Recognition: unknown
Tracing the Roots: A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
Pith reviewed 2026-05-10 16:11 UTC · model grok-4.3
The pith
Reconstructing evolutionary graphs of post-training datasets for LLMs reveals hidden redundancies and enables more diverse data curation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the concept of data lineage to the LLM ecosystem and propose an automated multi-agent framework to reconstruct the evolutionary graph of dataset development. Through large-scale lineage analysis, we characterize domain-specific structural patterns, such as vertical refinement in math-oriented datasets and horizontal aggregation in general-domain corpora. Moreover, we uncover pervasive systemic issues, including structural redundancy induced by implicit dataset intersections and the propagation of benchmark contamination along lineage paths. To demonstrate the practical value of lineage analysis for data construction, we leverage the reconstructed lineage graph to create a lineag
What carries the argument
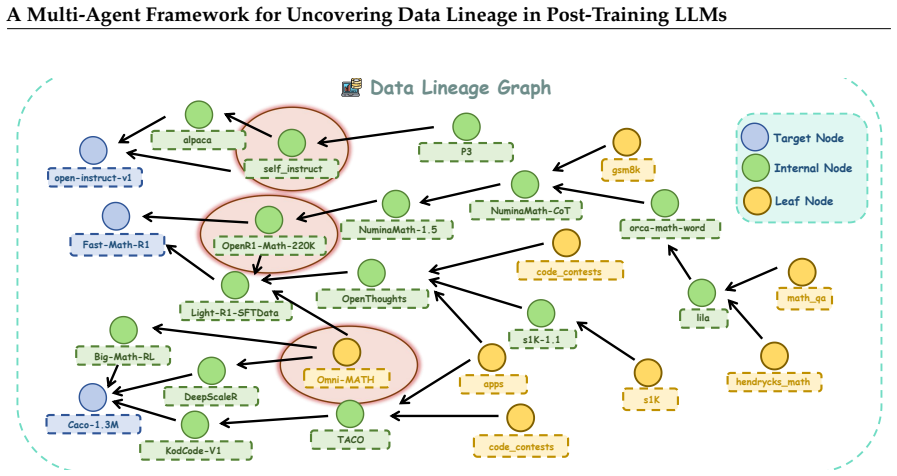
The data lineage graph, an evolutionary structure that captures directed relationships showing how later datasets derive from and build upon earlier root sources.
If this is right
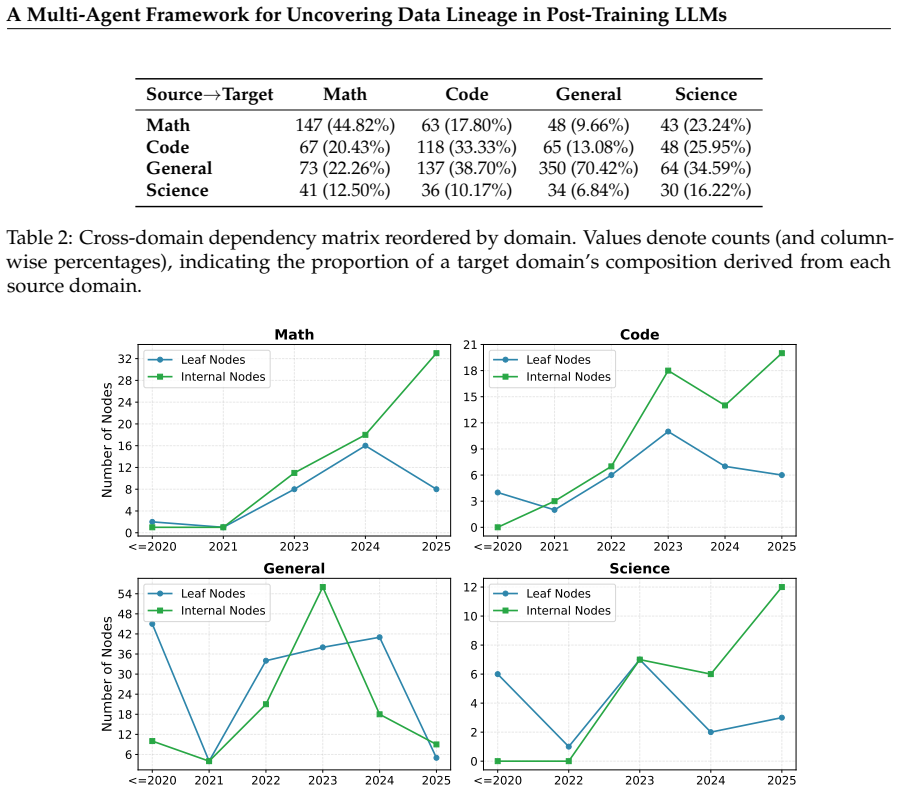
- Lineage analysis can characterize structural patterns such as vertical refinement in math-oriented datasets and horizontal aggregation in general-domain corpora.
