternationalConferenceonComputerVision(ICCV) Workshops
Noworolnik, F., Jaworek-Korjakowska, J.: Assessing the quality of soccer shots from single-camera video with vision-language models and motion features. In: ProceedingsoftheIEEE/CVFInternationalConferenceonComputerVision(ICCV) Workshops. pp. 2733–2740 (October 2025) 3
2025
- [37]
-
[38]
In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII
Parmar, P., Gharat, A., Rhodin, H.: Domain knowledge-informed self-supervised representations for workout form assessment. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII. pp. 105–123. Springer (2022) 3
2022
-
[39]
Parmar, P., Morris, B.T.: Learning to score olympic events (2017),https://arxiv. org/abs/1611.051253
- [40]
- [41]
- [42]
-
[43]
Sport Psychologist17, 220–241 (06 2003).https://doi
Ram, N., McCullagh, P.: Self-modeling: Influence on psychological responses and physical performance. Sport Psychologist17, 220–241 (06 2003).https://doi. org/10.1123/tsp.17.2.2201
- [44]
-
[45]
In: Proceedings of the 27th International Conference on Multimodal Interaction
Richardson, A., Putze, F.: Motion diffusion autoencoders: Enabling attribute manipulation in human motion demonstrated on karate techniques. In: Proceedings of the 27th International Conference on Multimodal Interaction. p. 372–380. ICMI ’25, ACM (Oct 2025).https://doi.org/10.1145/3716553.3750773, http://dx. doi.org/10.1145/3716553.375077310, 20
- [46]
-
[47]
Frontiers in Psy- chology2, 155 (2011).https://doi.org/10.3389/fpsyg.2011.001551
Ste-Marie, D.M., Vertes, K., Rymal, A.M., Martini, R.: Feedforward self-modeling enhances skill acquisition in children learning trampoline skills. Frontiers in Psy- chology2, 155 (2011).https://doi.org/10.3389/fpsyg.2011.001551
-
[48]
Steel, K.A., Mudie, K., Sandoval, R., Anderson, D., Dogramaci, S., Rehmanjan, M., Birznieks, I.: Can video self-modeling improve affected limb reach and grasp ability in stroke patients? Journal of Motor Behavior50(2), 117–126 (2018).https: //doi.org/10.1080/00222895.2017.1306480, epub 2017 May 19 1
-
[49]
Scientific Data8(01 2021).https://doi.org/10.1038/s41597-021-00801-51, 9
Szczęsna, A., Błaszczyszyn, M., Pawlyta, M.: Optical motion capture dataset of selected techniques in beginner and advanced kyokushin karate athletes. Scientific Data8(01 2021).https://doi.org/10.1038/s41597-021-00801-51, 9
- [50]
-
[51]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model (2022),https://arxiv.org/abs/2209.1491611
work page internal anchor Pith review arXiv 2022
- [52]
- [53]
- [54]
- [55]
-
[56]
Xu, H., Ke, X., Li, Y., Xu, R., Wu, H., Lin, X., Guo, W.: Vision-language ac- tion knowledge learning for semantic-aware action quality assessment. In: Com- puter Vision – ECCV 2024: 18th European Conference, Milan, Italy, Septem- ber 29–October 4, 2024, Proceedings, Part XLII. p. 423–440. Springer-Verlag, Berlin, Heidelberg (2024). https://doi.org/10.100...
- [57]
- [58]
- [59]
- [60]
- [61]
-
[62]
Yang, Z., Zhu, W., Wu, W., Qian, C., Zhou, Q., Zhou, B., Loy, C.C.: Transmomo: Invariance-driven unsupervised video motion retargeting (2020),https://arxiv. org/abs/2003.144014
-
[63]
Yeh, W.H., Su, Y.A., Chen, C.N., Lin, Y.H., Ku, C., Chiu, W., Hu, M.C., Ku, L.W.: Coachme: Decoding sport elements with a reference-based coaching instruction generation model. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). p. 29126–29151. Association for Computational Linguistics (2025...
- [64]
- [65]
-
[66]
Yin, H., Gu, L., Parmar, P., Xu, L., Guo, T., Fu, W., Zhang, Y., Zheng, T.: Flex: A large-scale multi-modal multi-action dataset for fitness action quality assessment (2025),https://arxiv.org/abs/2506.031983
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [67]
-
[68]
Motiondiffuse: Text-driven human motion generation with diffusion model
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondiffuse: Text-driven human motion generation with diffusion model (2022),https://arxiv. org/abs/2208.1500111
- [69]
-
[70]
Zhang, S., Bai, S., Chen, G., Chen, L., Lu, J., Wang, J., Tang, Y.: Narrative action evaluation with prompt-guided multimodal interaction (2024),https://arxiv. org/abs/2404.144713
- [71]
- [72]
-
[73]
Zhu, S., Chen, J.L., Dai, Z., Su, Q., Xu, Y., Cao, X., Yao, Y., Zhu, H., Zhu, S.: Champ: Controllable and consistent human image animation with 3d parametric guidance (2024),https://arxiv.org/abs/2403.147814 ExpertEdit: Learning Skill-Aware Motion Editing from Expert Videos Supplementary Material Table of Contents
-
[74]
Dataset preprocessing and technique clip extraction pipeline ....... Sec. A
-
[75]
Details of the procedure for constructing test set pseudo-pairs ..... Sec. B
-
[76]
Additional model architecture and training details ................. Sec. C
-
[77]
train set size scaling analysis
Performance vs. train set size scaling analysis ...................... Sec. D
-
[78]
Experiments with different text prompts for baselines .............. Sec. E
-
[79]
ball leaves hand,
Supplementary video content overview ............................. Sec. F A Dataset preprocessing and technique clip extraction We describe our procedure for extracting technique-centered clips from Ego- Exo4D (c.f. Sec. 3.1 ‘Technique criteria’, Sec. 4 ‘Datasets’). For Kyokushin karate, we directly use the pre-trimmed clips provided by MoDiffAE [45]. A.1...
-
[80]
Implementation details
(3) DTW then finds the minimum-cost monotonic alignment path π∗ = arg min π∈P X (i,j)∈π c(p n i ,p e j ), (4) where P denotesthesetofvalidmonotonicwarpingpaths.Theresultingalignment π∗ defines a frame mapping i7→π (i), which we use to resample the expert sequence to match the novice clip lengthT. 22 To address left–right asymmetries between novice and exp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.