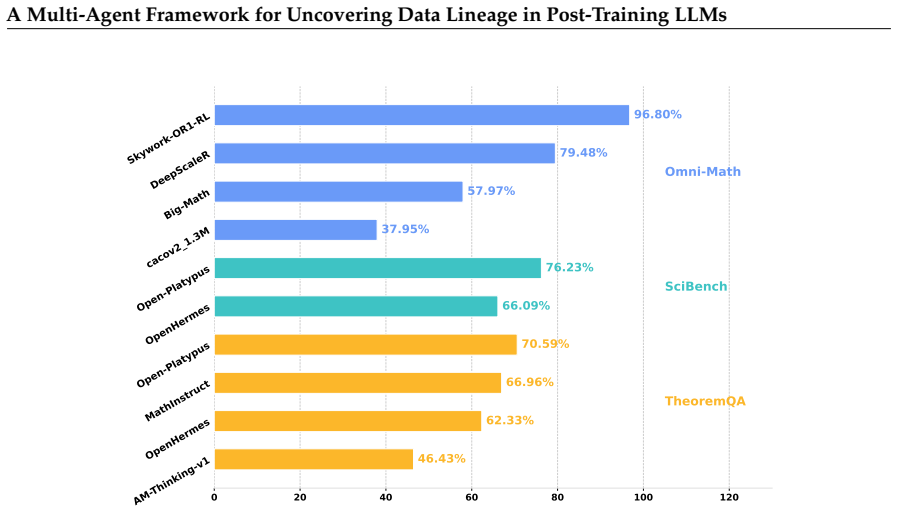
- Systemic issues become visible, including structural redundancy from implicit dataset intersections and propagation of benchmark contamination along lineage paths.
- Anchoring instruction sampling at upstream root sources in the lineage graph mitigates downstream homogenization and produces a more diverse post-training corpus.
- Lineage-centric analysis serves as an efficient topological alternative to sample-level dataset comparison for large-scale data ecosystems.
Where Pith is reading between the lines
- If lineage graphs prove reliable, they could support tracing specific model capabilities or biases back to originating data sources.
- Lineage structures might enable automated detection and removal of redundant branches when building new datasets.
- This approach could extend to other data ecosystems, such as those used for vision or multimodal models, to map their own evolutionary connections.
- Explicit lineage tracking might inform standards for data provenance and transparency requirements in AI development.
Load-bearing premise
The multi-agent framework can accurately reconstruct true evolutionary relationships between datasets at scale without introducing significant errors, biases, or incomplete mappings.
What would settle it
A manual expert audit of a sample of claimed lineage links between datasets that finds many false positives, false negatives, or missing connections would disprove the framework's reconstruction accuracy.
Figures


read the original abstract
Post-training data plays a pivotal role in shaping the capabilities of Large Language Models (LLMs), yet datasets are often treated as isolated artifacts, overlooking the systemic connections that underlie their evolution. To disentangle these complex relationships, we introduce the concept of \textbf{data lineage} to the LLM ecosystem and propose an automated multi-agent framework to reconstruct the evolutionary graph of dataset development. Through large-scale lineage analysis, we characterize domain-specific structural patterns, such as vertical refinement in math-oriented datasets and horizontal aggregation in general-domain corpora. Moreover, we uncover pervasive systemic issues, including \textit{structural redundancy} induced by implicit dataset intersections and the \textit{propagation of benchmark contamination} along lineage paths. To demonstrate the practical value of lineage analysis for data construction, we leverage the reconstructed lineage graph to create a \textit{lineage-aware diversity-oriented dataset}. By anchoring instruction sampling at upstream root sources, this approach mitigates downstream homogenization and hidden redundancy, yielding a more diverse post-training corpus. We further highlight lineage-centric analysis as an efficient and robust topological alternative to sample-level dataset comparison for large-scale data ecosystems. By grounding data construction in explicit lineage structures, our work advances post-training data curation toward a more systematic and controllable paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the concept of data lineage to post-training LLMs and presents an automated multi-agent framework for reconstructing evolutionary graphs of dataset development. It analyzes large-scale patterns such as vertical refinement in math datasets and horizontal aggregation in general-domain corpora, identifies structural redundancy and benchmark contamination propagation, and applies the lineage graph to construct a lineage-aware diversity-oriented dataset by sampling from upstream roots, claiming this yields a more diverse corpus. The work positions lineage analysis as a topological alternative to sample-level comparisons for data curation.
Significance. If the reconstruction framework proves accurate at scale, the work would offer a systematic, graph-based approach to post-training data curation that could reduce hidden redundancies and contamination more effectively than current ad-hoc methods. The multi-agent design for automated lineage tracing and the downstream application to diversity sampling represent a novel framing that could influence how datasets are constructed and audited in the LLM ecosystem.
major comments (3)
- [§3] §3 (Framework description): The multi-agent system is presented as reconstructing accurate evolutionary relationships, yet no ground-truth validation, precision/recall metrics, or human-verified subset is reported against known dataset provenance. This is load-bearing because all claims of structural redundancy, contamination propagation, and diversity gains rest on the fidelity of the reconstructed edges and roots.
- [§4] §4 (Lineage analysis): The characterizations of vertical refinement and horizontal aggregation are described qualitatively without formal definitions, quantitative metrics (e.g., edge-type distributions or statistical tests), or ablation on agent components, leaving open whether the observed patterns are robust or artifacts of the reconstruction process.
- [§5] §5 (Lineage-aware dataset construction): The claim that anchoring sampling at root sources produces a measurably more diverse corpus lacks reported diversity scores, overlap statistics, or controlled comparisons to non-lineage baselines, so the practical benefit cannot be assessed independently of reconstruction accuracy.
minor comments (2)
- [Abstract] Abstract and §2: The introduction of 'data lineage' would benefit from explicit citations to prior provenance work in data management and ML dataset papers to clarify novelty.
- Notation: The evolutionary graph is referred to with terms like 'vertical refinement' and 'horizontal aggregation' without accompanying formal definitions or pseudocode in the main text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key areas where additional rigor will strengthen the manuscript. We agree that the fidelity of the lineage reconstruction is central to the claims and that the analysis and evaluation sections require more formalization and quantification. We outline targeted revisions below to address each point.
read point-by-point responses
-
Referee: [§3] §3 (Framework description): The multi-agent system is presented as reconstructing accurate evolutionary relationships, yet no ground-truth validation, precision/recall metrics, or human-verified subset is reported against known dataset provenance. This is load-bearing because all claims of structural redundancy, contamination propagation, and diversity gains rest on the fidelity of the reconstructed edges and roots.
Authors: We acknowledge that the current manuscript does not include explicit quantitative validation of the reconstruction accuracy. While the multi-agent design uses LLM reasoning grounded in dataset metadata, content similarity, and provenance signals, we agree this is insufficient without empirical checks. In the revision we will add a new validation subsection to §3 that reports: (i) a human-annotated ground-truth set of 200 dataset pairs drawn from well-documented lineages (e.g., MATH, GSM8K, and Alpaca variants), (ii) precision, recall, and F1 scores for edge and root inference, and (iii) an error analysis categorizing false positives and negatives. We will also discuss the framework’s assumptions and failure modes. These additions will directly support the reliability of the structural and diversity claims. revision: yes
-
Referee: [§4] §4 (Lineage analysis): The characterizations of vertical refinement and horizontal aggregation are described qualitatively without formal definitions, quantitative metrics (e.g., edge-type distributions or statistical tests), or ablation on agent components, leaving open whether the observed patterns are robust or artifacts of the reconstruction process.
Authors: We agree that the domain-pattern analysis would benefit from formal definitions and quantitative backing. We will introduce precise definitions: vertical refinement as the average length of directed refinement chains within a domain, and horizontal aggregation as the mean in-degree of nodes in the lineage graph. We will report edge-type distributions (refinement vs. aggregation) per domain, accompanied by chi-squared tests for distributional differences. In addition, we will include an ablation study that disables individual agents (e.g., the content-similarity agent or the provenance agent) and measures the resulting change in detected patterns. These elements, together with new tables and figures, will be incorporated into §4. revision: yes
-
Referee: [§5] §5 (Lineage-aware dataset construction): The claim that anchoring sampling at root sources produces a measurably more diverse corpus lacks reported diversity scores, overlap statistics, or controlled comparisons to non-lineage baselines, so the practical benefit cannot be assessed independently of reconstruction accuracy.
Authors: We recognize that the diversity benefit of lineage-aware sampling requires quantitative demonstration. In the revised §5 we will report: (i) diversity metrics including unique n-gram coverage, average pairwise embedding cosine distance, and the fraction of samples overlapping with standard benchmarks; (ii) overlap statistics between the constructed dataset and its upstream roots; and (iii) controlled comparisons against three baselines—random sampling, diversity sampling without lineage information, and full-corpus sampling—using the same metrics and statistical significance tests. Results will be presented in tables that allow readers to evaluate the practical gains separately from reconstruction accuracy. revision: yes
Circularity Check
No circularity; framework proposal is self-contained
full rationale
The manuscript introduces the data lineage concept and describes a multi-agent reconstruction framework, followed by observational characterizations of dataset patterns and a downstream sampling method. No equations, parameter fits, predictions derived from fitted inputs, or load-bearing self-citations appear in the abstract or described content. The central claims rest on the framework's outputs as an external analysis tool rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for a conceptual and empirical framework paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
invented entities (1)
-
data lineage graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Opencodereasoning: Advancing data distillation for compet- itive coding
Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, and Boris Ginsburg. Opencodereasoning: Advancing data distillation for compet- itive coding. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= aykM7KUVJZ
2025
-
[2]
Towards tracing knowledge in language models back to the training data
Ekin Akyurek, Tolga Bolukbasi, Frederick Liu, Binbin Xiong, Ian Tenney, Jacob Andreas, and Kelvin Guu. Towards tracing knowledge in language models back to the training data. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2429–2446, Abu Dhabi, United Arab Emirates, D...
-
[3]
Python-code-23k-sharegpt
Ajinkya Bawase. Python-code-23k-sharegpt. https://huggingface.co/datasets/ajibawa-2023/ Python-Code-23k-ShareGPT, 2023. Dataset
2023
-
[4]
Syntactic clustering of the web
Andrei Z Broder, Steven C Glassman, Mark S Manasse, and Geoffrey Zweig. Syntactic clustering of the web. Computer networks and ISDN systems, 29(8-13):1157–1166, 1997
1997
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
Mengzhang Cai, Xin Gao, Yu Li, Honglin Lin, Zheng Liu, Zhuoshi Pan, Qizhi Pei, Xiaoran Shang, Mengyuan Sun, Zinan Tang, Xiaoyang Wang, Zhanping Zhong, Yun Zhu, Dahua Lin, Conghui He, and Lijun Wu. Opendataarena: A fair and open arena for benchmarking post-training dataset value, 2025. URL https: //arxiv.org/abs/2512.14051
-
[7]
Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, and Xiangzhong Fang. Reasoning with omnithought: A large cot dataset with verbosity and cognitive difficulty annotations, 2025. URL https://arxiv.org/abs/ 2505.10937
-
[8]
Alpagasus: Training a better alpaca with fewer data
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id= FdVXgSJhvz
2024
-
[9]
Theoremqa: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7889–7901, 2023
2023
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Smith, and Jesse Dodge
Yanai Elazar, Akshita Bhagia, Ian Helgi Magnusson, Abhilasha Ravichander, Dustin Schwenk, Alane Suhr, Evan Pete Walsh, Dirk Groeneveld, Luca Soldaini, Sameer Singh, Hannaneh Hajishirzi, Noah A. Smith, and Jesse Dodge. What’s in my big data? InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=RvfPnOkPV4
2024
-
[13]
Megascience: Pushing the frontiers of post-training datasets for science reasoning, 2025
Run-Ze Fan, Zengzhi Wang, and Pengfei Liu. Megascience: Pushing the frontiers of post-training datasets for science reasoning.arXiv preprint arXiv:2507.16812, 2025. URLhttps://arxiv.org/abs/2507.16812
-
[14]
The vendi score: A diversity evaluation metric for machine learning
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning. T ransactions on Machine Learning Research, 2023. ISSN 2835-8856
2023
-
[15]
Omni-MATH: A universal olympiad level 13 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs mathematic benchmark for large language models
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. Omni-MATH: A universal olympiad level 13 A Multi-Agent Framework for Uncovering Data Lineage in Post-Tr...
2025
-
[16]
Shahriar Golchin and Mihai Surdeanu. Time travel in llms: Tracing data contamination in large language models.CoRR, abs/2308.08493, 2023. doi: 10.48550/ARXIV .2308.08493. URL https://doi.org/10.48550/ arXiv.2308.08493
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[17]
Know your data, 2021
Google. Know your data, 2021. URLhttps://github.com/pair-code/knowyourdata
2021
-
[18]
Openthoughts: Data recipes for reasoning models
Etash Kumar Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Rea Sprague, Ashima Suvarna, Benjamin Feuer, Leon Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik sharma, Charlie...
2026
-
[19]
Kelvin Guu, Albert Webson, Ellie Pavlick, Lucas Dixon, Ian Tenney, and Tolga Bolukbasi. Simfluence: Modeling the influence of individual training examples by simulating training runs, 2023. URL https: //arxiv.org/abs/2303.08114
-
[20]
Open instruct v1: A dataset for having llms follow instructions
hakurei. Open instruct v1: A dataset for having llms follow instructions. Hugging Face Datasets, 2023. URL https://huggingface.co/datasets/hakurei/open-instruct-v1. Accessed: 2026-01-03
2023
-
[21]
Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.NeurIPS, 2021
2021
-
[22]
Opencoder: The open cookbook for top-tier code large language models
Siming Huang, Tianhao Cheng, Jason Klein Liu, Weidi Xu, Jiaran Hao, Liuyihan Song, Yang Xu, Jian Yang, Jiaheng Liu, Chenchen Zhang, et al. Opencoder: The open cookbook for top-tier code large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33167–33193, 2025
2025
-
[23]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=chfJJYC3iL
2025
-
[24]
Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh...
2025
-
[25]
Xingxuan Li, Yao Xiao, Dianwen Ng, Hai Ye, Yue Deng, Xiang Lin, Bin Wang, Zhanfeng Mo, Chong Zhang, Yueyi Zhang, Zonglin Yang, Ruilin Li, Lei Lei, Shihao Xu, Han Zhao, Weiling Chen, Feng Ji, and Lidong Bing. Miromind-m1: An open-source advancement in mathematical reasoning via context-aware multi-stage policy optimization, 2025. URLhttps://arxiv.org/abs/2...
-
[26]
Yu Li, Zhuoshi Pan, Honglin Lin, Mengyuan Sun, Conghui He, and Lijun Wu. Can one domain help others? a data-centric study on multi-domain reasoning via reinforcement learning, 2025. URL https: //arxiv.org/abs/2507.17512
-
[27]
Cipherbank: Exploring the boundary of llm reasoning capabilities through cryptography challenge
Yu Li, Qizhi Pei, Mengyuan Sun, Honglin Lin, Chenlin Ming, Xin Gao, Jiang Wu, Conghui He, and Lijun Wu. Cipherbank: Exploring the boundary of llm reasoning capabilities through cryptography challenge. In Findings of the Association for Computational Linguistics: ACL 2025, pages 5929–5965, 2025
2025
-
[28]
An open-source data contamination report 14 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs for large language models
Yucheng Li, Yunhao Guo, Frank Guerin, and Chenghua Lin. An open-source data contamination report 14 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs for large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 528–541, 2024
2024
-
[29]
Scaling code- assisted chain-of-thoughts and instructions for model reasoning
Honglin Lin, Qizhi Pei, Zhuoshi Pan, Yu Li, Xin Gao, Juntao Li, Conghui He, and Lijun Wu. Scaling code- assisted chain-of-thoughts and instructions for model reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=b7bOWd3kUL
2025
-
[30]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
2022
-
[31]
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=BTKAeLqLMw
2024
-
[32]
Hercules v1.0, 2024
Locutusque. Hercules v1.0, 2024. URLhttps://huggingface.co/datasets/Locutusque/hercules-v1.0
2024
-
[33]
The flan collection: Designing data and methods for effective instruction tuning
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. In International conference on machine learning, pages 22631–22648. PMLR, 2023
2023
-
[34]
A large-scale audit of dataset licensing and attribution in ai.Nature Machine Intelligence, 6(8):975–987, 2024
Shayne Longpre, Robert Mahari, Anthony Chen, Naana Obeng-Marnu, Damien Sileo, William Brannon, Niklas Muennighoff, Nathan Khazam, Jad Kabbara, Kartik Perisetla, et al. A large-scale audit of dataset licensing and attribution in ai.Nature Machine Intelligence, 6(8):975–987, 2024
2024
-
[35]
#instag: Instruction tagging for analyzing supervised fine-tuning of large language models
Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #instag: Instruction tagging for analyzing supervised fine-tuning of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id= pszewhybU9
2024
-
[36]
Data measurements tool, 2021
Sasha Luccioni, Yacine Jernite, and Margaret Mitchell. Data measurements tool, 2021. URL https:// huggingface.co/blog/data-measurements-tool
2021
-
[37]
Mmevol: Empowering multimodal large language models with evol-instruct
Run Luo, Haonan Zhang, Longze Chen, Ting-En Lin, Xiong Liu, Yuchuan Wu, Min Yang, Yongbin Li, Minzheng Wang, Pengpeng Zeng, et al. Mmevol: Empowering multimodal large language models with evol-instruct. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19655–19682, 2025
2025
-
[38]
Orca-math: Unlocking the potential of slms in grade school math, 2024
Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah. Orca-math: Unlocking the potential of slms in grade school math, 2024
2024
-
[39]
Vicky Zhao, Conghui He, and Lijun Wu
Zhuoshi Pan, Qizhi Pei, Yu Li, Qiyao Sun, Zinan Tang, H. Vicky Zhao, Conghui He, and Lijun Wu. Rest: Stress testing large reasoning models by asking multiple problems at once, 2025. URL https://arxiv.org/ abs/2507.10541
-
[40]
Large language model sourcing: A survey, 2025
Liang Pang, Kangxi Wu, Sunhao Dai, Zihao Wei, Zenghao Duan, Jia Gu, Xiang Li, Zhiyi Yin, Jun Xu, Huawei Shen, and Xueqi Cheng. Large language model sourcing: A survey, 2025. URL https://arxiv.org/abs/ 2510.10161
-
[41]
Mathfusion: Enhancing mathematical problem-solving of llm through instruction fusion
Qizhi Pei, Lijun Wu, Zhuoshi Pan, Yu Li, Honglin Lin, Chenlin Ming, Xin Gao, Conghui He, and Rui Yan. Mathfusion: Enhancing mathematical problem-solving of llm through instruction fusion. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7400–7420, 2025
2025
-
[42]
Scalediff: Scaling difficult problems for advanced mathematical reasoning, 2026
Qizhi Pei, Zhuoshi Pan, Honglin Lin, Xin Gao, Yu Li, Zinan Tang, Conghui He, Rui Yan, and Lijun Wu. Scalediff: Scaling difficult problems for advanced mathematical reasoning, 2026. URL https://openreview. net/forum?id=dbcXNwfgsI
2026
-
[43]
Codeforces cots
Guilherme Penedo, Anton Lozhkov, Hynek Kydl´ıˇcek, Loubna Ben Allal, Edward Beeching, Agust´ın Piqueres Lajar´ın, Quentin Gallou´edec, Nathan Habib, Lewis Tunstall, and Leandro von Werra. Codeforces cots. https://huggingface.co/datasets/open-r1/codeforces-cots, 2025
2025
-
[44]
Open-omega-forge-1m
prithivMLmods. Open-omega-forge-1m. https://huggingface.co/datasets/prithivMLmods/ Open-Omega-Forge-1M, 2025. Dataset. 15 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
2025
-
[45]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URLhttp://jmlr.org/papers/v21/20-074.html
2020
-
[46]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark
Oscar Sainz, Jon Campos, Iker Garc´ıa-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, 2023
2023
-
[47]
A survey of large language models: evolution, architectures, adaptation, benchmarking, applications, challenges, and societal implications.Electronics, 14(18), 2025
Seyed Mahmoud Sajjadi Mohammadabadi, Burak Cem Kara, Can Eyupoglu, Can Uzay, Mehmet Serkan Tosun, and Oktay Karaku s ¸. A survey of large language models: evolution, architectures, adaptation, benchmarking, applications, challenges, and societal implications.Electronics, 14(18), 2025
2025
-
[48]
Randomness is all you need: Semantic traversal of problem-solution spaces with large language models.Available at SSRN 4721407, 2024
Thomas E Sandholm, Sayandev Mukherjee, and Bernardo A Huberman. Randomness is all you need: Semantic traversal of problem-solution spaces with large language models.Available at SSRN 4721407, 2024
2024
-
[49]
EvolvedGRPO: Unlocking reasoning in LVLMs via progressive instruction evolution
Zhebei Shen, Qifan Yu, Juncheng Li, Wei Ji, Qizhi Chen, Siliang Tang, and Yueting Zhuang. EvolvedGRPO: Unlocking reasoning in LVLMs via progressive instruction evolution. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=tjXtcZjIgQ
2025
-
[50]
Analysis of euclidean distance and manhattan distance in the k-means algorithm for variations number of centroid k
Rizki Suwanda, Zulfahmi Syahputra, and Elvi M Zamzami. Analysis of euclidean distance and manhattan distance in the k-means algorithm for variations number of centroid k. InJournal of Physics: Conference Series, volume 1566, page 012058. IOP Publishing, 2020
2020
-
[51]
Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023
Teknium. Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023. URL https://huggingface.co/datasets/teknium/OpenHermes-2.5
2023
-
[52]
Not all correct answers are equal: Why your distillation source matters, 2025
Xiaoyu Tian, Yunjie Ji, Haotian Wang, Shuaiting Chen, Sitong Zhao, Yiping Peng, Han Zhao, and Xiangang Li. Not all correct answers are equal: Why your distillation source matters, 2025. URLhttps://arxiv.org/ abs/2505.14464
-
[53]
Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data. InThe Thirteenth In- ternational Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=mTCbq2QssD
2025
-
[54]
Scibench: evaluating college-level scientific problem-solving abilities of large language models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. Scibench: evaluating college-level scientific problem-solving abilities of large language models. InProceedings of the 41st International Conference on Machine Learning, pages 50622–50649, 2024
2024
-
[55]
Maurice Weber, Daniel Y. Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher R´e, Irina Rish, and Ce Zhang. Redpajama: an open dataset for training large language models.NeurIPS Datasets and ...
2024
-
[56]
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Tanglifu Tanglifu, Xiaowei Lv, et al. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry T rack), pages 318–327, 2025
2025
-
[57]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[58]
Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=Pnk7vMbznK
2025
-
[59]
A practical two-stage recipe for mathematical LLMs: Maximizing accuracy with SFT and efficiency with reinforcement learning
Hiroshi Yoshihara, Taiki Yamaguchi, and Yuichi Inoue. A practical two-stage recipe for mathematical LLMs: Maximizing accuracy with SFT and efficiency with reinforcement learning. In2nd AI for Math Workshop @ ICML 2025, 2025. URLhttps://openreview.net/forum?id=8hJfUAFY5f. 16 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs
2025
-
[60]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26125–26135, June 2025
2025
-
[61]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2025. URLhttps://arxiv.org/abs/2303.18223
work page internal anchor Pith review arXiv 2025
-
[63]
Opencodeinterpreter: Integrating code generation with execution and refinement
Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement. InFindings of the Association for Computational Linguistics: ACL 2024, pages 12834–12859, 2024
2024
-
[64]
Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36: 55006–55021, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36: 55006–55021, 2023
2023
-
[65]
A survey of llm×data.arXiv preprint arXiv:2505.18458, 2025
Xuanhe Zhou, Junxuan He, Wei Zhou, Haodong Chen, Zirui Tang, Haoyu Zhao, Xin Tong, Guoliang Li, Youmin Chen, Jun Zhou, et al. A survey of llm×data.arXiv preprint arXiv:2505.18458, 2025. 17 A Multi-Agent Framework for Uncovering Data Lineage in Post-Training LLMs Appendix A Implementation Details of Automatic Provenance Framework In this section, we provid...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.